 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMATAI: A Generalist Machine Learning Framework for Property Prediction and Inverse Design of Advanced Alloys
Nov 13, 2025



The discovery of advanced metallic alloys is hindered by vast composition spaces, competing property objectives, and real-world constraints on manufacturability. Here we introduce MATAI, a generalist machine learning framework for property prediction and inverse design of as-cast alloys. MATAI integrates a curated alloy database, deep neural network-based property predictors, a constraint-aware optimization engine, and an iterative AI-experiment feedback loop. The framework estimates key mechanical propertie, sincluding density, yield strength, ultimate tensile strength, and elongation, directly from composition, using multi-task learning and physics-informed inductive biases. Alloy design is framed as a constrained optimization problem and solved using a bi-level approach that combines local search with symbolic constraint programming. We demonstrate MATAI's capabilities on the Ti-based alloy system, a canonical class of lightweight structural materials, where it rapidly identifies candidates that simultaneously achieve lower density (<4.45 g/cm3), higher strength (>1000 MPa) and appreciable ductility (>5%) through only seven iterations. Experimental validation confirms that MATAI-designed alloys outperform commercial references such as TC4, highlighting the framework's potential to accelerate the discovery of lightweight, high-performance materials under real-world design constraints.
3D Face Arbitrary Style Transfer
Mar 14, 2023



