 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRAID-Database: human Responses to Affine Image Distortions
Dec 13, 2024



Image quality databases are used to train models for predicting subjective human perception. However, most existing databases focus on distortions commonly found in digital media and not in natural conditions. Affine transformations are particularly relevant to study, as they are among the most commonly encountered by human observers in everyday life. This Data Descriptor presents a set of human responses to suprathreshold affine image transforms (rotation, translation, scaling) and Gaussian noise as convenient reference to compare with previously existing image quality databases. The responses were measured using well established psychophysics: the Maximum Likelihood Difference Scaling method. The set contains responses to 864 distorted images. The experiments involved 105 observers and more than 20000 comparisons of quadruples of images. The quality of the dataset is ensured because (a) it reproduces the classical Pi\'eron's law, (b) it reproduces classical absolute detection thresholds, and (c) it is consistent with conventional image quality databases but improves them according to Group-MAD experiments.
Parametric Enhancement of PerceptNet: A Human-Inspired Approach for Image Quality Assessment
Dec 04, 2024



While deep learning models can learn human-like features at earlier levels, which suggests their utility in modeling human vision, few attempts exist to incorporate these features by design. Current approaches mostly optimize all parameters blindly, only constraining minor architectural aspects. This paper demonstrates how parametrizing neural network layers enables more biologically-plausible operations while reducing trainable parameters and improving interpretability. We constrain operations to functional forms present in human vision, optimizing only these functions' parameters rather than all convolutional tensor elements independently. We present two parametric model versions: one with hand-chosen biologically plausible parameters, and another fitted to human perception experimental data. We compare these with a non-parametric version. All models achieve comparable state-of-the-art results, with parametric versions showing orders of magnitude parameter reduction for minimal performance loss. The parametric models demonstrate improved interpretability and training behavior. Notably, the model fitted to human perception, despite biological initialization, converges to biologically incorrect results. This raises scientific questions and highlights the need for diverse evaluation methods to measure models' humanness, rather than assuming task performance correlates with human-like behavior.
Invariance of deep image quality metrics to affine transformations
Jul 29, 2024



Deep architectures are the current state-of-the-art in predicting subjective image quality. Usually, these models are evaluated according to their ability to correlate with human opinion in databases with a range of distortions that may appear in digital media. However, these oversee affine transformations which may represent better the changes in the images actually happening in natural conditions. Humans can be particularly invariant to these natural transformations, as opposed to the digital ones. In this work, we evaluate state-of-the-art deep image quality metrics by assessing their invariance to affine transformations, specifically: rotation, translation, scaling, and changes in spectral illumination. Here invariance of a metric refers to the fact that certain distances should be neglected (considered to be zero) if their values are below a threshold. This is what we call invisibility threshold of a metric. We propose a methodology to assign such invisibility thresholds for any perceptual metric. This methodology involves transformations to a distance space common to any metric, and psychophysical measurements of thresholds in this common space. By doing so, we allow the analyzed metrics to be directly comparable with actual human thresholds. We find that none of the state-of-the-art metrics shows human-like results under this strong test based on invisibility thresholds. This means that tuning the models exclusively to predict the visibility of generic distortions may disregard other properties of human vision as for instance invariances or invisibility thresholds.
Image Segmentation via Divisive Normalization: dealing with environmental diversity
Jul 25, 2024



Autonomous driving is a challenging scenario for image segmentation due to the presence of uncontrolled environmental conditions and the eventually catastrophic consequences of failures. Previous work suggested that a biologically motivated computation, the so-called Divisive Normalization, could be useful to deal with image variability, but its effects have not been systematically studied over different data sources and environmental factors. Here we put segmentation U-nets augmented with Divisive Normalization to work far from training conditions to find where this adaptation is more critical. We categorize the scenes according to their radiance level and dynamic range (day/night), and according to their achromatic/chromatic contrasts. We also consider video game (synthetic) images to broaden the range of environments. We check the performance in the extreme percentiles of such categorization. Then, we push the limits further by artificially modifying the images in perceptually/environmentally relevant dimensions: luminance, contrasts and spectral radiance. Results show that neural networks with Divisive Normalization get better results in all the scenarios and their performance remains more stable with regard to the considered environmental factors and nature of the source. Finally, we explain the improvements in segmentation performance in two ways: (1) by quantifying the invariance of the responses that incorporate Divisive Normalization, and (2) by illustrating the adaptive nonlinearity of the different layers that depends on the local activity.
