 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNORA-1.5: A Vision-Language-Action Model Trained using World Model- and Action-based Preference Rewards
Nov 18, 2025



Vision--language--action (VLA) models have recently shown promising performance on a variety of embodied tasks, yet they still fall short in reliability and generalization, especially when deployed across different embodiments or real-world environments. In this work, we introduce NORA-1.5, a VLA model built from the pre-trained NORA backbone by adding to it a flow-matching-based action expert. This architectural enhancement alone yields substantial performance gains, enabling NORA-1.5 to outperform NORA and several state-of-the-art VLA models across both simulated and real-world benchmarks. To further improve robustness and task success, we develop a set of reward models for post-training VLA policies. Our rewards combine (i) an action-conditioned world model (WM) that evaluates whether generated actions lead toward the desired goal, and (ii) a deviation-from-ground-truth heuristic that distinguishes good actions from poor ones. Using these reward signals, we construct preference datasets and adapt NORA-1.5 to target embodiments through direct preference optimization (DPO). Extensive evaluations show that reward-driven post-training consistently improves performance in both simulation and real-robot settings, demonstrating significant VLA model-reliability gains through simple yet effective reward models. Our findings highlight NORA-1.5 and reward-guided post-training as a viable path toward more dependable embodied agents suitable for real-world deployment.
10 Open Challenges Steering the Future of Vision-Language-Action Models
Nov 08, 2025Due to their ability of follow natural language instructions, vision-language-action (VLA) models are increasingly prevalent in the embodied AI arena, following the widespread success of their precursors -- LLMs and VLMs. In this paper, we discuss 10 principal milestones in the ongoing development of VLA models -- multimodality, reasoning, data, evaluation, cross-robot action generalization, efficiency, whole-body coordination, safety, agents, and coordination with humans. Furthermore, we discuss the emerging trends of using spatial understanding, modeling world dynamics, post training, and data synthesis -- all aiming to reach these milestones. Through these discussions, we hope to bring attention to the research avenues that may accelerate the development of VLA models into wider acceptability.
JAM: A Tiny Flow-based Song Generator with Fine-grained Controllability and Aesthetic Alignment
Jul 28, 2025



