 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
MULTIPAR: Supervised Irregular Tensor Factorization with Multi-task Learning
Aug 01, 2022
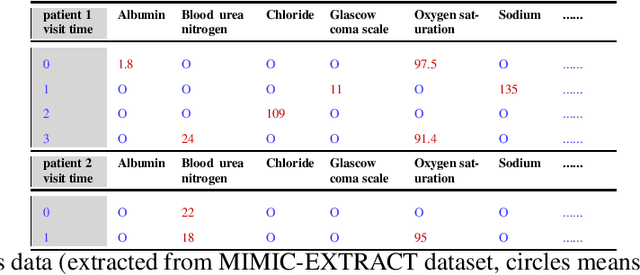
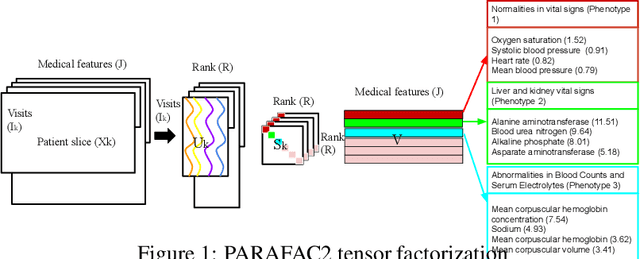
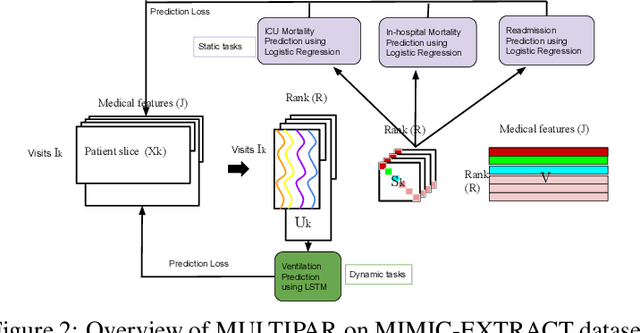
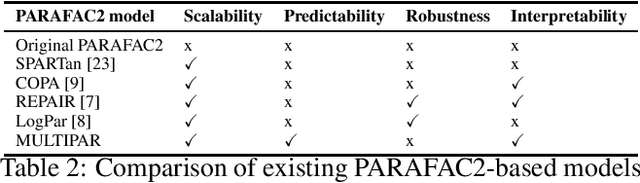
Tensor factorization has received increasing interest due to its intrinsic ability to capture latent factors in multi-dimensional data with many applications such as recommender systems and Electronic Health Records (EHR) mining. PARAFAC2 and its variants have been proposed to address irregular tensors where one of the tensor modes is not aligned, e.g., different users in recommender systems or patients in EHRs may have different length of records. PARAFAC2 has been successfully applied on EHRs for extracting meaningful medical concepts (phenotypes). Despite recent advancements, current models' predictability and interpretability are not satisfactory, which limits its utility for downstream analysis. In this paper, we propose MULTIPAR: a supervised irregular tensor factorization with multi-task learning. MULTIPAR is flexible to incorporate both static (e.g. in-hospital mortality prediction) and continuous or dynamic (e.g. the need for ventilation) tasks. By supervising the tensor factorization with downstream prediction tasks and leveraging information from multiple related predictive tasks, MULTIPAR can yield not only more meaningful phenotypes but also better predictive performance for downstream tasks. We conduct extensive experiments on two real-world temporal EHR datasets to demonstrate that MULTIPAR is scalable and achieves better tensor fit with more meaningful subgroups and stronger predictive performance compared to existing state-of-the-art methods.
