 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChance-Constrained MPPI under State and Dynamic Object Prediction Uncertainty and the Evaluation of Collision Risk Calibration
May 27, 2026Chance-constrained Model Predictive Path Integral (MPPI) control is increasingly adopted for navigation in dynamic environments to explicitly bound collision risk. However, these probabilistic guarantees implicitly assume that upstream uncertainties from localization and perception are well-calibrated. In practice, estimators are often miscalibrated, inducing characteristic closed-loop failure modes: overconfidence leads to systematic safety violations, while underconfidence triggers overly conservative freezing or probability dilution. To address this critical gap, our primary contribution is a rigorous evaluation methodology applying proper scoring rules to assess the statistical validity of predicted collision risks during closed-loop execution. Concurrently, Dual-Uncertainty Chance-Constrained Tube MPPI (DUCCT-MPPI) is proposed as a real-time, risk-aware planning architecture. DUCCT-MPPI jointly integrates localization uncertainty via a one-tube Unscented Transform (UT) approximation and dynamic obstacle prediction uncertainty via Monte Carlo aggregation. Through extensive physics-based simulations, the framework demonstrates robust failure-mitigation, seamlessly transitioning to safe, conservative maneuvering without succumbing to functional deadlocks in highly cluttered environments. In highly cluttered environments, DUCCT-MPPI achieves superior robustness, outperforming established Monte Carlo MPPI baselines by nearly 28\% in navigation success rate, while simultaneously recording the lowest travel times and minimizing induced social forces. Ultimately, these findings establish that reliable probabilistic safety in autonomous navigation dictates not only expressive risk models but statistically valid uncertainty estimates throughout the entire autonomy stack.
DD-MDN: Human Trajectory Forecasting with Diffusion-Based Dual Mixture Density Networks and Uncertainty Self-Calibration
Feb 11, 2026Human Trajectory Forecasting (HTF) predicts future human movements from past trajectories and environmental context, with applications in Autonomous Driving, Smart Surveillance, and Human-Robot Interaction. While prior work has focused on accuracy, social interaction modeling, and diversity, little attention has been paid to uncertainty modeling, calibration, and forecasts from short observation periods, which are crucial for downstream tasks such as path planning and collision avoidance. We propose DD-MDN, an end-to-end probabilistic HTF model that combines high positional accuracy, calibrated uncertainty, and robustness to short observations. Using a few-shot denoising diffusion backbone and a dual mixture density network, our method learns self-calibrated residence areas and probability-ranked anchor paths, from which diverse trajectory hypotheses are derived, without predefined anchors or endpoints. Experiments on the ETH/UCY, SDD, inD, and IMPTC datasets demonstrate state-of-the-art accuracy, robustness at short observation intervals, and reliable uncertainty modeling. The code is available at: https://github.com/kav-institute/ddmdn.
LiDAR Based Semantic Perception for Forklifts in Outdoor Environments
May 28, 2025



In this study, we present a novel LiDAR-based semantic segmentation framework tailored for autonomous forklifts operating in complex outdoor environments. Central to our approach is the integration of a dual LiDAR system, which combines forward-facing and downward-angled LiDAR sensors to enable comprehensive scene understanding, specifically tailored for industrial material handling tasks. The dual configuration improves the detection and segmentation of dynamic and static obstacles with high spatial precision. Using high-resolution 3D point clouds captured from two sensors, our method employs a lightweight yet robust approach that segments the point clouds into safety-critical instance classes such as pedestrians, vehicles, and forklifts, as well as environmental classes such as driveable ground, lanes, and buildings. Experimental validation demonstrates that our approach achieves high segmentation accuracy while satisfying strict runtime requirements, establishing its viability for safety-aware, fully autonomous forklift navigation in dynamic warehouse and yard environments.
Real Time Semantic Segmentation of High Resolution Automotive LiDAR Scans
Apr 30, 2025In recent studies, numerous previous works emphasize the importance of semantic segmentation of LiDAR data as a critical component to the development of driver-assistance systems and autonomous vehicles. However, many state-of-the-art methods are tested on outdated, lower-resolution LiDAR sensors and struggle with real-time constraints. This study introduces a novel semantic segmentation framework tailored for modern high-resolution LiDAR sensors that addresses both accuracy and real-time processing demands. We propose a novel LiDAR dataset collected by a cutting-edge automotive 128 layer LiDAR in urban traffic scenes. Furthermore, we propose a semantic segmentation method utilizing surface normals as strong input features. Our approach is bridging the gap between cutting-edge research and practical automotive applications. Additionaly, we provide a Robot Operating System (ROS2) implementation that we operate on our research vehicle. Our dataset and code are publicly available: https://github.com/kav-institute/SemanticLiDAR.
Reliable Probabilistic Human Trajectory Prediction for Autonomous Applications
Oct 10, 2024



