 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Task Aligned Meta-learning based Augmented Graph for Cold-Start Recommendation
Aug 11, 2022
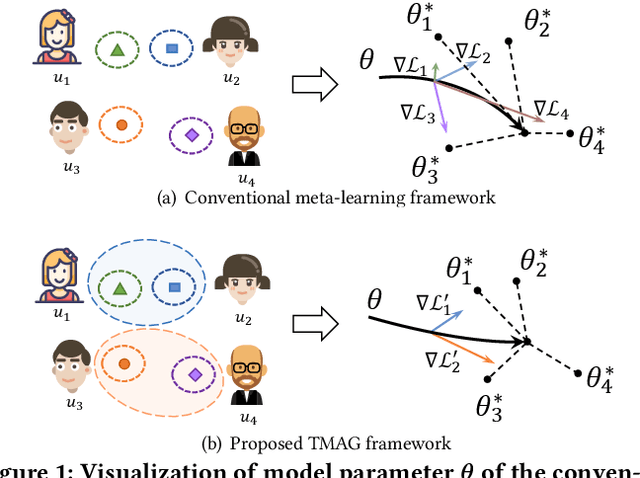
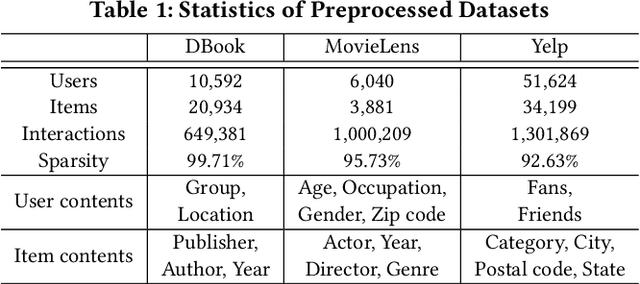
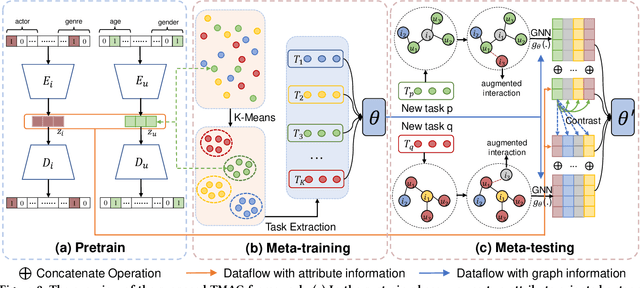
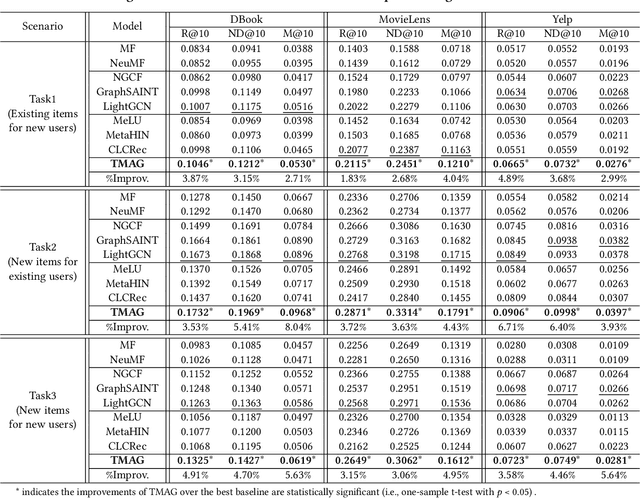
The cold-start problem is a long-standing challenge in recommender systems due to the lack of user-item interactions, which significantly hurts the recommendation effect over new users and items. Recently, meta-learning based methods attempt to learn globally shared prior knowledge across all users, which can be rapidly adapted to new users and items with very few interactions. Though with significant performance improvement, the globally shared parameter may lead to local optimum. Besides, they are oblivious to the inherent information and feature interactions existing in the new users and items, which are critical in cold-start scenarios. In this paper, we propose a Task aligned Meta-learning based Augmented Graph (TMAG) to address cold-start recommendation. Specifically, a fine-grained task aligned constructor is proposed to cluster similar users and divide tasks for meta-learning, enabling consistent optimization direction. Besides, an augmented graph neural network with two graph enhanced approaches is designed to alleviate data sparsity and capture the high-order user-item interactions. We validate our approach on three real-world datasets in various cold-start scenarios, showing the superiority of TMAG over state-of-the-art methods for cold-start recommendation.
