 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Diffractive Interconnects: All-Optical Permutation Operation Using Diffractive Networks
Jun 21, 2022
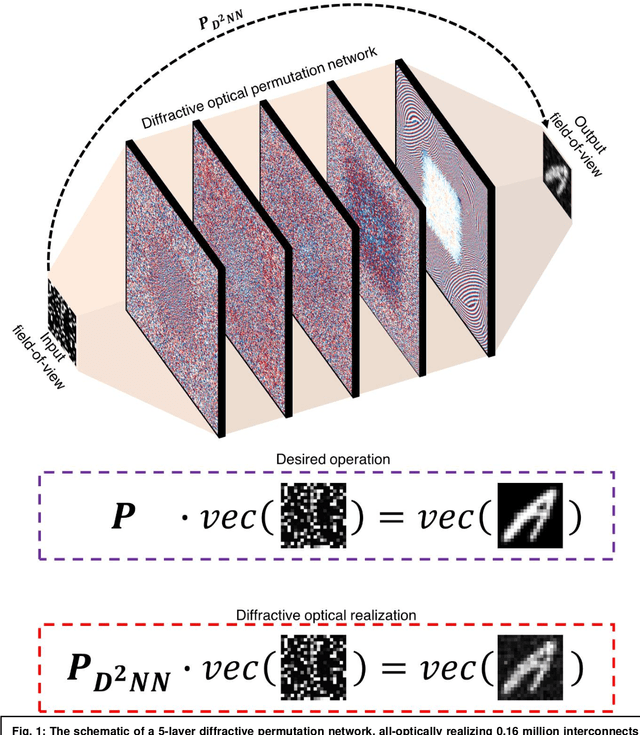
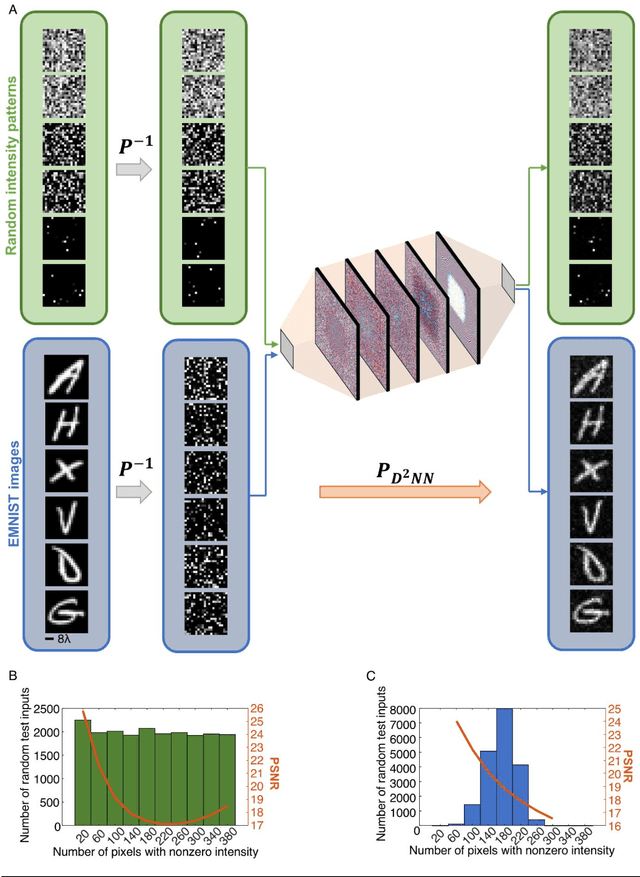
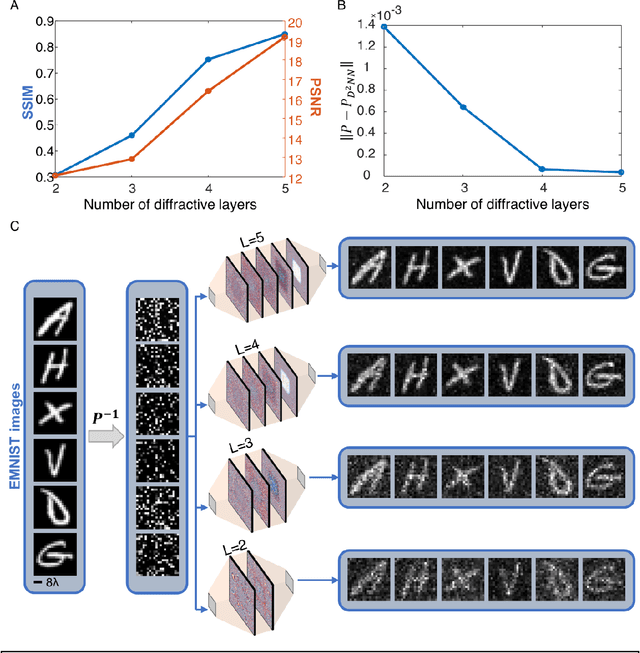
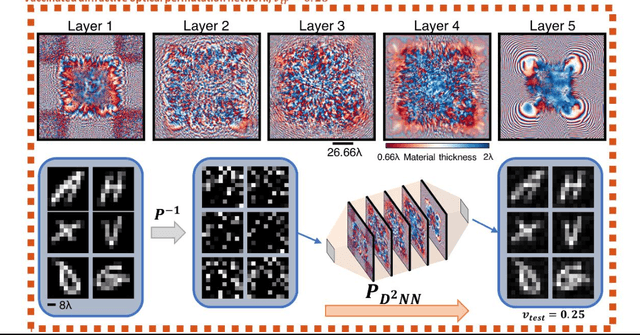
Permutation matrices form an important computational building block frequently used in various fields including e.g., communications, information security and data processing. Optical implementation of permutation operators with relatively large number of input-output interconnections based on power-efficient, fast, and compact platforms is highly desirable. Here, we present diffractive optical networks engineered through deep learning to all-optically perform permutation operations that can scale to hundreds of thousands of interconnections between an input and an output field-of-view using passive transmissive layers that are individually structured at the wavelength scale. Our findings indicate that the capacity of the diffractive optical network in approximating a given permutation operation increases proportional to the number of diffractive layers and trainable transmission elements in the system. Such deeper diffractive network designs can pose practical challenges in terms of physical alignment and output diffraction efficiency of the system. We addressed these challenges by designing misalignment tolerant diffractive designs that can all-optically perform arbitrarily-selected permutation operations, and experimentally demonstrated, for the first time, a diffractive permutation network that operates at THz part of the spectrum. Diffractive permutation networks might find various applications in e.g., security, image encryption and data processing, along with telecommunications; especially with the carrier frequencies in wireless communications approaching THz-bands, the presented diffractive permutation networks can potentially serve as channel routing and interconnection panels in wireless networks.