Style transfer of 3D faces has gained more and more attention. However, previous methods mainly use images of artistic faces for style transfer while ignoring arbitrary style images such as abstract paintings. To solve this problem, we propose a novel method, namely Face-guided Dual Style Transfer (FDST). To begin with, FDST employs a 3D decoupling module to separate facial geometry and texture. Then we propose a style fusion strategy for facial geometry. Subsequently, we design an optimization-based DDSG mechanism for textures that can guide the style transfer by two style images. Besides the normal style image input, DDSG can utilize the original face input as another style input as the face prior. By this means, high-quality face arbitrary style transfer results can be obtained. Furthermore, FDST can be applied in many downstream tasks, including region-controllable style transfer, high-fidelity face texture reconstruction, large-pose face reconstruction, and artistic face reconstruction. Comprehensive quantitative and qualitative results show that our method can achieve comparable performance. All source codes and pre-trained weights will be released to the public.
Learning Invariant Representation and Risk Minimized for Unsupervised Accent Domain Adaptation
Oct 15, 2022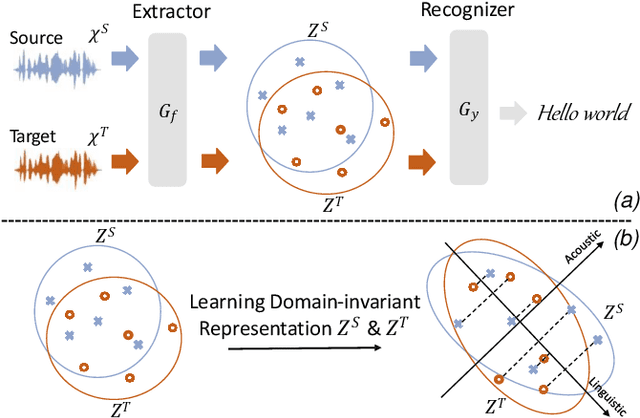
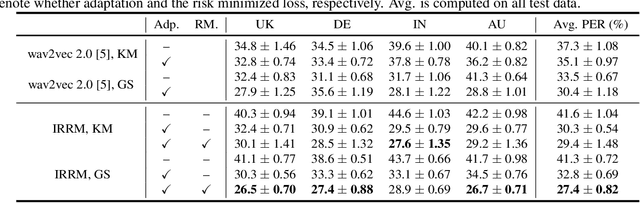
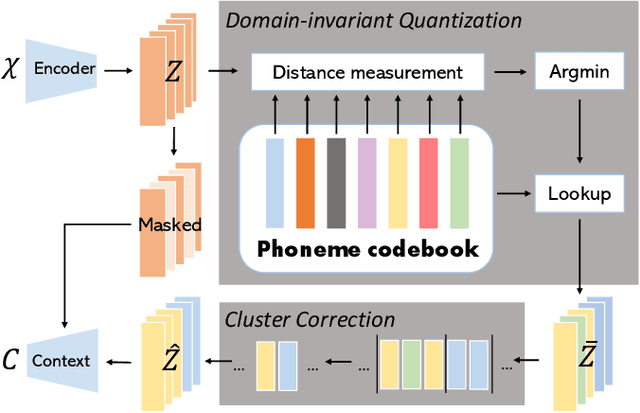

Unsupervised representation learning for speech audios attained impressive performances for speech recognition tasks, particularly when annotated speech is limited. However, the unsupervised paradigm needs to be carefully designed and little is known about what properties these representations acquire. There is no guarantee that the model learns meaningful representations for valuable information for recognition. Moreover, the adaptation ability of the learned representations to other domains still needs to be estimated. In this work, we explore learning domain-invariant representations via a