Multiclass-SGCN: Sparse Graph-based Trajectory Prediction with Agent Class Embedding
Jun 30, 2022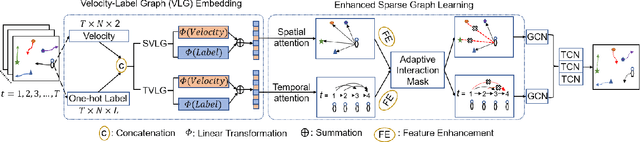
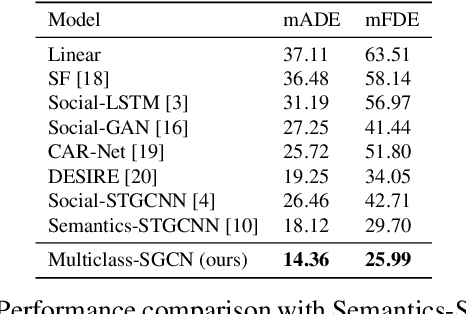
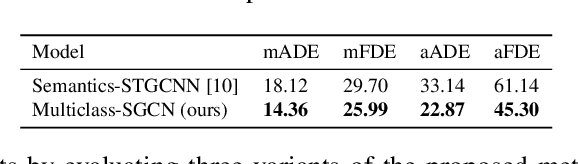
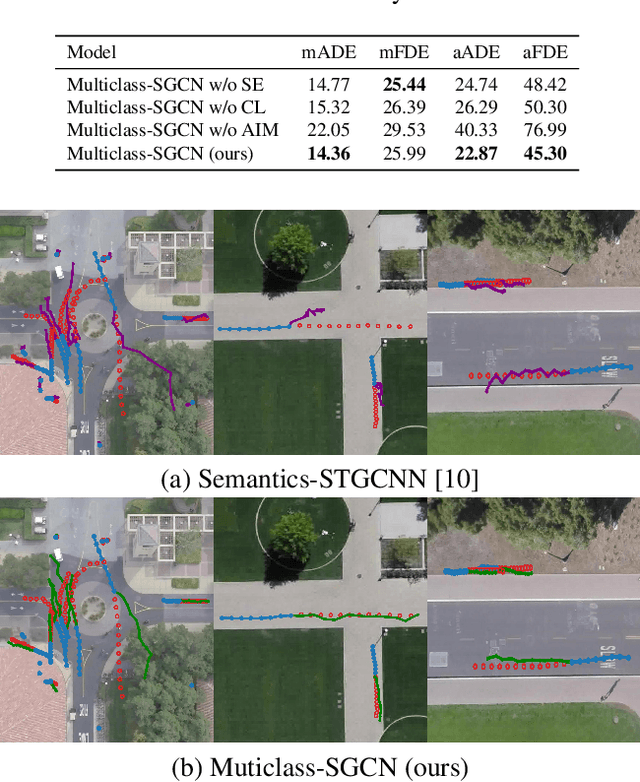
Trajectory prediction of road users in real-world scenarios is challenging because their movement patterns are stochastic and complex. Previous pedestrian-oriented works have been successful in modelling the complex interactions among pedestrians, but fail in predicting trajectories when other types of road users are involved (e.g., cars, cyclists, etc.), because they ignore user types. Although a few recent works construct densely connected graphs with user label information, they suffer from superfluous spatial interactions and temporal dependencies. To address these issues, we propose Multiclass-SGCN, a sparse graph convolution network based approach for multi-class trajectory prediction that takes into consideration velocity and agent label information and uses a novel interaction mask to adaptively decide the spatial and temporal connections of agents based on their interaction scores. The proposed approach significantly outperformed state-of-the-art approaches on the Stanford Drone Dataset, providing more realistic and plausible trajectory predictions.
Learning Based Joint Coding-Modulation for Digital Semantic Communication Systems
Aug 11, 2022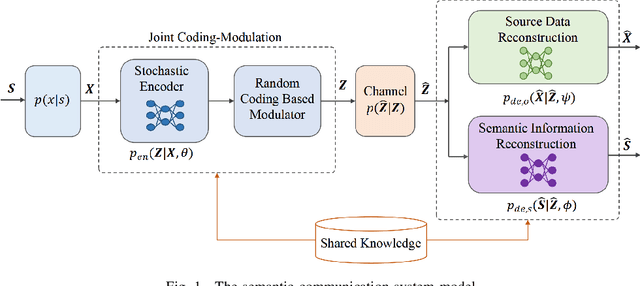
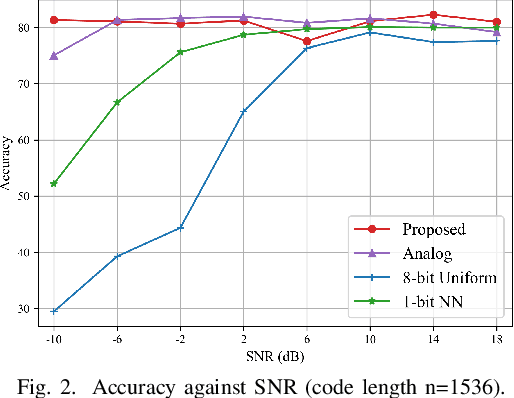
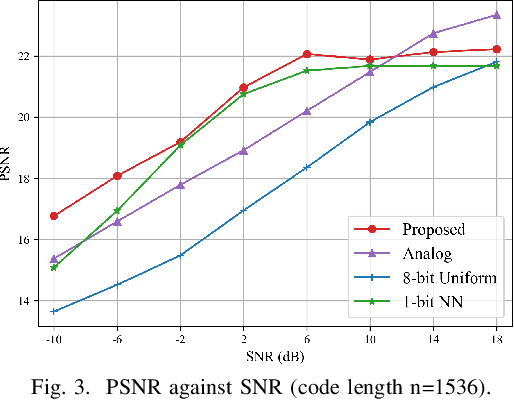
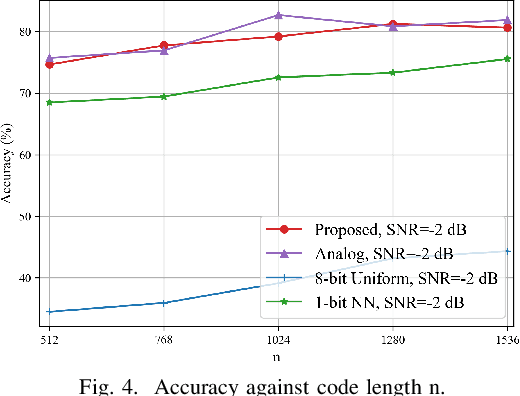
In learning-based semantic communications, neural networks have replaced different building blocks in traditional communication systems. However, the digital modulation still remains a challenge for neural networks. The intrinsic mechanism of neural network based digital modulation is mapping