Person-job fit estimation from candidate profile and related recruitment history with co-attention neural networks
Jun 18, 2022
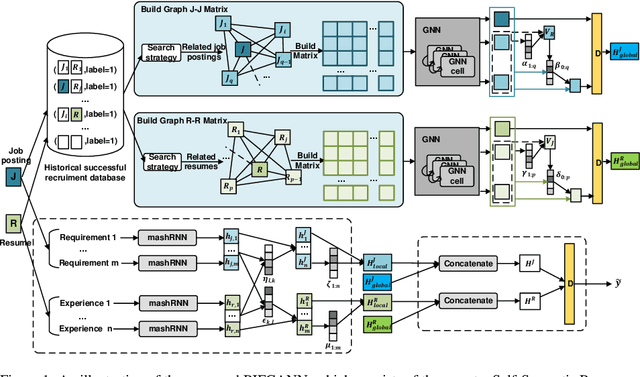
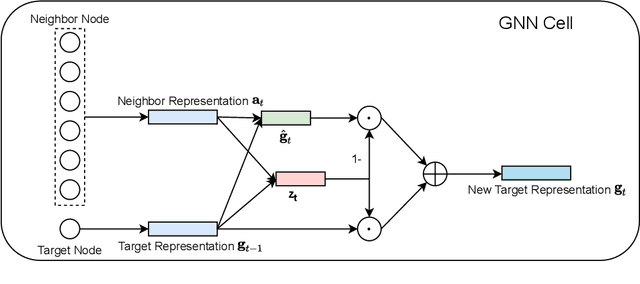
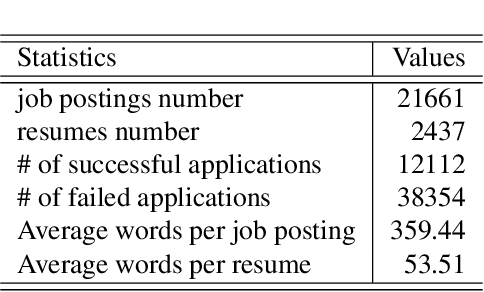
Existing online recruitment platforms depend on automatic ways of conducting the person-job fit, whose goal is matching appropriate job seekers with job positions. Intuitively, the previous successful recruitment records contain important information, which should be helpful for the current person-job fit. Existing studies on person-job fit, however, mainly focus on calculating the similarity between the candidate resumes and the job postings on the basis of their contents, without taking the recruiters' experience (i.e., historical successful recruitment records) into consideration. In this paper, we propose a novel neural network approach for person-job fit, which estimates person-job fit from candidate profile and related recruitment history with co-attention neural networks (named PJFCANN). Specifically, given a target resume-job post pair, PJFCANN generates local semantic representations through co-attention neural networks and global experience representations via graph neural networks. The final matching degree is calculated by combining these two representations. In this way, the historical successful recruitment records are introduced to enrich the features of resumes and job postings and strengthen the current matching process. Extensive experiments conducted on a large-scale recruitment dataset verify the effectiveness of PJFCANN compared with several state-of-the-art baselines. The codes are released at: https://github.com/CCIIPLab/PJFCANN.
