 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
INFINITY: A Simple Yet Effective Unsupervised Framework for Graph-Text Mutual Conversion
Sep 22, 2022
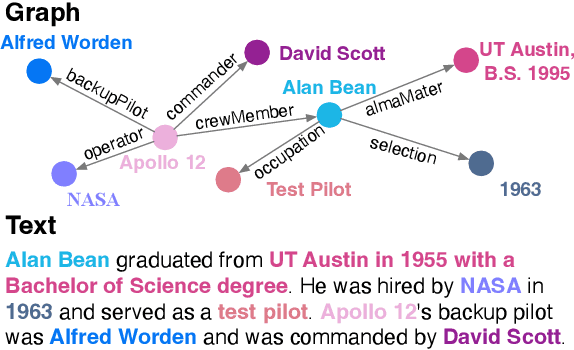

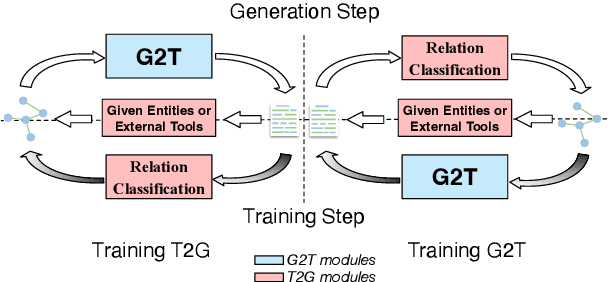
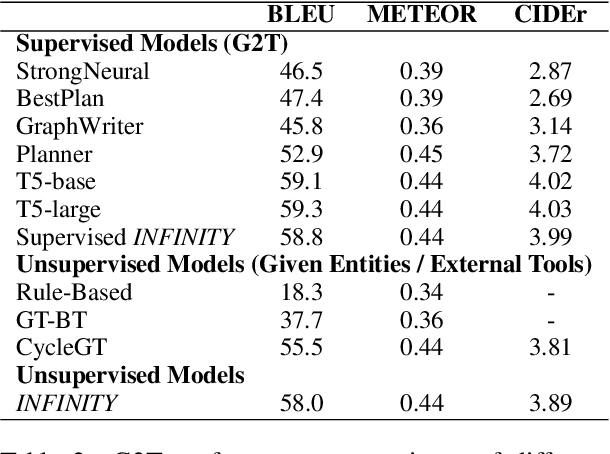
Graph-to-text (G2T) generation and text-to-graph (T2G) triple extraction are two essential tasks for constructing and applying knowledge graphs. Existing unsupervised approaches turn out to be suitable candidates for jointly learning the two tasks due to their avoidance of using graph-text parallel data. However, they are composed of multiple modules and still require both entity information and relation type in the training process. To this end, we propose INFINITY, a simple yet effective unsupervised approach that does not require external annotation tools or additional parallel information. It achieves fully unsupervised graph-text mutual conversion for the first time. Specifically, INFINITY treats both G2T and T2G as a bidirectional sequence generation task by fine-tuning only one pretrained seq2seq model. A novel back-translation-based framework is then designed to automatically generate continuous synthetic parallel data. To obtain reasonable graph sequences with structural information from source texts, INFINITY employs reward-based training loss by leveraging the advantage of reward augmented maximum likelihood. As a fully unsupervised framework, INFINITY is empirically verified to outperform state-of-the-art baselines for G2T and T2G tasks.
BLADERUNNER: Rapid Countermeasure for Synthetic (AI-Generated) StyleGAN Faces
Oct 14, 2022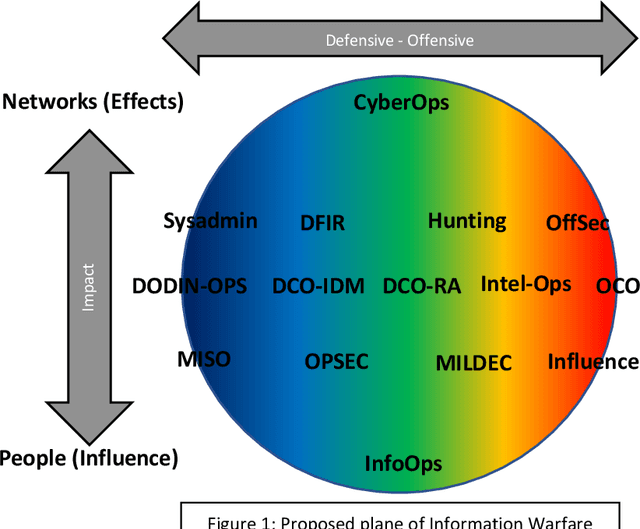