continuous output of the neural network encoder into discrete constellation symbols, which is a non-differentiable function that cannot be trained with existing gradient descend algorithms. To overcome this challenge, in this paper we develop a joint coding-modulation scheme for digital semantic communications with BPSK modulation. In our method, the neural network outputs the likelihood of each constellation point, instead of having a concrete mapping. A random code rather than a deterministic code is hence used, which preserves more information for the symbols with a close likelihood on each constellation point. The joint coding-modulation design can match the modulation process with channel states, and hence improve the performance of digital semantic communications. Experiment results show that our method outperforms existing digital modulation methods in semantic communications over a wide range of SNR, and outperforms neural network based analog modulation method in low SNR regime.
Semantic Enhanced Text-to-SQL Parsing via Iteratively Learning Schema Linking Graph
Aug 08, 2022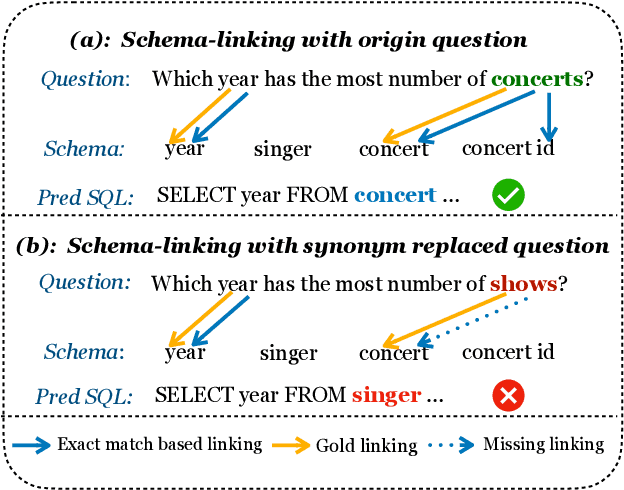
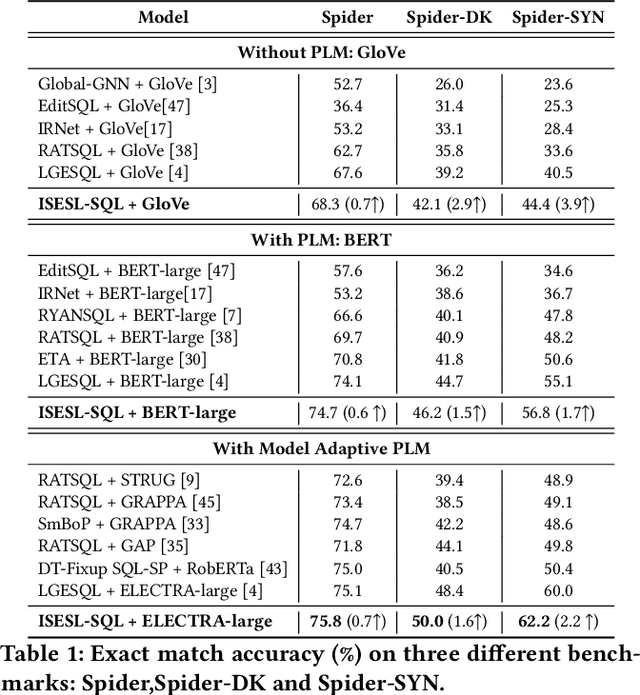
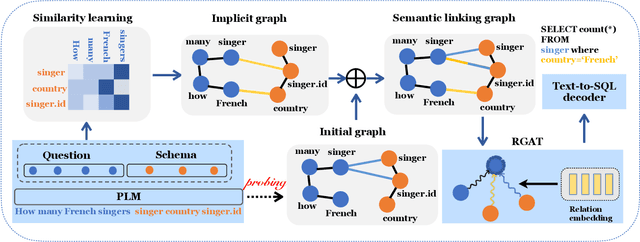
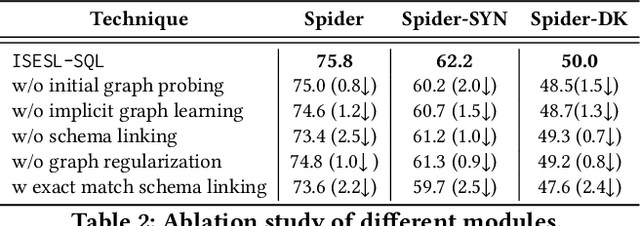
The generalizability to new databases is of vital importance to Text-to-SQL systems which aim to parse human utterances into SQL statements. Existing works achieve this goal by leveraging the exact matching method to identify the lexical matching between the question words and the schema items. However, these methods fail in other challenging scenarios, such as the synonym substitution in which the surface form differs between the corresponding question words and schema items. In this paper, we propose a framework named ISESL-SQL to iteratively build a semantic enhanced schema-linking graph between question tokens and