 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Object-Aware Attention Guided Frame Association for RGB-D SLAM
Oct 30, 2025Attention models have recently emerged as a powerful approach, demonstrating significant progress in various fields. Visualization techniques, such as class activation mapping, provide visual insights into the reasoning of convolutional neural networks (CNNs). Using network gradients, it is possible to identify regions where the network pays attention during image recognition tasks. Furthermore, these gradients can be combined with CNN features to localize more generalizable, task-specific attentive (salient) regions within scenes. However, explicit use of this gradient-based attention information integrated directly into CNN representations for semantic object understanding remains limited. Such integration is particularly beneficial for visual tasks like simultaneous localization and mapping (SLAM), where CNN representations enriched with spatially attentive object locations can enhance performance. In this work, we propose utilizing task-specific network attention for RGB-D indoor SLAM. Specifically, we integrate layer-wise attention information derived from network gradients with CNN feature representations to improve frame association performance. Experimental results indicate improved performance compared to baseline methods, particularly for large environments.
Attention-Guided Lidar Segmentation and Odometry Using Image-to-Point Cloud Saliency Transfer
Aug 28, 2023



LiDAR odometry estimation and 3D semantic segmentation are crucial for autonomous driving, which has achieved remarkable advances recently. However, these tasks are challenging due to the imbalance of points in different semantic categories for 3D semantic segmentation and the influence of dynamic objects for LiDAR odometry estimation, which increases the importance of using representative/salient landmarks as reference points for robust feature learning. To address these challenges, we propose a saliency-guided approach that leverages attention information to improve the performance of LiDAR odometry estimation and semantic segmentation models. Unlike in the image domain, only a few studies have addressed point cloud saliency information due to the lack of annotated training data. To alleviate this, we first present a universal framework to transfer saliency distribution knowledge from color images to point clouds, and use this to construct a pseudo-saliency dataset (i.e. FordSaliency) for point clouds. Then, we adopt point cloud-based backbones to learn saliency distribution from pseudo-saliency labels, which is followed by our proposed SalLiDAR module. SalLiDAR is a saliency-guided 3D semantic segmentation model that integrates saliency information to improve segmentation performance. Finally, we introduce SalLONet, a self-supervised saliency-guided LiDAR odometry network that uses the semantic and saliency predictions of SalLiDAR to achieve better odometry estimation. Our extensive experiments on benchmark datasets demonstrate that the proposed SalLiDAR and SalLONet models achieve state-of-the-art performance against existing methods, highlighting the effectiveness of image-to-LiDAR saliency knowledge transfer. Source code will be available at https://github.com/nevrez/SalLONet.
P2Net: A Post-Processing Network for Refining Semantic Segmentation of LiDAR Point Cloud based on Consistency of Consecutive Frames
Dec 01, 2022



We present a lightweight post-processing method to refine the semantic segmentation results of point cloud sequences. Most existing methods usually segment frame by frame and encounter the inherent ambiguity of the problem: based on a measurement in a single frame, labels are sometimes difficult to predict even for humans. To remedy this problem, we propose to explicitly train a network to refine these results predicted by an existing segmentation method. The network, which we call the P2Net, learns the consistency constraints between coincident points from consecutive frames after registration. We evaluate the proposed post-processing method both qualitatively and quantitatively on the SemanticKITTI dataset that consists of real outdoor scenes. The effectiveness of the proposed method is validated by comparing the results predicted by two representative networks with and without the refinement by the post-processing network. Specifically, qualitative visualization validates the key idea that labels of the points that are difficult to predict can be corrected with P2Net. Quantitatively, overall mIoU is improved from 10.5% to 11.7% for PointNet [1] and from 10.8% to 15.9% for PointNet++ [2].
