 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
NLOS Ranging Mitigation with Neural Network Model for UWB Localization
Jun 22, 2022
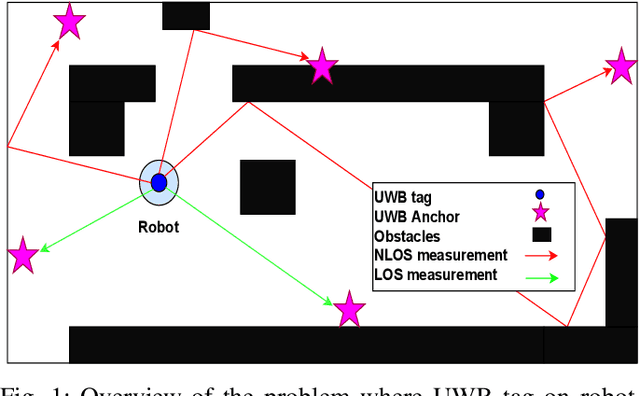
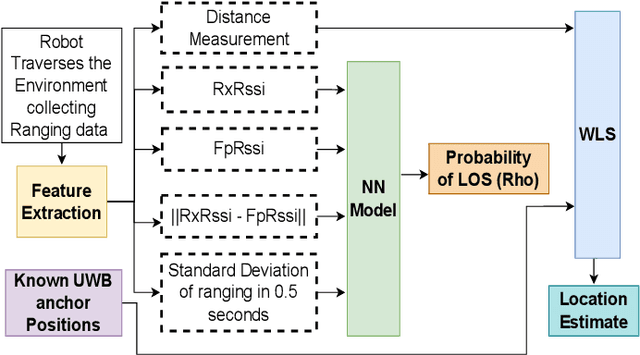
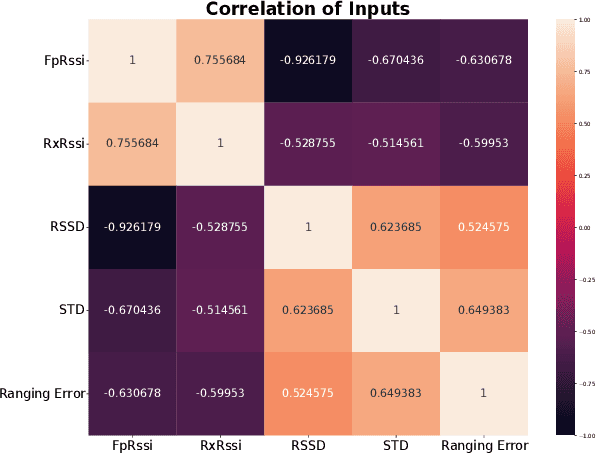
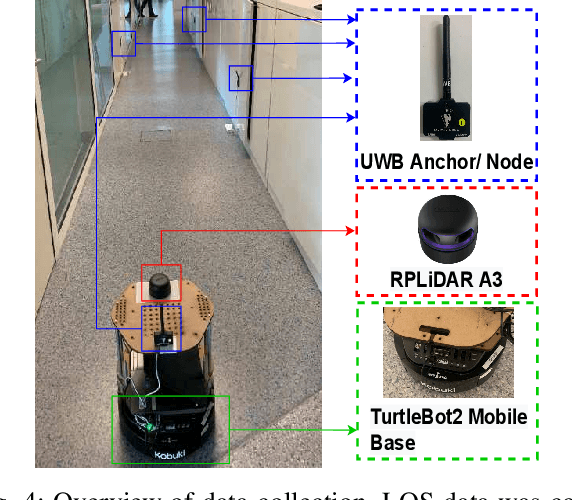
Localization of robots is vital for navigation and path planning, such as in cases where a map of the environment is needed. Ultra-Wideband (UWB) for indoor location systems has been gaining popularity over the years with the introduction of low-cost UWB modules providing centimetre-level accuracy. However, in the presence of obstacles in the environment, Non-Line-Of-Sight (NLOS) measurements from the UWB will produce inaccurate results. As low-cost UWB devices do not provide channel information, we propose an approach to decide if a measurement is within Line-Of-Sight (LOS) or not by using some signal strength information provided by low-cost UWB modules through a Neural Network (NN) model. The result of this model is the probability of a ranging measurement being LOS which was used for localization through the Weighted-Least-Square (WLS) method. Our approach improves localization accuracy by 16.93% on the lobby testing data and 27.97% on the corridor testing data using the NN model trained with all extracted inputs from the office training data.
