 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSoK: Data Reconstruction Attacks Against Machine Learning Models: Definition, Metrics, and Benchmark
Jun 09, 2025Data reconstruction attacks, which aim to recover the training dataset of a target model with limited access, have gained increasing attention in recent years. However, there is currently no consensus on a formal definition of data reconstruction attacks or appropriate evaluation metrics for measuring their quality. This lack of rigorous definitions and universal metrics has hindered further advancement in this field. In this paper, we address this issue in the vision domain by proposing a unified attack taxonomy and formal definitions of data reconstruction attacks. We first propose a set of quantitative evaluation metrics that consider important criteria such as quantifiability, consistency, precision, and diversity. Additionally, we leverage large language models (LLMs) as a substitute for human judgment, enabling visual evaluation with an emphasis on high-quality reconstructions. Using our proposed taxonomy and metrics, we present a unified framework for systematically evaluating the strengths and limitations of existing attacks and establishing a benchmark for future research. Empirical results, primarily from a memorization perspective, not only validate the effectiveness of our metrics but also offer valuable insights for designing new attacks.
Transferable Availability Poisoning Attacks
Oct 08, 2023



We consider availability data poisoning attacks, where an adversary aims to degrade the overall test accuracy of a machine learning model by crafting small perturbations to its training data. Existing poisoning strategies can achieve the attack goal but assume the victim to employ the same learning method as what the adversary uses to mount the attack. In this paper, we argue that this assumption is strong, since the victim may choose any learning algorithm to train the model as long as it can achieve some targeted performance on clean data. Empirically, we observe a large decrease in the effectiveness of prior poisoning attacks if the victim uses a different learning paradigm to train the model and show marked differences in frequency-level characteristics between perturbations generated with respect to different learners and attack methods. To enhance the attack transferability, we propose Transferable Poisoning, which generates high-frequency poisoning perturbations by alternately leveraging the gradient information with two specific algorithms selected from supervised and unsupervised contrastive learning paradigms. Through extensive experiments on benchmark image datasets, we show that our transferable poisoning attack can produce poisoned samples with significantly improved transferability, not only applicable to the two learners used to devise the attack but also for learning algorithms and even paradigms beyond.
Membership Inference Attacks by Exploiting Loss Trajectory
Aug 31, 2022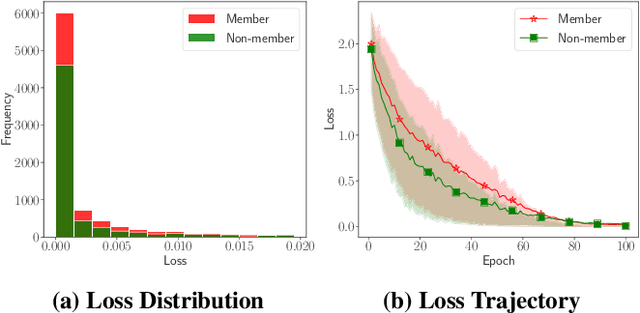
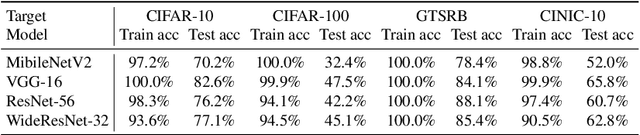
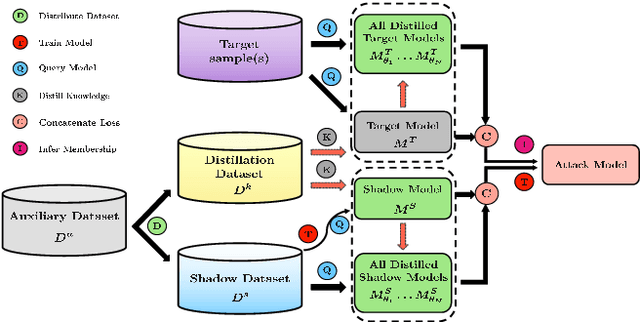

Machine learning models are vulnerable to membership inference attacks in which an adversary aims to predict whether or not a particular sample was contained in the target model's training dataset. Existing attack methods have commonly exploited the output information (mostly, losses) solely from the given target model. As a result, in practical scenarios where both the member and non-member samples yield similarly small losses, these methods are naturally unable to differentiate between them. To address this limitation, in this paper, we propose a new attack method, called \system, which can exploit the membership information from the whole training process of the target model for improving the attack performance. To mount the attack in the common black-box setting, we leverage knowledge distillation, and represent the membership information by the losses evaluated on a sequence of intermediate models at different distillation epochs, namely \emph{distilled loss trajectory}, together with the loss from the given target model. Experimental results over different datasets and model architectures demonstrate the great advantage of our attack in terms of different metrics. For example, on CINIC-10, our attack achieves at least 6$\times$ higher true-positive rate at a low false-positive rate of 0.1\% than existing methods. Further analysis demonstrates the general effectiveness of our attack in more strict scenarios.