database schemas. First, we extract a schema linking graph from PLMs through a probing procedure in an unsupervised manner. Then the schema linking graph is further optimized during the training process through a deep graph learning method. Meanwhile, we also design an auxiliary task called graph regularization to improve the schema information mentioned in the schema-linking graph. Extensive experiments on three benchmarks demonstrate that ISESL-SQL could consistently outperform the baselines and further investigations show its generalizability and robustness.
Impact Makes a Sound and Sound Makes an Impact: Sound Guides Representations and Explorations
Aug 04, 2022
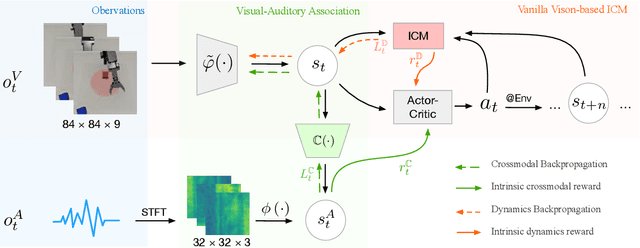
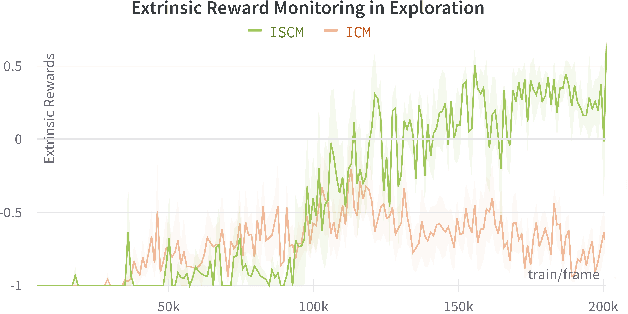
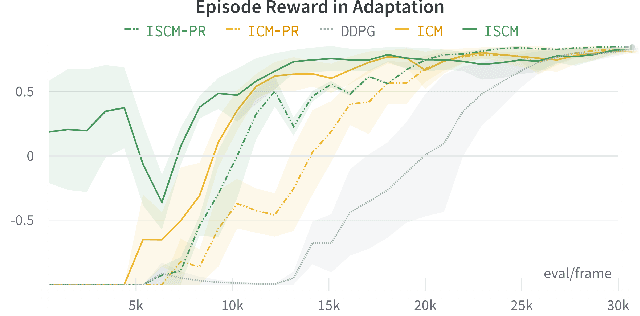
Sound is one of the most informative and abundant modalities in the real world while being robust to sense without contacts by small and cheap sensors that can be placed on mobile devices. Although deep learning is capable of extracting information from multiple sensory inputs, there has been little use of sound for the control and learning of robotic actions. For unsupervised reinforcement learning, an agent is expected to actively collect experiences and jointly learn representations and policies in a self-supervised way. We build realistic robotic manipulation scenarios with physics-based sound simulation and propose the Intrinsic Sound Curiosity Module (ISCM). The ISCM provides feedback to a reinforcement learner to learn robust representations and to reward a more efficient exploration behavior. We perform experiments with sound enabled during pre-training and disabled during adaptation, and show that representations learned by ISCM outperform the ones by vision-only baselines and pre-trained policies can accelerate the learning process when applied to downstream tasks.