direct mapping of speech representations to their corresponding high-level linguistic informations. Results prove that the learned latents not only capture the articulatory feature of each phoneme but also enhance the adaptation ability, outperforming the baseline largely on accented benchmarks.
Adaptive Sparse and Monotonic Attention for Transformer-based Automatic Speech Recognition
Sep 30, 2022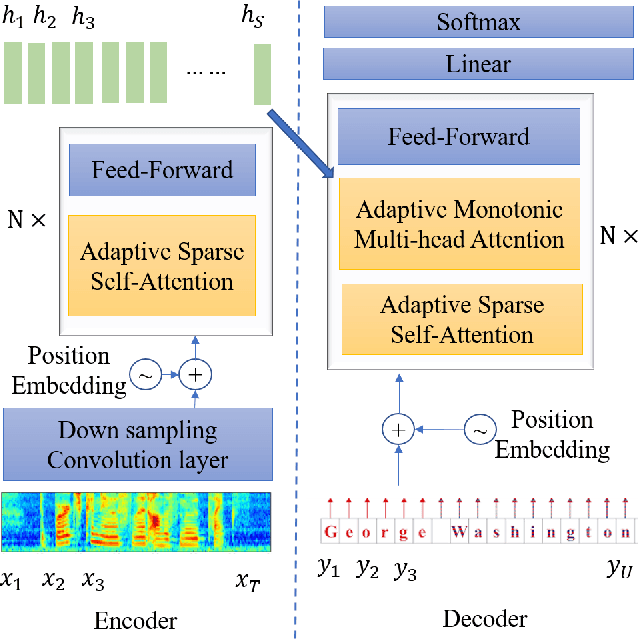
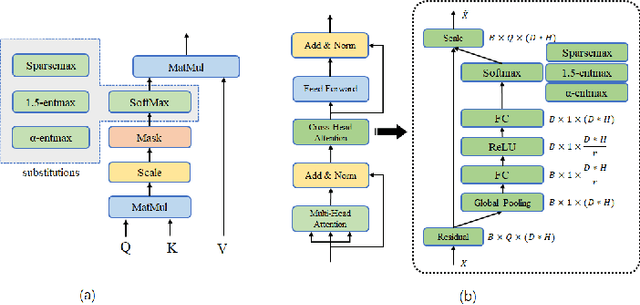
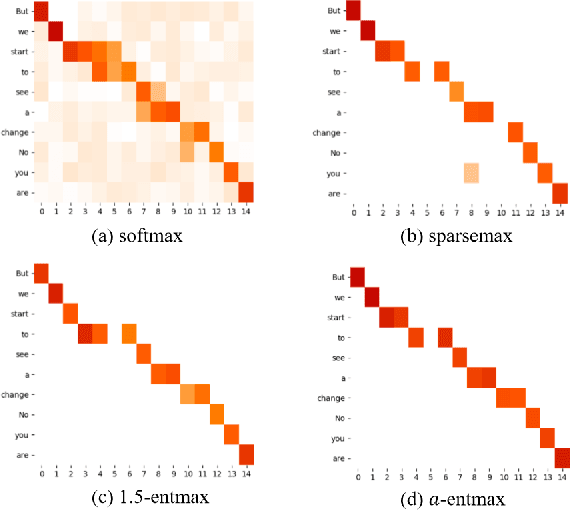
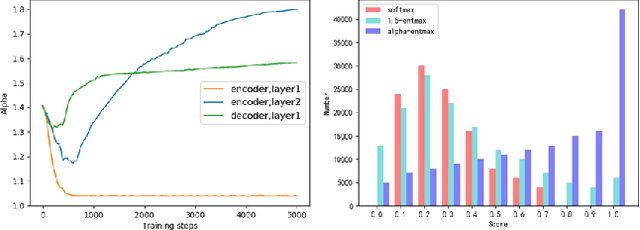
The Transformer architecture model, based on self-attention and multi-head attention, has achieved remarkable success in offline end-to-end Automatic Speech Recognition (ASR). However, self-attention and multi-head attention cannot be easily applied for streaming or online ASR. For self-attention in Transformer ASR, the softmax normalization function-based attention mechanism makes it impossible to highlight important speech information. For multi-head attention in Transformer ASR, it is not easy to model monotonic alignments in different heads. To overcome these two limits, we integrate sparse attention and monotonic attention into Transformer-based ASR. The sparse mechanism introduces a learned sparsity scheme to enable each self-attention structure to fit the corresponding head better. The monotonic attention deploys regularization to prune redundant heads for the multi-head attention structure. The experiments show that our method can effectively improve the attention mechanism on widely used benchmarks of speech recognition.
DT-SV: A Transformer-based Time-domain Approach for Speaker Verification
May 26, 2022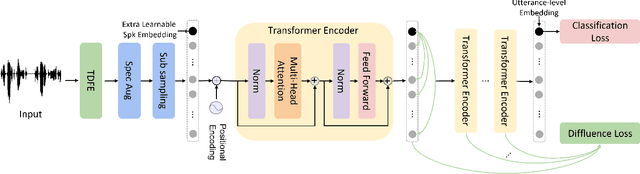
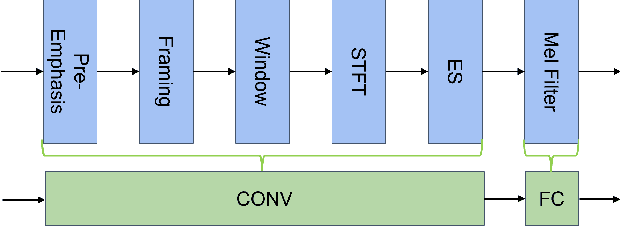
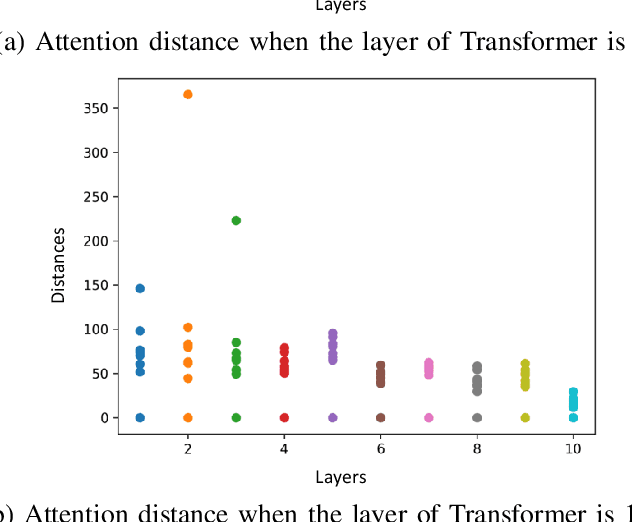
