 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMicro-AU CLIP: Fine-Grained Contrastive Learning from Local Independence to Global Dependency for Micro-Expression Action Unit Detection
Mar 17, 2026Micro-expression (ME) action units (Micro-AUs) provide objective clues for fine-grained genuine emotion analysis. Most existing Micro-AU detection methods learn AU features from the whole facial image/video, which conflicts with the inherent locality of AU, resulting in insufficient perception of AU regions. In fact, each AU independently corresponds to specific localized facial muscle movements (local independence), while there is an inherent dependency between some AUs under specific emotional states (global dependency). Thus, this paper explores the effectiveness of the independence-to-dependency pattern and proposes a novel micro-AU detection framework, micro-AU CLIP, that uniquely decomposes the AU detection process into local semantic independence modeling (LSI) and global semantic dependency (GSD) modeling. In LSI, Patch Token Attention (PTA) is designed, mapping several local features within the AU region to the same feature space; In GSD, Global Dependency Attention (GDA) and Global Dependency Loss (GDLoss) are presented to model the global dependency relationships between different AUs, thereby enhancing each AU feature. Furthermore, considering CLIP's native limitations in micro-semantic alignment, a microAU contrastive loss (MiAUCL) is designed to learn AU features by a fine-grained alignment of visual and text features. Also, Micro-AU CLIP is effectively applied to ME recognition in an emotion-label-free way. The experimental results demonstrate that Micro-AU CLIP can fully learn fine-grained micro-AU features, achieving state-of-the-art performance.
Learning Transferable Facial Emotion Representations from Large-Scale Semantically Rich Captions
Jul 28, 2025Current facial emotion recognition systems are predominately trained to predict a fixed set of predefined categories or abstract dimensional values. This constrained form of supervision hinders generalization and applicability, as it reduces the rich and nuanced spectrum of emotions into oversimplified labels or scales. In contrast, natural language provides a more flexible, expressive, and interpretable way to represent emotions, offering a much broader source of supervision. Yet, leveraging semantically rich natural language captions as supervisory signals for facial emotion representation learning remains relatively underexplored, primarily due to two key challenges: 1) the lack of large-scale caption datasets with rich emotional semantics, and 2) the absence of effective frameworks tailored to harness such rich supervision. To this end, we introduce EmoCap100K, a large-scale facial emotion caption dataset comprising over 100,000 samples, featuring rich and structured semantic descriptions that capture both global affective states and fine-grained local facial behaviors. Building upon this dataset, we further propose EmoCapCLIP, which incorporates a joint global-local contrastive learning framework enhanced by a cross-modal guided positive mining module. This design facilitates the comprehensive exploitation of multi-level caption information while accommodating semantic similarities between closely related expressions. Extensive evaluations on over 20 benchmarks covering five tasks demonstrate the superior performance of our method, highlighting the promise of learning facial emotion representations from large-scale semantically rich captions. The code and data will be available at https://github.com/sunlicai/EmoCapCLIP.
MagicPortrait: Temporally Consistent Face Reenactment with 3D Geometric Guidance
Apr 30, 2025In this paper, we propose a method for video face reenactment that integrates a 3D face parametric model into a latent diffusion framework, aiming to improve shape consistency and motion control in existing video-based face generation approaches. Our approach employs the FLAME (Faces Learned with an Articulated Model and Expressions) model as the 3D face parametric representation, providing a unified framework for modeling face expressions and head pose. This enables precise extraction of detailed face geometry and motion features from driving videos. Specifically, we enhance the latent diffusion model with rich 3D expression and detailed pose information by incorporating depth maps, normal maps, and rendering maps derived from FLAME sequences. A multi-layer face movements fusion module with integrated self-attention mechanisms is used to combine identity and motion latent features within the spatial domain. By utilizing the 3D face parametric model as motion guidance, our method enables parametric alignment of face identity between the reference image and the motion captured from the driving video. Experimental results on benchmark datasets show that our method excels at generating high-quality face animations with precise expression and head pose variation modeling. In addition, it demonstrates strong generalization performance on out-of-domain images. Code is publicly available at https://github.com/weimengting/MagicPortrait.
