 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Democracy Does Matter: Comprehensive Feature Mining for Co-Salient Object Detection
Mar 11, 2022

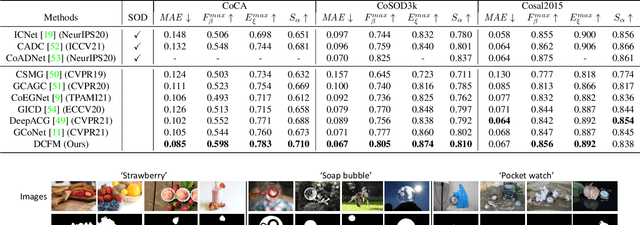
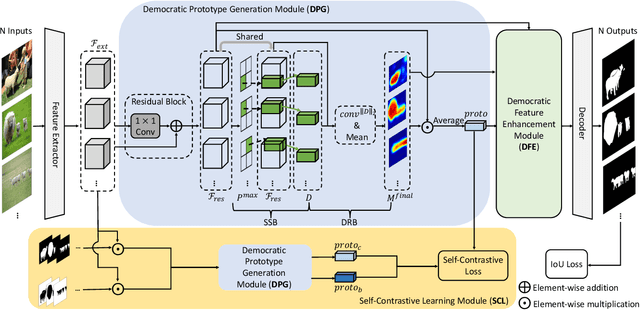
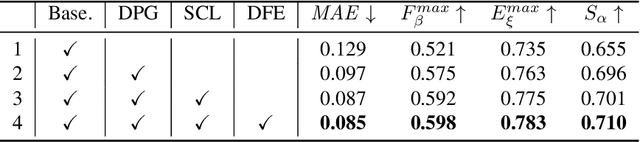
Co-salient object detection, with the target of detecting co-existed salient objects among a group of images, is gaining popularity. Recent works use the attention mechanism or extra information to aggregate common co-salient features, leading to incomplete even incorrect responses for target objects. In this paper, we aim to mine comprehensive co-salient features with democracy and reduce background interference without introducing any extra information. To achieve this, we design a democratic prototype generation module to generate democratic response maps, covering sufficient co-salient regions and thereby involving more shared attributes of co-salient objects. Then a comprehensive prototype based on the response maps can be generated as a guide for final prediction. To suppress the noisy background information in the prototype, we propose a self-contrastive learning module, where both positive and negative pairs are formed without relying on additional classification information. Besides, we also design a democratic feature enhancement module to further strengthen the co-salient features by readjusting attention values. Extensive experiments show that our model obtains better performance than previous state-of-the-art methods, especially on challenging real-world cases (e.g., for CoCA, we obtain a gain of 2.0% for MAE, 5.4% for maximum F-measure, 2.3% for maximum E-measure, and 3.7% for S-measure) under the same settings. Code will be released soon.
Screening Gender Transfer in Neural Machine Translation
Feb 25, 2022

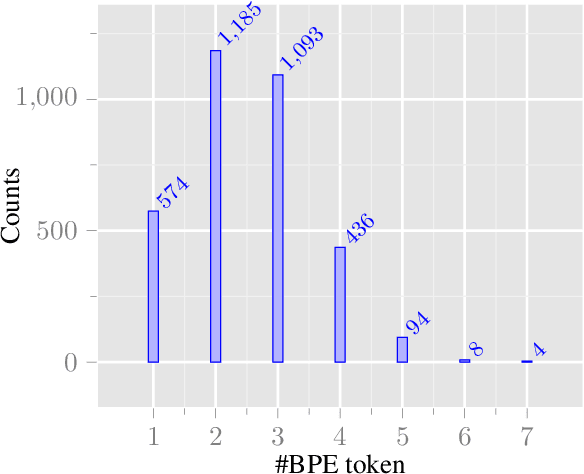
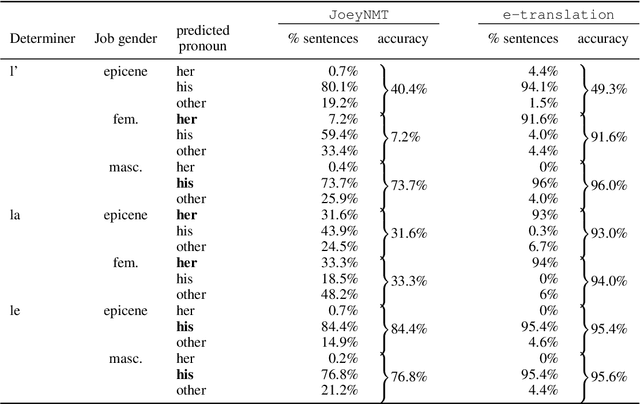
This paper aims at identifying the information flow in state-of-the-art machine translation systems, taking as example the transfer of gender when translating from French into English. Using a controlled set of examples, we experiment several ways to investigate how gender information circulates in a encoder-decoder architecture considering both probing techniques as well as interventions on the internal representations used in the MT system. Our results show that gender information can be found in all token representations built by the encoder and the decoder and lead us to conclude that there are multiple pathways for gender transfer.
