 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBoosting Self-Supervised Embeddings for Speech Enhancement
Paper and Code
Apr 07, 2022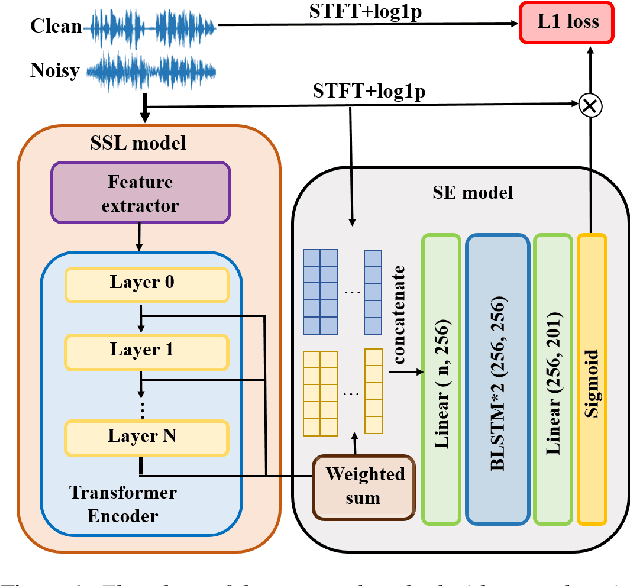
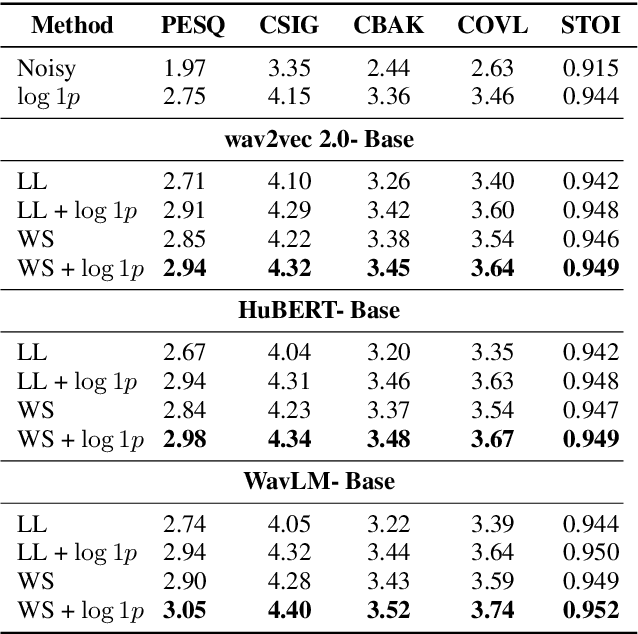
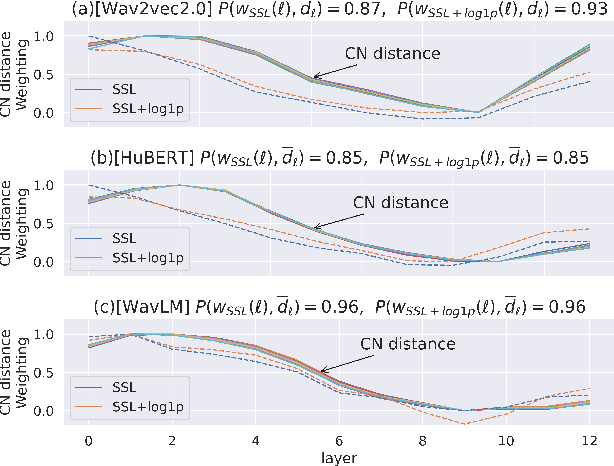
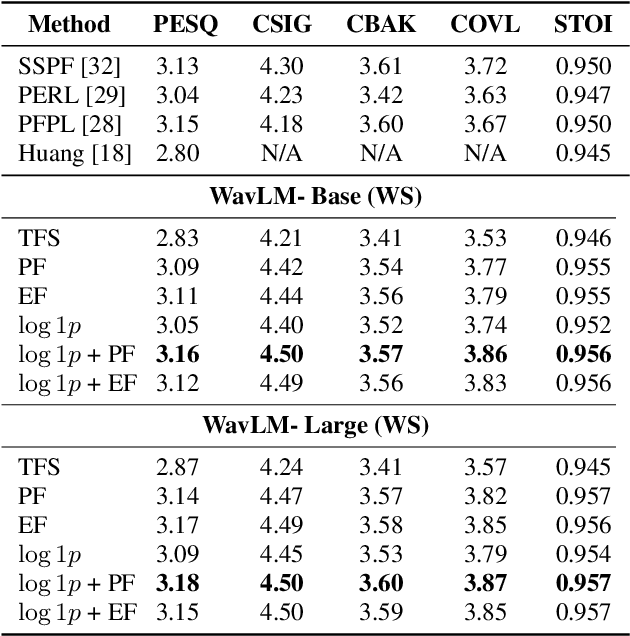
Self-supervised learning (SSL) representation for speech has achieved state-of-the-art (SOTA) performance on several downstream tasks. However, there remains room for improvement in speech enhancement (SE) tasks. In this study, we used a cross-domain feature to solve the problem that SSL embeddings may lack fine-grained information to regenerate speech signals. By integrating the SSL representation and spectrogram, the result can be significantly boosted. We further study the relationship between the noise robustness of SSL representation via clean-noisy distance (CN distance) and the layer importance for SE. Consequently, we found that SSL representations with lower noise robustness are more important. Furthermore, our experiments on the VCTK-DEMAND dataset demonstrated that fine-tuning an SSL representation with an SE model can outperform the SOTA SSL-based SE methods in PESQ, CSIG and COVL without invoking complicated network architectures. In later experiments, the CN distance in SSL embeddings was observed to increase after fine-tuning. These results verify our expectations and may help design SE-related SSL training in the future.