 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCardiac Mesh Flow: One-Step Generation of 3D+t Cardiac Four-Chamber Meshes via Flow Matching
May 03, 2026Spatio-temporal (3D+t) generative modelling of cardiac shape and motion is crucial for understanding heart structure and function at population scale. Existing generative models for cardiac shape synthesis either adopt volumetric shape representations that lack anatomical correspondence across different time points and subjects, or rely on VAE-based frameworks that suffer from a trade-off between reconstruction fidelity and generative diversity. In this work, we propose Cardiac Mesh Flow, a novel generative flow model for 3D+t cardiac four-chamber mesh generation with anatomical correspondence, temporal coherence, and periodic consistency. Leveraging the flow matching technique, Cardiac Mesh Flow performs efficient one-step generation of multi-scale free-form deformation fields, which warp a template mesh to generate cardiac four-chamber meshes across a cardiac cycle. Furthermore, Cardiac Mesh Flow enables controllable generation conditioned on cardiac chamber volumes, allowing precise control of the synthetic heart. Experimental results demonstrate that Cardiac Mesh Flow achieves high fidelity and diversity on both unconditional and conditional generation, compared to state-of-the-art 3D+t cardiac mesh generation methods.
AdamFlow: Adam-based Wasserstein Gradient Flows for Surface Registration in Medical Imaging
Apr 02, 2026Surface registration plays an important role for anatomical shape analysis in medical imaging. Existing surface registration methods often face a trade-off between efficiency and robustness. Local point matching methods are computationally efficient, but vulnerable to noise and initialisation. Methods designed for global point set alignment tend to incur a high computational cost. To address the challenge, here we present a fast surface registration method, which formulates surface meshes as probability measures and surface registration as a distributional optimisation problem. The discrepancy between two meshes is measured using an efficient sliced Wasserstein distance with log-linear computational complexity. We propose a novel optimisation method, AdamFlow, which generalises the well-known Adam optimisation method from the Euclidean space to the probability space for minimising the sliced Wasserstein distance. We theoretically analyse the asymptotic convergence of AdamFlow and empirically demonstrate its superior performance in both affine and non-rigid surface registration across various anatomical structures.
Learning a dynamic four-chamber shape model of the human heart for 95,695 UK Biobank participants
Mar 30, 2026The human heart is a sophisticated system composed of four cardiac chambers with distinct shapes, which function in a coordinated manner. Existing shape models of the heart mainly focus on the ventricular chambers and they are derived from relatively small datasets. Here, we present a spatio-temporal (3D+t) statistical shape model of all four cardiac chambers, learnt from a large population of nearly 100,000 participants from the UK Biobank. A deep learning-based pipeline is developed to reconstruct 3D+t four-chamber meshes from the cardiac magnetic resonance images of the UK Biobank imaging population. Based on the reconstructed meshes, a 3D+t statistical shape model is learnt to characterise the shape variations and motion patterns of the four cardiac chambers. We reveal the associations of the four-chamber shape model with demographics, anthropometrics, cardiovascular risk factors, and cardiac diseases. Compared to conventional image-derived phenotypes, we validate that the four-chamber shape-derived phenotypes significantly enhance the performance in downstream tasks, including cardiovascular disease classification and heart age prediction. Furthermore, we demonstrate the effectiveness of shape-derived phenotypes in novel applications such as heart shape retrieval and heart re-identification from longitudinal data. To facilitate future research, we will release the learning-based mesh reconstruction pipeline, the four-chamber cardiac shape model, and return all derived four-chamber meshes to the UK Biobank.
MCM: Mamba-based Cardiac Motion Tracking using Sequential Images in MRI
Jul 23, 2025Myocardial motion tracking is important for assessing cardiac function and diagnosing cardiovascular diseases, for which cine cardiac magnetic resonance (CMR) has been established as the gold standard imaging modality. Many existing methods learn motion from single image pairs consisting of a reference frame and a randomly selected target frame from the cardiac cycle. However, these methods overlook the continuous nature of cardiac motion and often yield inconsistent and non-smooth motion estimations. In this work, we propose a novel Mamba-based cardiac motion tracking network (MCM) that explicitly incorporates target image sequence from the cardiac cycle to achieve smooth and temporally consistent motion tracking. By developing a bi-directional Mamba block equipped with a bi-directional scanning mechanism, our method facilitates the estimation of plausible deformation fields. With our proposed motion decoder that integrates motion information from frames adjacent to the target frame, our method further enhances temporal coherence. Moreover, by taking advantage of Mamba's structured state-space formulation, the proposed method learns the continuous dynamics of the myocardium from sequential images without increasing computational complexity. We evaluate the proposed method on two public datasets. The experimental results demonstrate that the proposed method quantitatively and qualitatively outperforms both conventional and state-of-the-art learning-based cardiac motion tracking methods. The code is available at https://github.com/yjh-0104/MCM.