Surgical Skill Assessment via Video Semantic Aggregation
Aug 04, 2022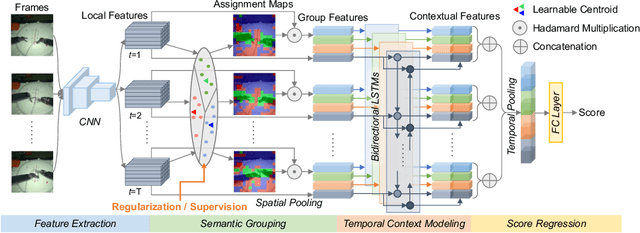
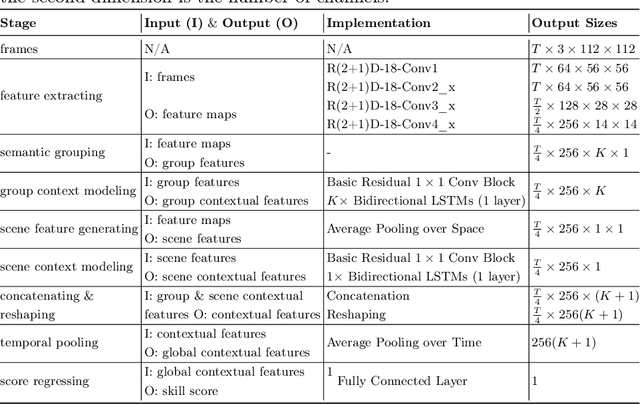
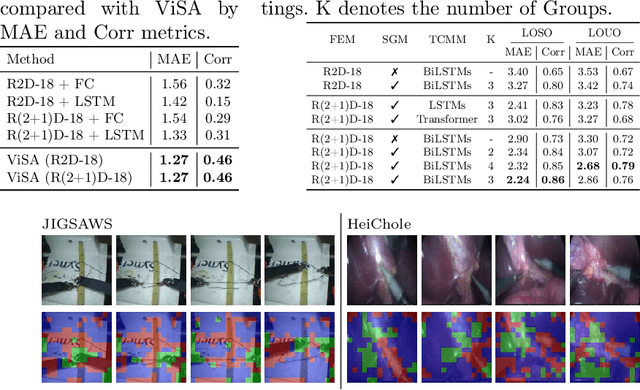
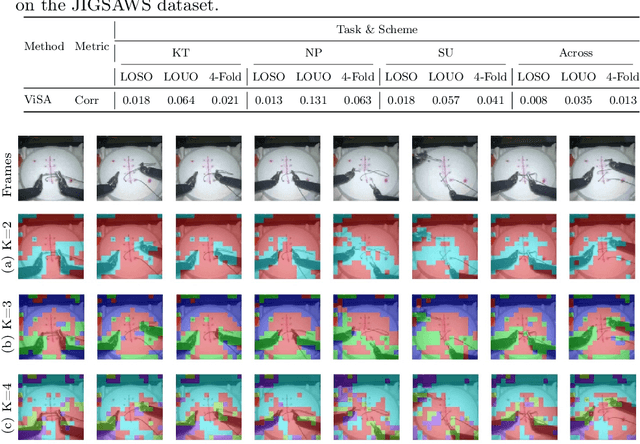
Automated video-based assessment of surgical skills is a promising task in assisting young surgical trainees, especially in poor-resource areas. Existing works often resort to a CNN-LSTM joint framework that models long-term relationships by LSTMs on spatially pooled short-term CNN features. However, this practice would inevitably neglect the difference among semantic concepts such as tools, tissues, and background in the spatial dimension, impeding the subsequent temporal relationship modeling. In this paper, we propose a novel skill assessment framework, Video Semantic Aggregation (ViSA), which discovers different semantic parts and aggregates them across spatiotemporal dimensions. The explicit discovery of semantic parts provides an explanatory visualization that helps understand the neural network's decisions. It also enables us to further incorporate auxiliary information such as the kinematic data to improve representation learning and performance. The experiments on two datasets show the competitiveness of ViSA compared to state-of-the-art methods. Source code is available at: bit.ly/MICCAI2022ViSA.
RGB-D SLAM Using Attention Guided Frame Association
Jan 28, 2022



Deep learning models as an emerging topic have shown great progress in various fields. Especially, visualization tools such as class activation mapping methods provided visual explanation on the reasoning of convolutional neural networks (CNNs). By using the gradients of the network layers, it is possible to demonstrate where the networks pay attention during a specific image recognition task. Moreover, these gradients can be integrated with CNN features for localizing more generalized task dependent attentive (salient) objects in scenes. Despite this progress, there is not much explicit usage of this gradient (network attention) information to integrate with CNN representations for object semantics. This can be very useful for visual tasks such as simultaneous localization and mapping (SLAM) where CNN representations of spatially attentive object locations may lead to improved performance. Therefore, in this work, we propose the use of task specific network attention for RGB-D indoor SLAM. To do so, we integrate layer-wise object attention information (layer gradients) with CNN layer representations to improve frame association performance in a state-of-the-art RGB-D indoor SLAM method. Experiments show promising initial results with improved performance.