Using Atom-Like Local Image Features to Study Human Genetics and Neuroanatomy in Large Sets of 3D Medical Image Volumes
Aug 25, 2022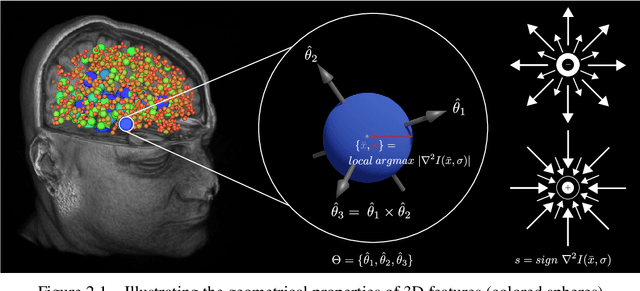
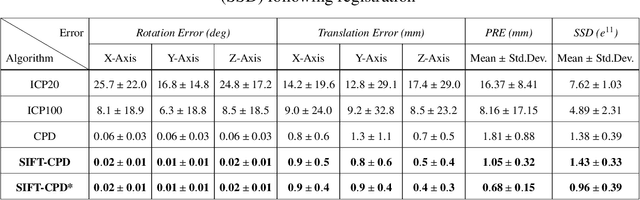
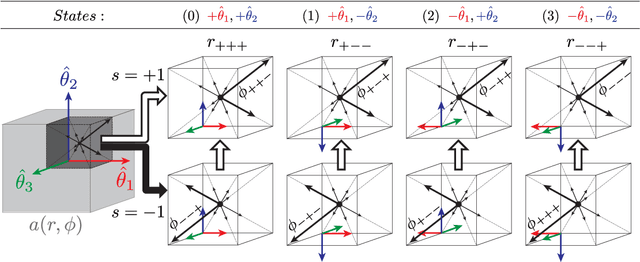
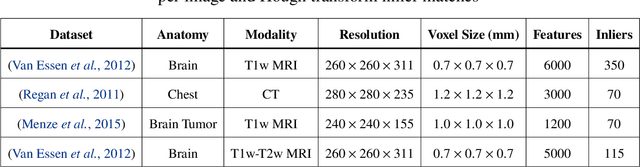
The contributions of this thesis stem from technology developed to analyse large sets of volumetric images in terms of atom-like features extracted in 3D image space, following SIFT algorithm in 2D image space. New feature properties are introduced including a binary feature sign, analogous to an electrical charge, and a discrete set of symmetric feature orientation states in 3D space. These new properties are leveraged to extend feature invariance to include the sign inversion and parity (SP) transform, analogous to the charge conjugation and parity (CP) transform between a particle and its antiparticle in quantum mechanics, thereby accounting for local intensity contrast inversion between imaging modalities and axis reflections due to shape symmetry. A novel exponential kernel is proposed to quantify the similarity of a pair of features extracted in different images from their properties including location, scale, orientation, sign and appearance. A novel measure entitled the soft Jaccard is proposed to quantify the similarity of a pair of feature sets based on their overlap or intersection-over-union, where a kernel establishes non-binary or soft equivalence between a pair of feature elements. The soft Jaccard may be used to identify pairs of feature sets extracted from the same individuals or families with high accuracy, and a simple distance threshold led to the surprising discovery of previously unknown individual and family labeling errors in major public neuroimage datasets. A new algorithm is proposed to register or spatially align a pair of feature sets, entitled SIFT Coherent Point Drift (SIFT-CPD), by identifying a transform that maximizes the soft Jaccard between a fixed feature set and a transformed set. SIFT-CPD achieves faster and more accurate registration than the original CPD algorithm based on feature location information alone, in a variety of challenging.