Autonomous systems, like vehicles or robots, require reliable, accurate, fast, resource-efficient, scalable, and low-latency trajectory predictions to get initial knowledge about future locations and movements of surrounding objects for safe human-machine interaction. Furthermore, they need to know the uncertainty of the predictions for risk assessment to provide safe path planning. This paper presents a lightweight method to address these requirements, combining Long Short-Term Memory and Mixture Density Networks. Our method predicts probability distributions, including confidence level estimations for positional uncertainty to support subsequent risk management applications and runs on a low-power embedded platform. We discuss essential requirements for human trajectory prediction in autonomous vehicle applications and demonstrate our method's performance using multiple traffic-related datasets. Furthermore, we explain reliability and sharpness metrics and show how important they are to guarantee the correctness and robustness of a model's predictions and uncertainty assessments. These essential evaluations have so far received little attention for no good reason. Our approach focuses entirely on real-world applicability. Verifying prediction uncertainties and a model's reliability are central to autonomous real-world applications. Our framework and code are available at: https://github.com/kav-institute/mdn_trajectory_forecasting.
Height Change Feature Based Free Space Detection
Aug 02, 2023In the context of autonomous forklifts, ensuring non-collision during travel, pick, and place operations is crucial. To accomplish this, the forklift must be able to detect and locate areas of free space and potential obstacles in its environment. However, this is particularly challenging in highly dynamic environments, such as factory sites and production halls, due to numerous industrial trucks and workers moving throughout the area. In this paper, we present a novel method for free space detection, which consists of the following steps. We introduce a novel technique for surface normal estimation relying on spherical projected LiDAR data. Subsequently, we employ the estimated surface normals to detect free space. The presented method is a heuristic approach that does not require labeling and can ensure real-time application due to high processing speed. The effectiveness of the proposed method is demonstrated through its application to a real-world dataset obtained on a factory site both indoors and outdoors, and its evaluation on the Semantic KITTI dataset [2]. We achieved a mean Intersection over Union (mIoU) score of 50.90 % on the benchmark dataset, with a processing speed of 105 Hz. In addition, we evaluated our approach on our factory site dataset. Our method achieved a mIoU score of 63.30 % at 54 Hz
The IMPTC Dataset: An Infrastructural Multi-Person Trajectory and Context Dataset
Jul 12, 2023



Inner-city intersections are among the most critical traffic areas for injury and fatal accidents. Automated vehicles struggle with the complex and hectic everyday life within those areas. Sensor-equipped smart infrastructures, which can cooperate with vehicles, can benefit automated traffic by extending the perception capabilities of drivers and vehicle perception systems. Additionally, they offer the opportunity to gather reproducible and precise data of a holistic scene understanding, including context information as a basis for training algorithms for various applications in automated traffic. Therefore, we introduce the Infrastructural Multi-Person Trajectory and Context Dataset (IMPTC). We use an intelligent public inner-city intersection in Germany with visual sensor technology. A multi-view camera and LiDAR system perceives traffic situations and road users' behavior. Additional sensors monitor contextual information like weather, lighting, and traffic light signal status. The data acquisition system focuses on Vulnerable Road Users (VRUs) and multi-agent interaction. The resulting dataset consists of eight hours of measurement data. It contains over 2,500 VRU trajectories, including pedestrians, cyclists, e-scooter riders, strollers, and wheelchair users, and over 20,000 vehicle trajectories at different day times, weather conditions, and seasons. In addition, to enable the entire stack of research capabilities, the dataset includes all data, starting from the sensor-, calibration- and detection data until trajectory and context data. The dataset is continuously expanded and is available online for non-commercial research at https://github.com/kav-institute/imptc-dataset.
Smart Infrastructure: A Research Junction
Jul 12, 2023


Complex inner-city junctions are among the most critical traffic areas for injury and fatal accidents. The development of highly automated driving (HAD) systems struggles with the complex and hectic everyday life within those areas. Sensor-equipped smart infrastructures, which can communicate and cooperate with vehicles, are essential to enable a holistic scene understanding to resolve occlusions drivers and vehicle perception systems for themselves can not cover. We introduce an intelligent research infrastructure equipped with visual sensor technology, located at a public inner-city junction in Aschaffenburg, Germany. A multiple-view camera system monitors the traffic situation to perceive road users' behavior. Both motorized and non-motorized traffic is considered. The system is used for research in data generation, evaluating new HAD sensors systems, algorithms, and Artificial Intelligence (AI) training strategies using real-, synthetic- and augmented data. In addition, the junction features a highly accurate digital twin. Real-world data can be taken into the digital twin for simulation purposes and synthetic data generation.
Sensor Equivariance by LiDAR Projection Images
Apr 29, 2023



