 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Coherence Law for Trainability in Noisy Equivariant Quantum Neural Networks
Jun 28, 2026Symmetry provides a quantum neural network structure, but on its own it does not keep the network trainable once noise is present. We ask which physical quantity decides whether the gradients of an equivariant circuit survive decoherence, and we answer with a compact training law. Working with U(1)-equivariant brickwork circuits that conserve a charge, we find that two distinct effects govern a trainable gradient. Causality fixes where the gradient can live, confining it to the backward light cone of the readout inside the active charge sector. Coherence then determines how fast it decays through the contraction of the off-diagonal sector modes that the projected readout can actually observe. We prove a light-cone reduction that pins the noiseless gradient to the sector-restricted cone with a lower bound independent of the total qubit number, and we define a readout-visible aligned coherence rate as a Rayleigh quotient of the noise generator along the gradient-carrying mode. A perturbative open-system analysis turns this rate into a leading-order training law. Density-matrix simulations then confirm that the finite-noise degradation follows a single accumulated variable built from noise depth and coherence contraction, with a coefficient of determination of 0.979. The sharpest test comes from a correlated-dephasing channel that has a large worst-case rate but a near-zero aligned rate. The law predicts no gradient loss for this channel, and none is seen. Sector coherence outperforms every standard channel diagnostic we compare it against, and the analysis identifies readout-visible sector coherence as the quantity that links equivariant architecture, open-system dynamics and noisy trainability.
Training Deep Visual Networks Beyond Loss and Accuracy Through a Dynamical Systems Approach
Apr 08, 2026Deep visual recognition models are usually trained and evaluated using metrics such as loss and accuracy. While these measures show whether a model is improving, they reveal very little about how its internal representations change during training. This paper introduces a complementary way to study that process by examining training through the lens of dynamical systems. Drawing on ideas from signal analysis originally used to study biological neural activity, we define three measures from layer activations collected across training epochs: an integration score that reflects long-range coordination across layers, a metastability score that captures how flexibly the network shifts between more and less synchronised states, and a combined dynamical stability index. We apply this framework to nine combinations of model architecture and dataset, including several ResNet variants, DenseNet-121, MobileNetV2, VGG-16, and a pretrained Vision Transformer on CIFAR-10 and CIFAR-100. The results suggest three main patterns. First, the integration measure consistently distinguishes the easier CIFAR-10 setting from the more difficult CIFAR-100 setting. Second, changes in the volatility of the stability index may provide an early sign of convergence before accuracy fully plateaus. Third, the relationship between integration and metastability appears to reflect different styles of training behaviour. Overall, this study offers an exploratory but promising new way to understand deep visual training beyond loss and accuracy.
A Neural Tension Operator for Curve Subdivision across Constant Curvature Geometries
Mar 30, 2026Interpolatory subdivision schemes generate smooth curves from piecewise-linear control polygons by repeatedly inserting new vertices. Classical schemes rely on a single global tension parameter and typically require separate formulations in Euclidean, spherical, and hyperbolic geometries. We introduce a shared learned tension predictor that replaces the global parameter with per-edge insertion angles predicted by a single 140K-parameter network. The network takes local intrinsic features and a trainable geometry embedding as input, and the predicted angles drive geometry-specific insertion operators across all three spaces without architectural modification. A constrained sigmoid output head enforces a structural safety bound, guaranteeing that every inserted vertex lies within a valid angular range for any finite weight configuration. Three theoretical results accompany the method: a structural guarantee of tangent-safe insertions; a heuristic motivation for per-edge adaptivity; and a conditional convergence certificate for continuously differentiable limit curves, subject to an explicit Lipschitz constraint verified post hoc. On 240 held-out validation curves, the learned predictor occupies a distinct position on the fidelity--smoothness Pareto frontier, achieving markedly lower bending energy and angular roughness than all fixed-tension and manifold-lift baselines. Riemannian manifold lifts retain a pointwise-fidelity advantage, which this study quantifies directly. On the out-of-distribution ISS orbital ground-track example, bending energy falls by 41% and angular roughness by 68% with only a modest increase in Hausdorff distance, suggesting that the predictor generalises beyond its synthetic training distribution.