SalFBNet: Learning Pseudo-Saliency Distribution via Feedback Convolutional Networks
Jan 11, 2022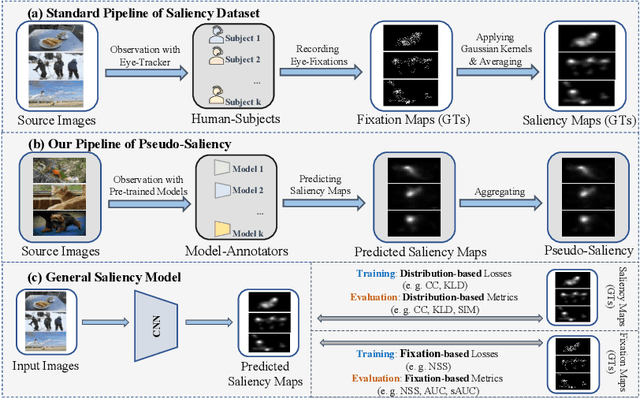
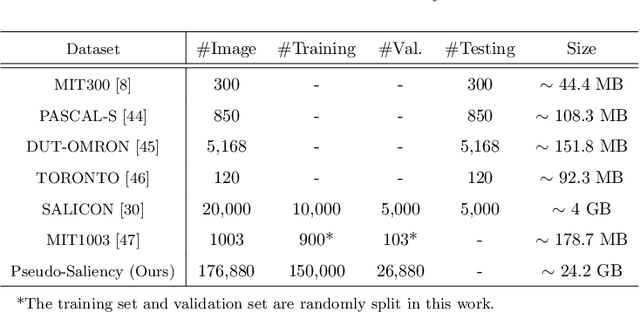
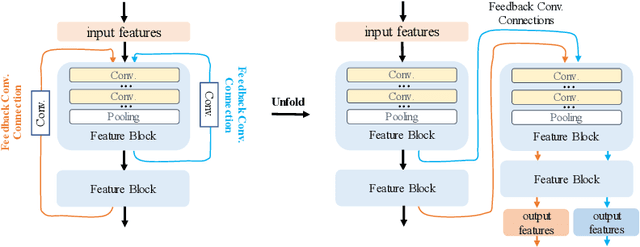
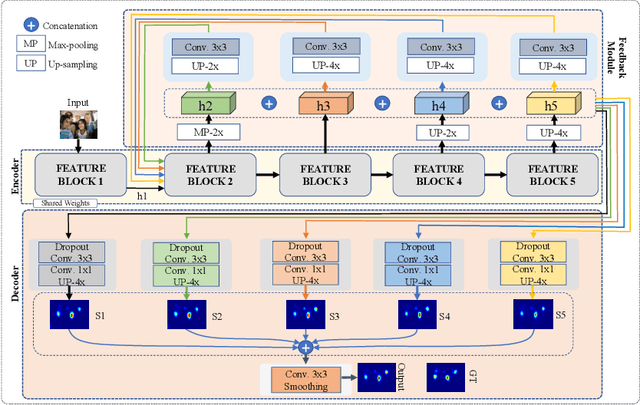
Feed-forward only convolutional neural networks (CNNs) may ignore intrinsic relationships and potential benefits of feedback connections in vision tasks such as saliency detection, despite their significant representation capabilities. In this work, we propose a feedback-recursive convolutional framework (SalFBNet) for saliency detection. The proposed feedback model can learn abundant contextual representations by bridging a recursive pathway from higher-level feature blocks to low-level layer. Moreover, we create a large-scale Pseudo-Saliency dataset to alleviate the problem of data deficiency in saliency detection. We first use the proposed feedback model to learn saliency distribution from pseudo-ground-truth. Afterwards, we fine-tune the feedback model on existing eye-fixation datasets. Furthermore, we present a novel Selective Fixation and Non-Fixation Error (sFNE) loss to make proposed feedback model better learn distinguishable eye-fixation-based features. Extensive experimental results show that our SalFBNet with fewer parameters achieves competitive results on the public saliency detection benchmarks, which demonstrate the effectiveness of proposed feedback model and Pseudo-Saliency data. Source codes and Pseudo-Saliency dataset can be found at https://github.com/gqding/SalFBNet
When CNNs Meet Random RNNs: Towards Multi-Level Analysis for RGB-D Object and Scene Recognition
Apr 26, 2020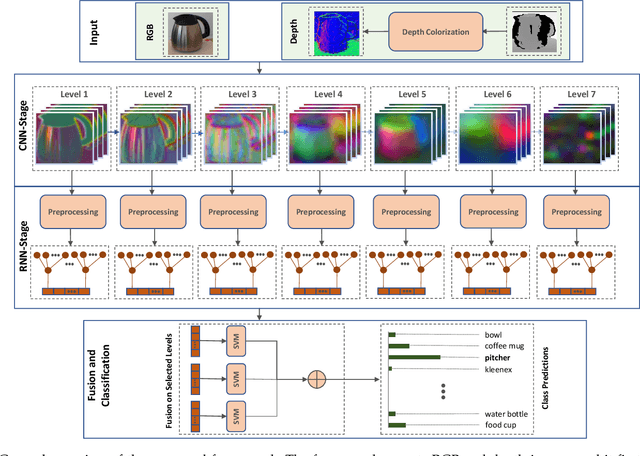

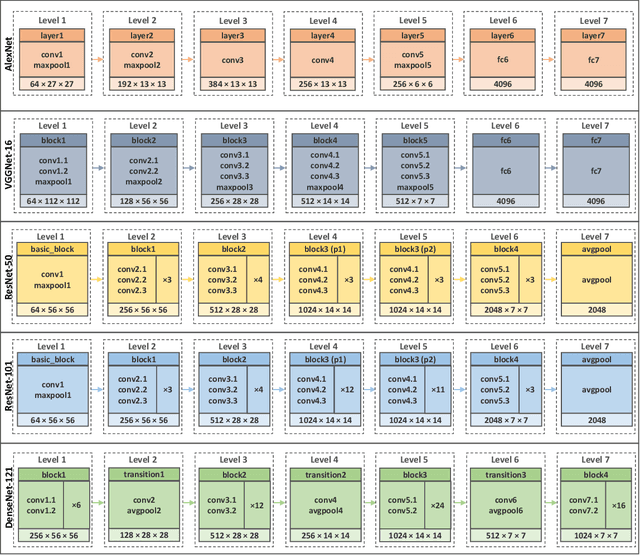
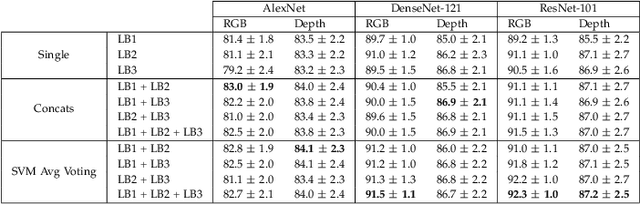