Contrastive Graph Multimodal Model for Text Classification in Videos
Jun 06, 2022
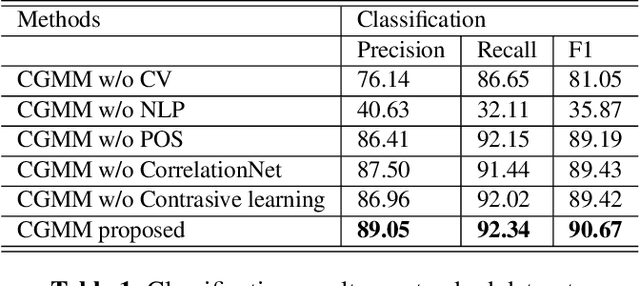
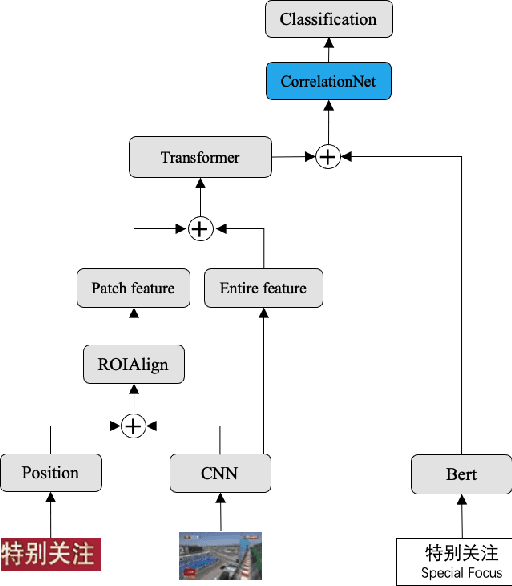
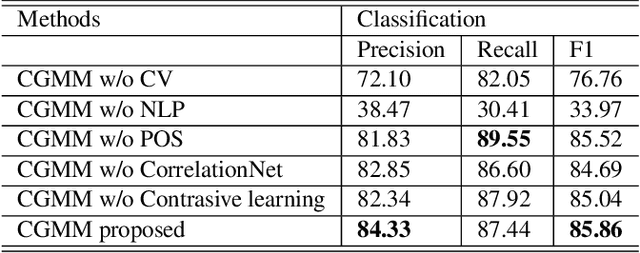
The extraction of text information in videos serves as a critical step towards semantic understanding of videos. It usually involved in two steps: (1) text recognition and (2) text classification. To localize texts in videos, we can resort to large numbers of text recognition methods based on OCR technology. However, to our knowledge, there is no existing work focused on the second step of video text classification, which will limit the guidance to downstream tasks such as video indexing and browsing. In this paper, we are the first to address this new task of video text classification by fusing multimodal information to deal with the challenging scenario where different types of video texts may be confused with various colors, unknown fonts and complex layouts. In addition, we tailor a specific module called CorrelationNet to reinforce feature representation by explicitly extracting layout information. Furthermore, contrastive learning is utilized to explore inherent connections between samples using plentiful unlabeled videos. Finally, we construct a new well-defined industrial dataset from the news domain, called TI-News, which is dedicated to building and evaluating video text recognition and classification applications. Extensive experiments on TI-News demonstrate the effectiveness of our method.
Association Between Neighborhood Factors and Adult Obesity in Shelby County, Tennessee: Geospatial Machine Learning Approach
Aug 09, 2022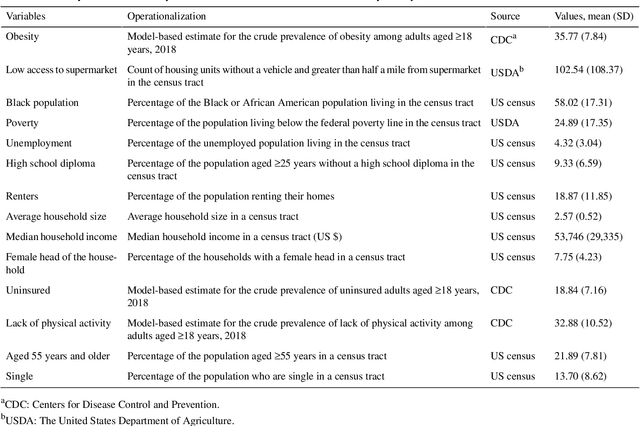
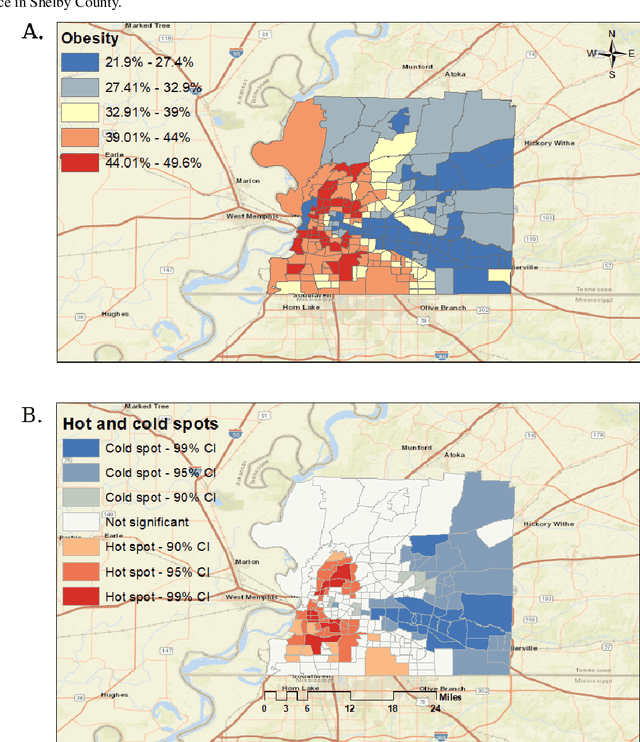

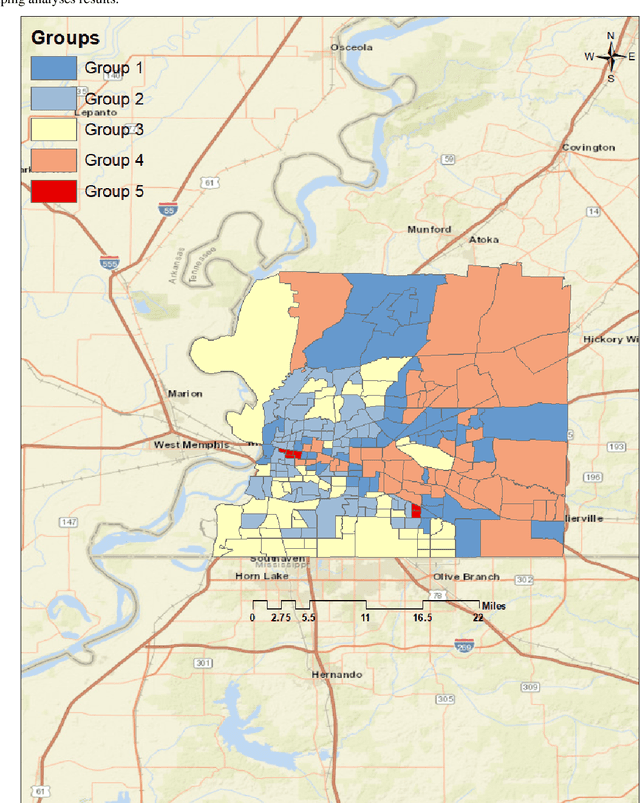