Diffusion and flow-matching models have revolutionized automatic text-to-audio generation in recent times. These models are increasingly capable of generating high quality and faithful audio outputs capturing to speech and acoustic events. However, there is still much room for improvement in creative audio generation that primarily involves music and songs. Recent open lyrics-to-song models, such as, DiffRhythm, ACE-Step, and LeVo, have set an acceptable standard in automatic song generation for recreational use. However, these models lack fine-grained word-level controllability often desired by musicians in their workflows. To the best of our knowledge, our flow-matching-based JAM is the first effort toward endowing word-level timing and duration control in song generation, allowing fine-grained vocal control. To enhance the quality of generated songs to better align with human preferences, we implement aesthetic alignment through Direct Preference Optimization, which iteratively refines the model using a synthetic dataset, eliminating the need or manual data annotations. Furthermore, we aim to standardize the evaluation of such lyrics-to-song models through our public evaluation dataset JAME. We show that JAM outperforms the existing models in terms of the music-specific attributes.
Lessons from Training Grounded LLMs with Verifiable Rewards
Jun 18, 2025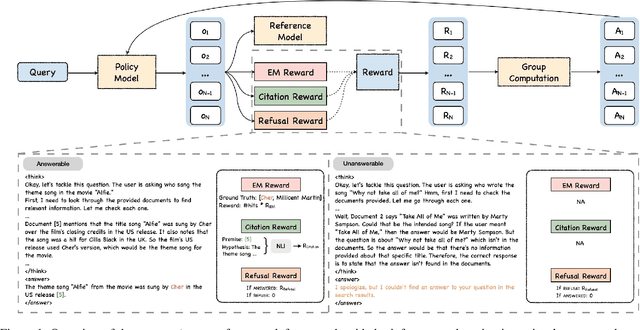
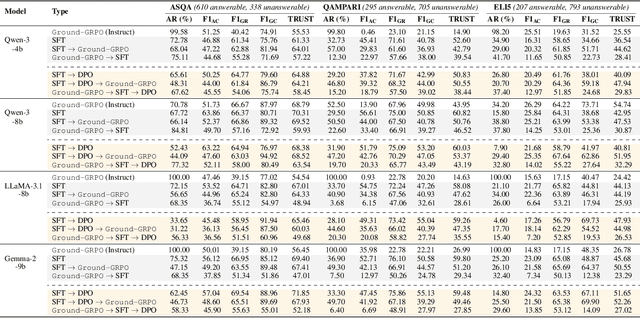
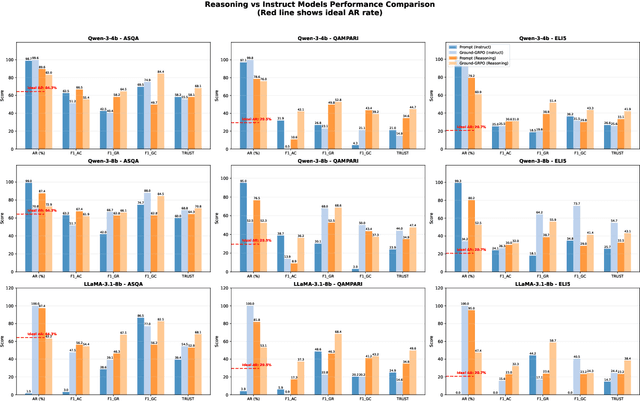
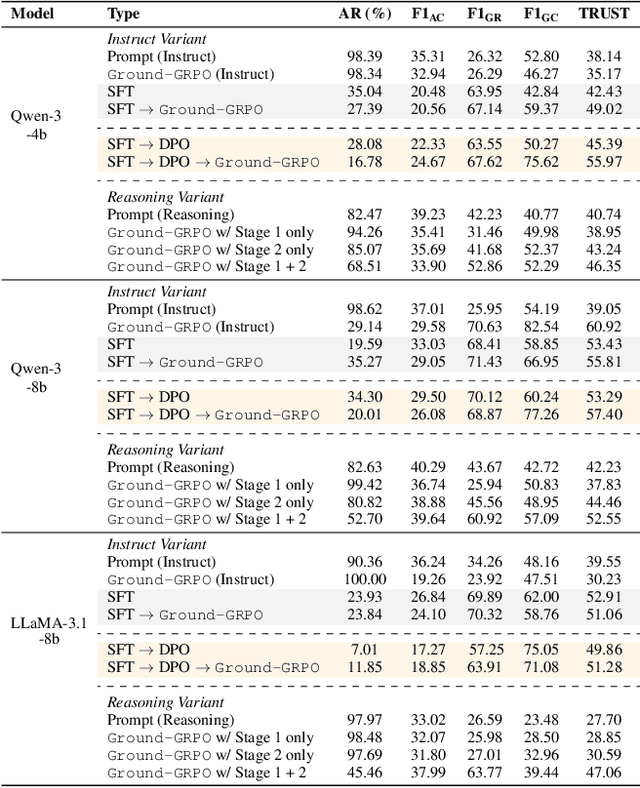
Generating grounded and trustworthy responses remains a key challenge for large language models (LLMs). While retrieval-augmented generation (RAG) with citation-based grounding holds promise, instruction-tuned models frequently fail even in straightforward scenarios: missing explicitly stated answers, citing incorrectly, or refusing when evidence is available. In this work, we explore how reinforcement learning (RL) and internal reasoning can enhance grounding in LLMs. We use the GRPO (Group Relative Policy Optimization) method to train models using verifiable outcome-based rewards targeting answer correctness, citation sufficiency, and refusal quality, without requiring gold reasoning traces or expensive annotations. Through comprehensive experiments across ASQA, QAMPARI, ELI5, and ExpertQA we show that reasoning-augmented models significantly outperform instruction-only variants, especially in handling unanswerable queries and generating well-cited responses. A two-stage training setup, first optimizing answer and citation behavior and then refusal, further improves grounding by stabilizing the learning signal. Additionally, we revisit instruction tuning via GPT-4 distillation and find that combining it with GRPO enhances performance on long-form, generative QA tasks. Overall, our findings highlight the value of reasoning, stage-wise optimization, and outcome-driven RL for building more verifiable and reliable LLMs.
NORA: A Small Open-Sourced Generalist Vision Language Action Model for Embodied Tasks
Apr 28, 2025



Existing Visual-Language-Action (VLA) models have shown promising performance in zero-shot scenarios, demonstrating impressive task execution and reasoning capabilities. However, a significant challenge arises from the limitations of visual encoding, which can result in failures during tasks such as object grasping. Moreover, these models typically suffer from high computational overhead due to their large sizes, often exceeding 7B parameters. While these models excel in reasoning and task planning, the substantial computational overhead they incur makes them impractical for real-time robotic environments, where speed and efficiency are paramount. To address the limitations of existing VLA models, we propose NORA, a 3B-parameter model designed to reduce computational overhead while maintaining strong task performance. NORA adopts the Qwen-2.5-VL-3B multimodal model as its backbone, leveraging its superior visual-semantic understanding to enhance visual reasoning and action grounding. Additionally, our \model{} is trained on 970k real-world robot demonstrations and equipped with the FAST+ tokenizer for efficient action sequence generation. Experimental results demonstrate that NORA outperforms existing large-scale VLA models, achieving better task performance with significantly reduced computational overhead, making it a more practical solution for real-time robotic autonomy.
TangoFlux: Super Fast and Faithful Text to Audio Generation with Flow Matching and Clap-Ranked Preference Optimization
Dec 30, 2024We introduce TangoFlux, an efficient Text-to-Audio (TTA) generative model with 515M parameters, capable of generating up to 30 seconds of 44.1kHz audio in just 3.7 seconds on a single A40 GPU. A key challenge in aligning TTA models lies in the difficulty of creating preference pairs, as TTA lacks structured mechanisms like verifiable rewards or gold-standard answers available for Large Language Models (LLMs). To address this, we propose CLAP-Ranked Preference Optimization (CRPO), a novel framework that iteratively generates and optimizes preference data to enhance TTA alignment. We demonstrate that the audio preference dataset generated using CRPO outperforms existing alternatives. With this framework, TangoFlux achieves state-of-the-art performance across both objective and subjective benchmarks. We open source all code and models to support further research in TTA generation.
Measuring and Enhancing Trustworthiness of LLMs in RAG through Grounded Attributions and Learning to Refuse
Sep 17, 2024