Pre-training Enhanced Spatial-temporal Graph Neural Network for Multivariate Time Series Forecasting
Jun 18, 2022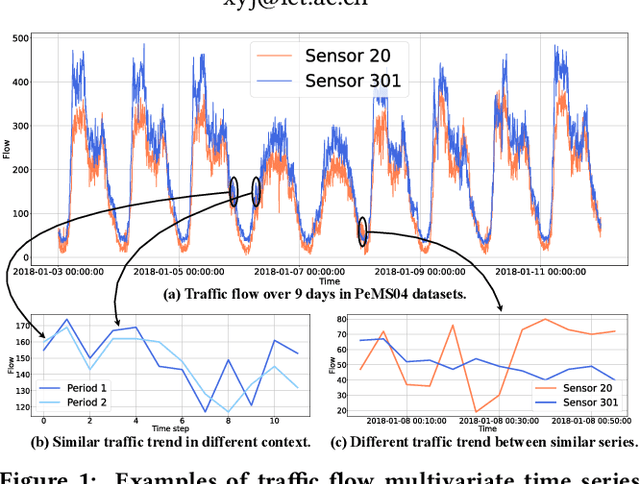
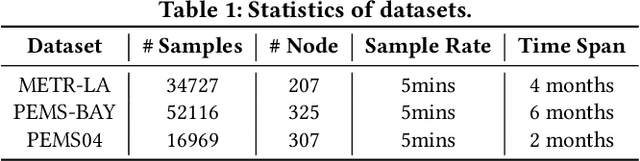
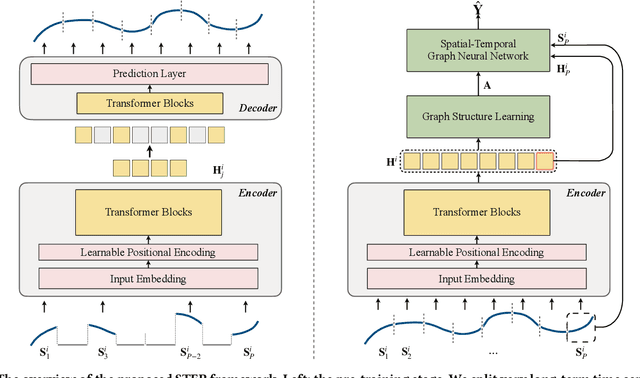
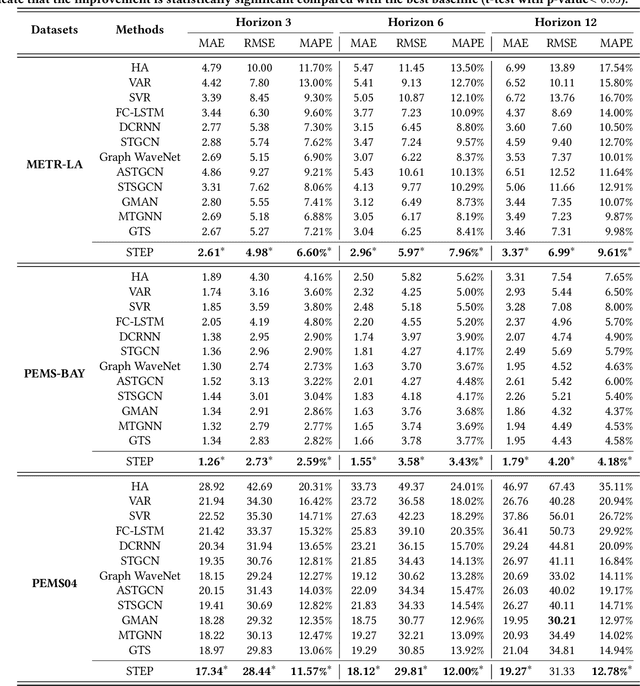
Multivariate Time Series (MTS) forecasting plays a vital role in a wide range of applications. Recently, Spatial-Temporal Graph Neural Networks (STGNNs) have become increasingly popular MTS forecasting methods. STGNNs jointly model the spatial and temporal patterns of MTS through graph neural networks and sequential models, significantly improving the prediction accuracy. But limited by model complexity, most STGNNs only consider short-term historical MTS data, such as data over the past one hour. However, the patterns of time series and the dependencies between them (i.e., the temporal and spatial patterns) need to be analyzed based on long-term historical MTS data. To address this issue, we propose a novel framework, in which STGNN is Enhanced by a scalable time series Pre-training model (STEP). Specifically, we design a pre-training model to efficiently learn temporal patterns from very long-term history time series (e.g., the past two weeks) and generate segment-level representations. These representations provide contextual information for short-term time series input to STGNNs and facilitate modeling dependencies between time series. Experiments on three public real-world datasets demonstrate that our framework is capable of significantly enhancing downstream STGNNs, and our pre-training model aptly captures temporal patterns.