In this work, we propose an extension of conventional image data by an additional channel in which the associated projection properties are encoded. This addresses the issue of sensor-dependent object representation in projection-based sensors, such as LiDAR, which can lead to distorted physical and geometric properties due to variations in sensor resolution and field of view. To that end, we propose an architecture for processing this data in an instance segmentation framework. We focus specifically on LiDAR as a key sensor modality for machine vision tasks and highly automated driving (HAD). Through an experimental setup in a controlled synthetic environment, we identify a bias on sensor resolution and field of view and demonstrate that our proposed method can reduce said bias for the task of LiDAR instance segmentation. Furthermore, we define our method such that it can be applied to other projection-based sensors, such as cameras. To promote transparency, we make our code and dataset publicly available. This method shows the potential to improve performance and robustness in various machine vision tasks that utilize projection-based sensors.
Cyclist Trajectory Forecasts by Incorporation of Multi-View Video Information
Jun 30, 2021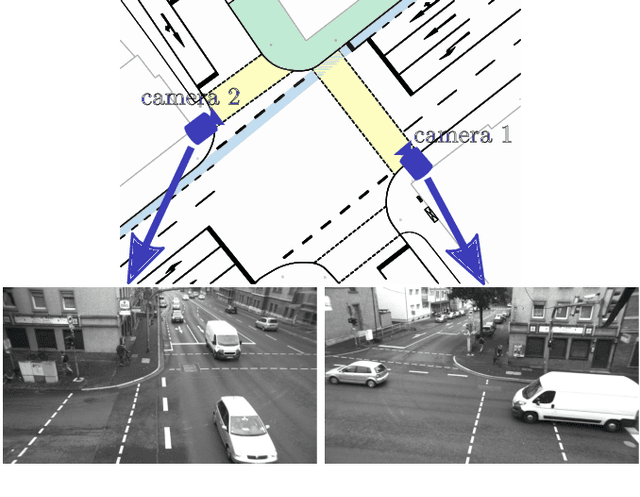

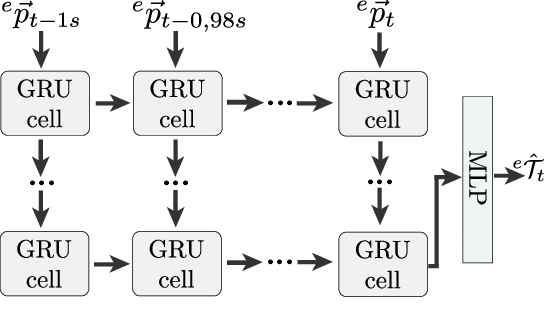
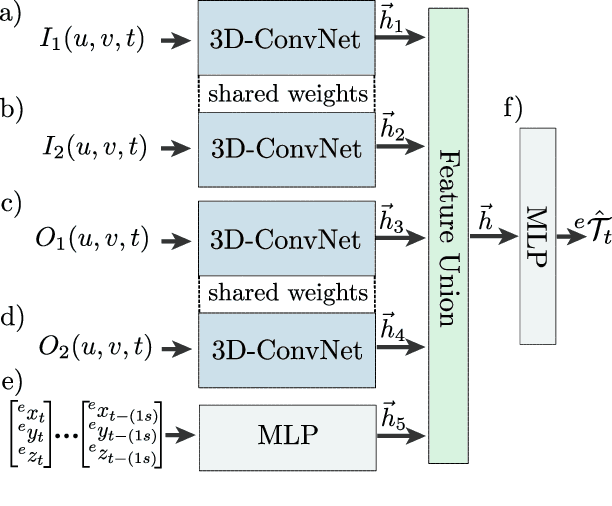
This article presents a novel approach to incorporate visual cues from video-data from a wide-angle stereo camera system mounted at an urban intersection into the forecast of cyclist trajectories. We extract features from image and optical flow (OF) sequences using 3D convolutional neural networks (3D-ConvNet) and combine them with features extracted from the cyclist's past trajectory to forecast future cyclist positions. By the use of additional information, we are able to improve positional accuracy by about 7.5 % for our test dataset and by up to 22 % for specific motion types compared to a method solely based on past trajectories. Furthermore, we compare the use of image sequences to the use of OF sequences as additional information, showing that OF alone leads to significant improvements in positional accuracy. By training and testing our methods using a real-world dataset recorded at a heavily frequented public intersection and evaluating the methods' runtimes, we demonstrate the applicability in real traffic scenarios. Our code and parts of our dataset are made publicly available.