 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Exploring Interactions and Regulations in Collaborative Learning: An Interdisciplinary Multimodal Dataset
Oct 11, 2022
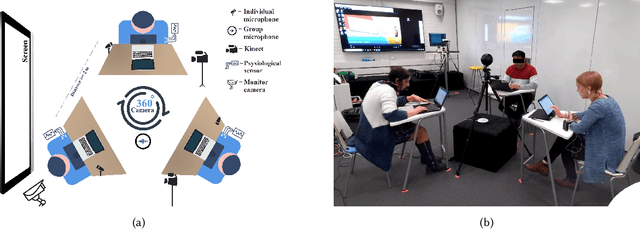
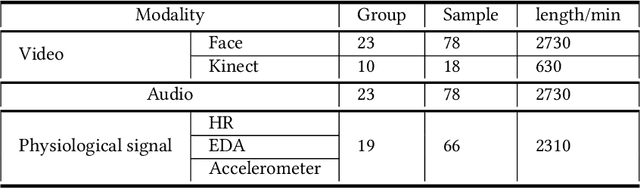

Collaborative learning is an educational approach that enhances learning through shared goals and working together. Interaction and regulation are two essential factors related to the success of collaborative learning. Since the information from various modalities can reflect the quality of collaboration, a new multimodal dataset with cognitive and emotional triggers is introduced in this paper to explore how regulations affect interactions during the collaborative process. Specifically, a learning task with intentional interventions is designed and assigned to high school students aged 15 years old (N=81) in average. Multimodal signals, including video, Kinect, audio, and physiological data, are collected and exploited to study regulations in collaborative learning in terms of individual-participant-single-modality, individual-participant-multiple-modality, and multiple-participant-multiple-modality. Analysis of annotated emotions, body gestures, and their interactions indicates that our multimodal dataset with designed treatments could effectively examine moments of regulation in collaborative learning. In addition, preliminary experiments based on baseline models suggest that the dataset provides a challenging in-the-wild scenario, which could further contribute to the fields of education and affective computing.
Fine-Grained Image Style Transfer with Visual Transformers
Oct 11, 2022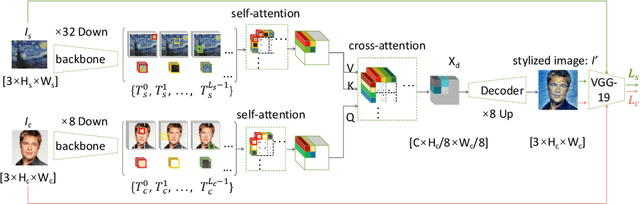
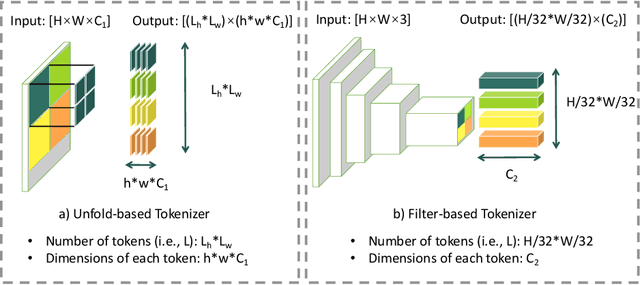

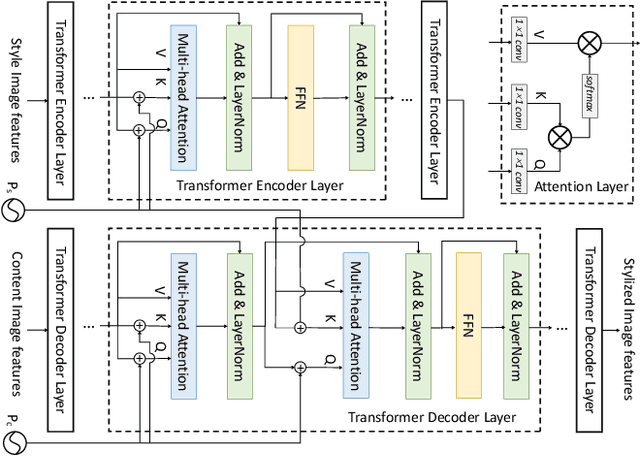
With the development of the convolutional neural network, image style transfer has drawn increasing attention. However, most existing approaches adopt a global feature transformation to transfer style patterns into content images (e.g., AdaIN and WCT). Such a design usually destroys the spatial information of the input images and fails to transfer fine-grained style patterns into style transfer results. To solve this problem, we propose a novel STyle TRansformer (STTR) network which breaks both content and style images into visual tokens to achieve a fine-grained style transformation. Specifically, two attention mechanisms are adopted in our STTR. We first propose to use self-attention to encode content and style tokens such that similar tokens can be grouped and learned together. We then adopt cross-attention between content and style tokens that encourages fine-grained style transformations. To compare STTR with existing approaches, we conduct user studies on Amazon Mechanical Turk (AMT), which are carried out with 50 human subjects with 1,000 votes in total. Extensive evaluations demonstrate the effectiveness and efficiency of the proposed STTR in generating visually pleasing style transfer results.
