 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Tensor-networks for High-order Polynomial Approximation: A Many-body Physics Perspective
Apr 16, 2022
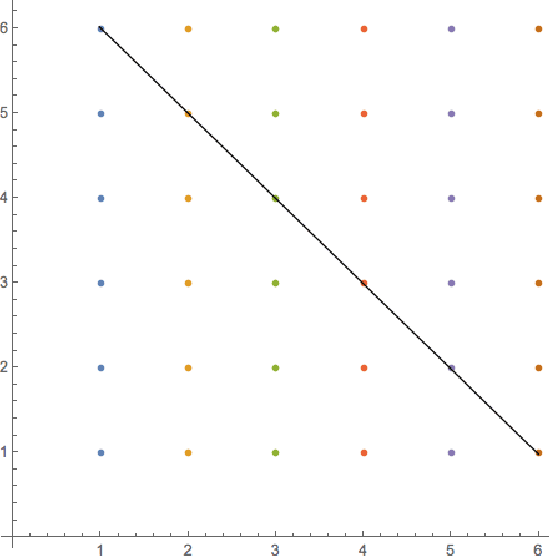
We analyze the problem of high-order polynomial approximation from a many-body physics perspective, and demonstrate the descriptive power of entanglement entropy in capturing model capacity and task complexity. Instantiated with a high-order nonlinear dynamics modeling problem, tensor-network models are investigated and exhibit promising modeling advantages. This novel perspective establish a connection between quantum information and functional approximation, which worth further exploration in future research.
DPSNN: A Differentially Private Spiking Neural Network
May 24, 2022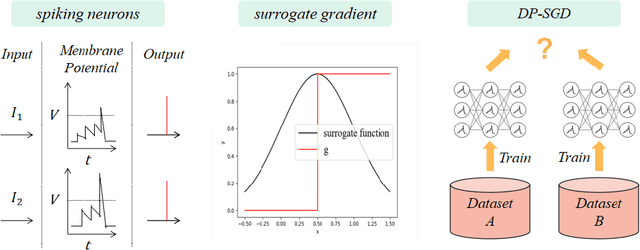

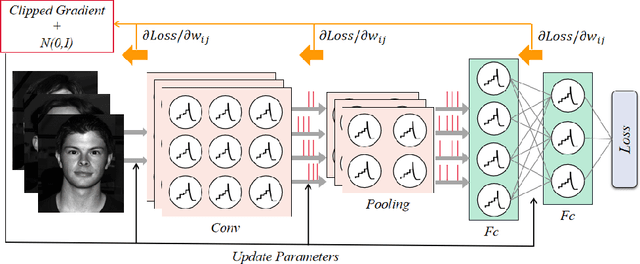
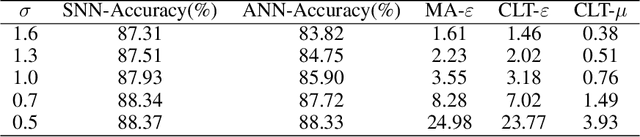
Privacy-preserving is a key problem for the machine learning algorithm. Spiking neural network (SNN) plays an important role in many domains, such as image classification, object detection, and speech recognition, but the study on the privacy protection of SNN is urgently needed. This study combines the differential privacy (DP) algorithm and SNN and proposes differentially private spiking neural network (DPSNN). DP injects noise into the gradient, and SNN transmits information in discrete spike trains so that our differentially private SNN can maintain strong privacy protection while still ensuring high accuracy. We conducted experiments on MNIST, Fashion-MNIST, and the face recognition dataset Extended YaleB. When the privacy protection is improved, the accuracy of the artificial neural network(ANN) drops significantly, but our algorithm shows little change in performance. Meanwhile, we analyzed different factors that affect the privacy protection of SNN. Firstly, the less precise the surrogate gradient is, the better the privacy protection of the SNN. Secondly, the Integrate-And-Fire (IF) neurons perform better than leaky Integrate-And-Fire (LIF) neurons. Thirdly, a large time window contributes more to privacy protection and performance.