Relation-guided acoustic scene classification aided with event embeddings
May 01, 2022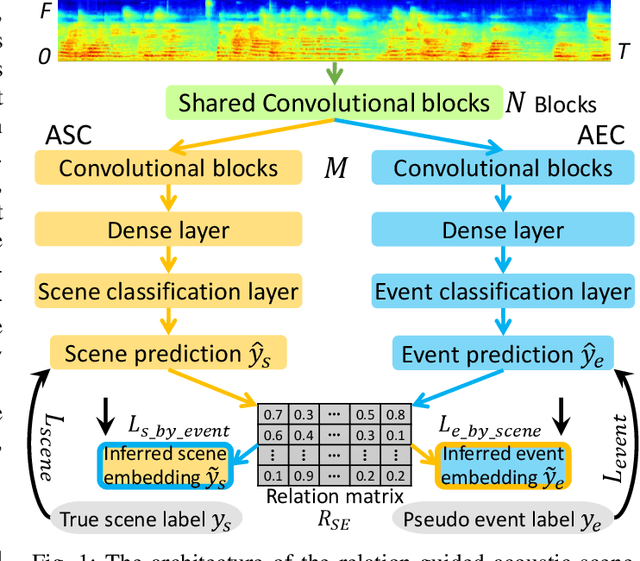
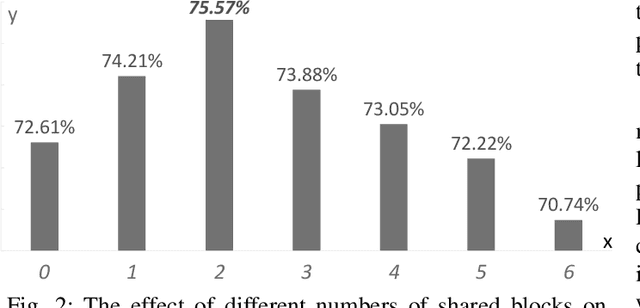
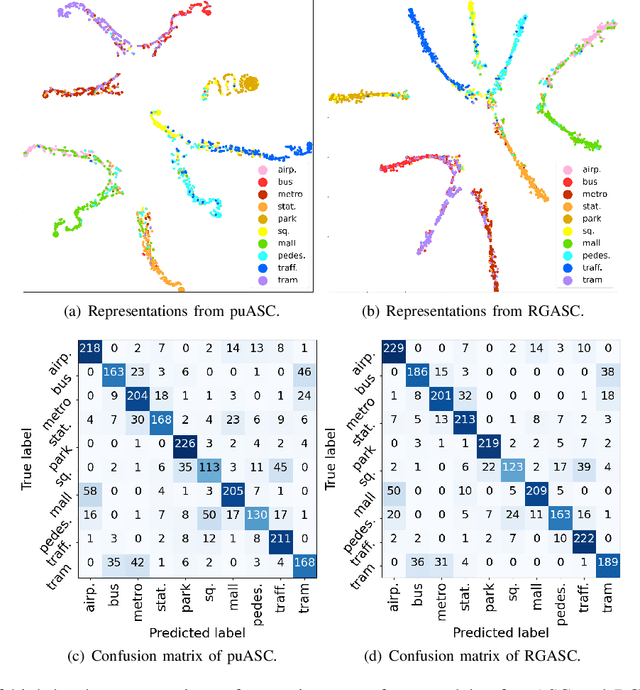
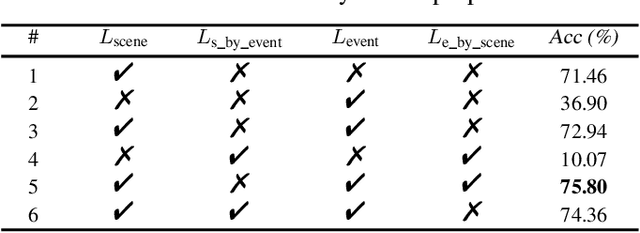
In real life, acoustic scenes and audio events are naturally correlated. Humans instinctively rely on fine-grained audio events as well as the overall sound characteristics to distinguish diverse acoustic scenes. Yet, most previous approaches treat acoustic scene classification (ASC) and audio event classification (AEC) as two independent tasks. A few studies on scene and event joint classification either use synthetic audio datasets that hardly match the real world, or simply use the multi-task framework to perform two tasks at the same time. Neither of these two ways makes full use of the implicit and inherent relation between fine-grained events and coarse-grained scenes. To this end, this paper proposes a relation-guided ASC (RGASC) model to further exploit and coordinate the scene-event relation for the mutual benefit of scene and event recognition. The TUT Urban Acoustic Scenes 2018 dataset (TUT2018) is annotated with pseudo labels of events by a simple and efficient audio-related pre-trained model PANN, which is one of the state-of-the-art AEC models. Then, a prior scene-event relation matrix is defined as the average probability of the presence of each event type in each scene class. Finally, the two-tower RGASC model is jointly trained on the real-life dataset TUT2018 for both scene and event classification. The following results are achieved. 1) RGASC effectively coordinates the true information of coarse-grained scenes and the pseudo information of fine-grained events. 2) The event embeddings learned from pseudo labels under the guidance of prior scene-event relations help reduce the confusion between similar acoustic scenes. 3) Compared with other (non-ensemble) methods, RGASC improves the scene classification accuracy on the real-life dataset.