An Experimental Study on Private Aggregation of Teacher Ensemble Learning for End-to-End Speech Recognition
Oct 11, 2022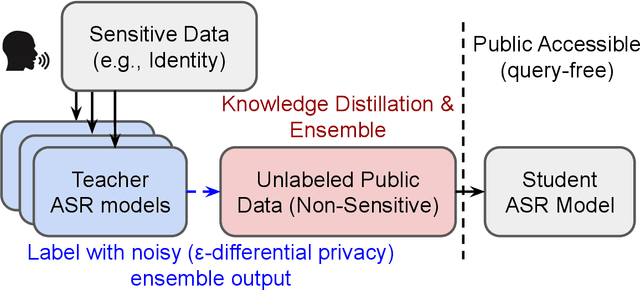
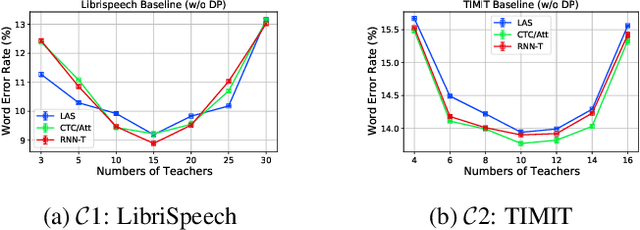
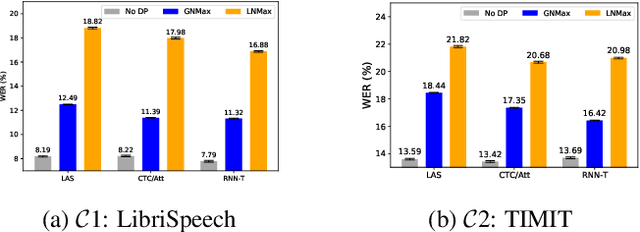
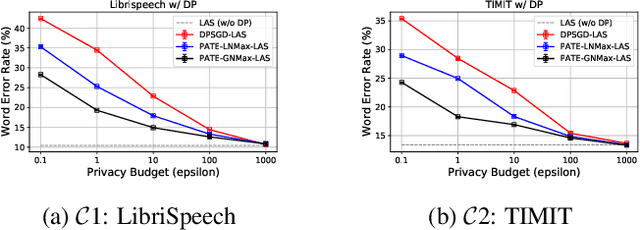
Differential privacy (DP) is one data protection avenue to safeguard user information used for training deep models by imposing noisy distortion on privacy data. Such a noise perturbation often results in a severe performance degradation in automatic speech recognition (ASR) in order to meet a privacy budget $\varepsilon$. Private aggregation of teacher ensemble (PATE) utilizes ensemble probabilities to improve ASR accuracy when dealing with the noise effects controlled by small values of $\varepsilon$. In this work, we extend PATE learning to work with dynamic patterns, namely speech, and perform one very first experimental study on ASR to avoid acoustic data leakage. We evaluate three end-to-end deep models, including LAS, hybrid attention/CTC, and RNN transducer, on the open-source LibriSpeech and TIMIT corpora. PATE learning-enhanced ASR models outperform the benchmark DP-SGD mechanisms, especially under strict DP budgets, giving relative word error rate reductions between 26.2% and 27.5% for RNN transducer model evaluated with LibriSpeech. We also introduce another DP-preserving ASR solution with public speech corpus pre-training.