Beyond the Prototype: Divide-and-conquer Proxies for Few-shot Segmentation
Apr 21, 2022
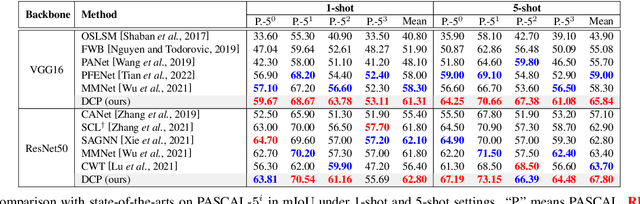
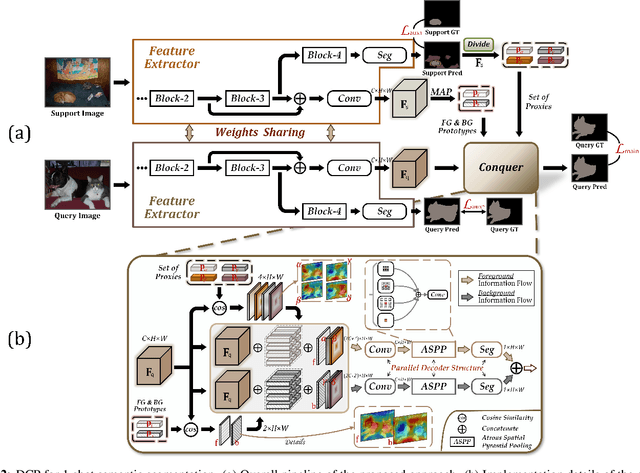

Few-shot segmentation, which aims to segment unseen-class objects given only a handful of densely labeled samples, has received widespread attention from the community. Existing approaches typically follow the prototype learning paradigm to perform meta-inference, which fails to fully exploit the underlying information from support image-mask pairs, resulting in various segmentation failures, e.g., incomplete objects, ambiguous boundaries, and distractor activation. To this end, we propose a simple yet versatile framework in the spirit of divide-and-conquer. Specifically, a novel self-reasoning scheme is first implemented on the annotated support image, and then the coarse segmentation mask is divided into multiple regions with different properties. Leveraging effective masked average pooling operations, a series of support-induced proxies are thus derived, each playing a specific role in conquering the above challenges. Moreover, we devise a unique parallel decoder structure that integrates proxies with similar attributes to boost the discrimination power. Our proposed approach, named divide-and-conquer proxies (DCP), allows for the development of appropriate and reliable information as a guide at the "episode" level, not just about the object cues themselves. Extensive experiments on PASCAL-5i and COCO-20i demonstrate the superiority of DCP over conventional prototype-based approaches (up to 5~10% on average), which also establishes a new state-of-the-art. Code is available at github.com/chunbolang/DCP.