InducT-GCN: Inductive Graph Convolutional Networks for Text Classification
Jun 01, 2022
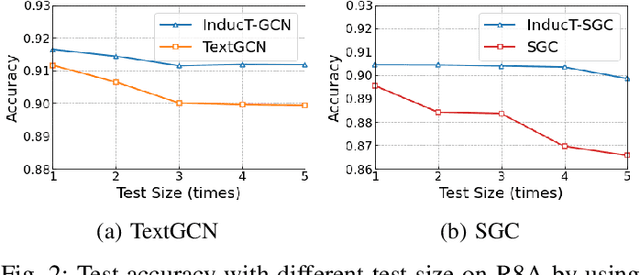
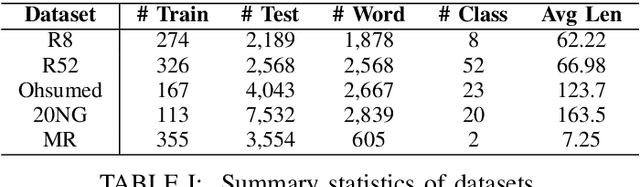
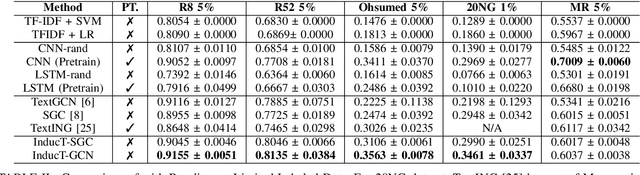
Text classification aims to assign labels to textual units by making use of global information. Recent studies have applied graph neural network (GNN) to capture the global word co-occurrence in a corpus. Existing approaches require that all the nodes (training and test) in a graph are present during training, which are transductive and do not naturally generalise to unseen nodes. To make those models inductive, they use extra resources, like pretrained word embedding. However, high-quality resource is not always available and hard to train. Under the extreme settings with no extra resource and limited amount of training set, can we still learn an inductive graph-based text classification model? In this paper, we introduce a novel inductive graph-based text classification framework, InducT-GCN (InducTive Graph Convolutional Networks for Text classification). Compared to transductive models that require test documents in training, we construct a graph based on the statistics of training documents only and represent document vectors with a weighted sum of word vectors. We then conduct one-directional GCN propagation during testing. Across five text classification benchmarks, our InducT-GCN outperformed state-of-the-art methods that are either transductive in nature or pre-trained additional resources. We also conducted scalability testing by gradually increasing the data size and revealed that our InducT-GCN can reduce the time and space complexity. The code is available on: https://github.com/usydnlp/InductTGCN.