Infused Suppression Of Magnification Artefacts For Micro-AU Detection
Apr 12, 2025Facial micro-expressions are spontaneous, brief and subtle facial motions that unveil the underlying, suppressed emotions. Detecting Action Units (AUs) in micro-expressions is crucial because it yields a finer representation of facial motions than categorical emotions, effectively resolving the ambiguity among different expressions. One of the difficulties in micro-expression analysis is that facial motions are subtle and brief, thereby increasing the difficulty in correlating facial motion features to AU occurrence. To bridge the subtlety issue, flow-related features and motion magnification are a few common approaches as they can yield descriptive motion changes and increased motion amplitude respectively. While motion magnification can amplify the motion changes, it also accounts for illumination changes and projection errors during the amplification process, thereby creating motion artefacts that confuse the model to learn inauthentic magnified motion features. The problem is further aggravated in the context of a more complicated task where more AU classes are analyzed in cross-database settings. To address this issue, we propose InfuseNet, a layer-wise unitary feature infusion framework that leverages motion context to constrain the Action Unit (AU) learning within an informative facial movement region, thereby alleviating the influence of magnification artefacts. On top of that, we propose leveraging magnified latent features instead of reconstructing magnified samples to limit the distortion and artefacts caused by the projection inaccuracy in the motion reconstruction process. Via alleviating the magnification artefacts, InfuseNet has surpassed the state-of-the-art results in the CD6ME protocol. Further quantitative studies have also demonstrated the efficacy of motion artefacts alleviation.
Towards Consistent and Controllable Image Synthesis for Face Editing
Feb 04, 2025Current face editing methods mainly rely on GAN-based techniques, but recent focus has shifted to diffusion-based models due to their success in image reconstruction. However, diffusion models still face challenges in manipulating fine-grained attributes and preserving consistency of attributes that should remain unchanged. To address these issues and facilitate more convenient editing of face images, we propose a novel approach that leverages the power of Stable-Diffusion models and crude 3D face models to control the lighting, facial expression and head pose of a portrait photo. We observe that this task essentially involve combinations of target background, identity and different face attributes. We aim to sufficiently disentangle the control of these factors to enable high-quality of face editing. Specifically, our method, coined as RigFace, contains: 1) A Spatial Arrtibute Encoder that provides presise and decoupled conditions of background, pose, expression and lighting; 2) An Identity Encoder that transfers identity features to the denoising UNet of a pre-trained Stable-Diffusion model; 3) An Attribute Rigger that injects those conditions into the denoising UNet. Our model achieves comparable or even superior performance in both identity preservation and photorealism compared to existing face editing models.
Towards Localized Fine-Grained Control for Facial Expression Generation
Jul 25, 2024Generative models have surged in popularity recently due to their ability to produce high-quality images and video. However, steering these models to produce images with specific attributes and precise control remains challenging. Humans, particularly their faces, are central to content generation due to their ability to convey rich expressions and intent. Current generative models mostly generate flat neutral expressions and characterless smiles without authenticity. Other basic expressions like anger are possible, but are limited to the stereotypical expression, while other unconventional facial expressions like doubtful are difficult to reliably generate. In this work, we propose the use of AUs (action units) for facial expression control in face generation. AUs describe individual facial muscle movements based on facial anatomy, allowing precise and localized control over the intensity of facial movements. By combining different action units, we unlock the ability to create unconventional facial expressions that go beyond typical emotional models, enabling nuanced and authentic reactions reflective of real-world expressions. The proposed method can be seamlessly integrated with both text and image prompts using adapters, offering precise and intuitive control of the generated results. Code and dataset are available in {https://github.com/tvaranka/fineface}.
Data Leakage and Evaluation Issues in Micro-Expression Analysis
Nov 21, 2022



Micro-expressions have drawn increasing interest lately due to various potential applications. The task is, however, difficult as it incorporates many challenges from the fields of computer vision, machine learning and emotional sciences. Due to the spontaneous and subtle characteristics of micro-expressions, the available training and testing data are limited, which make evaluation complex. We show that data leakage and fragmented evaluation protocols are issues among the micro-expression literature. We find that fixing data leaks can drastically reduce model performance, in some cases even making the models perform similarly to a random classifier. To this end, we go through common pitfalls, propose a new standardized evaluation protocol using facial action units with over 2000 micro-expression samples, and provide an open source library that implements the evaluation protocols in a standardized manner. Code will be available in \url{https://github.com/tvaranka/meb}.