Instance As Identity: A Generic Online Paradigm for Video Instance Segmentation
Aug 16, 2022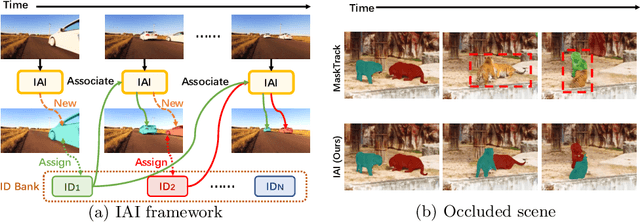
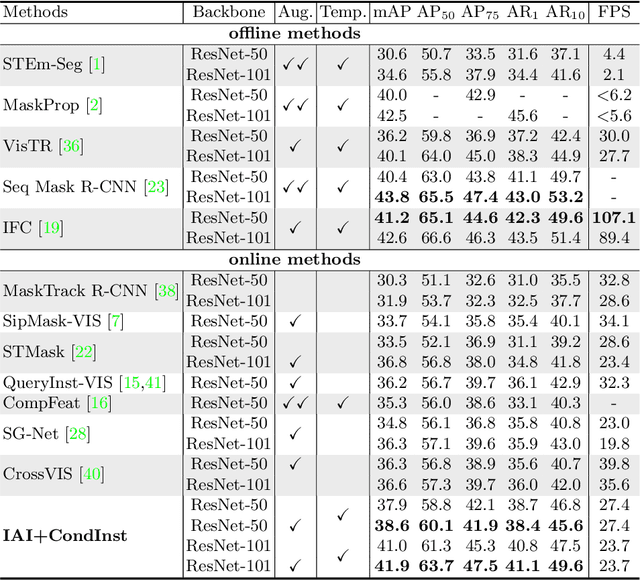
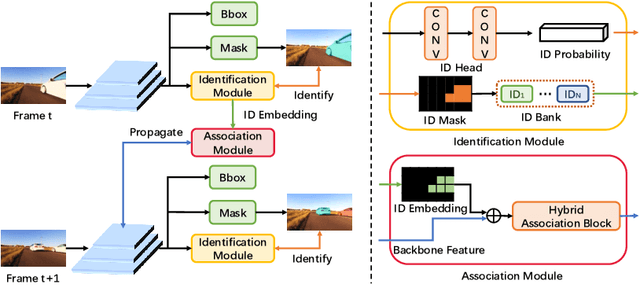
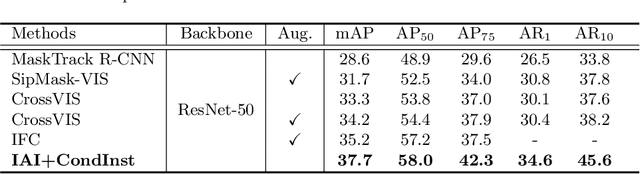
Modeling temporal information for both detection and tracking in a unified framework has been proved a promising solution to video instance segmentation (VIS). However, how to effectively incorporate the temporal information into an online model remains an open problem. In this work, we propose a new online VIS paradigm named Instance As Identity (IAI), which models temporal information for both detection and tracking in an efficient way. In detail, IAI employs a novel identification module to predict identification number for tracking instances explicitly. For passing temporal information cross frame, IAI utilizes an association module which combines current features and past embeddings. Notably, IAI can be integrated with different image models. We conduct extensive experiments on three VIS benchmarks. IAI outperforms all the online competitors on YouTube-VIS-2019 (ResNet-101 43.7 mAP) and YouTube-VIS-2021 (ResNet-50 38.0 mAP). Surprisingly, on the more challenging OVIS, IAI achieves SOTA performance (20.6 mAP). Code is available at https://github.com/zfonemore/IAI
Multi-Scale Wavelet Transformer for Face Forgery Detection
Oct 08, 2022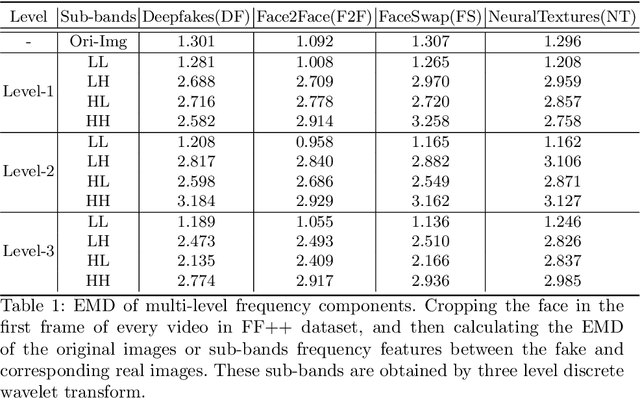


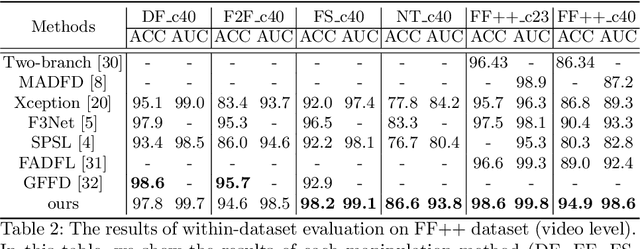
Currently, many face forgery detection methods aggregate spatial and frequency features to enhance the generalization ability and gain promising performance under the cross-dataset scenario. However, these methods only leverage one level frequency information which limits their expressive ability. To overcome these limitations, we propose a multi-scale wavelet transformer framework for face forgery detection. Specifically, to take full advantage of the multi-scale and multi-frequency