Unsupervised Knowledge Adaptation for Passenger Demand Forecasting
Jun 08, 2022
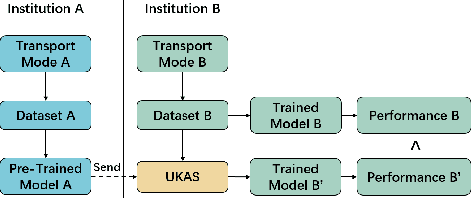
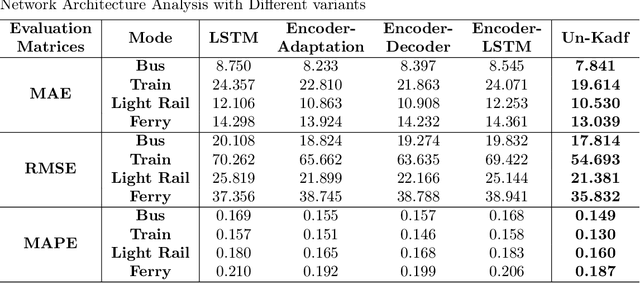
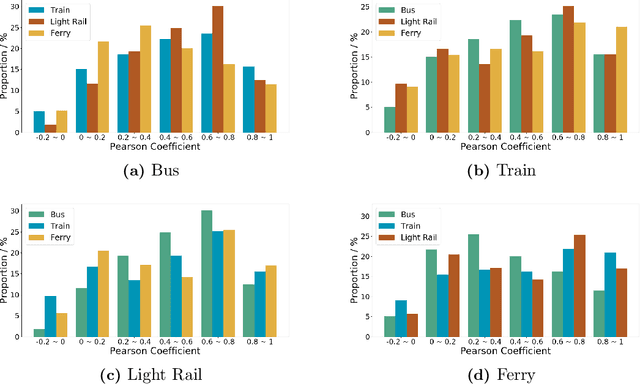
Considering the multimodal nature of transport systems and potential cross-modal correlations, there is a growing trend of enhancing demand forecasting accuracy by learning from multimodal data. These multimodal forecasting models can improve accuracy but be less practical when different parts of multimodal datasets are owned by different institutions who cannot directly share data among them. While various institutions may can not share their data with each other directly, they may share forecasting models trained by their data, where such models cannot be used to identify the exact information from their datasets. This study proposes an Unsupervised Knowledge Adaptation Demand Forecasting framework to forecast the demand of the target mode by utilizing a pre-trained model based on data of another mode, which does not require direct data sharing of the source mode. The proposed framework utilizes the potential shared patterns among multiple transport modes to improve forecasting performance while avoiding the direct sharing of data among different institutions. Specifically, a pre-trained forecasting model is first learned based on the data of a source mode, which can capture and memorize the source travel patterns. Then, the demand data of the target dataset is encoded into an individual knowledge part and a sharing knowledge part which will extract travel patterns by individual extraction network and sharing extraction network, respectively. The unsupervised knowledge adaptation strategy is utilized