PAS: A Position-Aware Similarity Measurement for Sequential Recommendation
May 14, 2022
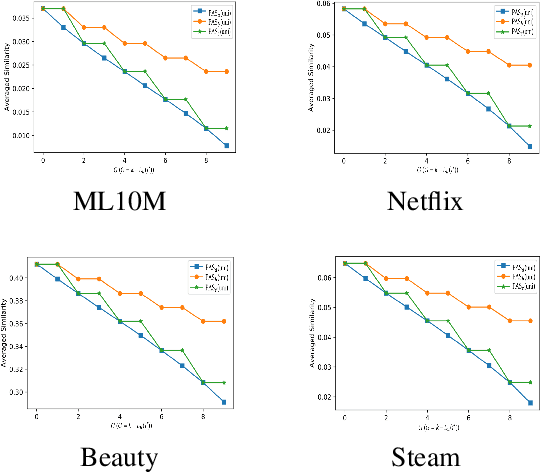
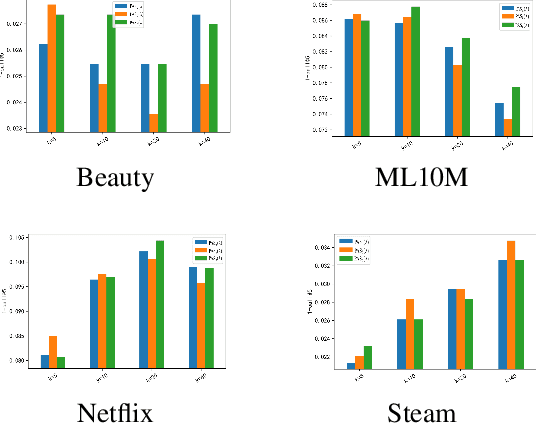
The common item-based collaborative filtering framework becomes a typical recommendation method when equipped with a certain item-to-item similarity measurement. On one hand, we realize that a well-designed similarity measurement is the key to providing satisfactory recommendation services. On the other hand, similarity measurements designed for sequential recommendation are rarely studied by the recommender systems community. Hence in this paper, we focus on devising a novel similarity measurement called position-aware similarity (PAS) for sequential recommendation. The proposed PAS is, to our knowledge, the first count-based similarity measurement that concurrently captures the sequential patterns from the historical user behavior data and from the item position information within the input sequences. We conduct extensive empirical studies on four public datasets, in which our proposed PAS-based method exhibits competitive performance even compared to the state-of-the-art sequential recommendation methods, including a very recent similarity-based method and two GNN-based methods.
3D Segmentation Guided Style-based Generative Adversarial Networks for PET Synthesis
May 18, 2022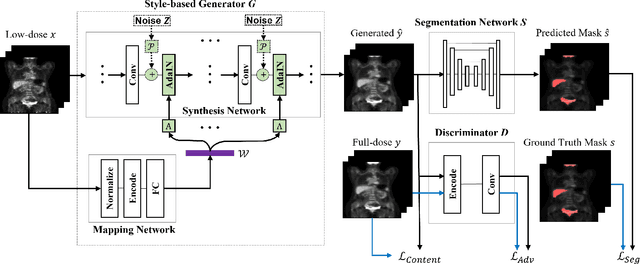
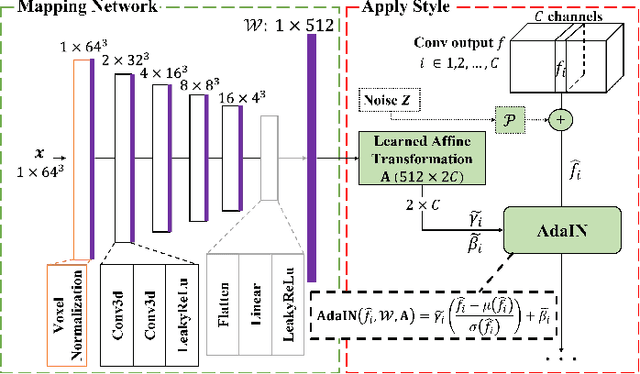
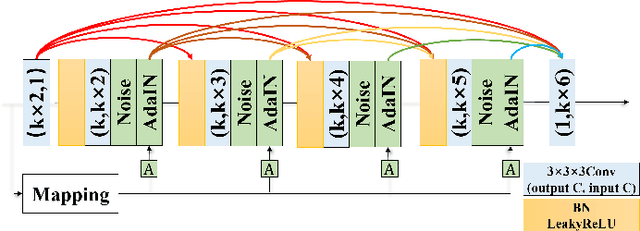
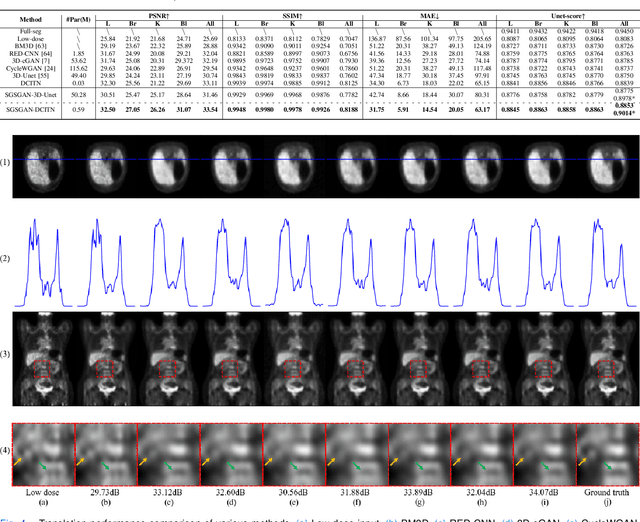
Potential radioactive hazards in full-dose positron emission tomography (PET) imaging remain a concern, whereas the quality of low-dose images is never desirable for clinical use. So it is of great interest to translate low-dose PET images into full-dose. Previous studies based on deep learning methods usually directly extract hierarchical features for reconstruction. We notice that the importance of each feature is different and they should be weighted dissimilarly so that tiny information can be captured by the neural network. Furthermore, the synthesis on some regions of interest is important in some applications. Here we propose a novel segmentation guided style-based generative adversarial network (SGSGAN) for PET synthesis. (1) We put forward a style-based generator employing style modulation, which specifically controls the hierarchical features in the translation process, to generate images with more realistic textures. (2) We adopt a task-driven strategy that couples a segmentation task with a generative adversarial network (GAN) framework to improve the translation performance. Extensive experiments show the superiority of our overall framework in PET synthesis, especially on those regions of interest.