Information Theory in Density Destructors
Dec 02, 2020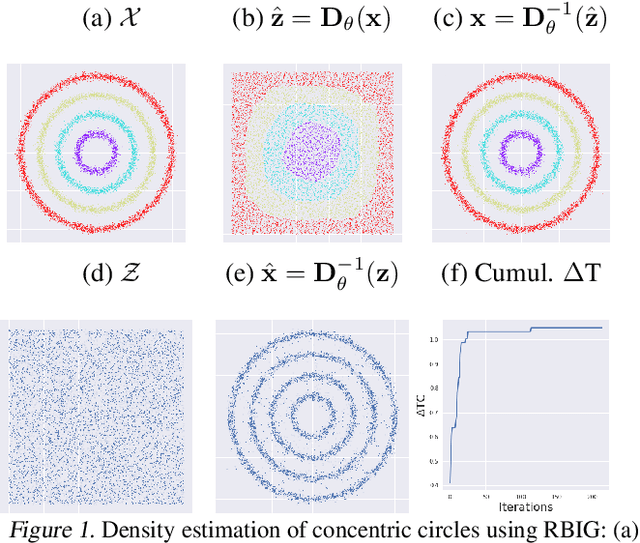
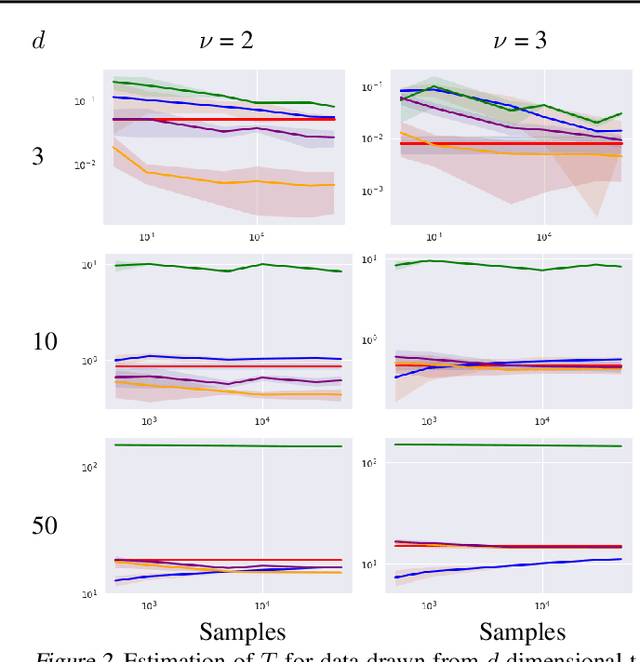
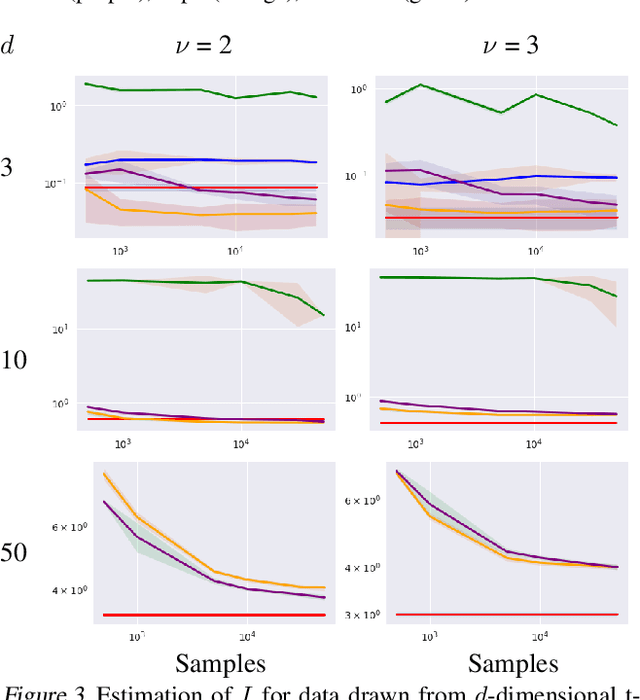
Density destructors are differentiable and invertible transforms that map multivariate PDFs of arbitrary structure (low entropy) into non-structured PDFs (maximum entropy). Multivariate Gaussianization and multivariate equalization are specific examples of this family, which break down the complexity of the original PDF through a set of elementary transforms that progressively remove the structure of the data. We demonstrate how this property of density destructive flows is connected to classical information theory, and how density destructors can be used to get more accurate estimates of information theoretic quantities. Experiments with total correlation and mutual information inmultivariate sets illustrate the ability of density destructors compared to competing methods. These results suggest that information theoretic measures may be an alternative optimization criteria when learning density destructive flows.