A Demographic Attribute Guided Approach to Age Estimation
May 20, 2022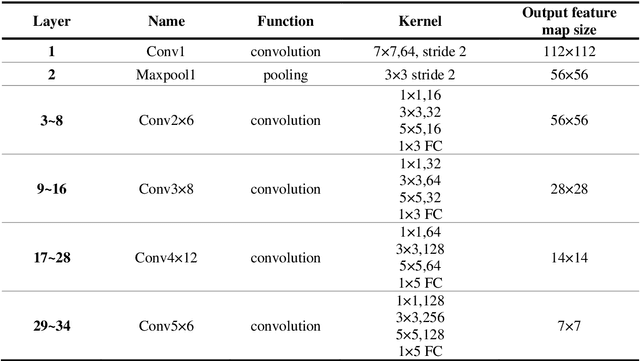
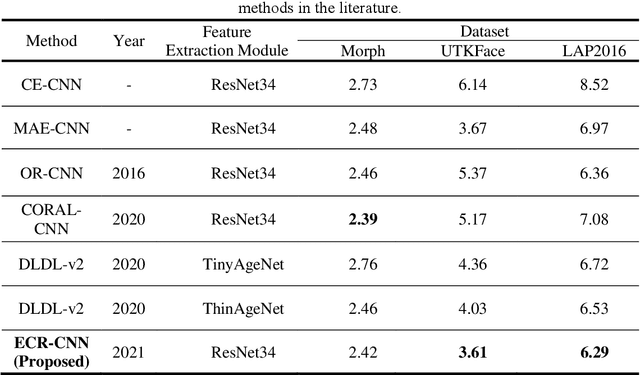
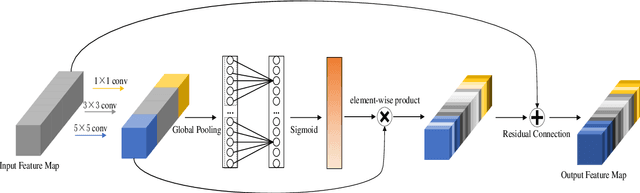
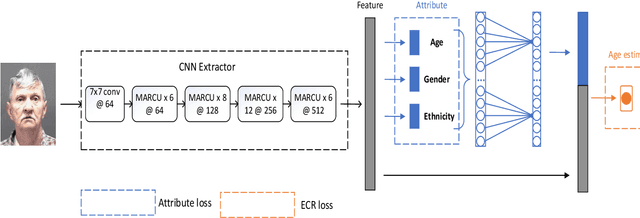
Face-based age estimation has attracted enormous attention due to wide applications to public security surveillance, human-computer interaction, etc. With vigorous development of deep learning, age estimation based on deep neural network has become the mainstream practice. However, seeking a more suitable problem paradigm for age change characteristics, designing the corresponding loss function and designing a more effective feature extraction module still needs to be studied. What is more, change of face age is also related to demographic attributes such as ethnicity and gender, and the dynamics of different age groups is also quite different. This problem has so far not been paid enough attention to. How to use demographic attribute information to improve the performance of age estimation remains to be further explored. In light of these issues, this research makes full use of auxiliary information of face attributes and proposes a new age estimation approach with an attribute guidance module. We first design a multi-scale attention residual convolution unit (MARCU) to extract robust facial features other than simply using other standard feature modules such as VGG and ResNet. Then, after being especially treated through full connection (FC) layers, the facial demographic attributes are weight-summed by 1*1 convolutional layer and eventually merged with the age features by a global FC layer. Lastly, we propose a new error compression ranking (ECR) loss to better converge the age regression value. Experimental results on three public datasets of UTKFace, LAP2016 and Morph show that our proposed approach achieves superior performance compared to other state-of-the-art methods.
Bridging the Gap Between Indexing and Retrieval for Differentiable Search Index with Query Generation
Jun 21, 2022
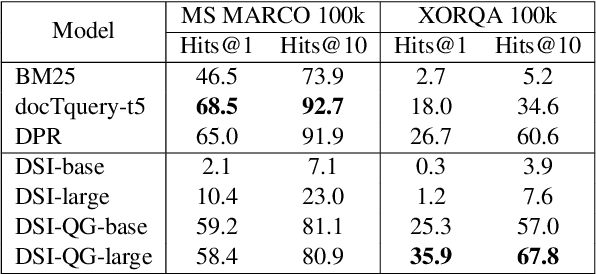
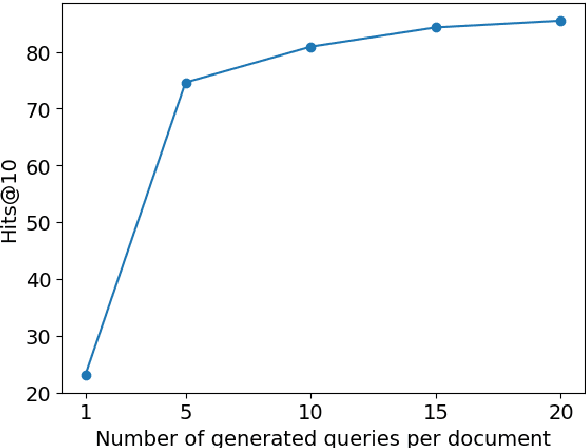
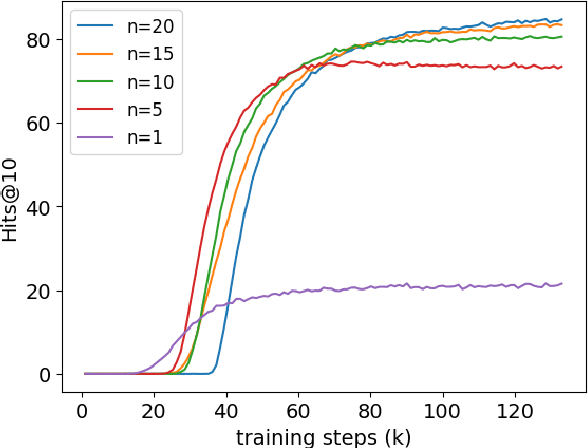
The Differentiable Search Index (DSI) is a new, emerging paradigm for information retrieval. Unlike traditional retrieval architectures where index and retrieval are two different and separate components, DSI uses a single transformer model to perform both indexing and retrieval. In this paper, we identify and tackle an important issue of current DSI models: the data distribution mismatch that occurs between the DSI indexing and retrieval processes. Specifically, we argue that, at indexing, current DSI methods learn to build connections between long document texts and their identifies, but then at retrieval, short query texts are provided to DSI models to perform the retrieval of the document identifiers. This problem is further exacerbated when using DSI for cross-lingual retrieval, where document text and query text are in different languages. To address this fundamental problem of current DSI models we propose a simple yet effective indexing framework for DSI called DSI-QG. In DSI-QG, documents are represented by a number of relevant queries generated by a query generation model at indexing time. This allows DSI models to connect a document identifier to a set of query texts when indexing, hence mitigating data distribution mismatches present between the indexing and the retrieval phases. Empirical results on popular mono-lingual and cross-lingual passage retrieval benchmark datasets show that DSI-QG significantly outperforms the original DSI model.