Recognizing objects and scenes are two challenging but essential tasks in image understanding. In particular, the use of RGB-D sensors in handling these tasks has emerged as an important area of focus for better visual understanding. Meanwhile, deep neural networks, specifically convolutional neural networks (CNNs), have become widespread and have been applied to many visual tasks by replacing hand-crafted features with effective deep features. However, it is an open problem how to exploit deep features from a multi-layer CNN model effectively. In this paper, we propose a novel two-stage framework that extracts discriminative feature representations from multi-modal RGB-D images for object and scene recognition tasks. In the first stage, a pretrained CNN model has been employed as a backbone to extract visual features at multiple levels. The second stage maps these features into high level representations with a fully randomized structure of recursive neural networks (RNNs) efficiently. In order to cope with the high dimensionality of CNN activations, a random weighted pooling scheme has been proposed by extending the idea of randomness in RNNs. Multi-modal fusion has been performed through a soft voting approach by computing weights based on individual recognition confidences (i.e. SVM scores) of RGB and depth streams separately. This produces consistent class label estimation in final RGB-D classification performance. Extensive experiments verify that fully randomized structure in RNN stage encodes CNN activations to discriminative solid features successfully. Comparative experimental results on the popular Washington RGB-D Object and SUN RGB-D Scene datasets show that the proposed approach significantly outperforms state-of-the-art methods both in object and scene recognition tasks.