Obesity is a global epidemic causing at least 2.8 million deaths per year. This complex disease is associated with significant socioeconomic burden, reduced work productivity, unemployment, and other social determinants of Health (SDoH) disparities. Objective: The objective of this study was to investigate the effects of SDoH on obesity prevalence among adults in Shelby County, Tennessee, USA using a geospatial machine-learning approach. Obesity prevalence was obtained from publicly available CDC 500 cities database while SDoH indicators were extracted from the U.S. Census and USDA. We examined the geographic distributions of obesity prevalence patterns using Getis-Ord Gi* statistics and calibrated multiple models to study the association between SDoH and adult obesity. Also, unsupervised machine learning was used to conduct grouping analysis to investigate the distribution of obesity prevalence and associated SDoH indicators. Results depicted a high percentage of neighborhoods experiencing high adult obesity prevalence within Shelby County. In the census tract, median household income, as well as the percentage of individuals who were black, home renters, living below the poverty level, fifty-five years or older, unmarried, and uninsured, had a significant association with adult obesity prevalence. The grouping analysis revealed disparities in obesity prevalence amongst disadvantaged neighborhoods. More research is needed that examines linkages between geographical location, SDoH, and chronic diseases. These findings, which depict a significantly higher prevalence of obesity within disadvantaged neighborhoods, and other geospatial information can be leveraged to offer valuable insights informing health decision-making and interventions that mitigate risk factors for increasing obesity prevalence.