to form the sharing features for further forecasting by making the pre-trained network and the sharing extraction network analogous. Our findings illustrate that unsupervised knowledge adaptation by sharing the pre-trained model to the target mode can improve the forecasting performance without the dependence on direct data sharing.
A Property Induction Framework for Neural Language Models
May 13, 2022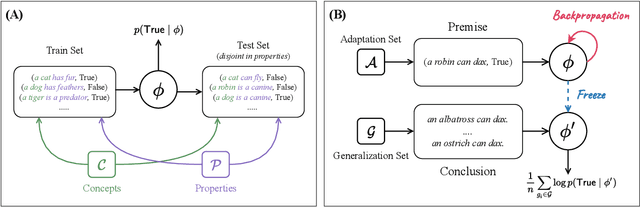
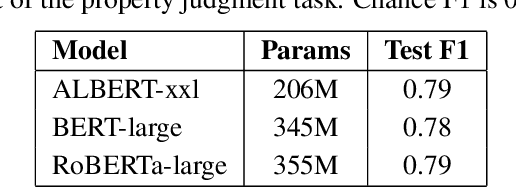
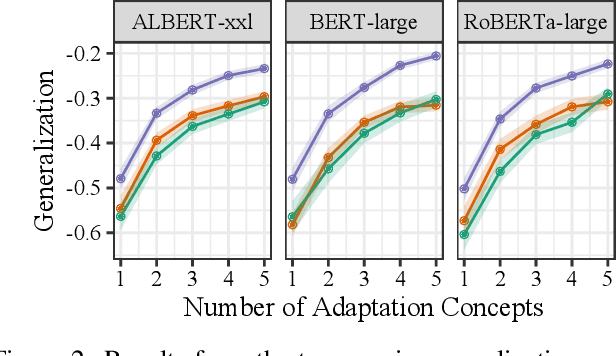
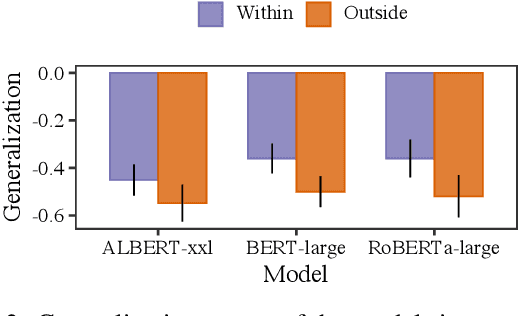
To what extent can experience from language contribute to our conceptual knowledge? Computational explorations of this question have shed light on the ability of powerful neural language models (LMs) -- informed solely through text input -- to encode and elicit information about concepts and properties. To extend this line of research, we present a framework that uses neural-network language models (LMs) to perform property induction -- a task in which humans generalize novel property knowledge (has sesamoid bones) from one or more concepts (robins) to others (sparrows, canaries). Patterns of property induction observed in humans have shed considerable light on the nature and organization of human conceptual knowledge. Inspired by this insight, we use our framework to explore the property inductions of LMs, and find that they show an inductive preference to generalize novel properties on the basis of category membership, suggesting the presence of a taxonomic bias in their representations.
Adaptive Few-Shot Learning Algorithm for Rare Sound Event Detection
May 24, 2022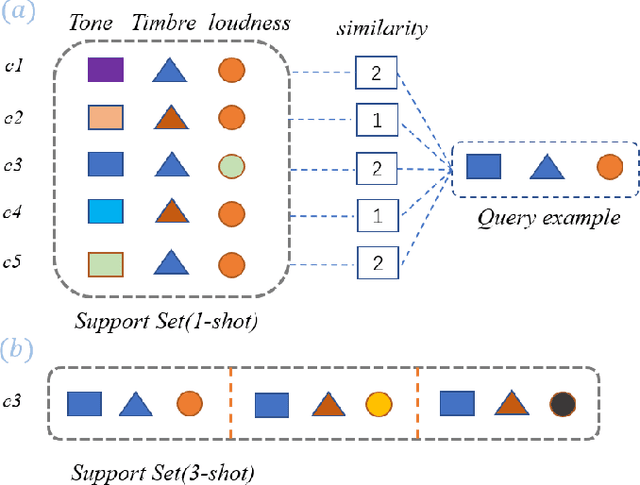
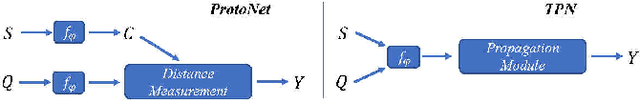