SOIC: Semantic Online Initialization and Calibration for LiDAR and Camera
Mar 09, 2020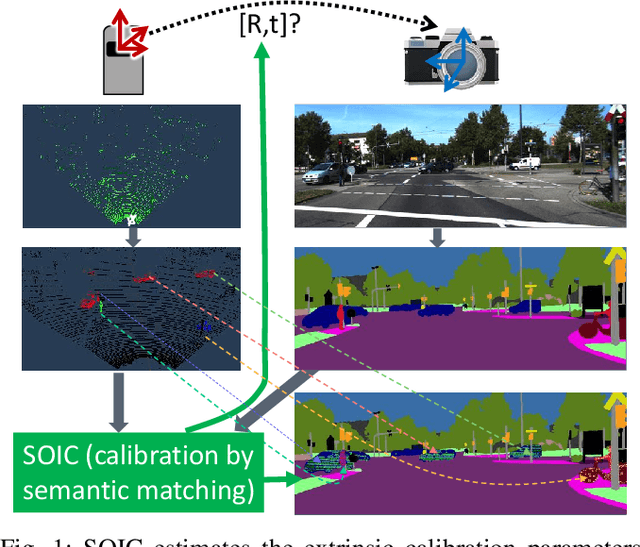
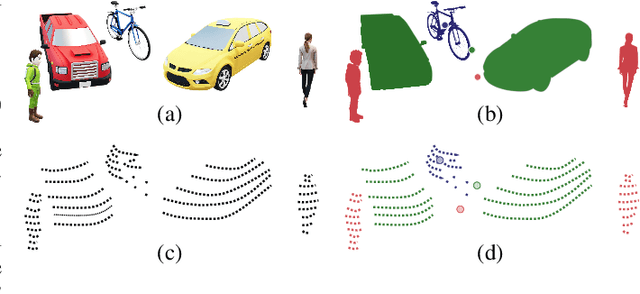
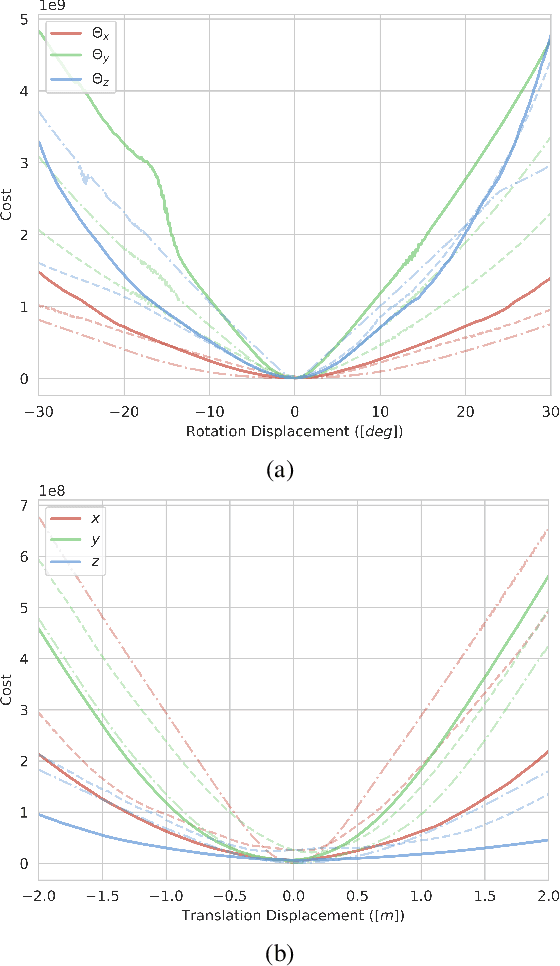
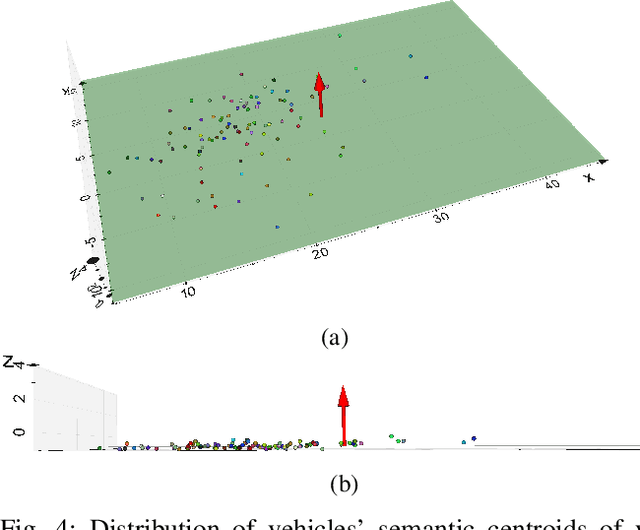
This paper presents a novel semantic-based online extrinsic calibration approach, SOIC (so, I see), for Light Detection and Ranging (LiDAR) and camera sensors. Previous online calibration methods usually need prior knowledge of rough initial values for optimization. The proposed approach removes this limitation by converting the initialization problem to a Perspective-n-Point (PnP) problem with the introduction of semantic centroids (SCs). The closed-form solution of this PnP problem has been well researched and can be found with existing PnP methods. Since the semantic centroid of the point cloud usually does not accurately match with that of the corresponding image, the accuracy of parameters are not improved even after a nonlinear refinement process. Thus, a cost function based on the constraint of the correspondence between semantic elements from both point cloud and image data is formulated. Subsequently, optimal extrinsic parameters are estimated by minimizing the cost function. We evaluate the proposed method either with GT or predicted semantics on KITTI dataset. Experimental results and comparisons with the baseline method verify the feasibility of the initialization strategy and the accuracy of the calibration approach. In addition, we release the source code at https://github.com/--/SOIC.