* 12 Pages, 3 Figures, 5 Tables
Scanning Inside Volcanoes by Synthetic Aperture Radar Echography Tomographic Doppler Imaging
Jun 18, 2022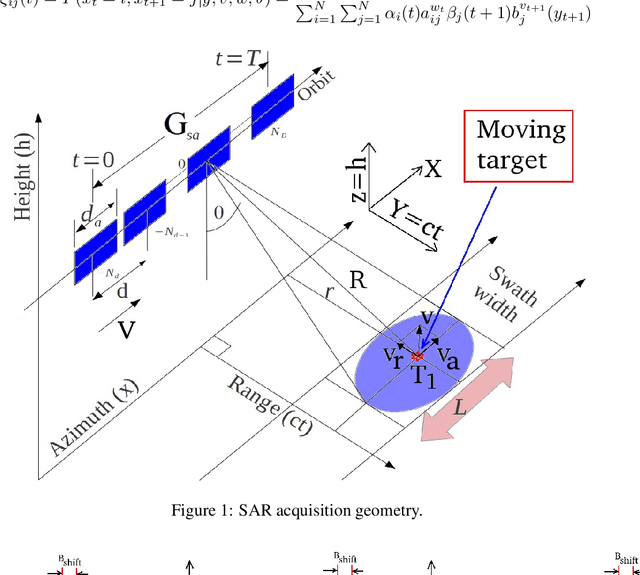
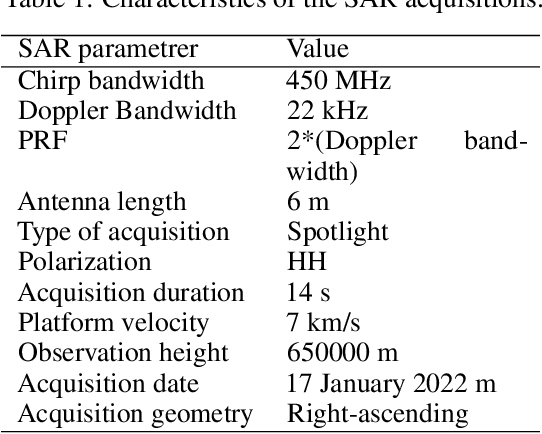
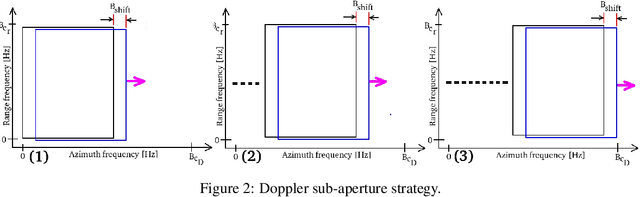

A problem with synthetic aperture radar (SAR) is that due to the poor penetrating action of electromagnetic waves within solid bodies, the ability to observe through distributed targets is precluded. In this context, indeed, imaging is only possible on targets distribute on the scene surface. This work describes an imaging method based on the analysis of micro-motions present on volcanoes and generated by the underground Earth's heat. Processing the coherent vibrational information embedded on the single SAR image, in the single-look-complex configuration, the sound information is exploited, penetrating tomographic imaging over a depth of about 3 km from the Earth's surface. Measurement results are calculated by processing a SLC image from the COSMO-SkyMed Second Generation satellite constellation of the Vesuvius. Tomographic maps reveal the presence of the magma chamber, together with the main and the secondary volcanic conduits. This technique certainly paves the way for completely new exploitation of SAR images to scan inside the Earth's surface.
Bear the Query in Mind: Visual Grounding with Query-conditioned Convolution
Jun 22, 2022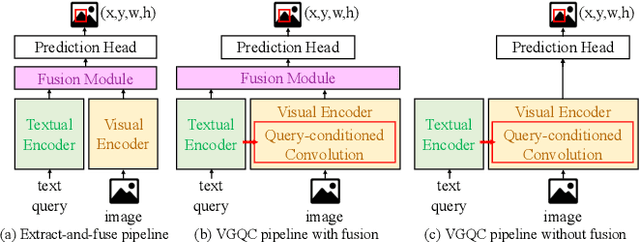
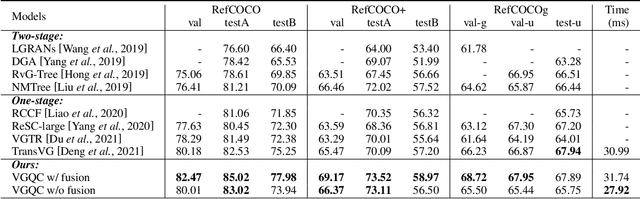
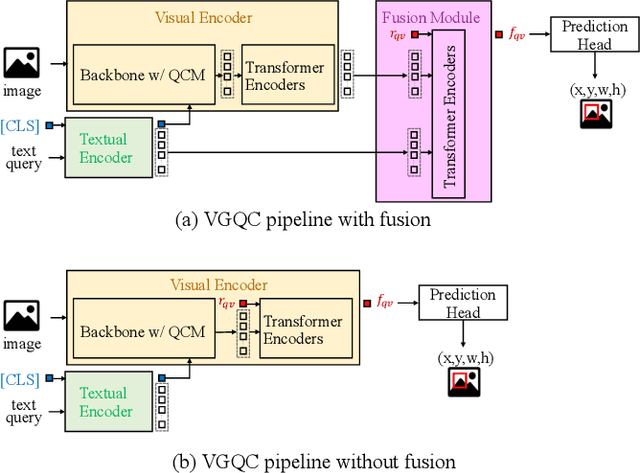
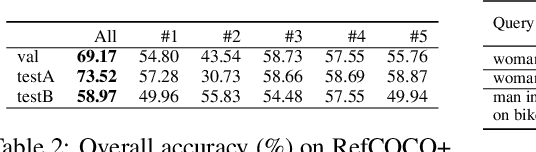
Visual grounding is a task that aims to locate a target object according to a natural language expression. As a multi-modal task, feature interaction between textual and visual inputs is vital. However, previous solutions mainly handle each modality independently before fusing them together, which does not take full advantage of relevant textual information while extracting visual features. To better leverage the textual-visual relationship in visual grounding, we propose a Query-conditioned Convolution Module (QCM) that extracts query-aware visual features by incorporating query information into the generation of convolutional kernels. With our proposed QCM, the downstream fusion module receives visual features that are more discriminative and focused on the desired object described in the expression, leading to more accurate predictions. Extensive experiments on three popular visual grounding datasets demonstrate that our method achieves state-of-the-art performance. In addition, the query-aware visual features are informative enough to achieve comparable performance to the latest methods when directly used for prediction without further multi-modal fusion.