Efficient and effective training of language and graph neural network models
Jun 22, 2022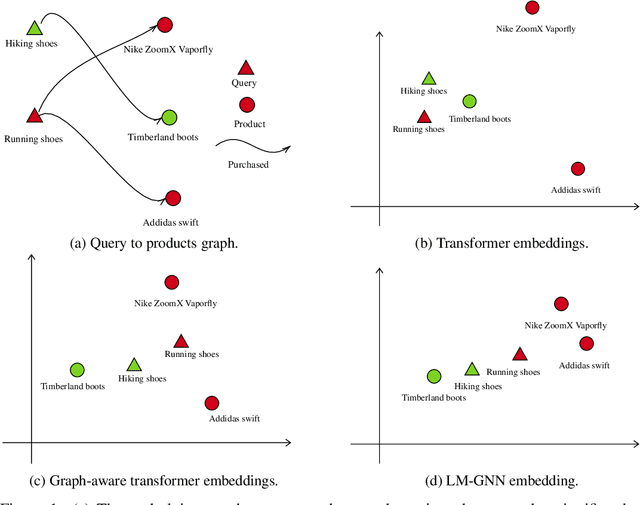
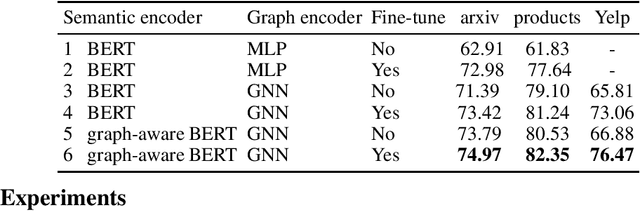
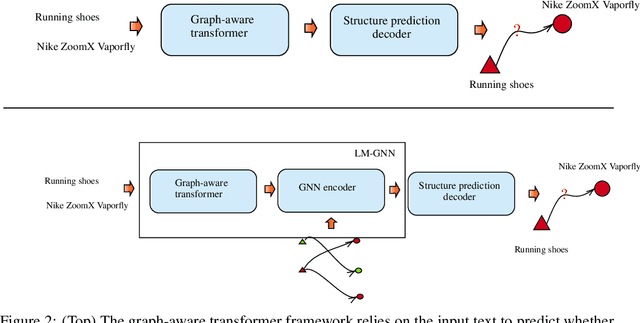
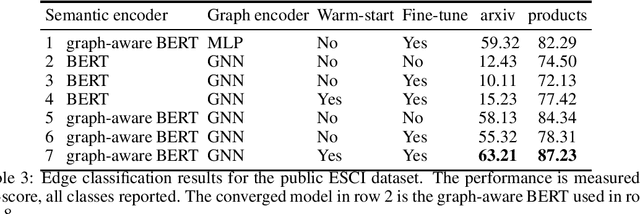
Can we combine heterogenous graph structure with text to learn high-quality semantic and behavioural representations? Graph neural networks (GNN)s encode numerical node attributes and graph structure to achieve impressive performance in a variety of supervised learning tasks. Current GNN approaches are challenged by textual features, which typically need to be encoded to a numerical vector before provided to the GNN that may incur some information loss. In this paper, we put forth an efficient and effective framework termed language model GNN (LM-GNN) to jointly train large-scale language models and graph neural networks. The effectiveness in our framework is achieved by applying stage-wise fine-tuning of the BERT model first with heterogenous graph information and then with a GNN model. Several system and design optimizations are proposed to enable scalable and efficient training. LM-GNN accommodates node and edge classification as well as link prediction tasks. We evaluate the LM-GNN framework in different datasets performance and showcase the effectiveness of the proposed approach. LM-GNN provides competitive results in an Amazon query-purchase-product application.
Cyclist Trajectory Forecasts by Incorporation of Multi-View Video Information
Jun 30, 2021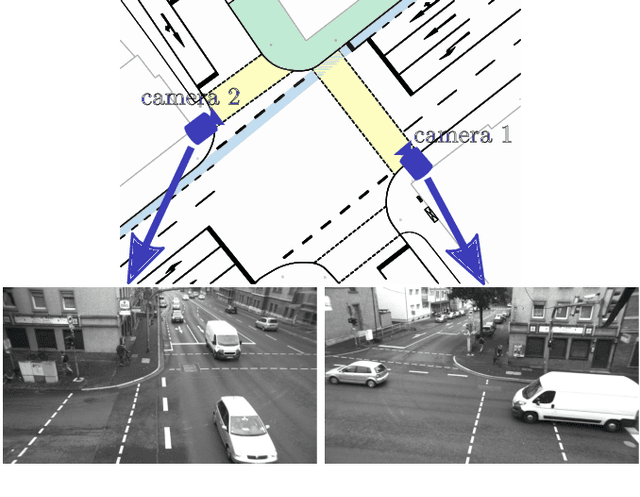

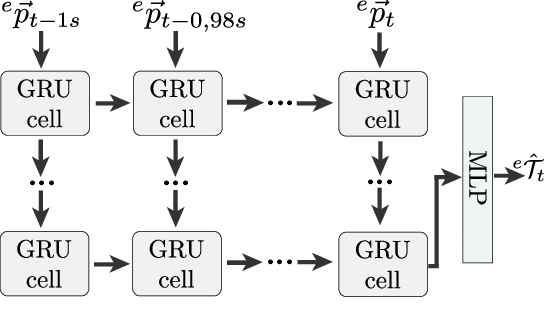
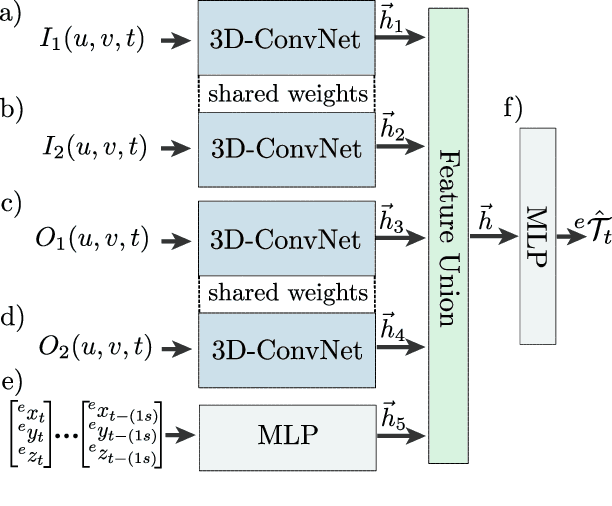
This article presents a novel approach to incorporate visual cues from video-data from a wide-angle stereo camera system mounted at an urban intersection into the forecast of cyclist trajectories. We extract features from image and optical flow (OF) sequences using 3D convolutional neural networks (3D-ConvNet) and combine them with features extracted from the cyclist's past trajectory to forecast future cyclist positions. By the use of additional information, we are able to improve positional accuracy by about 7.5 % for our test dataset and by up to 22 % for specific motion types compared to a method solely based on past trajectories. Furthermore, we compare the use of image sequences to the use of OF sequences as additional information, showing that OF alone leads to significant improvements in positional accuracy. By training and testing our methods using a real-world dataset recorded at a heavily frequented public intersection and evaluating the methods' runtimes, we demonstrate the applicability in real traffic scenarios. Our code and parts of our dataset are made publicly available.