Surgical Skill Assessment via Video Semantic Aggregation
Aug 04, 2022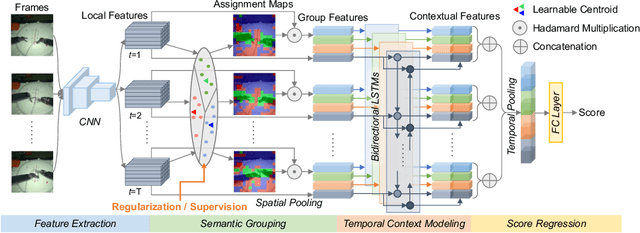
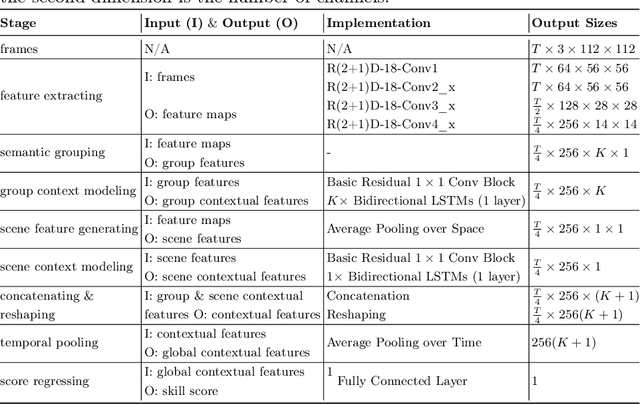
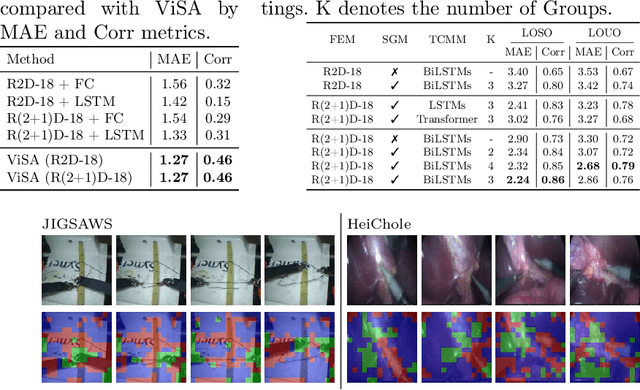
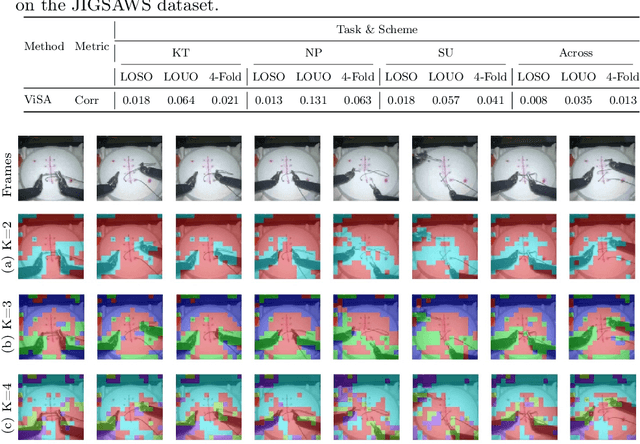
Automated video-based assessment of surgical skills is a promising task in assisting young surgical trainees, especially in poor-resource areas. Existing works often resort to a CNN-LSTM joint framework that models long-term relationships by LSTMs on spatially pooled short-term CNN features. However, this practice would inevitably neglect the difference among semantic concepts such as tools, tissues, and background in the spatial dimension, impeding the subsequent temporal relationship modeling. In this paper, we propose a novel skill assessment framework, Video Semantic Aggregation (ViSA), which discovers different semantic parts and aggregates them across spatiotemporal dimensions. The explicit discovery of semantic parts provides an explanatory visualization that helps understand the neural network's decisions. It also enables us to further incorporate auxiliary information such as the kinematic data to improve representation learning and performance. The experiments on two datasets show the competitiveness of ViSA compared to state-of-the-art methods. Source code is available at: bit.ly/MICCAI2022ViSA.
Auditing Membership Leakages of Multi-Exit Networks
Aug 23, 2022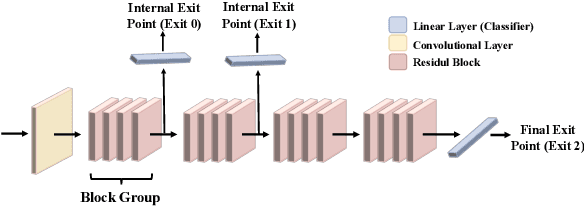
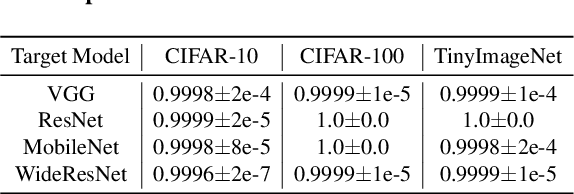
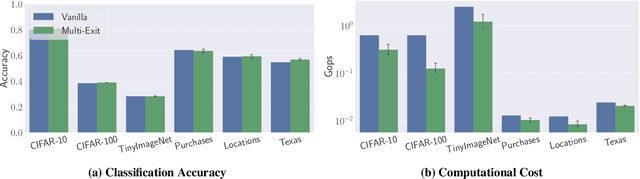
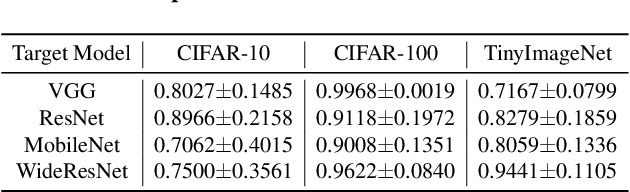
Relying on the fact that not all inputs require the same amount of computation to yield a confident prediction, multi-exit networks are gaining attention as a prominent approach for pushing the limits of efficient deployment. Multi-exit networks endow a backbone model with early exits, allowing to obtain predictions at intermediate layers of the model and thus save computation time and/or energy. However, current various designs of multi-exit networks are only considered to achieve the best trade-off between resource usage efficiency and prediction accuracy, the privacy risks stemming from them have never been explored. This prompts the need for a comprehensive investigation of privacy risks in multi-exit networks. In this paper, we perform the first privacy analysis of multi-exit networks through the lens of membership leakages. In particular, we first leverage the existing attack methodologies to quantify the multi-exit networks' vulnerability to membership leakages. Our experimental results show that multi-exit networks are less vulnerable to membership leakages and the exit (number and depth) attached to the backbone model is highly correlated with the attack performance. Furthermore, we propose a hybrid attack that exploits the exit information to improve the performance of existing attacks. We evaluate membership leakage threat caused by our hybrid attack under three different adversarial setups, ultimately arriving at a model-free and data-free adversary. These results clearly demonstrate that our hybrid attacks are very broadly applicable, thereby the corresponding risks are much more severe than shown by existing membership inference attacks. We further present a defense mechanism called TimeGuard specifically for multi-exit networks and show that TimeGuard mitigates the newly proposed attacks perfectly.