wavelet representation, we gradually aggregate the multi-scale wavelet representation at different stages of the backbone network. To better fuse the frequency feature with the spatial features, frequency-based spatial attention is designed to guide the spatial feature extractor to concentrate more on forgery traces. Meanwhile, cross-modality attention is proposed to fuse the frequency features with the spatial features. These two attention modules are calculated through a unified transformer block for efficiency. A wide variety of experiments demonstrate that the proposed method is efficient and effective for both within and cross datasets.
Dynamically meeting performance objectives for multiple services on a service mesh
Oct 08, 2022
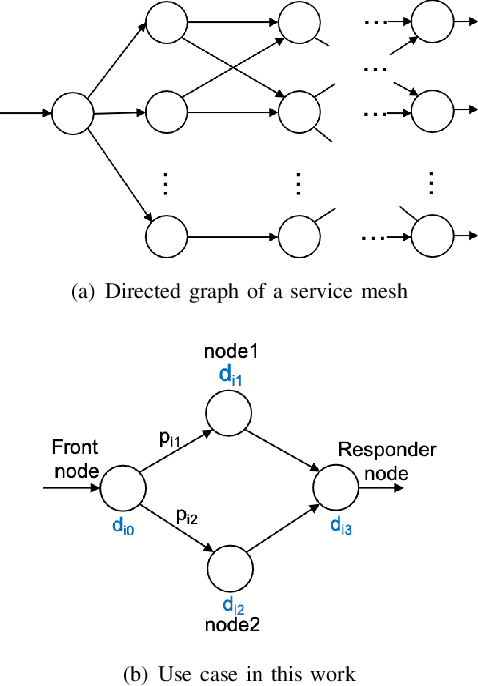
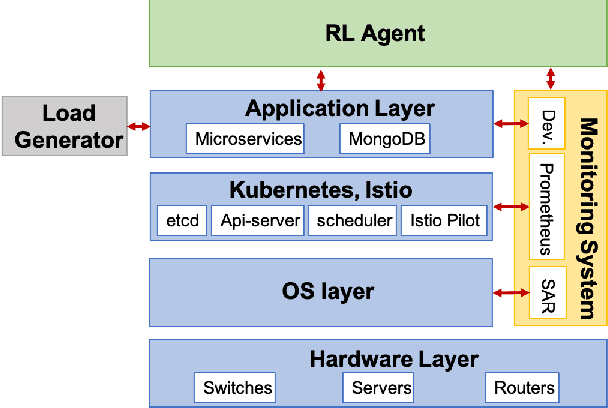
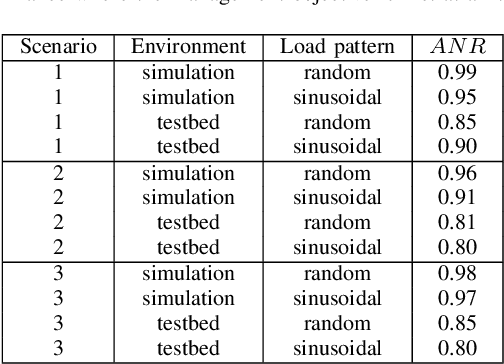
We present a framework that lets a service provider achieve end-to-end management objectives under varying load. Dynamic control actions are performed by a reinforcement learning (RL) agent. Our work includes experimentation and evaluation on a laboratory testbed where we have implemented basic information services on a service mesh supported by the Istio and Kubernetes platforms. We investigate different management objectives that include end-to-end delay bounds on service requests, throughput objectives, and service differentiation. These objectives are mapped onto reward functions that an RL agent learns to optimize, by executing control actions, namely, request routing and request blocking. We compute the control policies not on the testbed, but in a simulator, which speeds up the learning process by orders of magnitude. In our approach, the system model is learned on the testbed; it is then used to instantiate the simulator, which produces near-optimal control policies for various management objectives. The learned policies are then evaluated on the testbed using unseen load patterns.