Rating the Crisis of Online Public Opinion Using a Multi-Level Index System
Jul 29, 2022



Online public opinion usually spreads rapidly and widely, thus a small incident probably evolves into a large social crisis in a very short time, and results in a heavy loss in credit or economic aspects. We propose a method to rate the crisis of online public opinion based on a multi-level index system to evaluate the impact of events objectively. Firstly, the dissemination mechanism of online public opinion is explained from the perspective of information ecology. According to the mechanism, some evaluation indexes are selected through correlation analysis and principal component analysis. Then, a classification model of text emotion is created via the training by deep learning to achieve the accurate quantification of the emotional indexes in the index system. Finally, based on the multi-level evaluation index system and grey correlation analysis, we propose a method to rate the crisis of online public opinion. The experiment with the real-time incident show that this method can objectively evaluate the emotional tendency of Internet users and rate the crisis in different dissemination stages of online public opinion. It is helpful to realizing the crisis warning of online public opinion and timely blocking the further spread of the crisis.
MV-FCOS3D++: Multi-View Camera-Only 4D Object Detection with Pretrained Monocular Backbones
Jul 26, 2022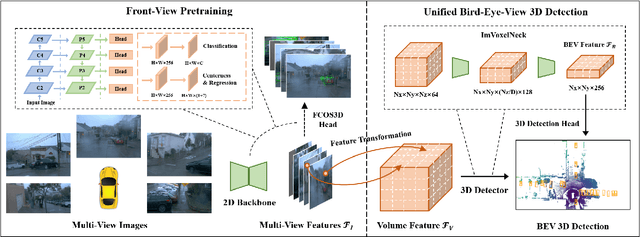
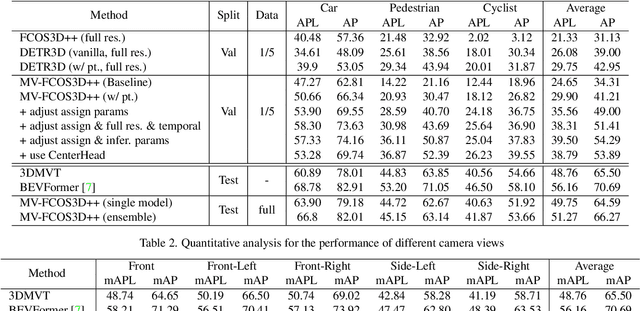
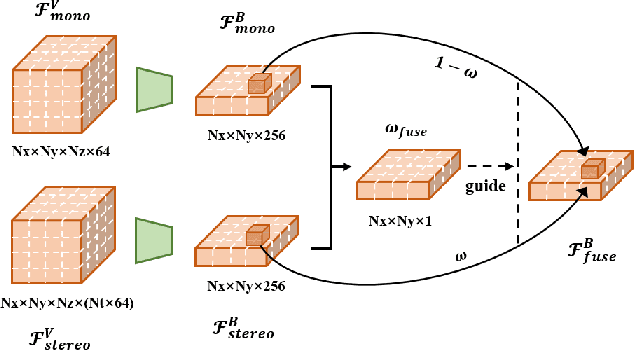

In this technical report, we present our solution, dubbed MV-FCOS3D++, for the Camera-Only 3D Detection track in Waymo Open Dataset Challenge 2022. For multi-view camera-only 3D detection, methods based on bird-eye-view or 3D geometric representations can leverage the stereo cues from overlapped regions between adjacent views and directly perform 3D detection without hand-crafted post-processing. However, it lacks direct semantic supervision for 2D backbones, which can be complemented by pretraining simple monocular-based detectors. Our solution is a multi-view framework for 4D detection following this paradigm. It is built upon a simple monocular detector FCOS3D++, pretrained only with object annotations of Waymo, and converts multi-view features to a 3D grid space to detect 3D objects thereon. A dual-path neck for single-frame understanding and temporal stereo matching is devised to incorporate multi-frame information. Our method finally achieves 49.75% mAPL with a single model and wins 2nd place in the WOD challenge, without any LiDAR-based depth supervision during training. The code will be released at https://github.com/Tai-Wang/Depth-from-Motion.