Salient object detection on hyperspectral images using features learned from unsupervised segmentation task
Feb 28, 2019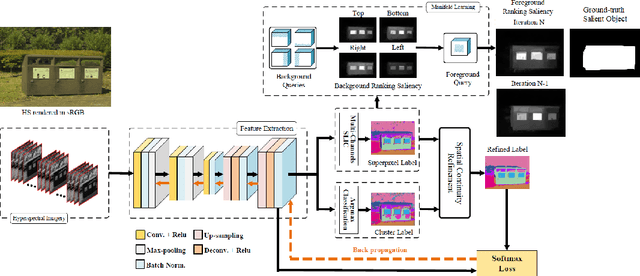
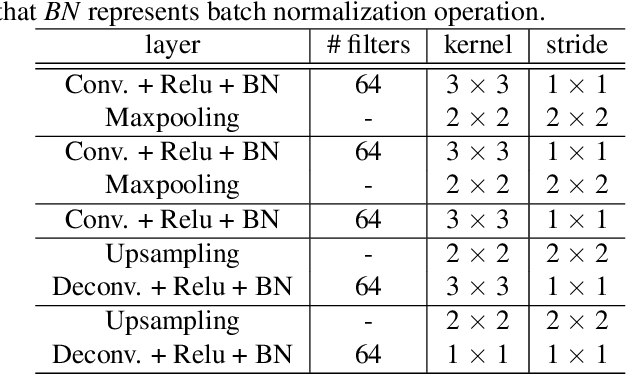
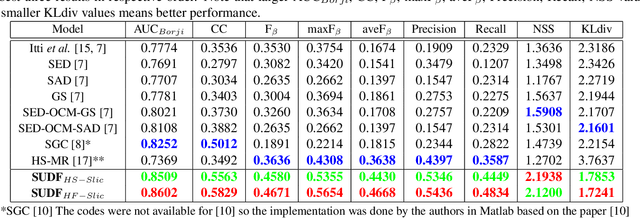

Various saliency detection algorithms from color images have been proposed to mimic eye fixation or attentive object detection response of human observers for the same scenes. However, developments on hyperspectral imaging systems enable us to obtain redundant spectral information of the observed scenes from the reflected light source from objects. A few studies using low-level features on hyperspectral images demonstrated that salient object detection can be achieved. In this work, we proposed a salient object detection model on hyperspectral images by applying manifold ranking (MR) on self-supervised Convolutional Neural Network (CNN) features (high-level features) from unsupervised image segmentation task. Self-supervision of CNN continues until clustering loss or saliency maps converges to a defined error between each iteration. Finally, saliency estimations is done as the saliency map at last iteration when the self-supervision procedure terminates with convergence. Experimental evaluations demonstrated that proposed saliency detection algorithm on hyperspectral images is outperforming state-of-the-arts hyperspectral saliency models including the original MR based saliency model.
