 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeALARM: Audio-Language Alignment for Reasoning Models
Mar 10, 2026Large audio language models (ALMs) extend LLMs with auditory understanding. A common approach freezes the LLM and trains only an adapter on self-generated targets. However, this fails for reasoning LLMs (RLMs) whose built-in chain-of-thought traces expose the textual surrogate input, yielding unnatural responses. We propose self-rephrasing, converting self-generated responses into audio-understanding variants compatible with RLMs while preserving distributional alignment. We further fuse and compress multiple audio encoders for stronger representations. For training, we construct a 6M-instance multi-task corpus (2.5M unique prompts) spanning 19K hours of speech, music, and sound. Our 4B-parameter ALM outperforms similarly sized models and surpasses most larger ALMs on related audio-reasoning benchmarks, while preserving textual capabilities with a low training cost. Notably, we achieve the best open-source result on the MMAU-speech and MMSU benchmarks and rank third among all the models.
What Does an Audio Deepfake Detector Focus on? A Study in the Time Domain
Jan 27, 2025



Adding explanations to audio deepfake detection (ADD) models will boost their real-world application by providing insight on the decision making process. In this paper, we propose a relevancy-based explainable AI (XAI) method to analyze the predictions of transformer-based ADD models. We compare against standard Grad-CAM and SHAP-based methods, using quantitative faithfulness metrics as well as a partial spoof test, to comprehensively analyze the relative importance of different temporal regions in an audio. We consider large datasets, unlike previous works where only limited utterances are studied, and find that the XAI methods differ in their explanations. The proposed relevancy-based XAI method performs the best overall on a variety of metrics. Further investigation on the relative importance of speech/non-speech, phonetic content, and voice onsets/offsets suggest that the XAI results obtained from analyzing limited utterances don't necessarily hold when evaluated on large datasets.
A Comparative Study of Fusion Methods for SASV Challenge 2022
Mar 31, 2022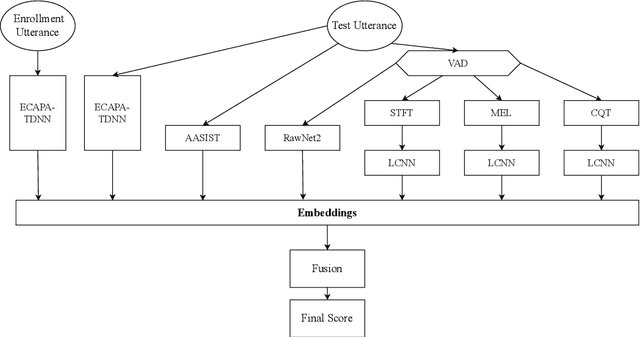
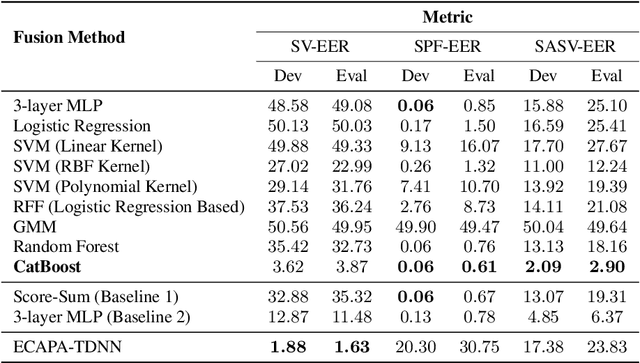
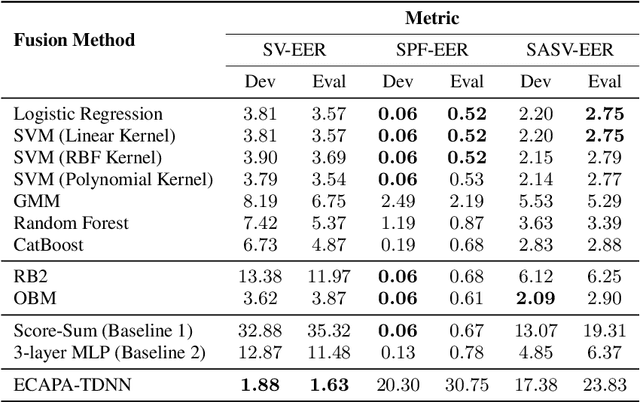
Automatic Speaker Verification (ASV) system is a type of bio-metric authentication. It can be attacked by an intruder, who falsifies data in order to get access to protected information. Countermeasures (CM) are special algorithms that detect these spoofing-attacks. While the ASVspoof Challenge series were focused on the development of CM for fixed ASV system, the new Spoofing Aware Speaker Verification (SASV) Challenge organizers believe that best results can be achieved if CM and ASV systems are optimized jointly. One of the approaches for cooperative optimization is a fusion over embeddings or scores obtained from ASV and CM models. The baselines of SASV Challenge 2022 present two types of fusion: score-sum and back-end ensemble with a 3-layer MLP. This paper describes our research of other fusion methods, including boosting over embeddings, which has not been used in anti-spoofing studies before.