Updating Industrial Robots for Emerging Technologies
Apr 07, 2022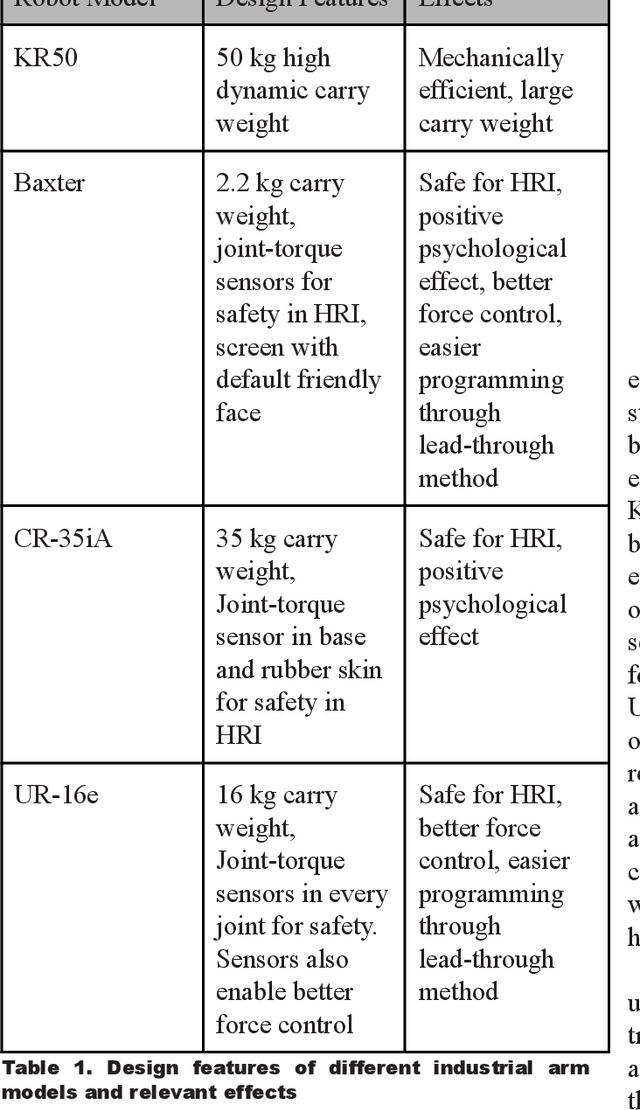
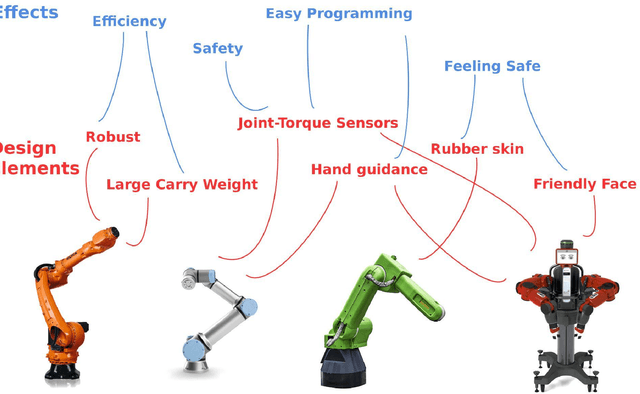
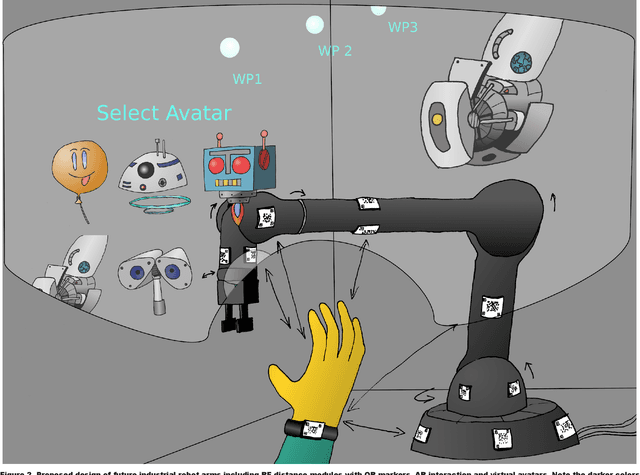
Industrial arms need to evolve beyond their standard shape to embrace new and emerging technologies. In this paper, we shall first perform an analysis of four popular but different modern industrial robot arms. By seeing the common trends we will try to extrapolate and expand these trends for the future. Here, particular focus will be on interaction based on augmented reality (AR) through head-mounted displays (HMD), but also through smartphones. Long-term human-robot interaction and personalization of said interaction will also be considered. The use of AR in human-robot interaction has proven to enhance communication and information exchange. A basic addition to industrial arm design would be the integration of QR markers on the robot, both for accessing information and adding tracking capabilities to more easily display AR overlays. In a recent example of information access, Mercedes Benz added QR markers on their cars to help rescue workers estimate the best places to cut and evacuate people after car crashes. One has also to deal with safety in an environment that will be more and more about collaboration. The QR markers can therefore be combined with RF-based ranging modules, developed in the EU-project SafeLog, that can be used both for safety as well as for tracking of human positions while in close proximity interactions with the industrial arms. The industrial arms of the future should also be intuitive to program