Towards Homogeneous Modality Learning and Multi-Granularity Information Exploration for Visible-Infrared Person Re-Identification
Apr 11, 2022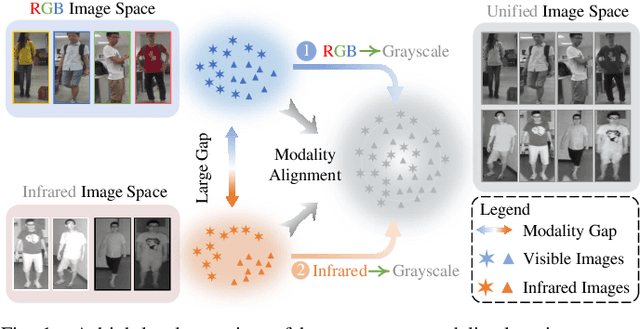

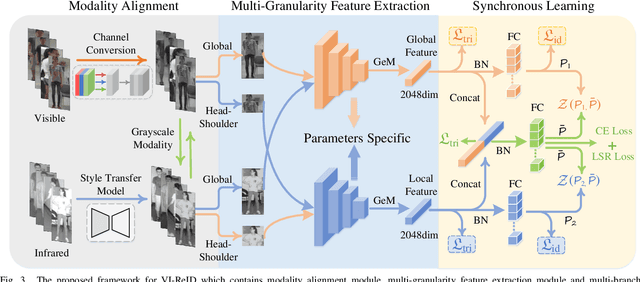

Visible-infrared person re-identification (VI-ReID) is a challenging and essential task, which aims to retrieve a set of person images over visible and infrared camera views. In order to mitigate the impact of large modality discrepancy existing in heterogeneous images, previous methods attempt to apply generative adversarial network (GAN) to generate the modality-consisitent data. However, due to severe color variations between the visible domain and infrared domain, the generated fake cross-modality samples often fail to possess good qualities to fill the modality gap between synthesized scenarios and target real ones, which leads to sub-optimal feature representations. In this work, we address cross-modality matching problem with Aligned Grayscale Modality (AGM), an unified dark-line spectrum that reformulates visible-infrared dual-mode learning as a gray-gray single-mode learning problem. Specifically, we generate the grasycale modality from the homogeneous visible images. Then, we train a style tranfer model to transfer infrared images into homogeneous grayscale images. In this way, the modality discrepancy is significantly reduced in the image space. In order to reduce the remaining appearance discrepancy, we further introduce a multi-granularity feature extraction network to conduct feature-level alignment. Rather than relying on the global information, we propose to exploit local (head-shoulder) features to assist person Re-ID, which complements each other to form a stronger feature descriptor. Comprehensive experiments implemented on the mainstream evaluation datasets include SYSU-MM01 and RegDB indicate that our method can significantly boost cross-modality retrieval performance against the state of the art methods.