EchoFlow: A Foundation Model for Cardiac Ultrasound Image and Video Generation
Mar 28, 2025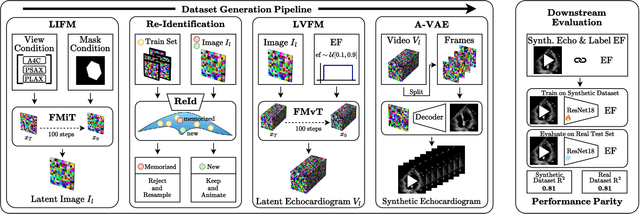
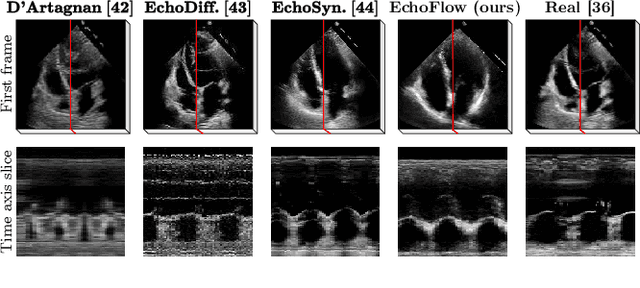
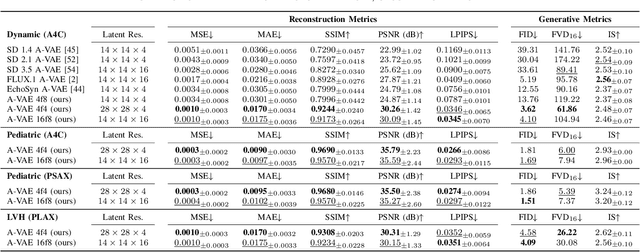
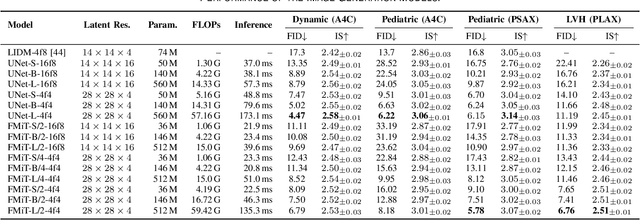
Advances in deep learning have significantly enhanced medical image analysis, yet the availability of large-scale medical datasets remains constrained by patient privacy concerns. We present EchoFlow, a novel framework designed to generate high-quality, privacy-preserving synthetic echocardiogram images and videos. EchoFlow comprises four key components: an adversarial variational autoencoder for defining an efficient latent representation of cardiac ultrasound images, a latent image flow matching model for generating accurate latent echocardiogram images, a latent re-identification model to ensure privacy by filtering images anatomically, and a latent video flow matching model for animating latent images into realistic echocardiogram videos conditioned on ejection fraction. We rigorously evaluate our synthetic datasets on the clinically relevant task of ejection fraction regression and demonstrate, for the first time, that downstream models trained exclusively on EchoFlow-generated synthetic datasets achieve performance parity with models trained on real datasets. We release our models and synthetic datasets, enabling broader, privacy-compliant research in medical ultrasound imaging at https://huggingface.co/spaces/HReynaud/EchoFlow.