Egocentric scene context for human-centric environment understanding from video
Jul 22, 2022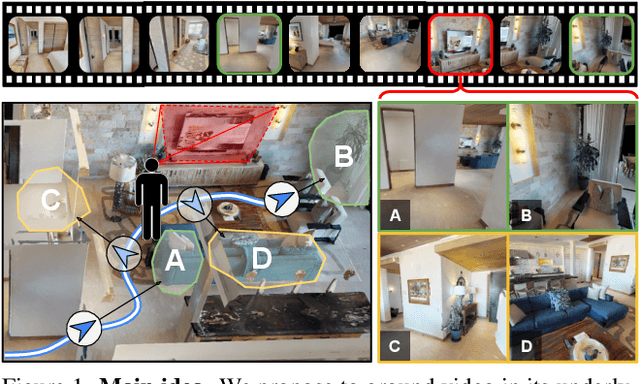
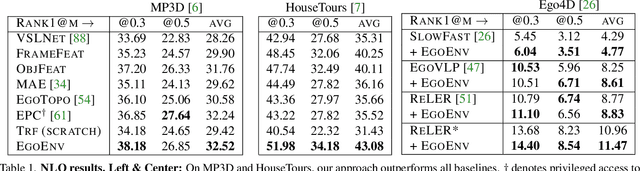
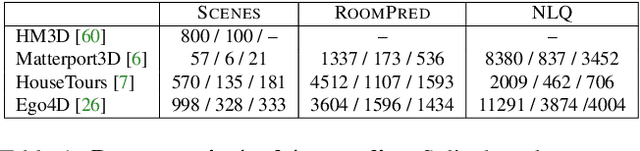

First-person video highlights a camera-wearer's activities in the context of their persistent environment. However, current video understanding approaches reason over visual features from short video clips that are detached from the underlying physical space and only capture what is directly seen. We present an approach that links egocentric video and camera pose over time by learning representations that are predictive of the camera-wearer's (potentially unseen) local surroundings to facilitate human-centric environment understanding. We train such models using videos from agents in simulated 3D environments where the environment is fully observable, and test them on real-world videos of house tours from unseen environments. We show that by grounding videos in their physical environment, our models surpass traditional scene classification models at predicting which room a camera-wearer is in (where frame-level information is insufficient), and can leverage this grounding to localize video moments corresponding to environment-centric queries, outperforming prior methods. Project page: http://vision.cs.utexas.edu/projects/ego-scene-context/
Unsupervised Domain Adaptation for Video Transformers in Action Recognition
Jul 26, 2022
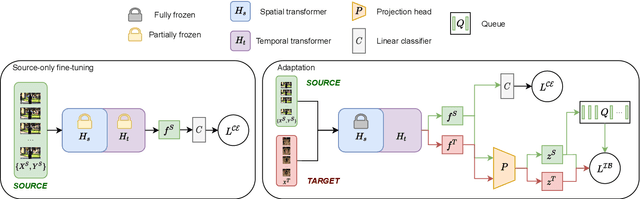
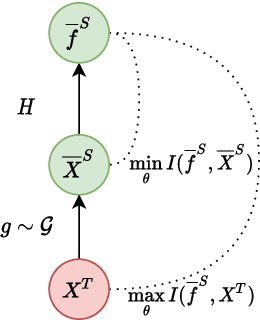
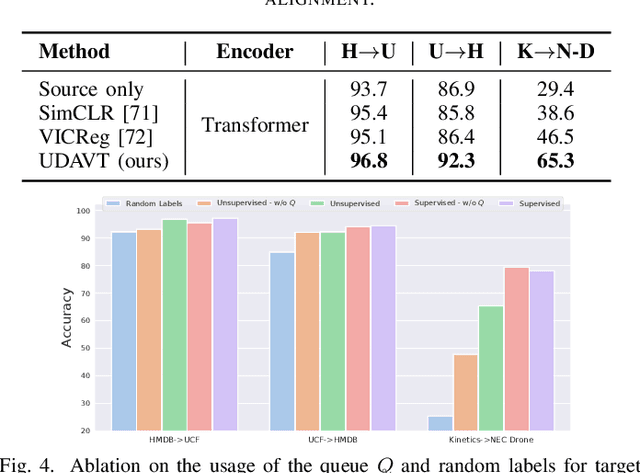
Over the last few years, Unsupervised Domain Adaptation (UDA) techniques have acquired remarkable importance and popularity in computer vision. However, when compared to the extensive literature available for images, the field of videos is still relatively unexplored. On the other hand, the performance of a model in action recognition is heavily affected by domain shift. In this paper, we propose a simple and novel UDA approach for video action recognition. Our approach leverages recent advances on spatio-temporal transformers to build a robust source model that better generalises to the target domain. Furthermore, our architecture learns domain invariant features thanks to the introduction of a novel alignment loss term derived from the Information Bottleneck principle. We report results on two video action recognition benchmarks for UDA, showing state-of-the-art performance on HMDB$\leftrightarrow$UCF, as well as on Kinetics$\rightarrow$NEC-Drone, which is more challenging. This demonstrates the effectiveness of our method in handling different levels of domain shift. The source code is available at https://github.com/vturrisi/UDAVT.