Do Deep Neural Networks Always Perform Better When Eating More Data?
May 30, 2022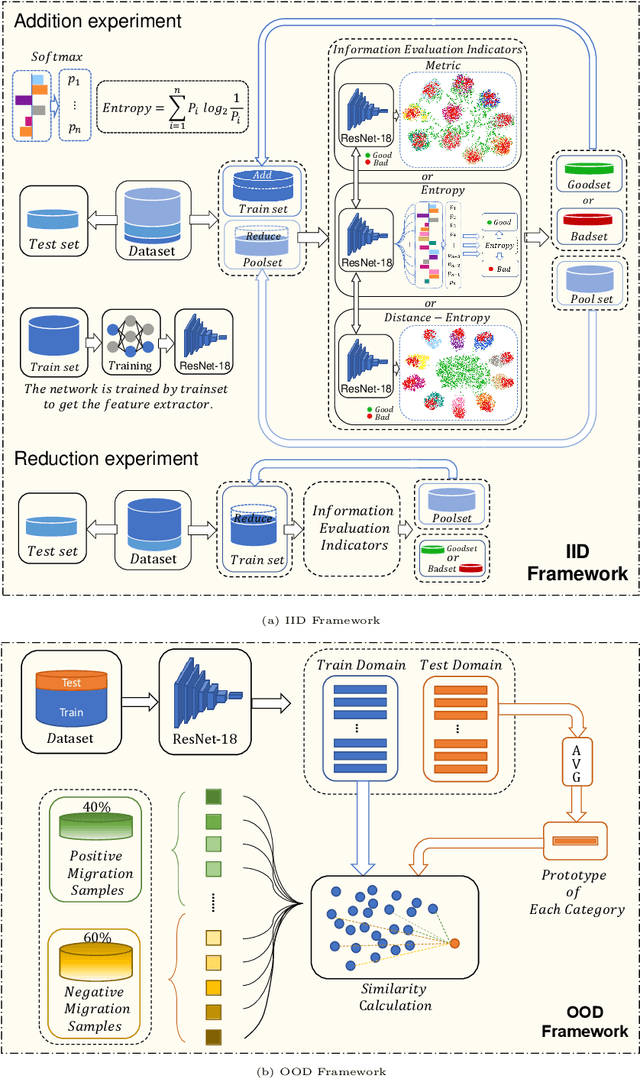
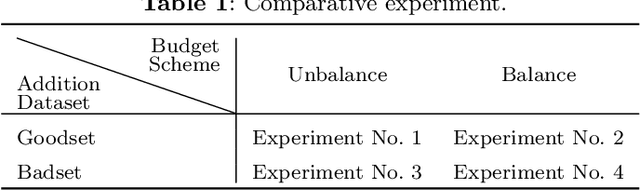
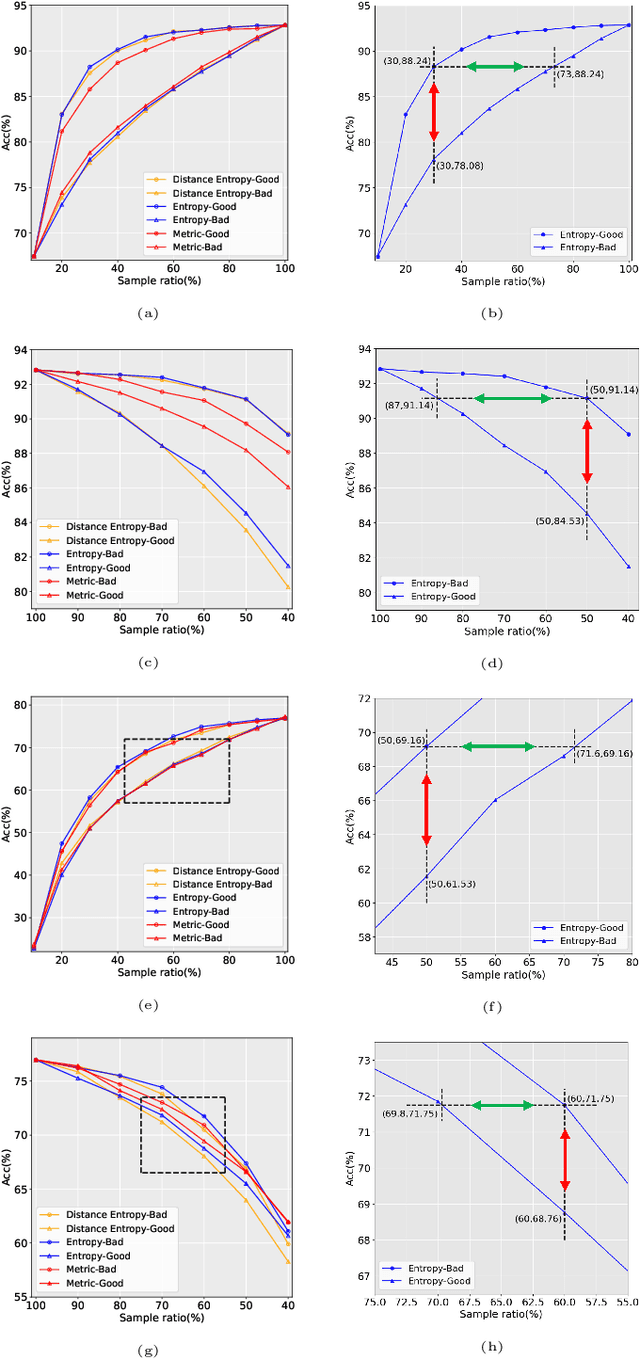
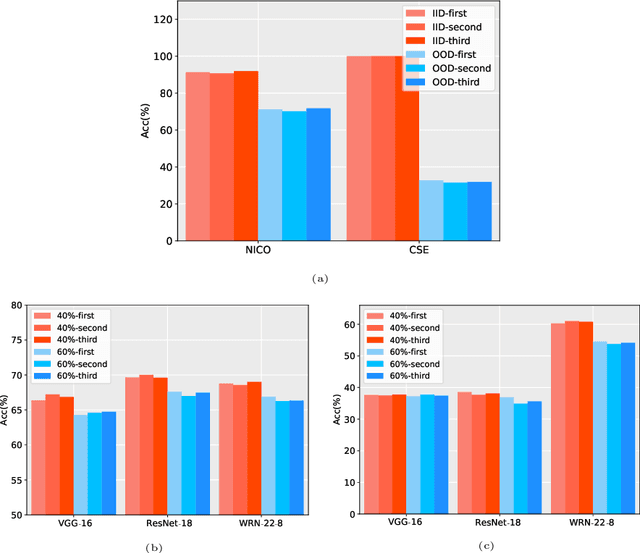
Data has now become a shortcoming of deep learning. Researchers in their own fields share the thinking that "deep neural networks might not always perform better when they eat more data," which still lacks experimental validation and a convincing guiding theory. Here to fill this lack, we design experiments from Identically Independent Distribution(IID) and Out of Distribution(OOD), which give powerful answers. For the purpose of guidance, based on the discussion of results, two theories are proposed: under IID condition, the amount of information determines the effectivity of each sample, the contribution of samples and difference between classes determine the amount of sample information and the amount of class information; under OOD condition, the cross-domain degree of samples determine the contributions, and the bias-fitting caused by irrelevant elements is a significant factor of cross-domain. The above theories provide guidance from the perspective of data, which can promote a wide range of practical applications of artificial intelligence.