and interact with. This would be achieved through AR and head mounted displays as well as the already mentioned RF-based person tracking. Finally, a more personalized interaction between the robots and humans can be achieved through life-long learning AI and disembodied, personalized agents. We propose a design that not only exists in the physical world, but also partly in the digital world of mixed reality.
Good Visual Guidance Makes A Better Extractor: Hierarchical Visual Prefix for Multimodal Entity and Relation Extraction
May 07, 2022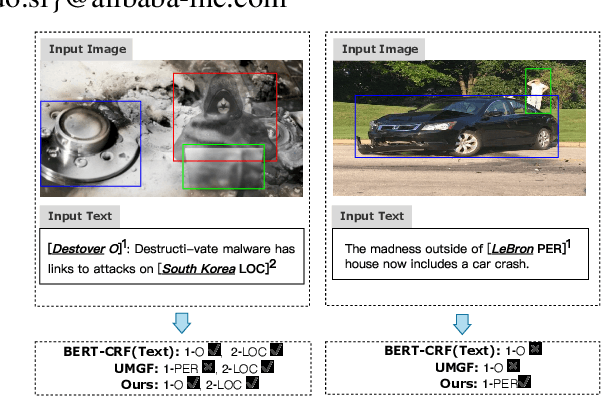
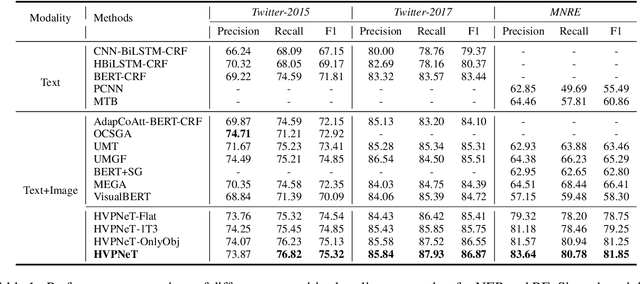
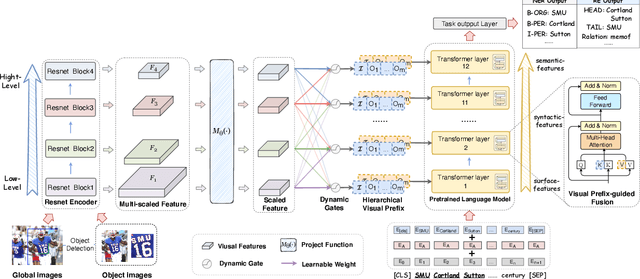

Multimodal named entity recognition and relation extraction (MNER and MRE) is a fundamental and crucial branch in information extraction. However, existing approaches for MNER and MRE usually suffer from error sensitivity when irrelevant object images incorporated in texts. To deal with these issues, we propose a novel Hierarchical Visual Prefix fusion NeTwork (HVPNeT) for visual-enhanced entity and relation extraction, aiming to achieve more effective and robust performance. Specifically, we regard visual representation as pluggable visual prefix to guide the textual representation for error insensitive forecasting decision. We further propose a dynamic gated aggregation strategy to achieve hierarchical multi-scaled visual features as visual prefix for fusion. Extensive experiments on three benchmark datasets demonstrate the effectiveness of our method, and achieve state-of-the-art performance. Code is available in https://github.com/zjunlp/HVPNeT.