Dynamical Systems Analysis Reveals Functional Regimes in Large Language Models
Jan 11, 2026Large language models perform text generation through high-dimensional internal dynamics, yet the temporal organisation of these dynamics remains poorly understood. Most interpretability approaches emphasise static representations or causal interventions, leaving temporal structure largely unexplored. Drawing on neuroscience, where temporal integration and metastability are core markers of neural organisation, we adapt these concepts to transformer models and discuss a composite dynamical metric, computed from activation time-series during autoregressive generation. We evaluate this metric in GPT-2-medium across five conditions: structured reasoning, forced repetition, high-temperature noisy sampling, attention-head pruning, and weight-noise injection. Structured reasoning consistently exhibits elevated metric relative to repetitive, noisy, and perturbed regimes, with statistically significant differences confirmed by one-way ANOVA and large effect sizes in key comparisons. These results are robust to layer selection, channel subsampling, and random seeds. Our findings demonstrate that neuroscience-inspired dynamical metrics can reliably characterise differences in computational organisation across functional regimes in large language models. We stress that the proposed metric captures formal dynamical properties and does not imply subjective experience.
Advancing Neuromorphic Computing: Mixed-Signal Design Techniques Leveraging Brain Code Units and Fundamental Code Units
Mar 18, 2024This paper introduces a groundbreaking digital neuromorphic architecture that innovatively integrates Brain Code Unit (BCU) and Fundamental Code Unit (FCU) using mixedsignal design methodologies. Leveraging open-source datasets and the latest advances in materials science, our research focuses on enhancing the computational efficiency, accuracy, and adaptability of neuromorphic systems. The core of our approach lies in harmonizing the precision and scalability of digital systems with the robustness and energy efficiency of analog processing. Through experimentation, we demonstrate the effectiveness of our system across various metrics. The BCU achieved an accuracy of 88.0% and a power efficiency of 20.0 GOP/s/W, while the FCU recorded an accuracy of 86.5% and a power efficiency of 18.5 GOP/s/W. Our mixed-signal design approach significantly improved latency and throughput, achieving a latency as low as 0.75 ms and throughput up to 213 TOP/s. These results firmly establish the potential of our architecture in neuromorphic computing, providing a solid foundation for future developments in this domain. Our study underscores the feasibility of mixedsignal neuromorphic systems and their promise in advancing the field, particularly in applications requiring high efficiency and adaptability
WikiDes: A Wikipedia-Based Dataset for Generating Short Descriptions from Paragraphs
Sep 27, 2022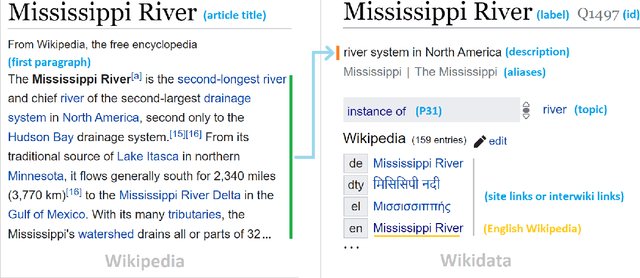
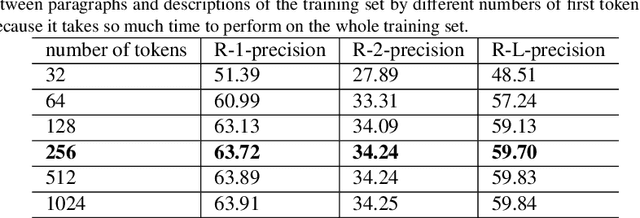
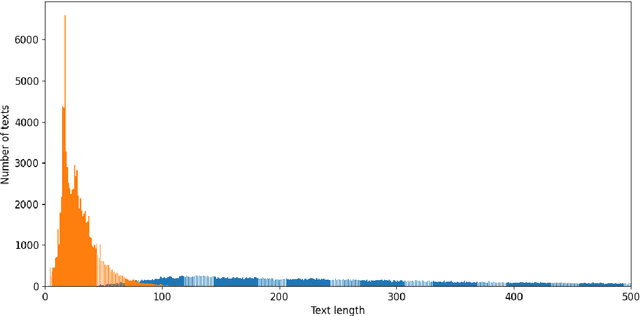

As free online encyclopedias with massive volumes of content, Wikipedia and Wikidata are key to many Natural Language Processing (NLP) tasks, such as information retrieval, knowledge base building, machine translation, text classification, and text summarization. In this paper, we introduce WikiDes, a novel dataset to generate short descriptions of Wikipedia articles for the problem of text summarization. The dataset consists of over 80k English samples on 6987 topics. We set up a two-phase summarization method - description generation (Phase I) and candidate ranking (Phase