WikiDes: A Wikipedia-Based Dataset for Generating Short Descriptions from Paragraphs
Sep 27, 2022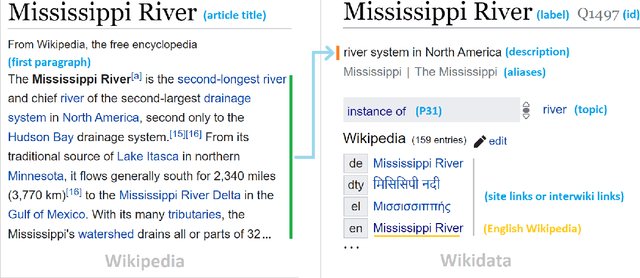
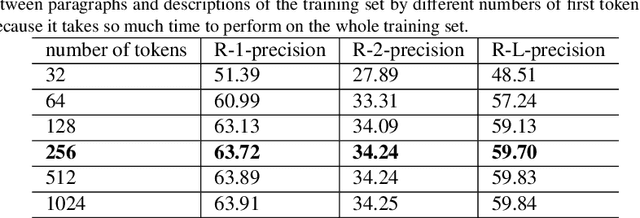
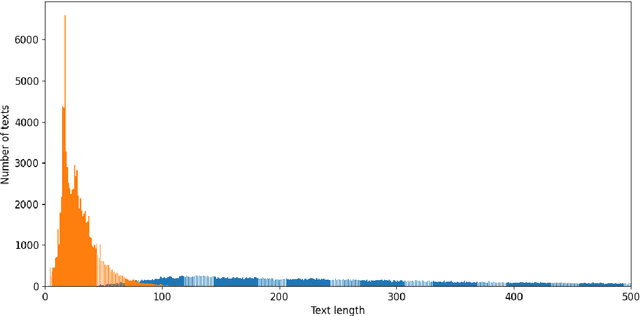

As free online encyclopedias with massive volumes of content, Wikipedia and Wikidata are key to many Natural Language Processing (NLP) tasks, such as information retrieval, knowledge base building, machine translation, text classification, and text summarization. In this paper, we introduce WikiDes, a novel dataset to generate short descriptions of Wikipedia articles for the problem of text summarization. The dataset consists of over 80k English samples on 6987 topics. We set up a two-phase summarization method - description generation (Phase I) and candidate ranking (Phase II) - as a strong approach that relies on transfer and contrastive learning. For description generation, T5 and BART show their superiority compared to other small-scale pre-trained models. By applying contrastive learning with the diverse input from beam search, the metric fusion-based ranking models outperform the direct description generation models significantly up to 22 ROUGE in topic-exclusive split and topic-independent split. Furthermore, the outcome descriptions in Phase II are supported by human evaluation in over 45.33% chosen compared to 23.66% in Phase I against the gold descriptions. In the aspect of sentiment analysis, the generated descriptions cannot effectively capture all sentiment polarities from paragraphs while doing this task better from the gold descriptions. The automatic generation of new descriptions reduces the human efforts in creating them and enriches Wikidata-based knowledge graphs. Our paper shows a practical impact on Wikipedia and Wikidata since there are thousands of missing descriptions. Finally, we expect WikiDes to be a useful dataset for related works in capturing salient information from short paragraphs. The curated dataset is publicly available at: https://github.com/declare-lab/WikiDes.