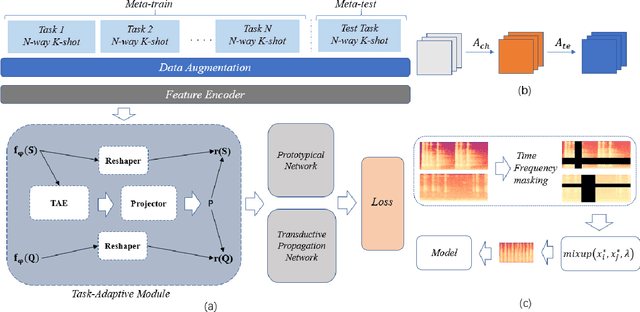
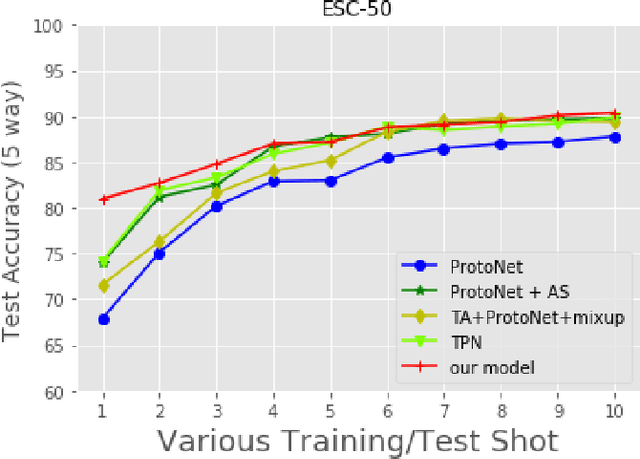
Sound event detection is to infer the event by understanding the surrounding environmental sounds. Due to the scarcity of rare sound events, it becomes challenging for the well-trained detectors which have learned too much prior knowledge. Meanwhile, few-shot learning methods promise a good generalization ability when facing a new limited-data task. Recent approaches have achieved promising results in this field. However, these approaches treat each support example independently, ignoring the information of other examples from the whole task. Because of this, most of previous methods are constrained to generate a same feature embedding for all test-time tasks, which is not adaptive to each inputted data. In this work, we propose a novel task-adaptive module which is easy to plant into any metric-based few-shot learning frameworks. The module could identify the task-relevant feature dimension. Incorporating our module improves the performance considerably on two datasets over baseline methods, especially for the transductive propagation network. Such as +6.8% for 5-way 1-shot accuracy on ESC-50, and +5.9% on noiseESC-50. We investigate our approach in the domain-mismatch setting and also achieve better results than previous methods.
HeatER: An Efficient and Unified Network for Human Reconstruction via Heatmap-based TransformER
May 30, 2022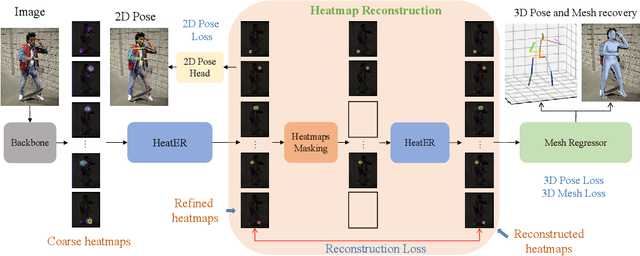
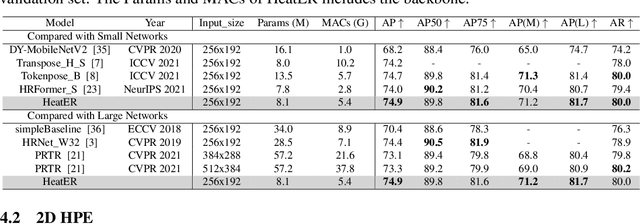
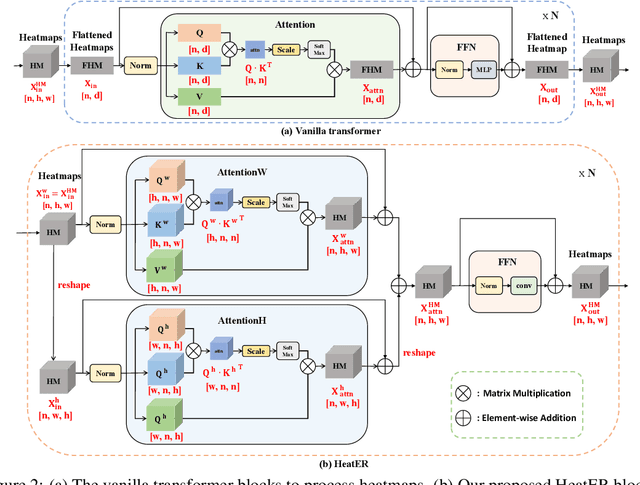
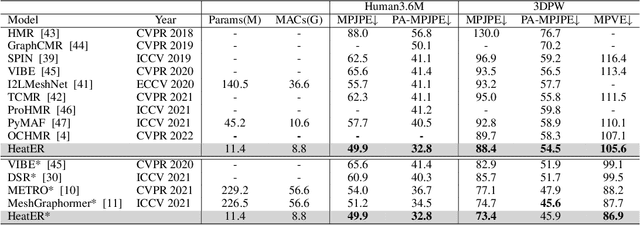