Near-Infrared Depth-Independent Image Dehazing using Haar Wavelets
Mar 26, 2022
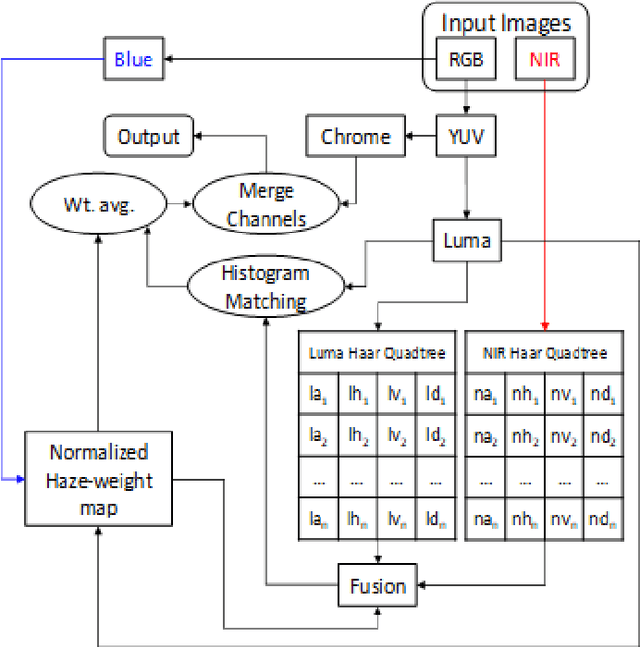
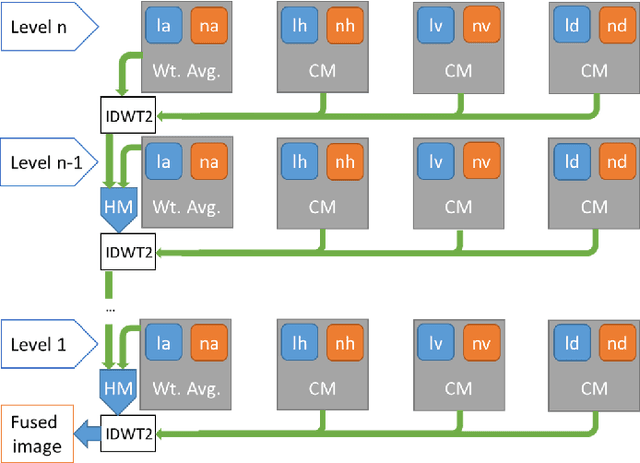
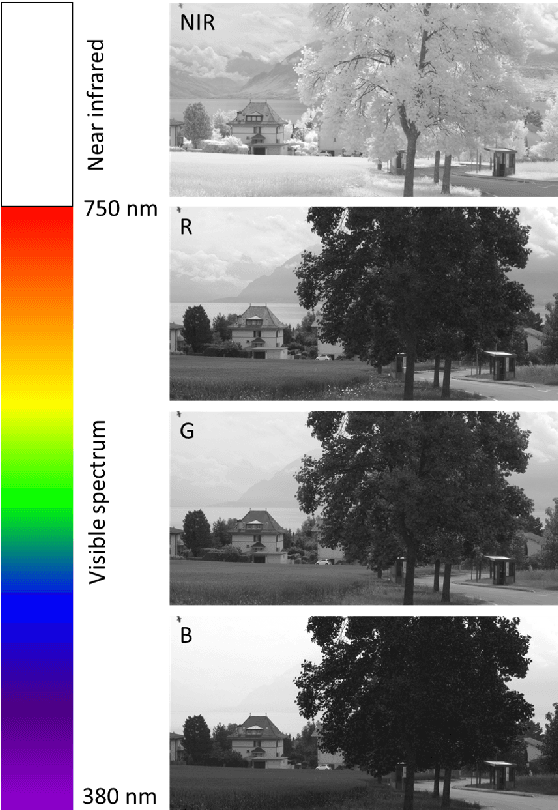
We propose a fusion algorithm for haze removal that combines color information from an RGB image and edge information extracted from its corresponding NIR image using Haar wavelets. The proposed algorithm is based on the key observation that NIR edge features are more prominent in the hazy regions of the image than the RGB edge features in those same regions. To combine the color and edge information, we introduce a haze-weight map which proportionately distributes the color and edge information during the fusion process. Because NIR images are, intrinsically, nearly haze-free, our work makes no assumptions like existing works that rely on a scattering model and essentially designing a depth-independent method. This helps in minimizing artifacts and gives a more realistic sense to the restored haze-free image. Extensive experiments show that the proposed algorithm is both qualitatively and quantitatively better on several key metrics when compared to existing state-of-the-art methods.