TLDW: Extreme Multimodal Summarisation of News Videos
Oct 16, 2022

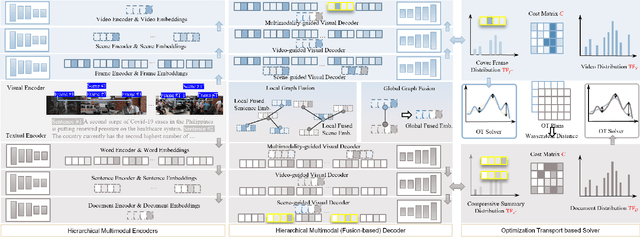
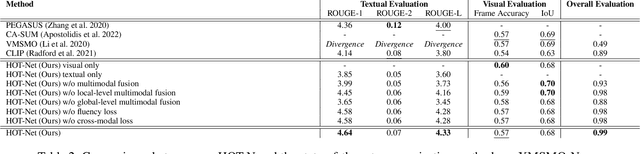
Multimodal summarisation with multimodal output is drawing increasing attention due to the rapid growth of multimedia data. While several methods have been proposed to summarise visual-text contents, their multimodal outputs are not succinct enough at an extreme level to address the information overload issue. To the end of extreme multimodal summarisation, we introduce a new task, eXtreme Multimodal Summarisation with Multimodal Output (XMSMO) for the scenario of TL;DW - Too Long; Didn't Watch, akin to TL;DR. XMSMO aims to summarise a video-document pair into a summary with an extremely short length, which consists of one cover frame as the visual summary and one sentence as the textual summary. We propose a novel unsupervised Hierarchical Optimal Transport Network (HOT-Net) consisting of three components: hierarchical multimodal encoders, hierarchical multimodal fusion decoders, and optimal transport solvers. Our method is trained, without using reference summaries, by optimising the visual and textual coverage from the perspectives of the distance between the semantic distributions under optimal transport plans. To facilitate the study on this task, we collect a large-scale dataset XMSMO-News by harvesting 4,891 video-document pairs. The experimental results show that our method achieves promising performance in terms of ROUGE and IoU metrics.
RIS-aided Zero-Forcing and Regularized Zero-Forcing Beamforming in Integrated Information and Energy Delivery