Auditing Membership Leakages of Multi-Exit Networks
Aug 23, 2022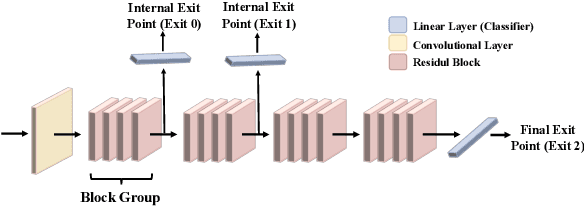
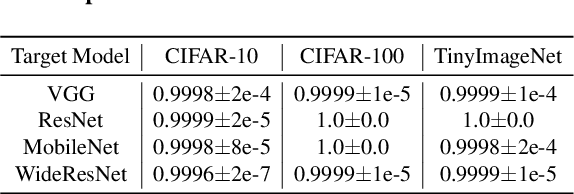
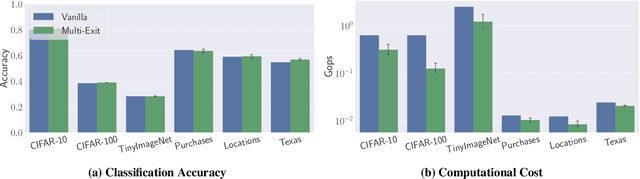
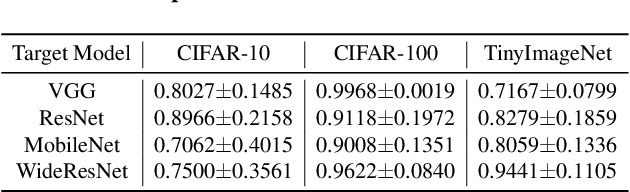
Relying on the fact that not all inputs require the same amount of computation to yield a confident prediction, multi-exit networks are gaining attention as a prominent approach for pushing the limits of efficient deployment. Multi-exit networks endow a backbone model with early exits, allowing to obtain predictions at intermediate layers of the model and thus save computation time and/or energy. However, current various designs of multi-exit networks are only considered to achieve the best trade-off between resource usage efficiency and prediction accuracy, the privacy risks stemming from them have never been explored. This prompts the need for a comprehensive investigation of privacy risks in multi-exit networks. In this paper, we perform the first privacy analysis of multi-exit networks through the lens of membership leakages. In particular, we first leverage the existing attack methodologies to quantify the multi-exit networks' vulnerability to membership leakages. Our experimental results show that multi-exit networks are less vulnerable to membership leakages and the exit (number and depth) attached to the backbone model is highly correlated with the attack performance. Furthermore, we propose a hybrid attack that exploits the exit information to improve the performance of existing attacks. We evaluate membership leakage threat caused by our hybrid attack under three different adversarial setups, ultimately arriving at a model-free and data-free adversary. These results clearly demonstrate that our hybrid attacks are very broadly applicable, thereby the corresponding risks are much more severe than shown by existing membership inference attacks. We further present a defense mechanism called TimeGuard specifically for multi-exit networks and show that TimeGuard mitigates the newly proposed attacks perfectly.