II) - as a strong approach that relies on transfer and contrastive learning. For description generation, T5 and BART show their superiority compared to other small-scale pre-trained models. By applying contrastive learning with the diverse input from beam search, the metric fusion-based ranking models outperform the direct description generation models significantly up to 22 ROUGE in topic-exclusive split and topic-independent split. Furthermore, the outcome descriptions in Phase II are supported by human evaluation in over 45.33% chosen compared to 23.66% in Phase I against the gold descriptions. In the aspect of sentiment analysis, the generated descriptions cannot effectively capture all sentiment polarities from paragraphs while doing this task better from the gold descriptions. The automatic generation of new descriptions reduces the human efforts in creating them and enriches Wikidata-based knowledge graphs. Our paper shows a practical impact on Wikipedia and Wikidata since there are thousands of missing descriptions. Finally, we expect WikiDes to be a useful dataset for related works in capturing salient information from short paragraphs. The curated dataset is publicly available at: https://github.com/declare-lab/WikiDes.
Deep clustering of longitudinal data
Feb 09, 2018



Deep neural networks are a family of computational models that have led to a dramatical improvement of the state of the art in several domains such as image, voice or text analysis. These methods provide a framework to model complex, non-linear interactions in large datasets, and are naturally suited to the analysis of hierarchical data such as, for instance, longitudinal data with the use of recurrent neural networks. In the other hand, cohort studies have become a tool of importance in the research field of epidemiology. In such studies, variables are measured repeatedly over time, to allow the practitioner to study their temporal evolution as trajectories, and, as such, as longitudinal data. This paper investigates the application of the advanced modelling techniques provided by the deep learning framework in the analysis of the longitudinal data provided by cohort studies. Methods: A method for visualizing and clustering longitudinal dataset is proposed, and compared to other widely used approaches to the problem on both real and simulated datasets. Results: The proposed method is shown to be coherent with the preexisting procedures on simple tasks, and to outperform them on more complex tasks such as the partitioning of longitudinal datasets into non-spherical clusters. Conclusion: Deep artificial neural networks can be used to visualize longitudinal data in a low dimensional manifold that is much simpler to interpret than traditional longitudinal plots are. Consequently, practitioners should start considering the use of deep artificial neural networks for the analysis of their longitudinal data in studies to come.
A new recurrent neural network based predictive model for Faecal Calprotectin analysis: A retrospective study
Dec 17, 2016



Faecal Calprotectin (FC) is a surrogate marker for intestinal inflammation, termed Inflammatory Bowel Disease (IBD), but not for cancer. In this retrospective study of 804 patients, an enhanced benchmark predictive model for analyzing FC is developed, based on a novel state-of-the-art Echo State Network (ESN), an advanced dynamic recurrent neural network which implements a biologically plausible architecture, and a supervised learning mechanism. The proposed machine learning driven predictive model is benchmarked against a conventional logistic regression model, demonstrating statistically significant performance improvements.