Disentangling the Link Between Image Statistics and Human Perception
Mar 17, 2023



In the 1950s Horace Barlow and Fred Attneave suggested a connection between sensory systems and how they are adapted to the environment: early vision evolved to maximise the information it conveys about incoming signals. Following Shannon's definition, this information was described using the probability of the images taken from natural scenes. Previously, direct accurate predictions of image probabilities were not possible due to computational limitations. Despite the exploration of this idea being indirect, mainly based on oversimplified models of the image density or on system design methods, these methods had success in reproducing a wide range of physiological and psychophysical phenomena. In this paper, we directly evaluate the probability of natural images and analyse how it may determine perceptual sensitivity. We employ image quality metrics that correlate well with human opinion as a surrogate of human vision, and an advanced generative model to directly estimate the probability. Specifically, we analyse how the sensitivity of full-reference image quality metrics can be predicted from quantities derived directly from the probability distribution of natural images. First, we compute the mutual information between a wide range of probability surrogates and the sensitivity of the metrics and find that the most influential factor is the probability of the noisy image. Then we explore how these probability surrogates can be combined using a simple model to predict the metric sensitivity, giving an upper bound for the correlation of 0.85 between the model predictions and the actual perceptual sensitivity. Finally, we explore how to combine the probability surrogates using simple expressions, and obtain two functional forms (using one or two surrogates) that can be used to predict the sensitivity of the human visual system given a particular pair of images.
Analysis of Deep Image Quality Models
Feb 26, 2023



Subjective image quality measures based on deep neural networks are very related to models of visual neuroscience. This connection benefits engineering but, more interestingly, the freedom to optimize deep networks in different ways, make them an excellent tool to explore the principles behind visual perception (both human and artificial). Recently, a myriad of networks have been successfully optimized for many interesting visual tasks. Although these nets were not specifically designed to predict image quality or other psychophysics, they have shown surprising human-like behavior. The reasons for this remain unclear. In this work, we perform a thorough analysis of the perceptual properties of pre-trained nets (particularly their ability to predict image quality) by isolating different factors: the goal (the function), the data (learning environment), the architecture, and the readout: selected layer(s), fine-tuning of channel relevance, and use of statistical descriptors as opposed to plain readout of responses. Several conclusions can be drawn. All the models correlate better with human opinion than SSIM. More importantly, some of the nets are in pair of state-of-the-art with no extra refinement or perceptual information. Nets trained for supervised tasks such as classification correlate substantially better with humans than LPIPS (a net specifically tuned for image quality). Interestingly, self-supervised tasks such as jigsaw also perform better than LPIPS. Simpler architectures are better than very deep nets. In simpler nets, correlation with humans increases with depth as if deeper layers were closer to human judgement. This is not true in very deep nets. Consistently with reports on illusions and contrast sensitivity, small changes in the image environment does not make a big difference. Finally, the explored statistical descriptors and concatenations had no major impact.