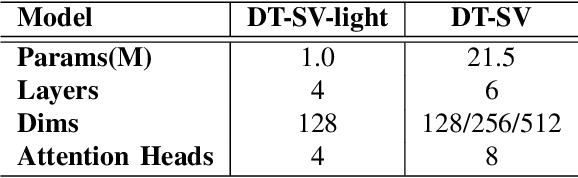
Speaker verification (SV) aims to determine whether the speaker's identity of a test utterance is the same as the reference speech. In the past few years, extracting speaker embeddings using deep neural networks for SV systems has gone mainstream. Recently, different attention mechanisms and Transformer networks have been explored widely in SV fields. However, utilizing the original Transformer in SV directly may have frame-level information waste on output features, which could lead to restrictions on capacity and discrimination of speaker embeddings. Therefore, we propose an approach to derive utterance-level speaker embeddings via a Transformer architecture that uses a novel loss function named diffluence loss to integrate the feature information of different Transformer layers. Therein, the diffluence loss aims to aggregate frame-level features into an utterance-level representation, and it could be integrated into the Transformer expediently. Besides, we also introduce a learnable mel-fbank energy feature extractor named time-domain feature extractor that computes the mel-fbank features more precisely and efficiently than the standard mel-fbank extractor. Combining Diffluence loss and Time-domain feature extractor, we propose a novel Transformer-based time-domain SV model (DT-SV) with faster training speed and higher accuracy. Experiments indicate that our proposed model can achieve better performance in comparison with other models.
QSpeech: Low-Qubit Quantum Speech Application Toolkit
May 26, 2022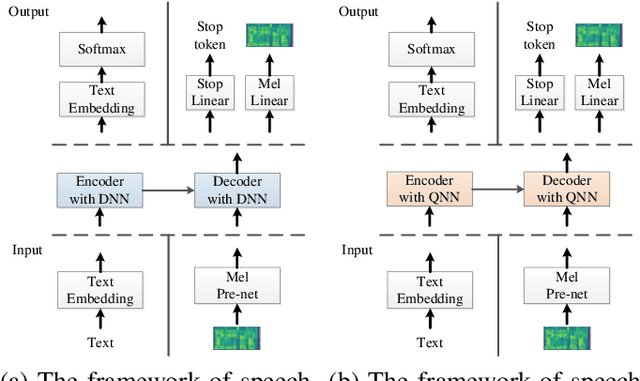
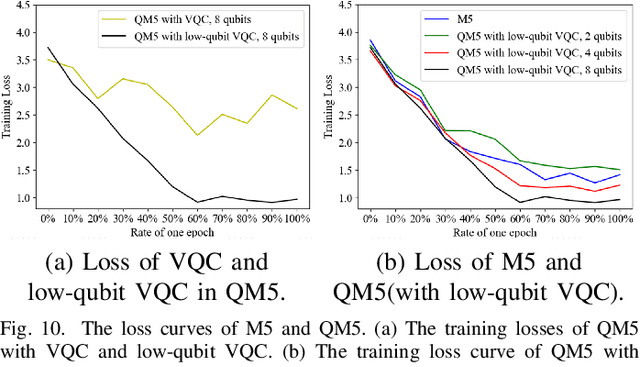
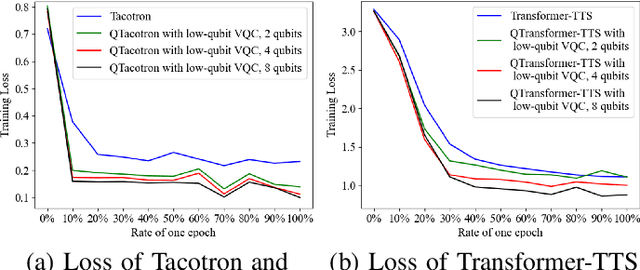
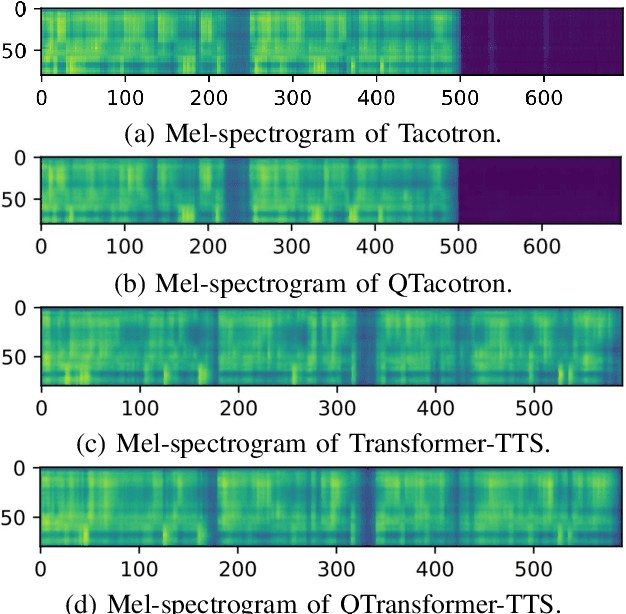