LLMs are an integral part of retrieval-augmented generation (RAG) systems. While many studies focus on evaluating the quality of end-to-end RAG systems, there is a lack of research on understanding the appropriateness of an LLM for the RAG task. Thus, we introduce a new metric, Trust-Score, that provides a holistic evaluation of the trustworthiness of LLMs in an RAG framework. We show that various prompting methods, such as in-context learning, fail to adapt LLMs effectively to the RAG task. Thus, we propose Trust-Align, a framework to align LLMs for higher Trust-Score. LLaMA-3-8b, aligned with our method, significantly outperforms open-source LLMs of comparable sizes on ASQA (up 10.7), QAMPARI (up 29.2) and ELI5 (up 14.9). We release our code at: https://github.com/declare-lab/trust-align.
Reward Steering with Evolutionary Heuristics for Decoding-time Alignment
Jun 25, 2024



The widespread applicability and increasing omnipresence of LLMs have instigated a need to align LLM responses to user and stakeholder preferences. Many preference optimization approaches have been proposed that fine-tune LLM parameters to achieve good alignment. However, such parameter tuning is known to interfere with model performance on many tasks. Moreover, keeping up with shifting user preferences is tricky in such a situation. Decoding-time alignment with reward model guidance solves these issues at the cost of increased inference time. However, most of such methods fail to strike the right balance between exploration and exploitation of reward -- often due to the conflated formulation of these two aspects - to give well-aligned responses. To remedy this we decouple these two aspects and implement them in an evolutionary fashion: exploration is enforced by decoding from mutated instructions and exploitation is represented as the periodic replacement of poorly-rewarded generations with well-rewarded ones. Empirical evidences indicate that this strategy outperforms many preference optimization and decode-time alignment approaches on two widely accepted alignment benchmarks AlpacaEval 2 and MT-Bench. Our implementation will be available at: https://darwin-alignment.github.io.
Improving Text-To-Audio Models with Synthetic Captions
Jun 18, 2024



It is an open challenge to obtain high quality training data, especially captions, for text-to-audio models. Although prior methods have leveraged \textit{text-only language models} to augment and improve captions, such methods have limitations related to scale and coherence between audio and captions. In this work, we propose an audio captioning pipeline that uses an \textit{audio language model} to synthesize accurate and diverse captions for audio at scale. We leverage this pipeline to produce a dataset of synthetic captions for AudioSet, named \texttt{AF-AudioSet}, and then evaluate the benefit of pre-training text-to-audio models on these synthetic captions. Through systematic evaluations on AudioCaps and MusicCaps, we find leveraging our pipeline and synthetic captions leads to significant improvements on audio generation quality, achieving a new \textit{state-of-the-art}.
Tango 2: Aligning Diffusion-based Text-to-Audio Generations through Direct Preference Optimization
Apr 16, 2024



Generative multimodal content is increasingly prevalent in much of the content creation arena, as it has the potential to allow artists and media personnel to create pre-production mockups by quickly bringing their ideas to life. The generation of audio from text prompts is an important aspect of such processes in the music and film industry. Many of the recent diffusion-based text-to-audio models focus on training increasingly sophisticated diffusion models on a large set of datasets of prompt-audio pairs. These models do not explicitly focus on the presence of concepts or events and their temporal ordering in the output audio with respect to the input prompt. Our hypothesis is focusing on how these aspects of audio generation could improve audio generation performance in the presence of limited data. As such, in this work, using an existing text-to-audio model Tango, we synthetically create a preference dataset where each prompt has a winner audio output and some loser audio outputs for the diffusion model to learn from. The loser outputs, in theory, have some concepts from the prompt missing or in an incorrect order. We fine-tune the publicly available Tango text-to-audio model using diffusion-DPO (direct preference optimization) loss on our preference dataset and show that it leads to improved audio output over Tango and AudioLDM2, in terms of both automatic- and manual-evaluation metrics.