Multimodal Learning on Graphs for Disease Relation Extraction
Mar 16, 2022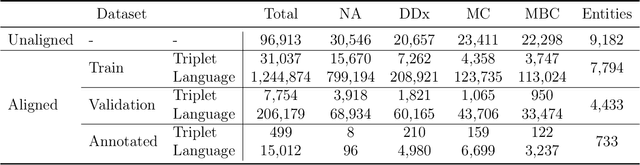
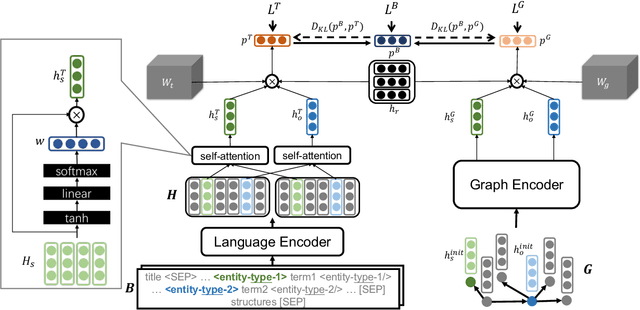
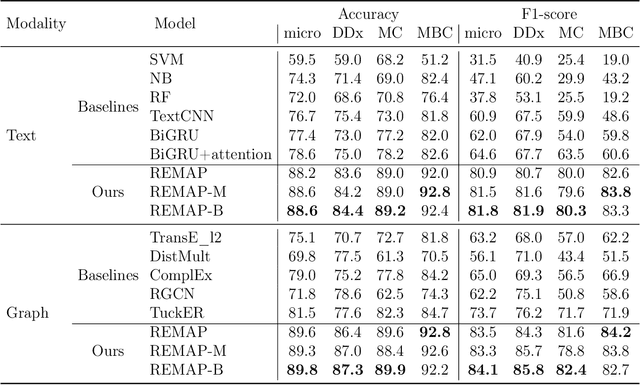

Objective: Disease knowledge graphs are a way to connect, organize, and access disparate information about diseases with numerous benefits for artificial intelligence (AI). To create knowledge graphs, it is necessary to extract knowledge from multimodal datasets in the form of relationships between disease concepts and normalize both concepts and relationship types. Methods: We introduce REMAP, a multimodal approach for disease relation extraction and classification. The REMAP machine learning approach jointly embeds a partial, incomplete knowledge graph and a medical language dataset into a compact latent vector space, followed by aligning the multimodal embeddings for optimal disease relation extraction. Results: We apply REMAP approach to a disease knowledge graph with 96,913 relations and a text dataset of 1.24 million sentences. On a dataset annotated by human experts, REMAP improves text-based disease relation extraction by 10.0% (accuracy) and 17.2% (F1-score) by fusing disease knowledge graphs with text information. Further, REMAP leverages text information to recommend new relationships in the knowledge graph, outperforming graph-based methods by 8.4% (accuracy) and 10.4% (F1-score). Discussion: Systematized knowledge is becoming the backbone of AI, creating opportunities to inject semantics into AI and fully integrate it into machine learning algorithms. While prior semantic knowledge can assist in extracting disease relationships from text, existing methods can not fully leverage multimodal datasets. Conclusion: REMAP is a multimodal approach for extracting and classifying disease relationships by fusing structured knowledge and text information. REMAP provides a flexible neural architecture to easily find, access, and validate AI-driven relationships between disease concepts.