Quantum devices with low qubits are common in the Noisy Intermediate-Scale Quantum (NISQ) era. However, Quantum Neural Network (QNN) running on low-qubit quantum devices would be difficult since it is based on Variational Quantum Circuit (VQC), which requires many qubits. Therefore, it is critical to make QNN with VQC run on low-qubit quantum devices. In this study, we propose a novel VQC called the low-qubit VQC. VQC requires numerous qubits based on the input dimension; however, the low-qubit VQC with linear transformation can liberate this condition. Thus, it allows the QNN to run on low-qubit quantum devices for speech applications. Furthermore, as compared to the VQC, our proposed low-qubit VQC can stabilize the training process more. Based on the low-qubit VQC, we implement QSpeech, a library for quick prototyping of hybrid quantum-classical neural networks in the speech field. It has numerous quantum neural layers and QNN models for speech applications. Experiments on Speech Command Recognition and Text-to-Speech show that our proposed low-qubit VQC outperforms VQC and is more stable.
Adaptive Few-Shot Learning Algorithm for Rare Sound Event Detection
May 26, 2022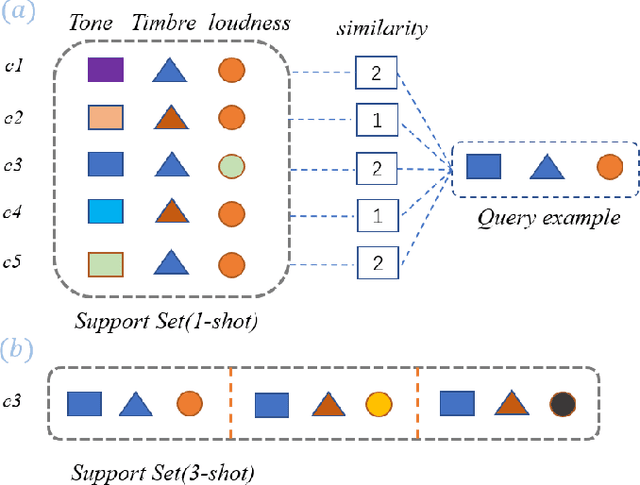
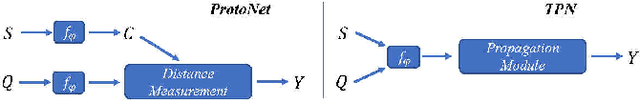
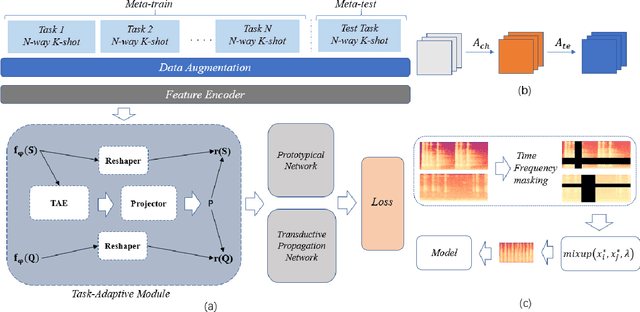
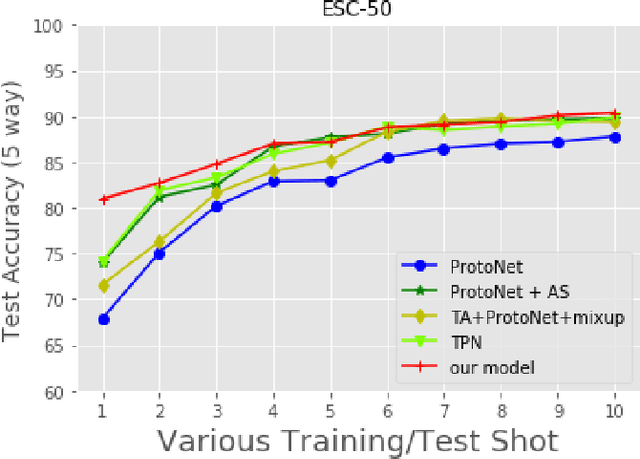
Sound event detection is to infer the event by understanding the surrounding environmental sounds. Due to the scarcity of rare sound events, it becomes challenging for the well-trained detectors which have learned too much prior knowledge. Meanwhile, few-shot learning methods promise a good generalization ability when facing a new limited-data task. Recent approaches have achieved promising results in this field. However, these approaches treat each support example independently, ignoring the information of other examples from the whole task. Because of this, most of previous