Orthonormal Convolutions for the Rotation Based Iterative Gaussianization
Jun 08, 2022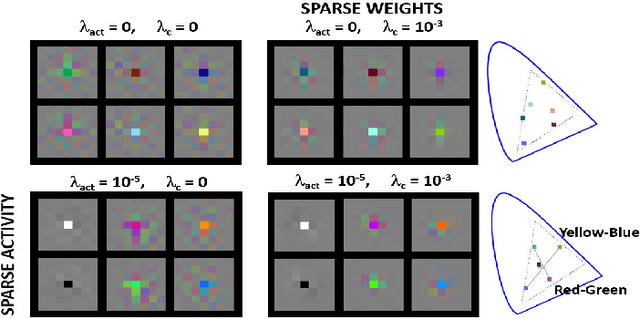
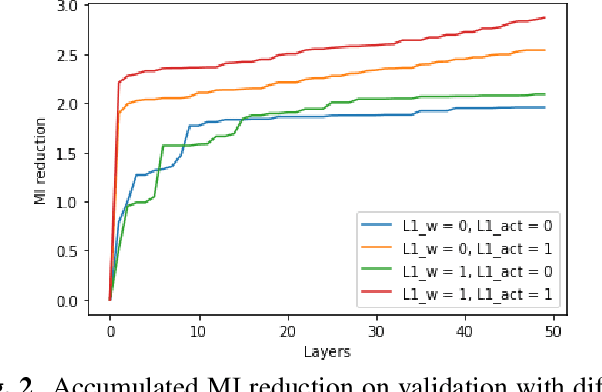
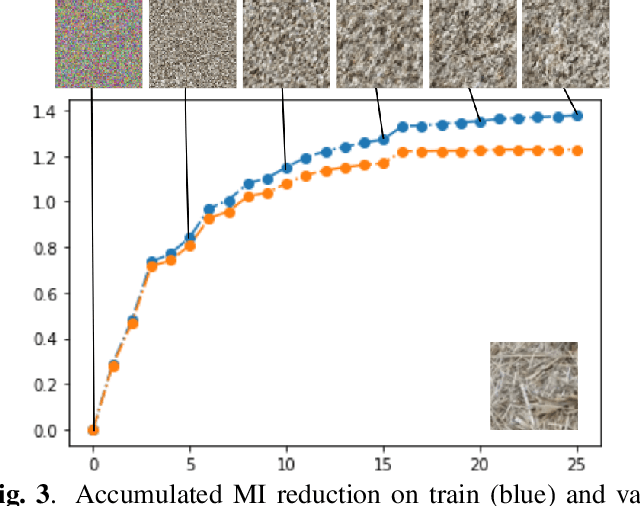

In this paper we elaborate an extension of rotation-based iterative Gaussianization, RBIG, which makes image Gaussianization possible. Although RBIG has been successfully applied to many tasks, it is limited to medium dimensionality data (on the order of a thousand dimensions). In images its application has been restricted to small image patches or isolated pixels, because rotation in RBIG is based on principal or independent component analysis and these transformations are difficult to learn and scale. Here we present the \emph{Convolutional RBIG}: an extension that alleviates this issue by imposing that the rotation in RBIG is a convolution. We propose to learn convolutional rotations (i.e. orthonormal convolutions) by optimising for the reconstruction loss between the input and an approximate inverse of the transformation using the transposed convolution operation. Additionally, we suggest different regularizers in learning these orthonormal convolutions. For example, imposing sparsity in the activations leads to a transformation that extends convolutional independent component analysis to multilayer architectures. We also highlight how statistical properties of the data, such as multivariate mutual information, can be obtained from \emph{Convolutional RBIG}. We illustrate the behavior of the transform with a simple example of texture synthesis, and analyze its properties by visualizing the stimuli that maximize the response in certain feature and layer.
Neural Networks with Divisive normalization for image segmentation with application in cityscapes dataset
Mar 25, 2022
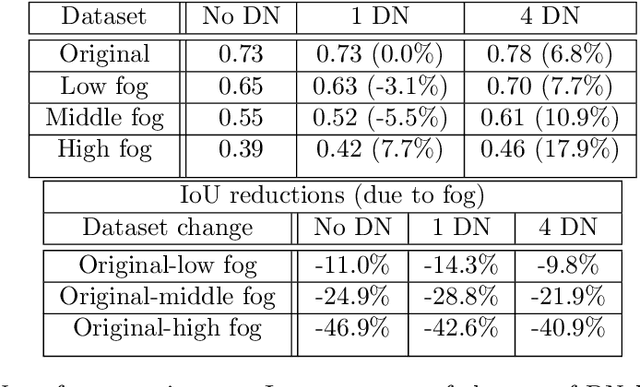

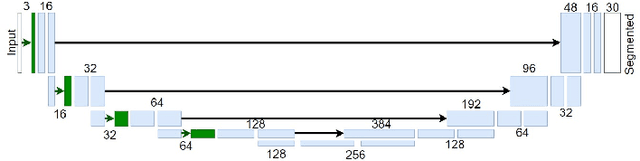
One of the key problems in computer vision is adaptation: models are too rigid to follow the variability of the inputs. The canonical computation that explains adaptation in sensory neuroscience is divisive normalization, and it has appealing effects on image manifolds. In this work we show that including divisive normalization in current deep networks makes them more invariant to non-informative changes in the images. In particular, we focus on U-Net architectures for image segmentation. Experiments show that the inclusion of divisive normalization in the U-Net architecture leads to better segmentation results with respect to conventional U-Net. The gain increases steadily when dealing with images acquired in bad weather conditions. In addition to the results on the Cityscapes and Foggy Cityscapes datasets, we explain these advantages through visualization of the responses: the equalization induced by the divisive normalization leads to more invariant features to local changes in contrast and illumination.