* Accepted in 25th International Conference on Pattern Recognition (ICPR 2020)
Cross-modal Representation Learning for Zero-shot Action Recognition
May 03, 2022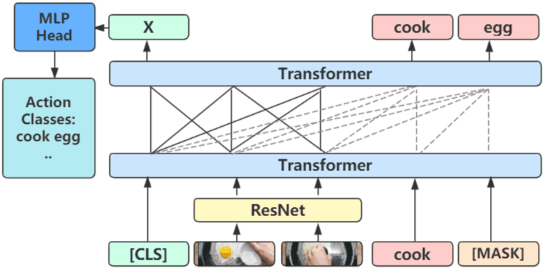
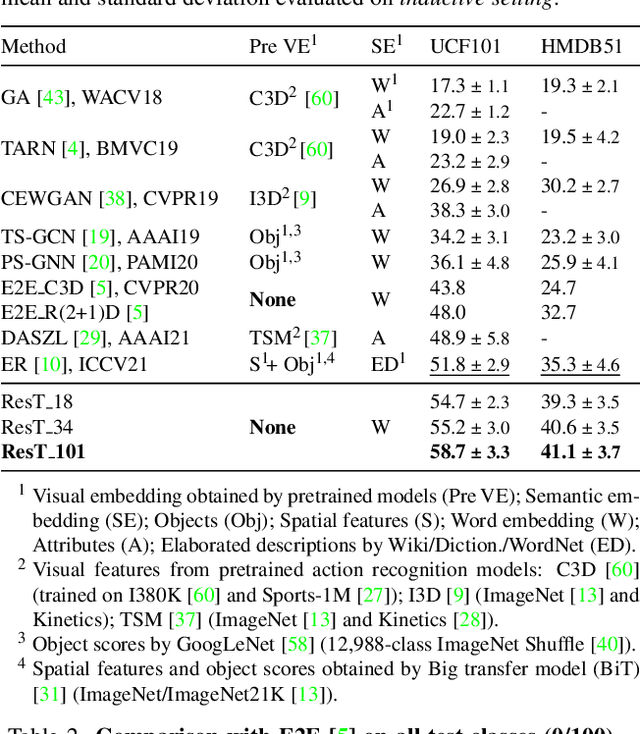
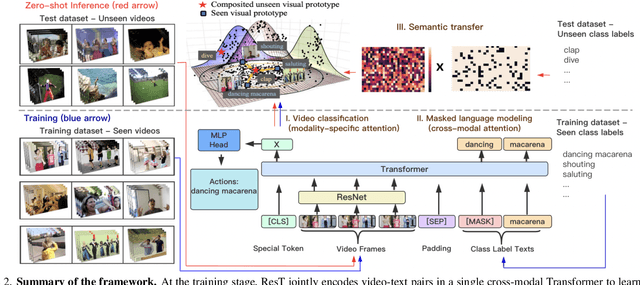
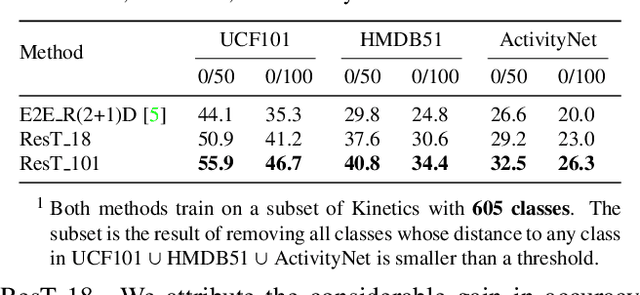
We present a cross-modal Transformer-based framework, which jointly encodes video data and text labels for zero-shot action recognition (ZSAR). Our model employs a conceptually new pipeline by which visual representations are learned in conjunction with visual-semantic associations in an end-to-end manner. The model design provides a natural mechanism for visual and semantic representations to be learned in a shared knowledge space, whereby it encourages the learned visual embedding to be discriminative and more semantically consistent. In zero-shot inference, we devise a simple semantic transfer scheme that embeds semantic relatedness information between seen and unseen classes to composite unseen visual prototypes. Accordingly, the discriminative features in the visual structure could be preserved and exploited to alleviate the typical zero-shot issues of information loss, semantic gap, and the hubness problem. Under a rigorous zero-shot setting of not pre-training on additional datasets, the experiment results show our model considerably improves upon the state of the arts in ZSAR, reaching encouraging top-1 accuracy on UCF101, HMDB51, and ActivityNet benchmark datasets. Code will be made available.