methods are constrained to generate a same feature embedding for all test-time tasks, which is not adaptive to each inputted data. In this work, we propose a novel task-adaptive module which is easy to plant into any metric-based few-shot learning frameworks. The module could identify the task-relevant feature dimension. Incorporating our module improves the performance considerably on two datasets over baseline methods, especially for the transductive propagation network. Such as +6.8% for 5-way 1-shot accuracy on ESC-50, and +5.9% on noiseESC-50. We investigate our approach in the domain-mismatch setting and also achieve better results than previous methods.
r-G2P: Evaluating and Enhancing Robustness of Grapheme to Phoneme Conversion by Controlled noise introducing and Contextual information incorporation
Feb 21, 2022
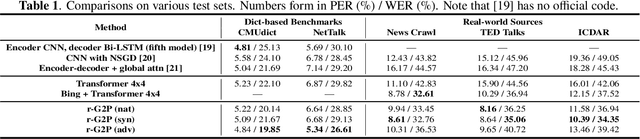
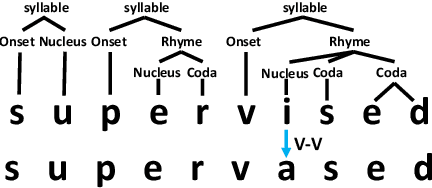
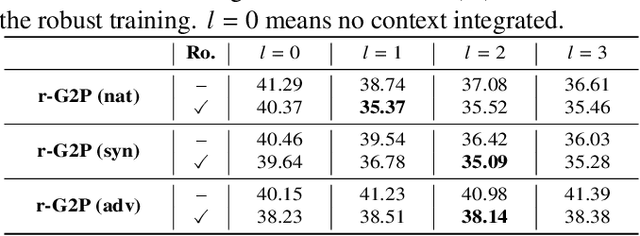
Grapheme-to-phoneme (G2P) conversion is the process of converting the written form of words to their pronunciations. It has an important role for text-to-speech (TTS) synthesis and automatic speech recognition (ASR) systems. In this paper, we aim to evaluate and enhance the robustness of G2P models. We show that neural G2P models are extremely sensitive to orthographical variations in graphemes like spelling mistakes. To solve this problem, we propose three controlled noise introducing methods to synthesize noisy training data. Moreover, we incorporate the contextual information with the baseline and propose a robust training strategy to stabilize the training process. The experimental results demonstrate that our proposed robust G2P model (r-G2P) outperforms the baseline significantly (-2.73\% WER on Dict-based benchmarks and -9.09\% WER on Real-world sources).