SACB-Net: Spatial-awareness Convolutions for Medical Image Registration
Mar 25, 2025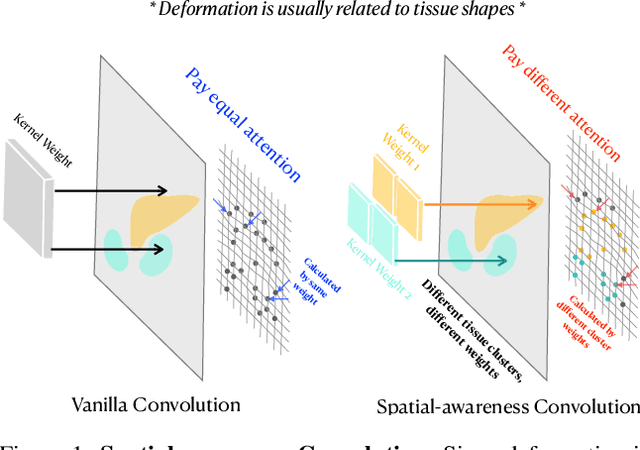
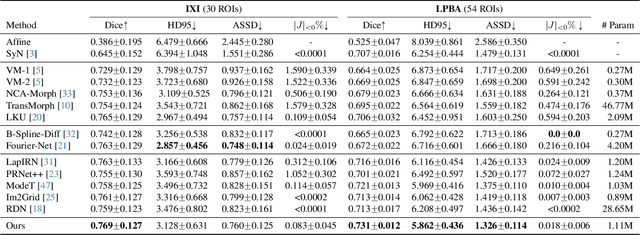
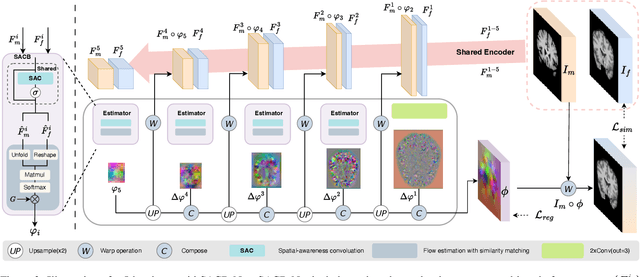
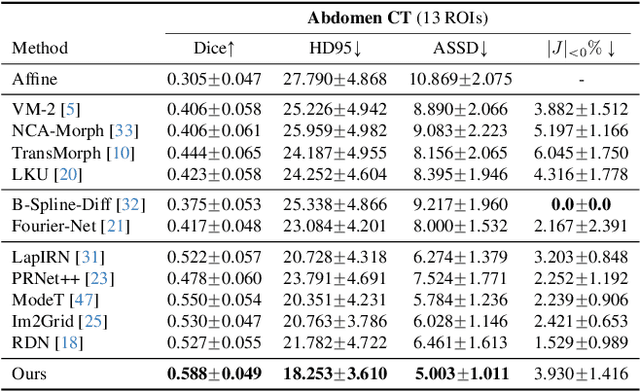
Deep learning-based image registration methods have shown state-of-the-art performance and rapid inference speeds. Despite these advances, many existing approaches fall short in capturing spatially varying information in non-local regions of feature maps due to the reliance on spatially-shared convolution kernels. This limitation leads to suboptimal estimation of deformation fields. In this paper, we propose a 3D Spatial-Awareness Convolution Block (SACB) to enhance the spatial information within feature representations. Our SACB estimates the spatial clusters within feature maps by leveraging feature similarity and subsequently parameterizes the adaptive convolution kernels across diverse regions. This adaptive mechanism generates the convolution kernels (weights and biases) tailored to spatial variations, thereby enabling the network to effectively capture spatially varying information. Building on SACB, we introduce a pyramid flow estimator (named SACB-Net) that integrates SACBs to facilitate multi-scale flow composition, particularly addressing large deformations. Experimental results on the brain IXI and LPBA datasets as well as Abdomen CT datasets demonstrate the effectiveness of SACB and the superiority of SACB-Net over the state-of-the-art learning-based registration methods. The code is available at https://github.com/x-xc/SACB_Net .
JVID: Joint Video-Image Diffusion for Visual-Quality and Temporal-Consistency in Video Generation
Sep 21, 2024



We introduce the Joint Video-Image Diffusion model (JVID), a novel approach to generating high-quality and temporally coherent videos. We achieve this by integrating two diffusion models: a Latent Image Diffusion Model (LIDM) trained on images and a Latent Video Diffusion Model (LVDM) trained on video data. Our method combines these models in the reverse diffusion process, where the LIDM enhances image quality and the LVDM ensures temporal consistency. This unique combination allows us to effectively handle the complex spatio-temporal dynamics in video generation. Our results demonstrate quantitative and qualitative improvements in producing realistic and coherent videos.
EchoNet-Synthetic: Privacy-preserving Video Generation for Safe Medical Data Sharing
Jun 02, 2024To make medical datasets accessible without sharing sensitive patient information, we introduce a novel end-to-end approach for generative de-identification of dynamic medical imaging data. Until now, generative methods have faced constraints in terms of fidelity, spatio-temporal coherence, and the length of generation, failing to capture the complete details of dataset distributions. We present a model designed to produce high-fidelity, long and complete data samples with near-real-time efficiency and explore our approach on a challenging task: generating echocardiogram videos. We develop our generation method based on diffusion models and introduce a protocol for medical video dataset anonymization. As an exemplar, we present EchoNet-Synthetic, a fully synthetic, privacy-compliant echocardiogram dataset with paired ejection fraction labels. As part of our de-identification protocol, we evaluate the quality of the generated dataset and propose to use clinical downstream tasks as a measurement on top of widely used but potentially biased image quality metrics. Experimental outcomes demonstrate that EchoNet-Synthetic achieves comparable dataset fidelity to the actual dataset, effectively supporting the ejection fraction regression task. Code, weights and dataset are available at https://github.com/HReynaud/EchoNet-Synthetic.