Rare Event Detection using Disentangled Representation Learning
Dec 04, 2018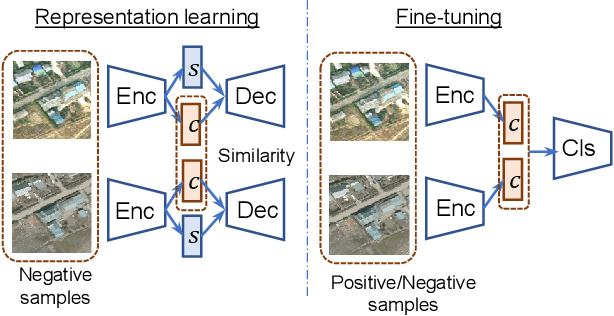
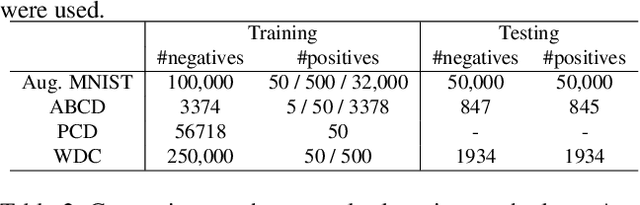
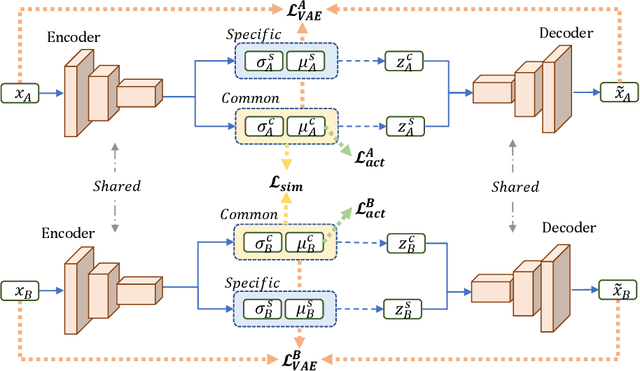
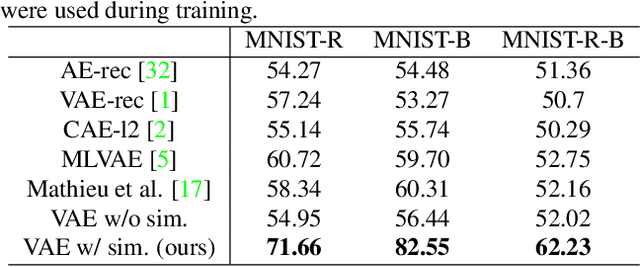
This paper presents a novel method for rare event detection from an image pair with class-imbalanced datasets. A straightforward approach for event detection tasks is to train a detection network from a large-scale dataset in an end-to-end manner. However, in many applications such as building change detection on satellite images, few positive samples are available for the training. Moreover, scene image pairs contain many trivial events, such as in illumination changes or background motions. These many trivial events and the class imbalance problem lead to false alarms for rare event detection. In order to overcome these difficulties, we propose a novel method to learn disentangled representations from only low-cost negative samples. The proposed method disentangles different aspects in a pair of observations: variant and invariant factors that represent trivial events and image contents, respectively. The effectiveness of the proposed approach is verified by the quantitative evaluations on four change detection datasets, and the qualitative analysis shows that the proposed method can acquire the representations that disentangle rare events from trivial ones.