Recently, vision transformers have shown great success in 2D human pose estimation (2D HPE), 3D human pose estimation (3D HPE), and human mesh reconstruction (HMR) tasks. In these tasks, heatmap representations of the human structural information are often extracted first from the image by a CNN, and then further processed with a transformer architecture to provide the final HPE or HMR estimation. However, existing transformer architectures are not able to process these heatmap inputs directly, forcing an unnatural flattening of the features prior to input. Furthermore, much of the performance benefit in recent HPE and HMR methods has come at the cost of ever-increasing computation and memory needs. Therefore, to simultaneously address these problems, we propose HeatER, a novel transformer design which preserves the inherent structure of heatmap representations when modeling attention while reducing the memory and computational costs. Taking advantage of HeatER, we build a unified and efficient network for 2D HPE, 3D HPE, and HMR tasks. A heatmap reconstruction module is applied to improve the robustness of the estimated human pose and mesh. Extensive experiments demonstrate the effectiveness of HeatER on various human pose and mesh datasets. For instance, HeatER outperforms the SOTA method MeshGraphormer by requiring 5% of Params and 16% of MACs on Human3.6M and 3DPW datasets. Code will be publicly available.
Mixed-Timescale Deep-Unfolding for Joint Channel Estimation and Hybrid Beamforming
Jun 08, 2022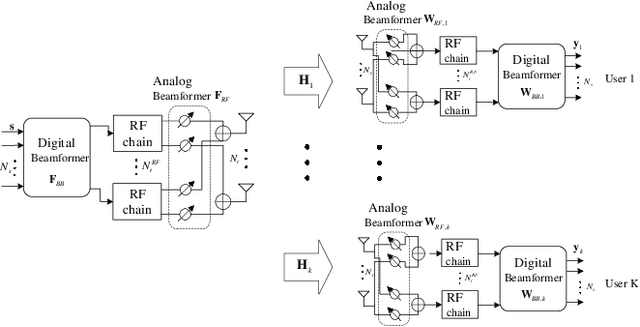
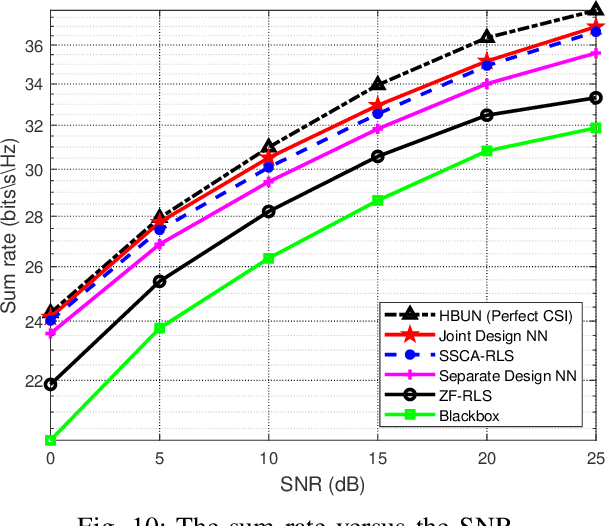
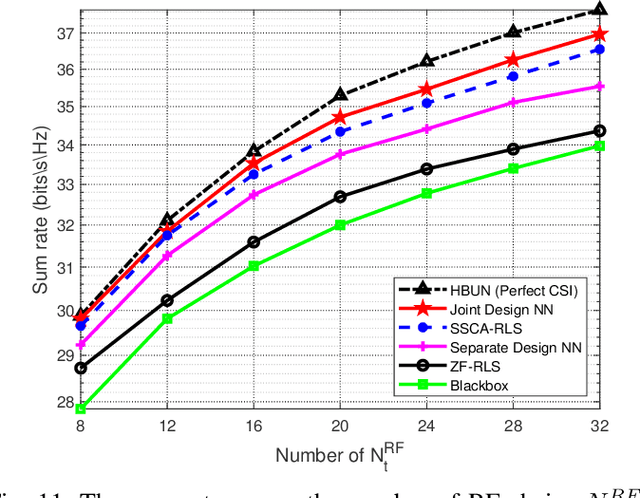
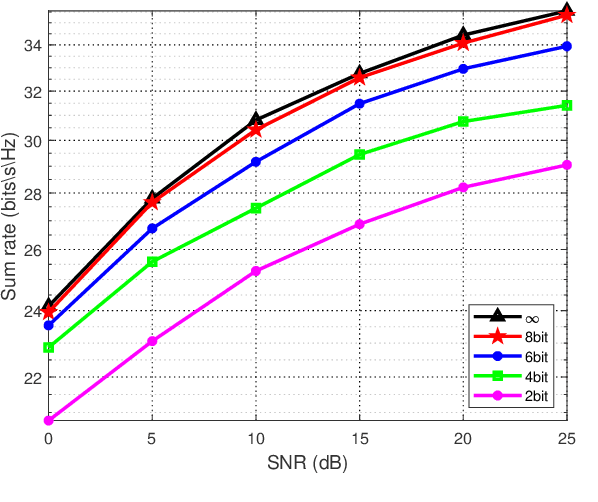