EVM Mitigation with PAPR and ACLR Constraints in Large-Scale MIMO-OFDM Using TOP-ADMM
May 25, 2022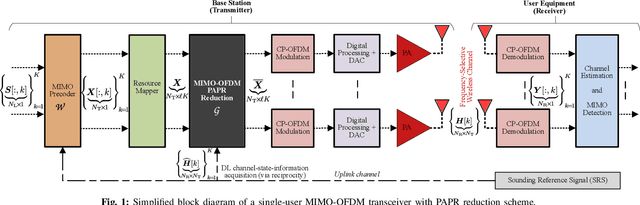
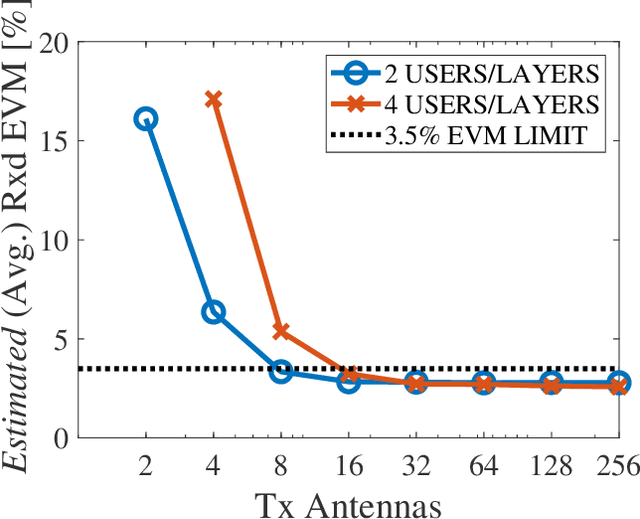
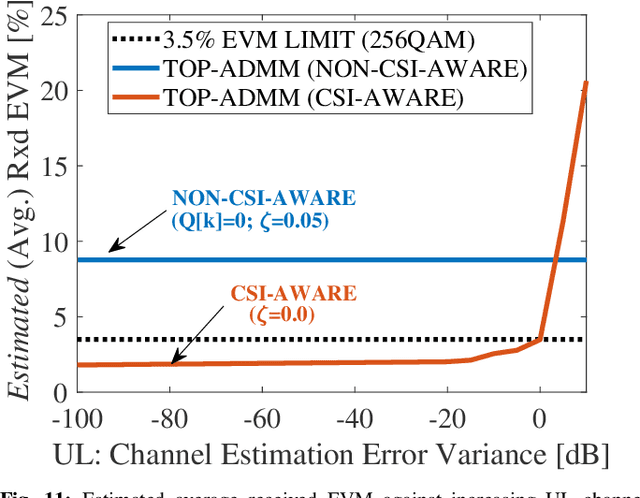
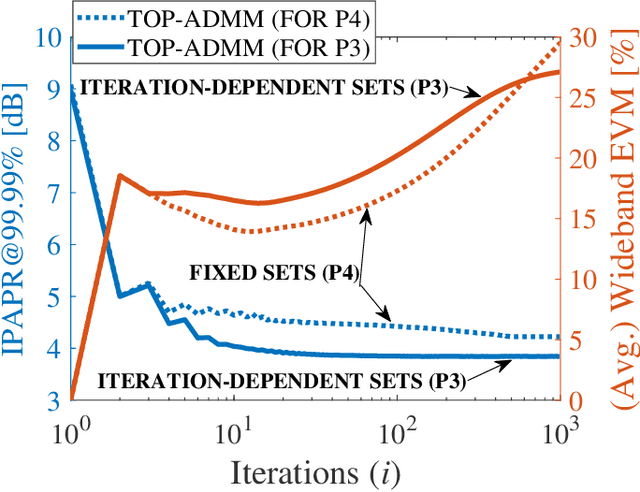
Although signal distortion-based peak-to-average power ratio (PAPR) reduction is a feasible candidate for orthogonal frequency division multiplexing (OFDM) to meet standard/regulatory requirements, the error vector magnitude (EVM) stemming from the PAPR reduction has a deleterious impact on the performance of high data-rate achieving multiple-input multiple-output (MIMO) systems. Moreover, these systems must constrain the adjacent channel leakage ratio (ACLR) to comply with regulatory requirements. Several recent works have investigated the mitigation of the EVM seen at the receivers by capitalizing on the excess spatial dimensions inherent in the large-scale MIMO that assume the availability of perfect channel state information (CSI) with spatially uncorrelated wireless channels. Unfortunately, practical systems operate with erroneous CSI and spatially correlated channels. Additionally, most standards support user-specific/CSI-aware beamformed and cell-specific/non-CSI-aware broadcasting channels. Hence, we formulate a robust EVM mitigation problem under channel uncertainty with nonconvex PAPR and ACLR constraints catering to beamforming/broadcasting. To solve this formidable problem, we develop an efficient scheme using our recently proposed three-operator alternating direction method of multipliers (TOP-ADMM) algorithm and benchmark it against two three-operator algorithms previously presented for machine learning purposes. Numerical results show the efficacy of the proposed algorithm under imperfect CSI and spatially correlated channels.