MulViMotion: Shape-aware 3D Myocardial Motion Tracking from Multi-View Cardiac MRI
Jul 29, 2022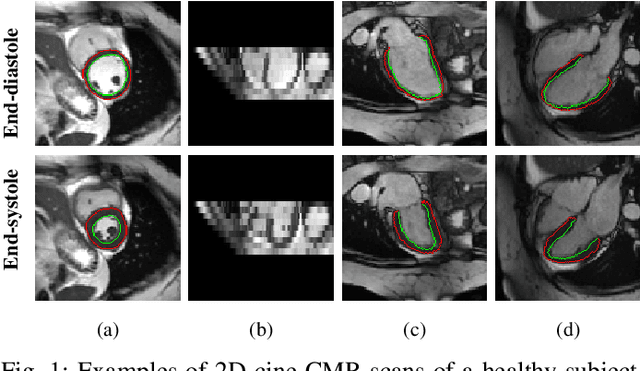
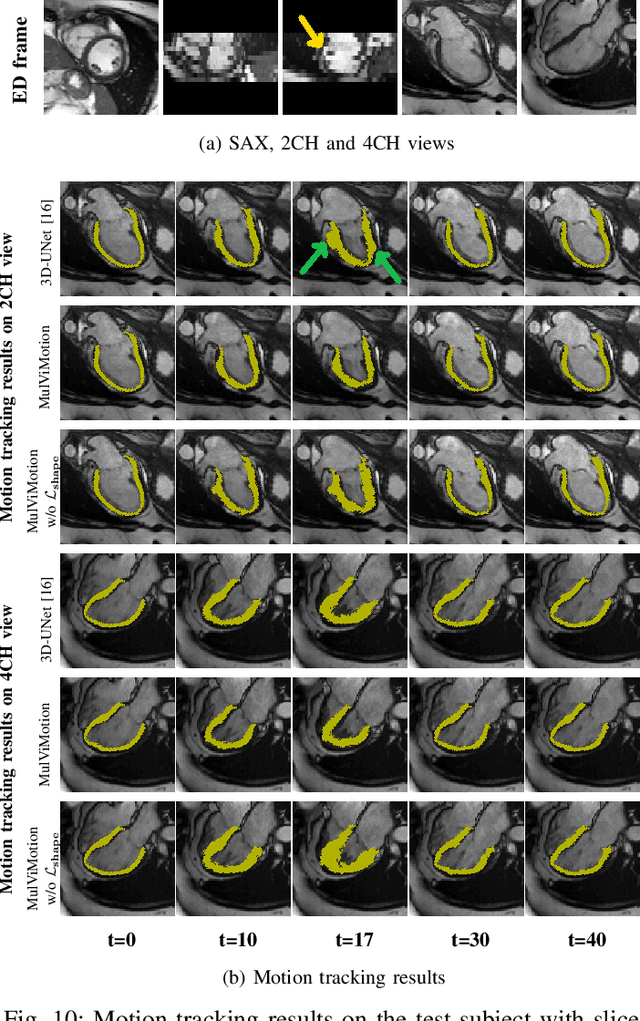
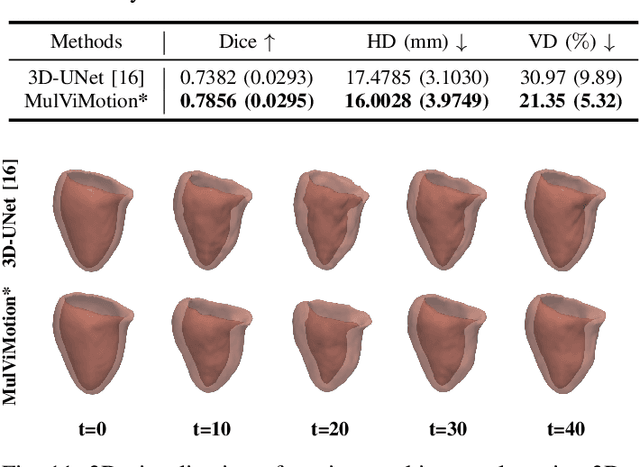
Recovering the 3D motion of the heart from cine cardiac magnetic resonance (CMR) imaging enables the assessment of regional myocardial function and is important for understanding and analyzing cardiovascular disease. However, 3D cardiac motion estimation is challenging because the acquired cine CMR images are usually 2D slices which limit the accurate estimation of through-plane motion. To address this problem, we propose a novel multi-view motion estimation network (MulViMotion), which integrates 2D cine CMR images acquired in short-axis and long-axis planes to learn a consistent 3D motion field of the heart. In the proposed method, a hybrid 2D/3D network is built to generate dense 3D motion fields by learning fused representations from multi-view images. To ensure that the motion estimation is consistent in 3D, a shape regularization module is introduced during training, where shape information from multi-view images is exploited to provide weak supervision to 3D motion estimation. We extensively evaluate the proposed method on 2D cine CMR images from 580 subjects of the UK Biobank study for 3D motion tracking of the left ventricular myocardium. Experimental results show that the proposed method quantitatively and qualitatively outperforms competing methods.