Exploring Interactions and Regulations in Collaborative Learning: An Interdisciplinary Multimodal Dataset
Oct 11, 2022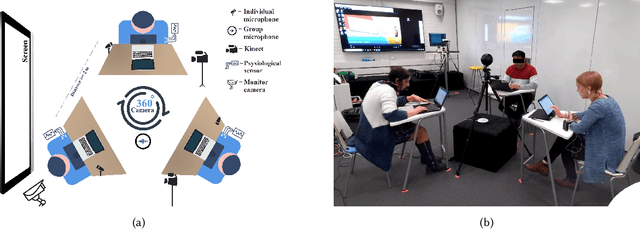
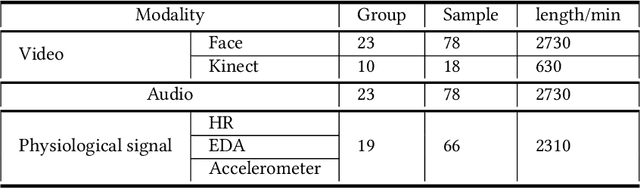

Collaborative learning is an educational approach that enhances learning through shared goals and working together. Interaction and regulation are two essential factors related to the success of collaborative learning. Since the information from various modalities can reflect the quality of collaboration, a new multimodal dataset with cognitive and emotional triggers is introduced in this paper to explore how regulations affect interactions during the collaborative process. Specifically, a learning task with intentional interventions is designed and assigned to high school students aged 15 years old (N=81) in average. Multimodal signals, including video, Kinect, audio, and physiological data, are collected and exploited to study regulations in collaborative learning in terms of individual-participant-single-modality, individual-participant-multiple-modality, and multiple-participant-multiple-modality. Analysis of annotated emotions, body gestures, and their interactions indicates that our multimodal dataset with designed treatments could effectively examine moments of regulation in collaborative learning. In addition, preliminary experiments based on baseline models suggest that the dataset provides a challenging in-the-wild scenario, which could further contribute to the fields of education and affective computing.
Geometric Graph Representation with Learnable Graph Structure and Adaptive AU Constraint for Micro-Expression Recognition
May 01, 2022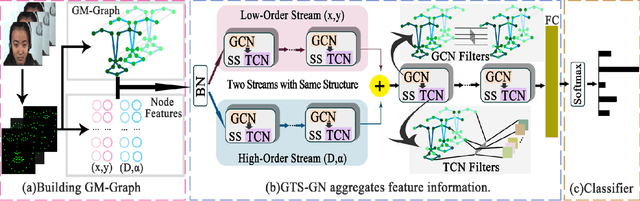
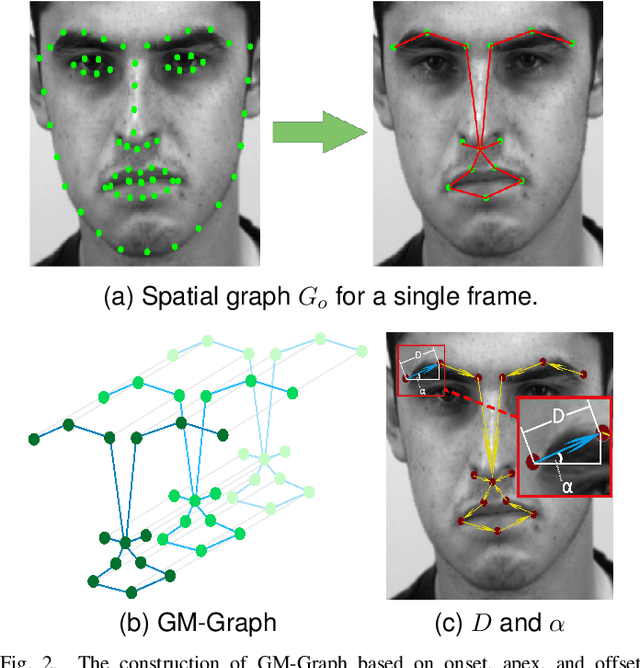
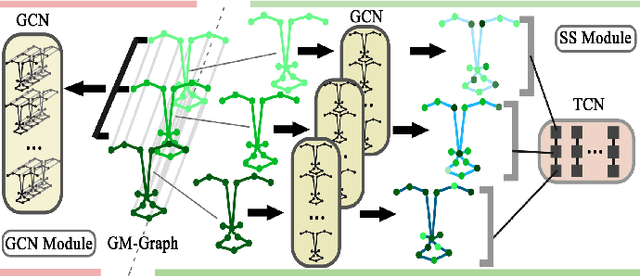
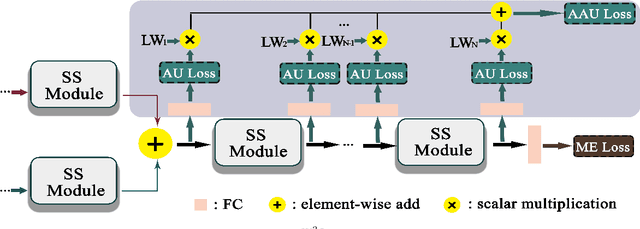
Micro-expression recognition (MER) is valuable because the involuntary nature of micro-expressions (MEs) can reveal genuine emotions. Most works recognize MEs by taking RGB videos or images as input. In fact, the activated facial regions in ME images are very small and the subtle motion can be easily submerged in the unrelated information. Facial landmarks are a low-dimensional and compact modality, which leads to much lower computational cost and can potentially concentrate more on ME-related features. However, the discriminability of landmarks for MER is not clear. Thus, this paper explores the contribution of facial landmarks and constructs a new framework to efficiently recognize MEs with sole facial landmark information. Specially, we design a separate structure module to separately aggregate the spatial and temporal information in the geometric movement graph based on facial landmarks, and a Geometric Two-Stream Graph Network is constructed to aggregate the low-order geometric information and high-order semantic information of facial landmarks. Furthermore, two core components are proposed to enhance features. Specifically, a semantic adjacency matrix can automatically model the relationship between nodes even long-distance nodes in a self-learning fashion; and an Adaptive Action Unit loss is introduced to guide the learning process such that the learned features are forced to have a synchronized pattern with facial action units. Notably, this work tackles MER only utilizing geometric features, processed based on a graph model, which provides a new idea with much higher efficiency to promote MER. The experimental results demonstrate that the proposed method can achieve competitive or even superior performance with a significantly reduced computational cost, and facial landmarks can significantly contribute to MER and are worth further study for efficient ME analysis.