On the relation between statistical learning and perceptual distances
Jun 08, 2021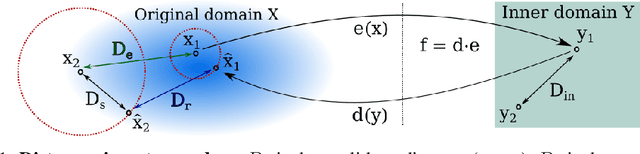
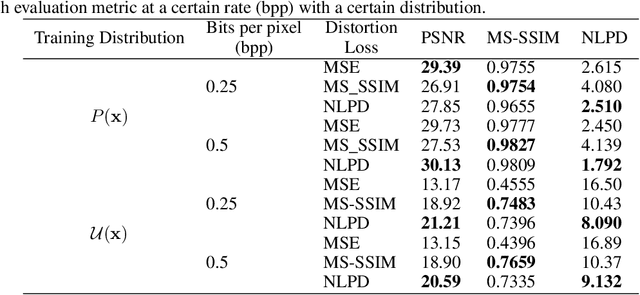
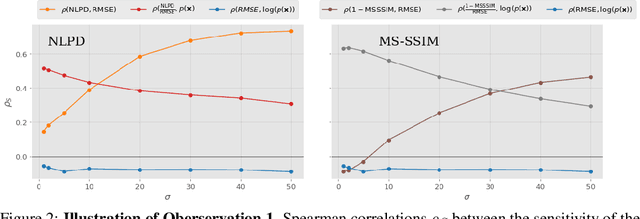
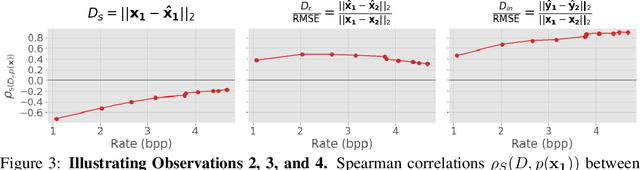
It has been demonstrated many times that the behavior of the human visual system is connected to the statistics of natural images. Since machine learning relies on the statistics of training data as well, the above connection has interesting implications when using perceptual distances (which mimic the behavior of the human visual system) as a loss function. In this paper, we aim to unravel the non-trivial relationship between the probability distribution of the data, perceptual distances, and unsupervised machine learning. To this end, we show that perceptual sensitivity is correlated with the probability of an image in its close neighborhood. We also explore the relation between distances induced by autoencoders and the probability distribution of the data used for training them, as well as how these induced distances are correlated with human perception. Finally, we discuss why perceptual distances might not lead to noticeable gains in performance over standard Euclidean distances in common image processing tasks except when data is scarce and the perceptual distance provides regularization.