An analysis of retracted papers in Computer Science
Jun 14, 2022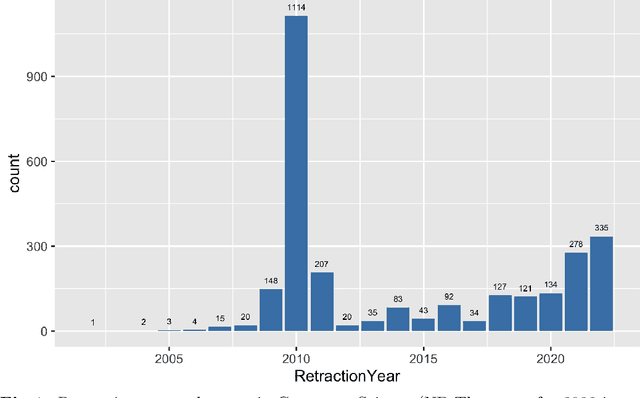
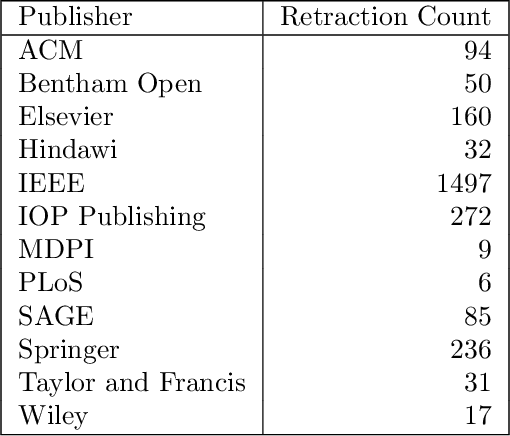
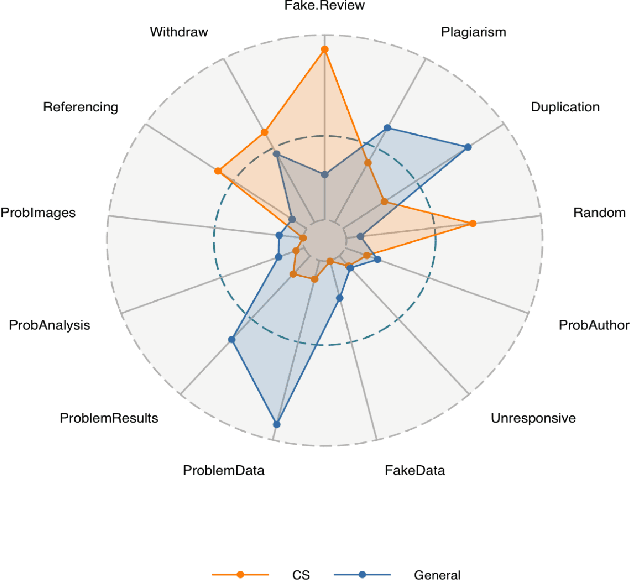
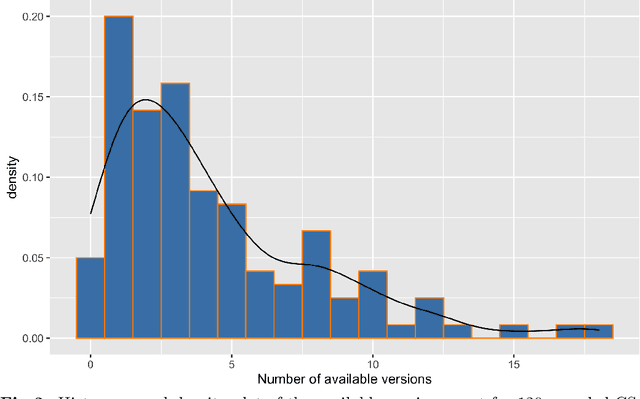
Context: The retraction of research papers, for whatever reason, is a growing phenomenon. However, although retracted paper information is publicly available via publishers, it is somewhat distributed and inconsistent. Objective: The aim is to assess: (i) the extent and nature of retracted research in Computer Science (CS) (ii) the post-retraction citation behaviour of retracted works and (iii) the potential impact on systematic reviews and mapping studies. Method: We analyse the Retraction Watch database and take citation information from the Web of Science and Google scholar. Results: We find that of the 33,955 entries in the Retraction watch database (16 May 2022), 2,816 are classified as CS, i.e., approximately 8.3%. For CS, 56% of retracted papers, provide little or no information as to the reasons. This contrasts with 26% for other disciplines. There is also a remarkable disparity between different publishers, a tendency for multiple versions of a retracted paper over and above the Version of Record (VoR), and for new citations long after a paper is officially retracted. Conclusions: Unfortunately retraction seems to be a sufficiently common outcome for a scientific paper that we as a research community need to take it more seriously, e.g., standardising procedures and taxonomies across publishers and the provision of appropriate research tools. Finally, we recommend particular caution when undertaking secondary analyses and meta-analyses which are at risk of becoming contaminated by these problem primary studies.