In massive multiple-input multiple-output (MIMO) systems, hybrid analog-digital beamforming is an essential technique for exploiting the potential array gain without using a dedicated radio frequency chain for each antenna. However, due to the large number of antennas, the conventional channel estimation and hybrid beamforming algorithms generally require high computational complexity and signaling overhead. In this work, we propose an end-to-end deep-unfolding neural network (NN) joint channel estimation and hybrid beamforming (JCEHB) algorithm to maximize the system sum rate in time-division duplex (TDD) massive MIMO. Specifically, the recursive least-squares (RLS) algorithm and stochastic successive convex approximation (SSCA) algorithm are unfolded for channel estimation and hybrid beamforming, respectively. In order to reduce the signaling overhead, we consider a mixed-timescale hybrid beamforming scheme, where the analog beamforming matrices are optimized based on the channel state information (CSI) statistics offline, while the digital beamforming matrices are designed at each time slot based on the estimated low-dimensional equivalent CSI matrices. We jointly train the analog beamformers together with the trainable parameters of the RLS and SSCA induced deep-unfolding NNs based on the CSI statistics offline. During data transmission, we estimate the low-dimensional equivalent CSI by the RLS induced deep-unfolding NN and update the digital beamformers. In addition, we propose a mixed-timescale deep-unfolding NN where the analog beamformers are optimized online, and extend the framework to frequency-division duplex (FDD) systems where channel feedback is considered. Simulation results show that the proposed algorithm can significantly outperform conventional algorithms with reduced computational complexity and signaling overhead.