Information Theory in Density Destructors
Dec 02, 2020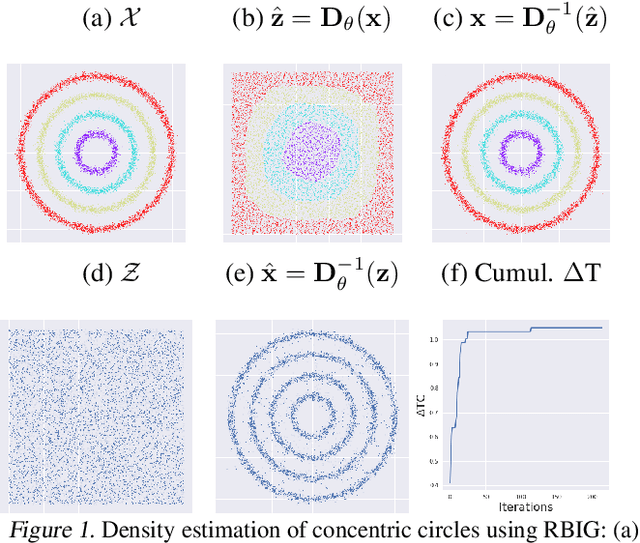
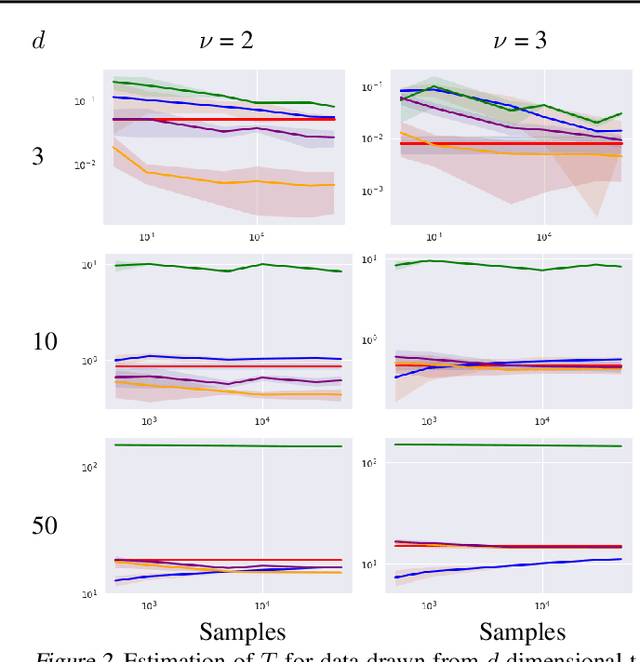
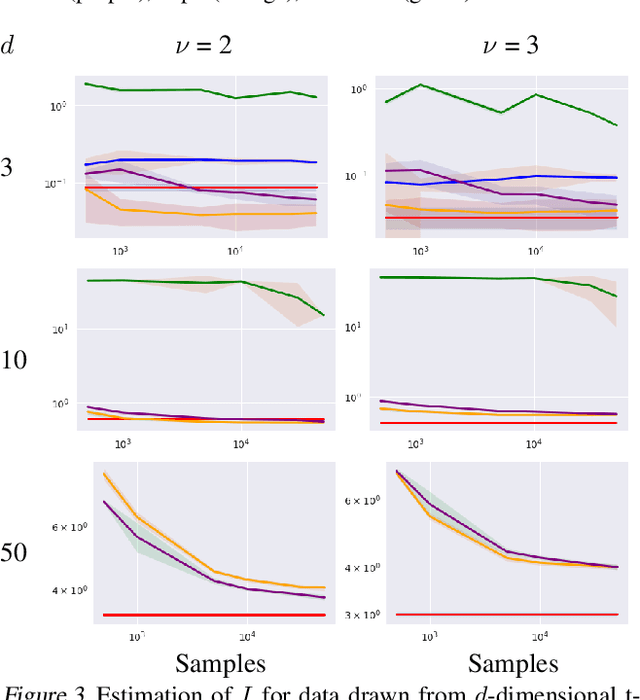
Density destructors are differentiable and invertible transforms that map multivariate PDFs of arbitrary structure (low entropy) into non-structured PDFs (maximum entropy). Multivariate Gaussianization and multivariate equalization are specific examples of this family, which break down the complexity of the original PDF through a set of elementary transforms that progressively remove the structure of the data. We demonstrate how this property of density destructive flows is connected to classical information theory, and how density destructors can be used to get more accurate estimates of information theoretic quantities. Experiments with total correlation and mutual information inmultivariate sets illustrate the ability of density destructors compared to competing methods. These results suggest that information theoretic measures may be an alternative optimization criteria when learning density destructive flows.