Leveraging Pre-Trained Language Models to Streamline Natural Language Interaction for Self-Tracking
Jun 07, 2022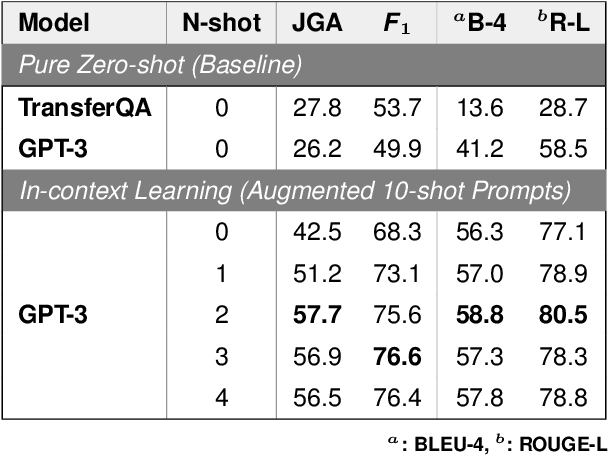
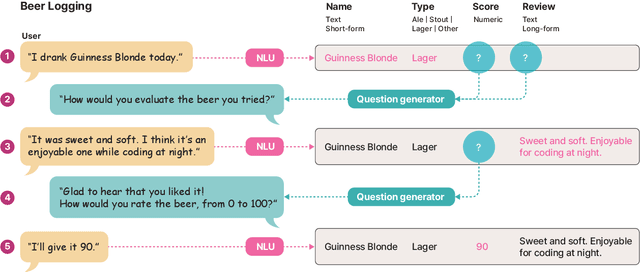
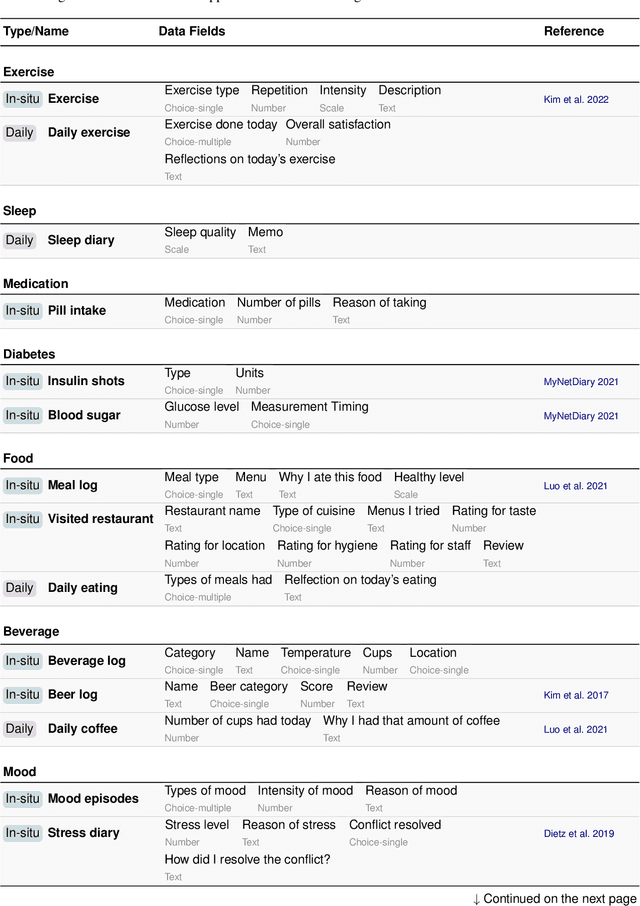
Current natural language interaction for self-tracking tools largely depends on bespoke implementation optimized for a specific tracking theme and data format, which is neither generalizable nor scalable to a tremendous design space of self-tracking. However, training machine learning models in the context of self-tracking is challenging due to the wide variety of tracking topics and data formats. In this paper, we propose a novel NLP task for self-tracking that extracts close- and open-ended information from a retrospective activity log described as a plain text, and a domain-agnostic, GPT-3-based NLU framework that performs this task. The framework augments the prompt using synthetic samples to transform the task into 10-shot learning, to address a cold-start problem in bootstrapping a new tracking topic. Our preliminary evaluation suggests that our approach significantly outperforms the baseline QA models. Going further, we discuss future application domains toward which the NLP and HCI researchers can collaborate.
DcnnGrasp: Towards Accurate Grasp Pattern Recognition with Adaptive Regularizer Learning
May 11, 2022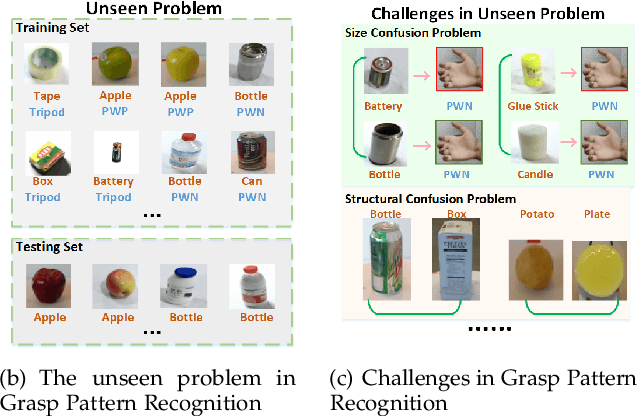

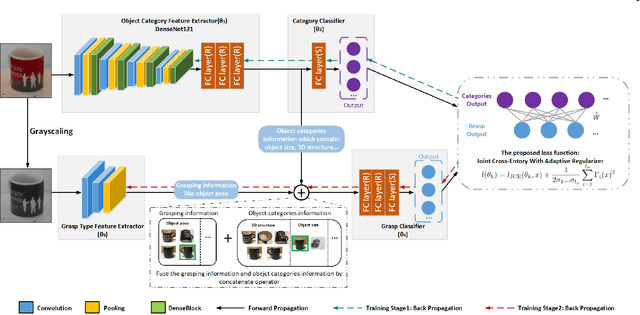

The task of grasp pattern recognition aims to derive the applicable grasp types of an object according to the visual information. Current state-of-the-art methods ignore category information of objects which is crucial for grasp pattern recognition. This paper presents a novel dual-branch convolutional neural network (DcnnGrasp) to achieve joint learning of object category classification and grasp pattern recognition. DcnnGrasp takes object category classification as an auxiliary task to improve the effectiveness of grasp pattern recognition. Meanwhile, a new loss function called joint cross-entropy with an adaptive regularizer is derived through maximizing a posterior, which significantly improves the model performance. Besides, based on the new loss function, a training strategy is proposed to maximize the collaborative learning of the two tasks. The experiment was performed on five household objects datasets including the RGB-D Object dataset, Hit-GPRec dataset, Amsterdam library of object images (ALOI), Columbia University Image Library (COIL-100), and MeganePro dataset 1. The experimental results demonstrated that the proposed method can achieve competitive performance on grasp pattern recognition with several state-of-the-art methods. Specifically, our method even outperformed the second-best one by nearly 15% in terms of global accuracy for the case of testing a novel object on the RGB-D Object dataset.