Spatial Aware Multi-Task Learning Based Speech Separation
Jul 20, 2022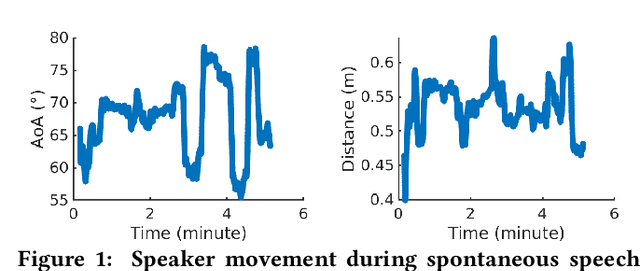
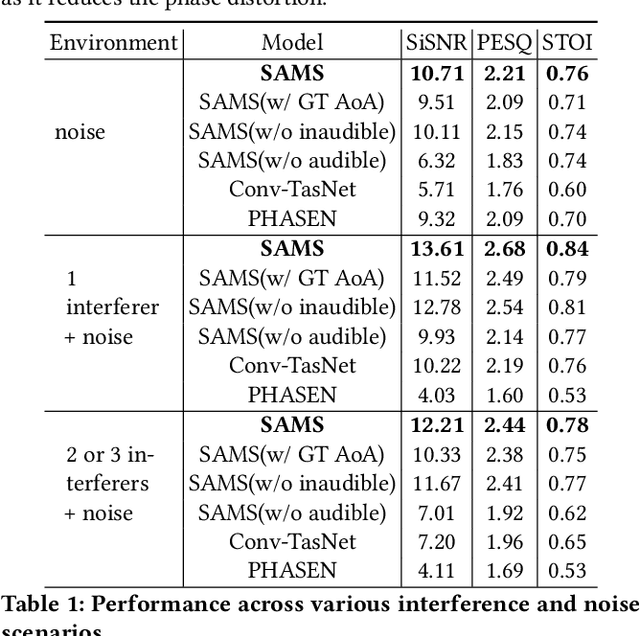
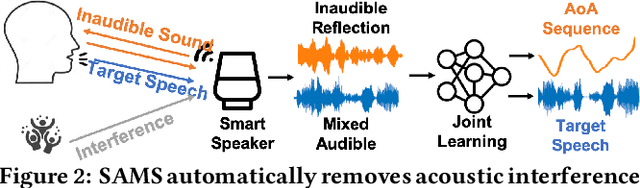
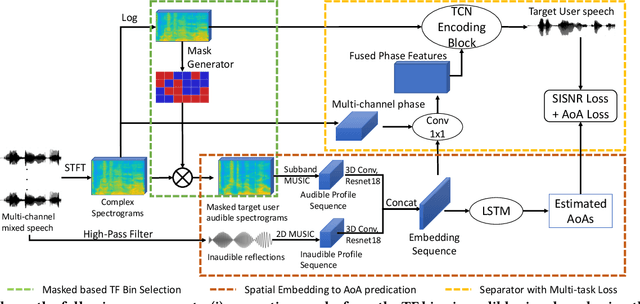
During the Covid, online meetings have become an indispensable part of our lives. This trend is likely to continue due to their convenience and broad reach. However, background noise from other family members, roommates, office-mates not only degrades the voice quality but also raises serious privacy issues. In this paper, we develop a novel system, called Spatial Aware Multi-task learning-based Separation (SAMS), to extract audio signals from the target user during teleconferencing. Our solution consists of three novel components: (i) generating fine-grained location embeddings from the user's voice and inaudible tracking sound, which contains the user's position and rich multipath information, (ii) developing a source separation neural network using multi-task learning to jointly optimize source separation and location, and (iii) significantly speeding up inference to provide a real-time guarantee. Our testbed experiments demonstrate the effectiveness of our approach
Contrastive Learning from Spatio-Temporal Mixed Skeleton Sequences for Self-Supervised Skeleton-Based Action Recognition
Jul 07, 2022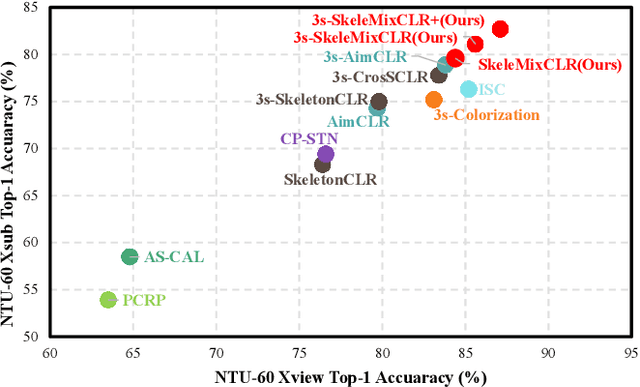
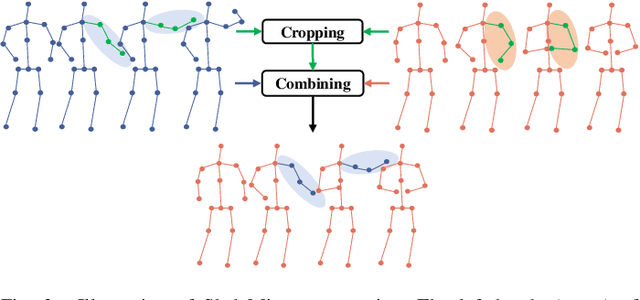
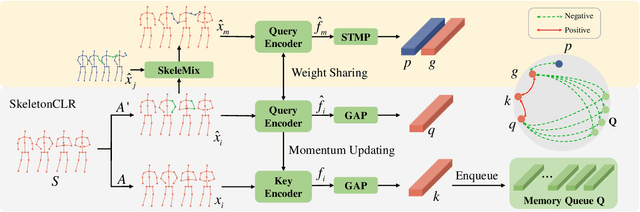
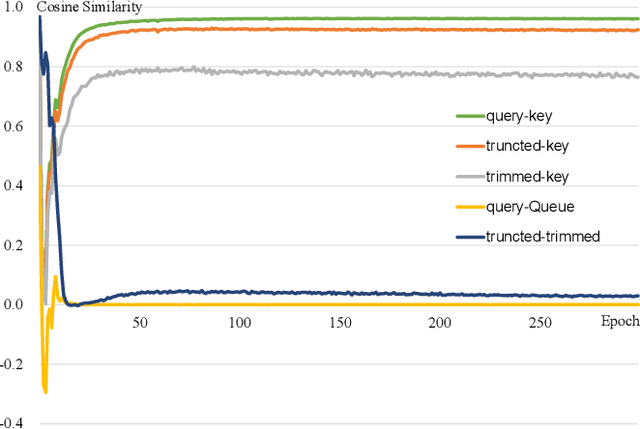