Jan 08, 2022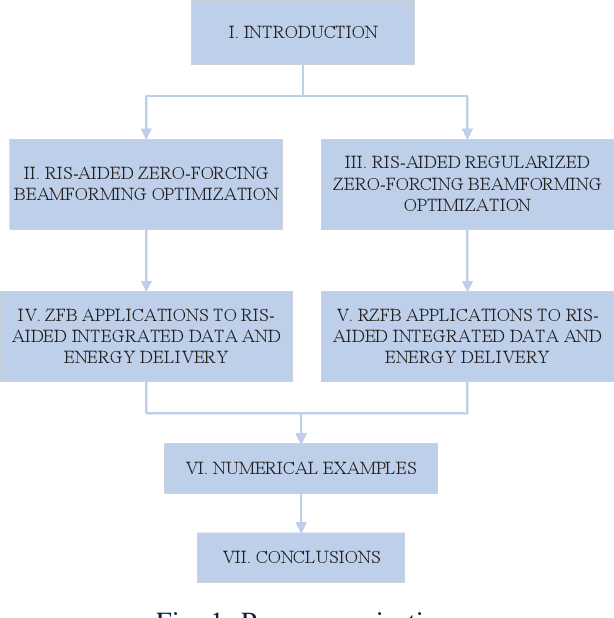
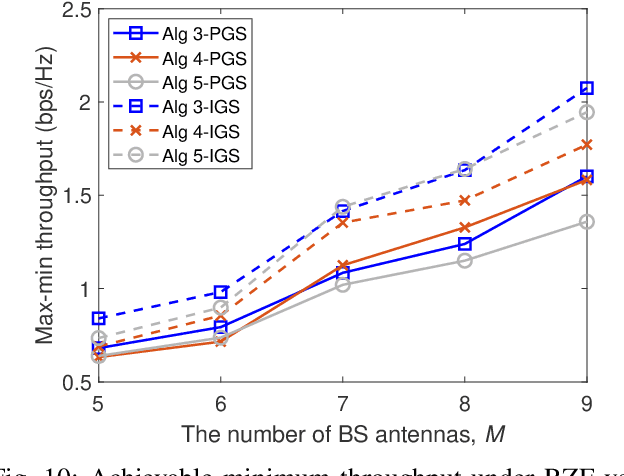
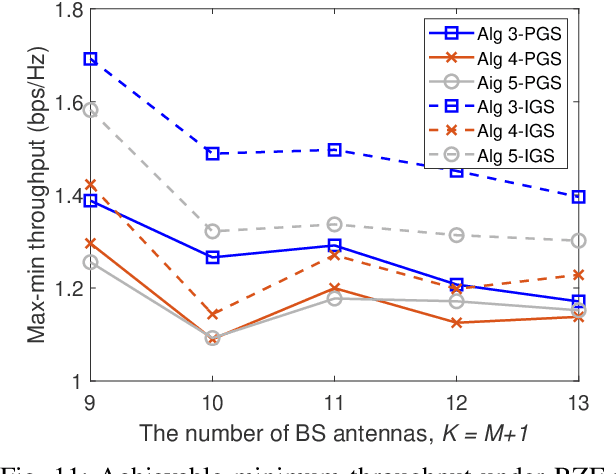
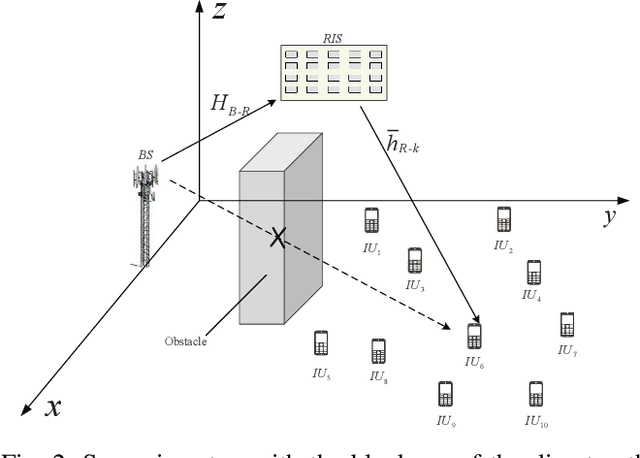
This paper considers a network of a multi-antenna array base station (BS) and a reconfigurable intelligent surface (RIS) to deliver both information to information users (IUs) and power to energy users (EUs). The RIS links the connection between the IUs and the BS as there is no direct path between the former and the latter. The EUs are located nearby the BS in order to effectively harvest energy from the high-power signal from the BS, while the much weaker signal reflected from the RIS hardly contributes to the EUs' harvested energy. To provide reliable links for all users over the same time-slot, we adopt the transmit time-switching (transmit-TS) approach, under which information and energy are delivered over different time-slot fractions. This allows us to rely on conjugate beamforming for energy links and zero-forcing/regularized zero-forcing beamforming (ZFB/RZFB) and on the programmable reflecting coefficients (PRCs) of the RIS for information links. We show that ZFB/RZFB and PRCs can be still separately optimized in their joint design, where PRC optimization is based on iterative closed-form expressions. We then develop a path-following algorithm for solving our max-min IU throughput optimization problem subject to a realistic constraint on the quality-of-energy-service in terms of the EUs' harvested energy thresholds. We also propose a new RZFB for substantially improving the IUs' throughput.