DeepMesh: Mesh-based Cardiac Motion Tracking using Deep Learning
Sep 25, 2023



3D motion estimation from cine cardiac magnetic resonance (CMR) images is important for the assessment of cardiac function and the diagnosis of cardiovascular diseases. Current state-of-the art methods focus on estimating dense pixel-/voxel-wise motion fields in image space, which ignores the fact that motion estimation is only relevant and useful within the anatomical objects of interest, e.g., the heart. In this work, we model the heart as a 3D mesh consisting of epi- and endocardial surfaces. We propose a novel learning framework, DeepMesh, which propagates a template heart mesh to a subject space and estimates the 3D motion of the heart mesh from CMR images for individual subjects. In DeepMesh, the heart mesh of the end-diastolic frame of an individual subject is first reconstructed from the template mesh. Mesh-based 3D motion fields with respect to the end-diastolic frame are then estimated from 2D short- and long-axis CMR images. By developing a differentiable mesh-to-image rasterizer, DeepMesh is able to leverage 2D shape information from multiple anatomical views for 3D mesh reconstruction and mesh motion estimation. The proposed method estimates vertex-wise displacement and thus maintains vertex correspondences between time frames, which is important for the quantitative assessment of cardiac function across different subjects and populations. We evaluate DeepMesh on CMR images acquired from the UK Biobank. We focus on 3D motion estimation of the left ventricle in this work. Experimental results show that the proposed method quantitatively and qualitatively outperforms other image-based and mesh-based cardiac motion tracking methods.
Mesh-based 3D Motion Tracking in Cardiac MRI using Deep Learning
Sep 05, 2022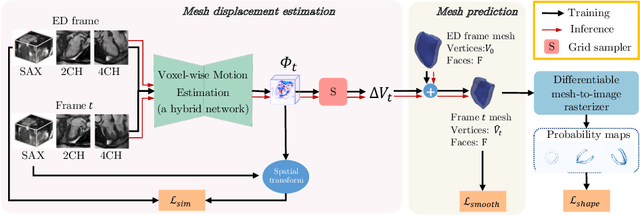
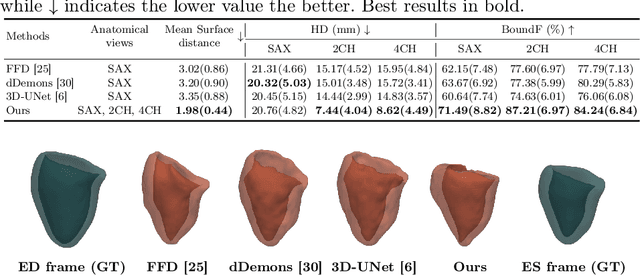
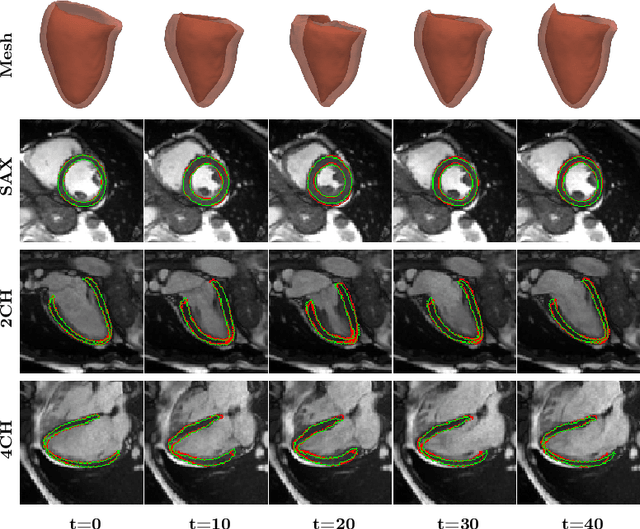

3D motion estimation from cine cardiac magnetic resonance (CMR) images is important for the assessment of cardiac function and diagnosis of cardiovascular diseases. Most of the previous methods focus on estimating pixel-/voxel-wise motion fields in the full image space, which ignore the fact that motion estimation is mainly relevant and useful within the object of interest, e.g., the heart. In this work, we model the heart as a 3D geometric mesh and propose a novel deep learning-based method that can estimate 3D motion of the heart mesh from 2D short- and long-axis CMR images. By developing a differentiable mesh-to-image rasterizer, the method is able to leverage the anatomical shape information from 2D multi-view CMR images for 3D motion estimation. The differentiability of the rasterizer enables us to train the method end-to-end. One advantage of the proposed method is that by tracking the motion of each vertex, it is able to keep the vertex correspondence of 3D meshes between time frames, which is important for quantitative assessment of the cardiac function on the mesh. We evaluate the proposed method on CMR images acquired from the UK Biobank study. Experimental results show that the proposed method quantitatively and qualitatively outperforms both conventional and learning-based cardiac motion tracking methods.