CSI Sensing from Heterogeneous User Feedbacks: A Constrained Phase Retrieval Approach
Jun 28, 2022

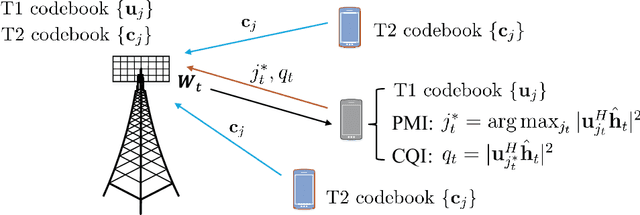
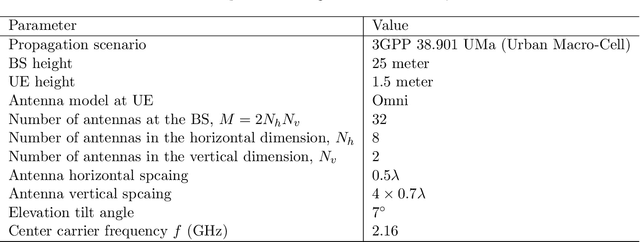
This paper investigates the downlink channel state information (CSI) sensing in 5G heterogeneous networks composed of user equipments (UEs) with different feedback capabilities. We aim to enhance the CSI accuracy of UEs only affording the low-resolution Type-I codebook. While existing works have demonstrated that the task can be accomplished by solving a phase retrieval (PR) formulation based on the feedback of precoding matrix indicator (PMI) and channel quality indicator (CQI), they need many feedback rounds. In this paper, we propose a novel CSI sensing scheme that can significantly reduce the feedback overhead. Our scheme involves a novel parameter dimension reduction design by exploiting the spatial consistency of wireless channels among nearby UEs, and a constrained PR (CPR) formulation that characterizes the feasible region of CSI by the PMI information. To address the computational challenge due to the non-convexity and the large number of constraints of CPR, we develop a two-stage algorithm that firstly identifies and removes inactive constraints, followed by a fast first-order algorithm. The study is further extended to multi-carrier systems. Extensive tests over DeepMIMO and QuaDriGa datasets showcase that our designs greatly outperform existing methods and achieve the high-resolution Type-II codebook performance with a few rounds of feedback.
A Data Driven Method for Multi-step Prediction of Ship Roll Motion in High Sea States
Jul 26, 2022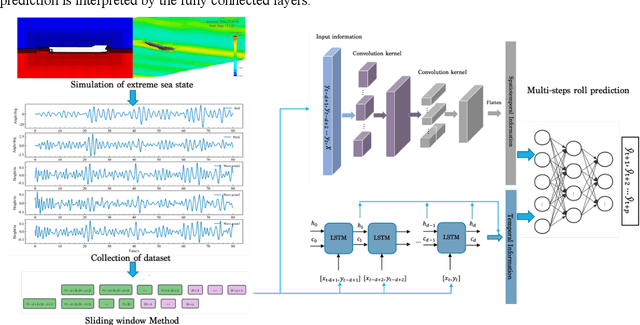
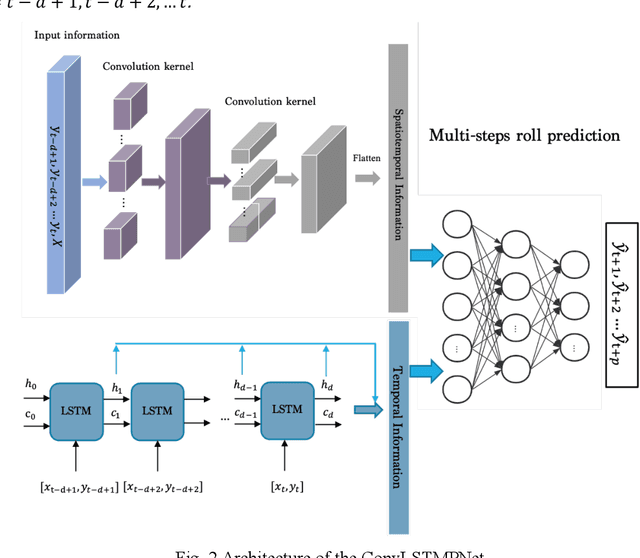
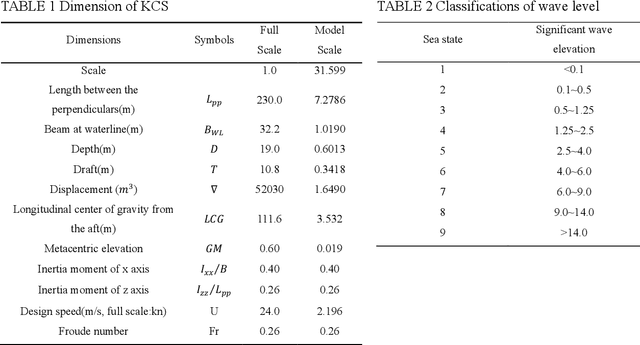
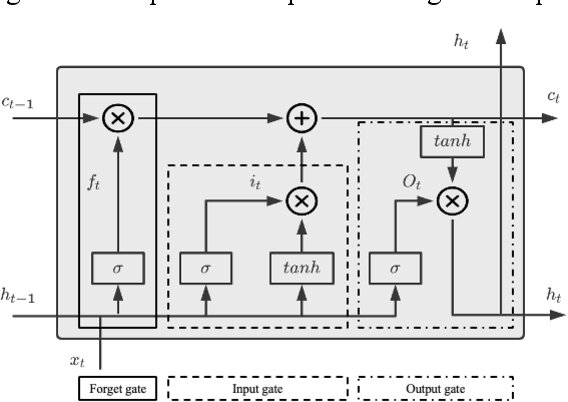
Accurate prediction of roll motion in high sea state is significant for the operability, safety and survivability of marine vehicles. This paper presents a novel data-driven methodology for achieving the multi-step prediction of ship roll motion in high sea states. A hybrid neural network, named ConvLSTMPNet, is proposed to execute long short-term memory (LSTM) and one-dimensional convolutional neural networks (CNN) in parallel to extract time-dependent and spatio-temporal information from multidimensional inputs. Taken KCS as the study object, the numerical solution of computational fluid dynamics method is utilized to generate the ship motion data in sea state 7 with different wave directions. An in-depth comparative study on the selection of feature space is conducted, considering the effects of time history of motion states and wave height. The comparison results demonstrate the superiority of selecting both motion states and wave heights as the feature space for multi-step prediction. In addition, the results demonstrate that ConvLSTMNet achieves more accurate than LSTM and CNN methods in multi-step prediction of roll motion, validating the efficiency of the proposed method.