From Easy to Hard: Two-stage Selector and Reader for Multi-hop Question Answering
May 24, 2022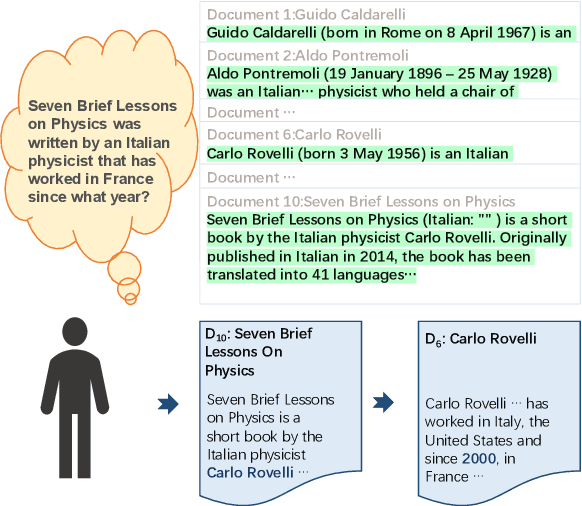
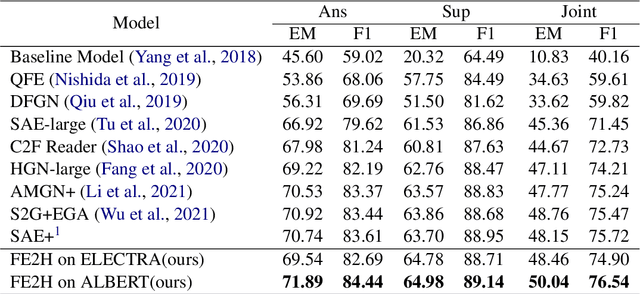
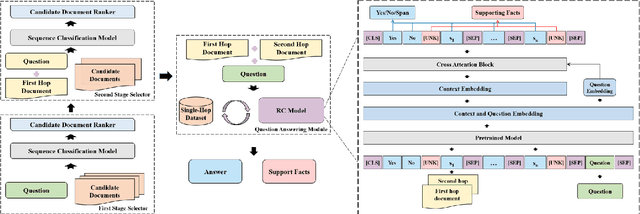
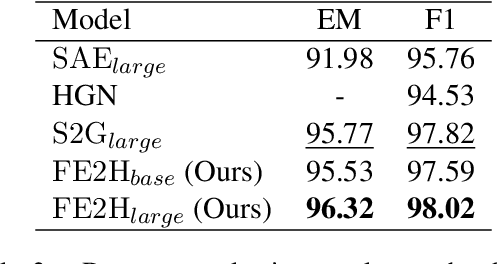
Multi-hop question answering (QA) is a challenging task requiring QA systems to perform complex reasoning over multiple documents and provide supporting facts together with the exact answer. Existing works tend to utilize graph-based reasoning and question decomposition to obtain the reasoning chain, which inevitably introduces additional complexity and cumulative error to the system. To address the above issue, we propose a simple yet effective novel framework, From Easy to Hard (FE2H), to remove distracting information and obtain better contextual representations for the multi-hop QA task. Inspired by the iterative document selection process and the progressive learning custom of humans, FE2H divides both the document selector and reader into two stages following an easy-to-hard manner. Specifically, we first select the document most relevant to the question and then utilize the question together with this document to select other pertinent documents. As for the QA phase, our reader is first trained on a single-hop QA dataset and then transferred into the multi-hop QA task. We comprehensively evaluate our model on the popular multi-hop QA benchmark HotpotQA. Experimental results demonstrate that our method ourperforms all other methods in the leaderboard of HotpotQA (distractor setting).
Inference and Sampling for Archimax Copulas
May 27, 2022

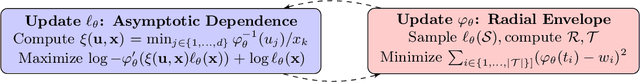

Understanding multivariate dependencies in both the bulk and the tails of a distribution is an important problem for many applications, such as ensuring algorithms are robust to observations that are infrequent but have devastating effects. Archimax copulas are a family of distributions endowed with a precise representation that allows simultaneous modeling of the bulk and the tails of a distribution. Rather than separating the two as is typically done in practice, incorporating additional information from the bulk may improve inference of the tails, where observations are limited. Building on the stochastic representation of Archimax copulas, we develop a non-parametric inference method and sampling algorithm. Our proposed methods, to the best of our knowledge, are the first that allow for highly flexible and scalable inference and sampling algorithms, enabling the increased use of Archimax copulas in practical settings. We experimentally compare to state-of-the-art density modeling techniques, and the results suggest that the proposed method effectively extrapolates to the tails while scaling to higher dimensional data. Our findings suggest that the proposed algorithms can be used in a variety of applications where understanding the interplay between the bulk and the tails of a distribution is necessary, such as healthcare and safety.