Federated Learning with Dynamic Transformer for Text to Speech
Jul 09, 2021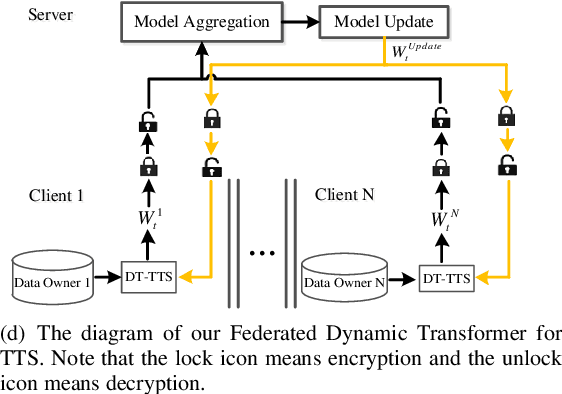

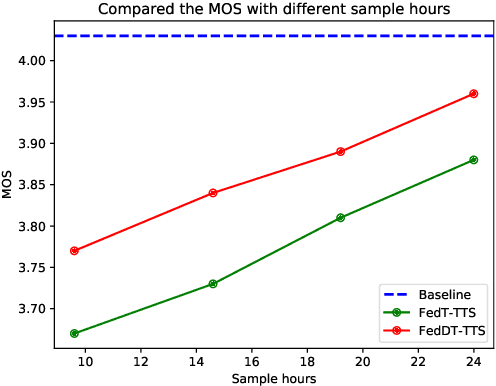
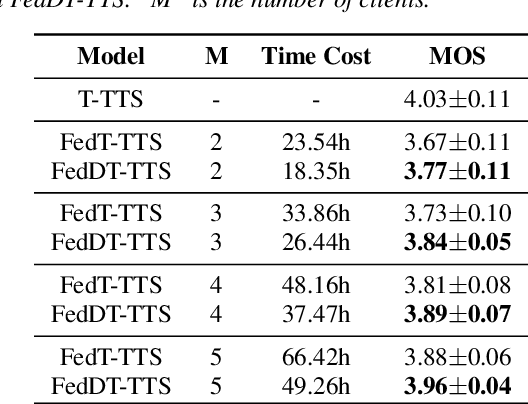
Text to speech (TTS) is a crucial task for user interaction, but TTS model training relies on a sizable set of high-quality original datasets. Due to privacy and security issues, the original datasets are usually unavailable directly. Recently, federated learning proposes a popular distributed machine learning paradigm with an enhanced privacy protection mechanism. It offers a practical and secure framework for data owners to collaborate with others, thus obtaining a better global model trained on the larger dataset. However, due to the high complexity of transformer models, the convergence process becomes slow and unstable in the federated learning setting. Besides, the transformer model trained in federated learning is costly communication and limited computational speed on clients, impeding its popularity. To deal with these challenges, we propose the federated dynamic transformer. On the one hand, the performance is greatly improved comparing with the federated transformer, approaching centralize-trained Transformer-TTS when increasing clients number. On the other hand, it achieves faster and more stable convergence in the training phase and significantly reduces communication time. Experiments on the LJSpeech dataset also strongly prove our method's advantage.