Crafting Monocular Cues and Velocity Guidance for Self-Supervised Multi-Frame Depth Learning
Aug 19, 2022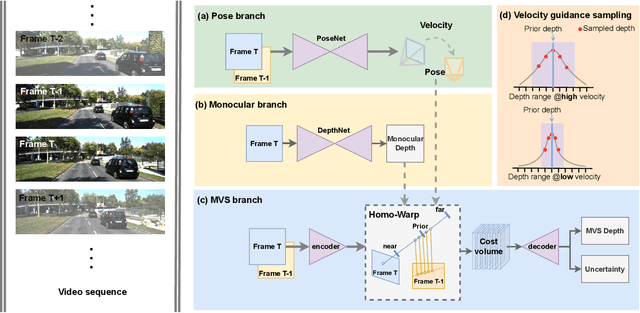
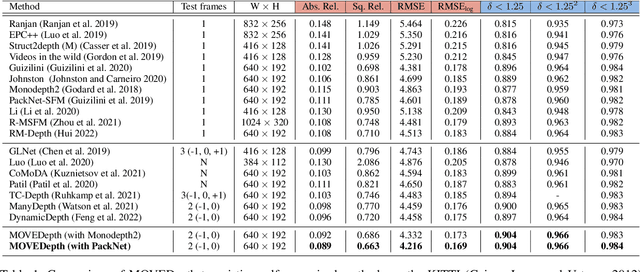
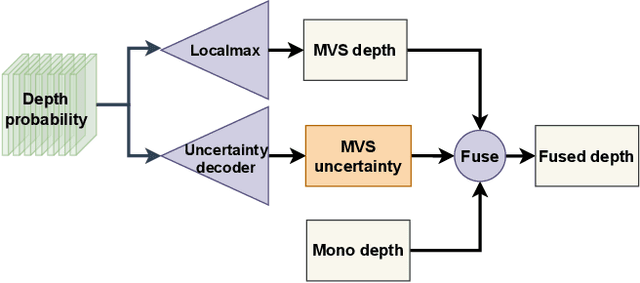
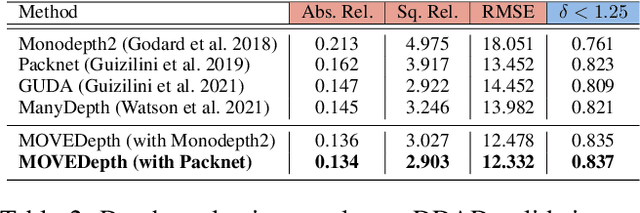
Self-supervised monocular methods can efficiently learn depth information of weakly textured surfaces or reflective objects. However, the depth accuracy is limited due to the inherent ambiguity in monocular geometric modeling. In contrast, multi-frame depth estimation methods improve the depth accuracy thanks to the success of Multi-View Stereo (MVS), which directly makes use of geometric constraints. Unfortunately, MVS often suffers from texture-less regions, non-Lambertian surfaces, and moving objects, especially in real-world video sequences without known camera motion and depth supervision. Therefore, we propose MOVEDepth, which exploits the MOnocular cues and VElocity guidance to improve multi-frame Depth learning. Unlike existing methods that enforce consistency between MVS depth and monocular depth, MOVEDepth boosts multi-frame depth learning by directly addressing the inherent problems of MVS. The key of our approach is to utilize monocular depth as a geometric priority to construct MVS cost volume, and adjust depth candidates of cost volume under the guidance of predicted camera velocity. We further fuse monocular depth and MVS depth by learning uncertainty in the cost volume, which results in a robust depth estimation against ambiguity in multi-view geometry. Extensive experiments show MOVEDepth achieves state-of-the-art performance: Compared with Monodepth2 and PackNet, our method relatively improves the depth accuracy by 20\% and 19.8\% on the KITTI benchmark. MOVEDepth also generalizes to the more challenging DDAD benchmark, relatively outperforming ManyDepth by 7.2\%. The code is available at https://github.com/JeffWang987/MOVEDepth.