Self-supervised skeleton-based action recognition with contrastive learning has attracted much attention. Recent literature shows that data augmentation and large sets of contrastive pairs are crucial in learning such representations. In this paper, we found that directly extending contrastive pairs based on normal augmentations brings limited returns in terms of performance, because the contribution of contrastive pairs from the normal data augmentation to the loss get smaller as training progresses. Therefore, we delve into hard contrastive pairs for contrastive learning. Motivated by the success of mixing augmentation strategy which improves the performance of many tasks by synthesizing novel samples, we propose SkeleMixCLR: a contrastive learning framework with a spatio-temporal skeleton mixing augmentation (SkeleMix) to complement current contrastive learning approaches by providing hard contrastive samples. First, SkeleMix utilizes the topological information of skeleton data to mix two skeleton sequences by randomly combing the cropped skeleton fragments (the trimmed view) with the remaining skeleton sequences (the truncated view). Second, a spatio-temporal mask pooling is applied to separate these two views at the feature level. Third, we extend contrastive pairs with these two views. SkeleMixCLR leverages the trimmed and truncated views to provide abundant hard contrastive pairs since they involve some context information from each other due to the graph convolution operations, which allows the model to learn better motion representations for action recognition. Extensive experiments on NTU-RGB+D, NTU120-RGB+D, and PKU-MMD datasets show that SkeleMixCLR achieves state-of-the-art performance. Codes are available at https://github.com/czhaneva/SkeleMixCLR.