Speech Emotion Recognition with Global-Aware Fusion on Multi-scale Feature Representation
Apr 12, 2022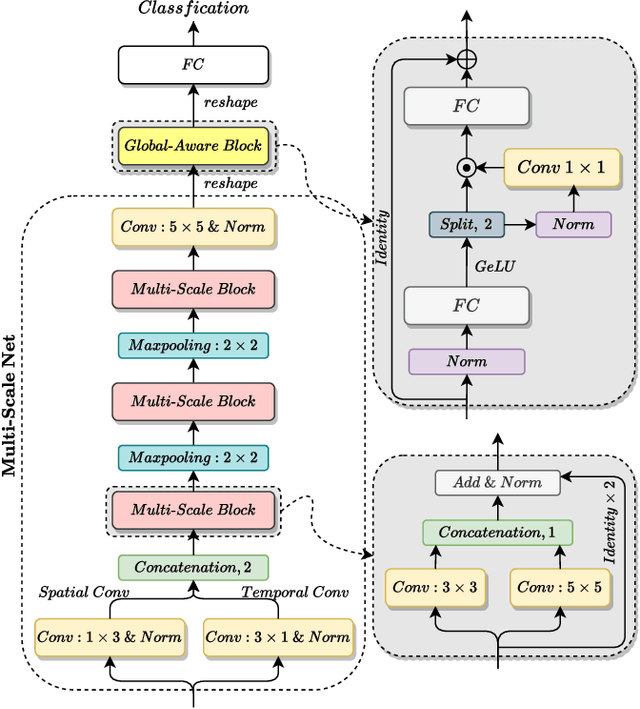
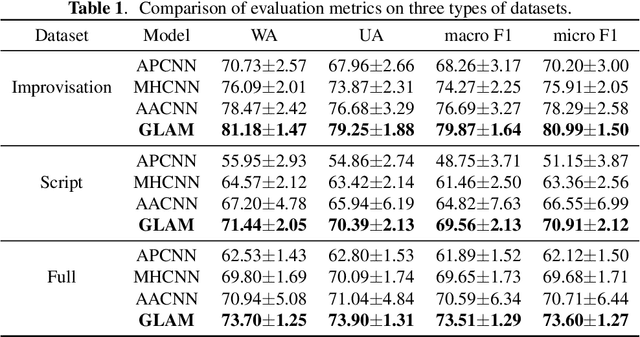
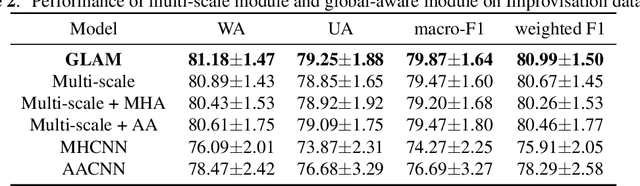
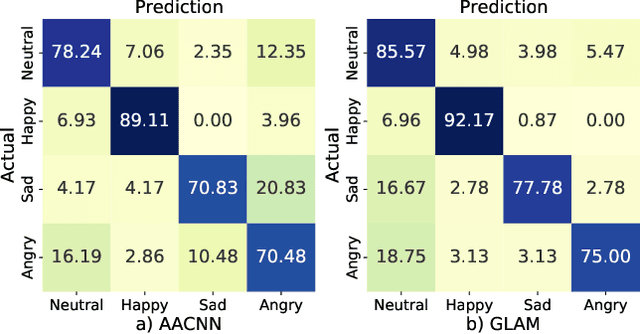
Speech Emotion Recognition (SER) is a fundamental task to predict the emotion label from speech data. Recent works mostly focus on using convolutional neural networks~(CNNs) to learn local attention map on fixed-scale feature representation by viewing time-varied spectral features as images. However, rich emotional feature at different scales and important global information are not able to be well captured due to the limits of existing CNNs for SER. In this paper, we propose a novel GLobal-Aware Multi-scale (GLAM) neural network (The code is available at https://github.com/lixiangucas01/GLAM) to learn multi-scale feature representation with global-aware fusion module to attend emotional information. Specifically, GLAM iteratively utilizes multiple convolutional kernels with different scales to learn multiple feature representation. Then, instead of using attention-based methods, a simple but effective global-aware fusion module is applied to grab most important emotional information globally. Experiments on the benchmark corpus IEMOCAP over four emotions demonstrates the superiority of our proposed model with 2.5% to 4.5% improvements on four common metrics compared to previous state-of-the-art approaches.