Safety-Enhanced Autonomous Driving Using Interpretable Sensor Fusion Transformer
Jul 29, 2022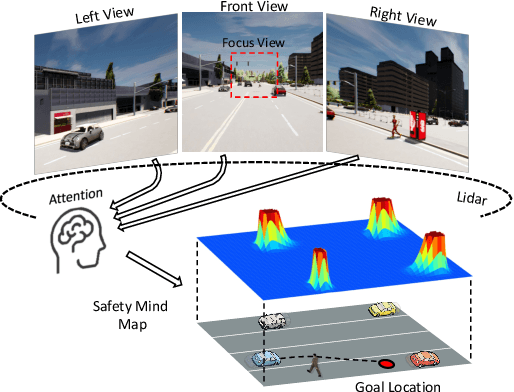
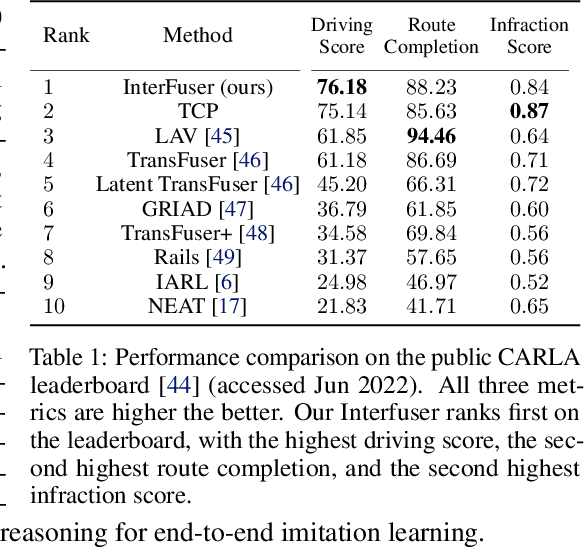
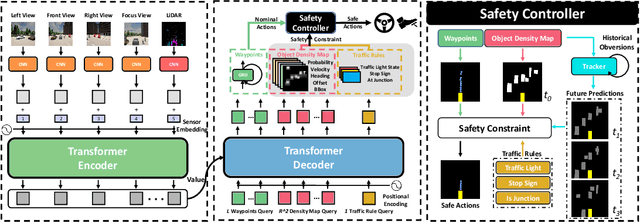
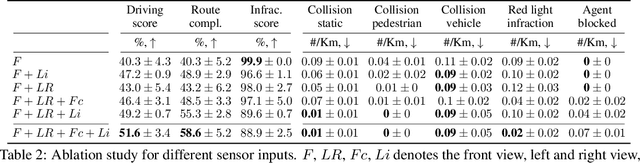
Large-scale deployment of autonomous vehicles has been continually delayed due to safety concerns. On the one hand, comprehensive scene understanding is indispensable, a lack of which would result in vulnerability to rare but complex traffic situations, such as the sudden emergence of unknown objects. However, reasoning from a global context requires access to sensors of multiple types and adequate fusion of multi-modal sensor signals, which is difficult to achieve. On the other hand, the lack of interpretability in learning models also hampers the safety with unverifiable failure causes. In this paper, we propose a safety-enhanced autonomous driving framework, named Interpretable Sensor Fusion Transformer(InterFuser), to fully process and fuse information from multi-modal multi-view sensors for achieving comprehensive scene understanding and adversarial event detection. Besides, intermediate interpretable features are generated from our framework, which provide more semantics and are exploited to better constrain actions to be within the safe sets. We conducted extensive experiments on CARLA benchmarks, where our model outperforms prior methods, ranking the first on the public CARLA Leaderboard. Our code will be made available at https://github.com/opendilab/InterFuser