Deep Learning based Micro-expression Recognition: A Survey
Jul 06, 2021
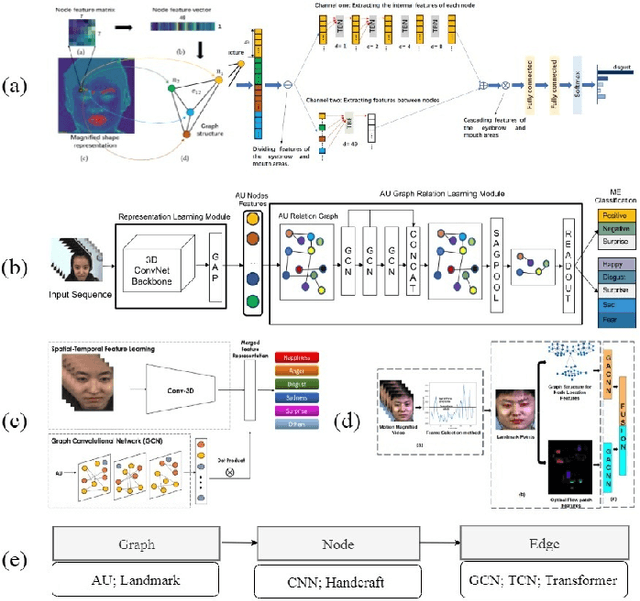
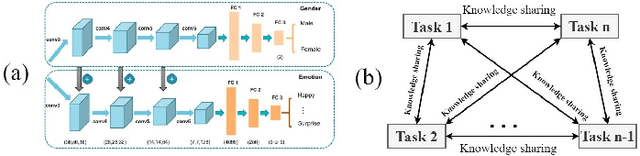
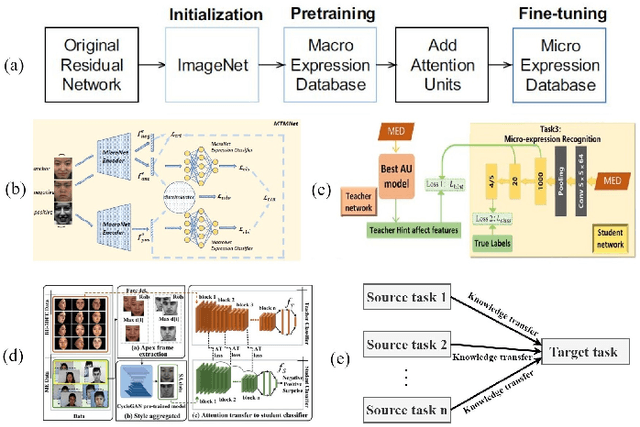
Micro-expressions (MEs) are involuntary facial movements revealing people's hidden feelings in high-stake situations and have practical importance in medical treatment, national security, interrogations and many human-computer interaction systems. Early methods for MER mainly based on traditional appearance and geometry features. Recently, with the success of deep learning (DL) in various fields, neural networks have received increasing interests in MER. Different from macro-expressions, MEs are spontaneous, subtle, and rapid facial movements, leading to difficult data collection, thus have small-scale datasets. DL based MER becomes challenging due to above ME characters. To data, various DL approaches have been proposed to solve the ME issues and improve MER performance. In this survey, we provide a comprehensive review of deep micro-expression recognition (MER), including datasets, deep MER pipeline, and the bench-marking of most influential methods. This survey defines a new taxonomy for the field, encompassing all aspects of MER based on DL. For each aspect, the basic approaches and advanced developments are summarized and discussed. In addition, we conclude the remaining challenges and and potential directions for the design of robust deep MER systems. To the best of our knowledge, this is the first survey of deep MER methods, and this survey can serve as a reference point for future MER research.