StyleGAN is the open-sourced TensorFlow implementation made by NVIDIA. It has revolutionized high quality facial image generation. However, this democratization of Artificial Intelligence / Machine Learning (AI/ML) algorithms has enabled hostile threat actors to establish cyber personas or sock-puppet accounts in social media platforms. These ultra-realistic synthetic faces. This report surveys the relevance of AI/ML with respect to Cyber & Information Operations. The proliferation of AI/ML algorithms has led to a rise in DeepFakes and inauthentic social media accounts. Threats are analyzed within the Strategic and Operational Environments. Existing methods of identifying synthetic faces exists, but they rely on human beings to visually scrutinize each photo for inconsistencies. However, through use of the DLIB 68-landmark pre-trained file, it is possible to analyze and detect synthetic faces by exploiting repetitive behaviors in StyleGAN images. Project Blade Runner encompasses two scripts necessary to counter StyleGAN images. Through PapersPlease acting as the analyzer, it is possible to derive indicators-of-attack (IOA) from scraped image samples. These IOAs can be fed back into Among_Us acting as the detector to identify synthetic faces from live operational samples. The opensource copy of Blade Runner may lack additional unit tests and some functionality, but the open-source copy is a redacted version, far leaner, better optimized, and a proof-of-concept for the information security community. The desired end-state will be to incrementally add automation to stay on-par with its closed-source predecessor.
Augmentations in Hypergraph Contrastive Learning: Fabricated and Generative
Oct 07, 2022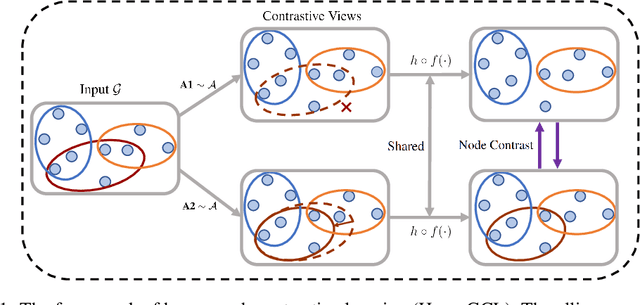

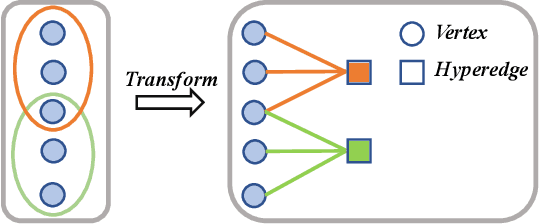

This paper targets at improving the generalizability of hypergraph neural networks in the low-label regime, through applying the contrastive learning approach from images/graphs (we refer to it as HyperGCL). We focus on the following question: How to construct contrastive views for hypergraphs via augmentations? We provide the solutions in two folds. First, guided by domain knowledge, we fabricate two schemes to augment hyperedges with higher-order relations encoded, and adopt three vertex augmentation strategies from graph-structured data. Second, in search of more effective views in a data-driven manner, we for the first time propose a hypergraph generative model to generate augmented views, and then an end-to-end differentiable pipeline to jointly learn hypergraph augmentations and model parameters. Our technical innovations are reflected in designing both fabricated and generative augmentations of hypergraphs. The experimental findings include: (i) Among fabricated augmentations in HyperGCL, augmenting hyperedges provides the most numerical gains, implying that higher-order information in structures is usually more downstream-relevant; (ii) Generative augmentations do better in preserving higher-order information to further benefit generalizability; (iii) HyperGCL also boosts robustness and fairness in hypergraph representation learning. Codes are released at https://github.com/weitianxin/HyperGCL.
Deep Learning for Rapid Landslide Detection using Synthetic Aperture Radar (SAR) Datacubes
Nov 05, 2022

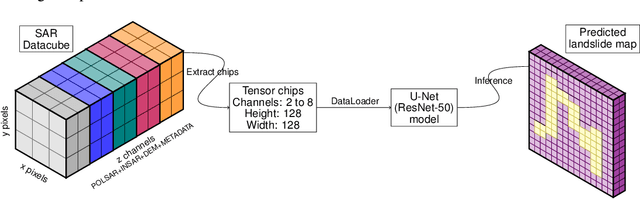
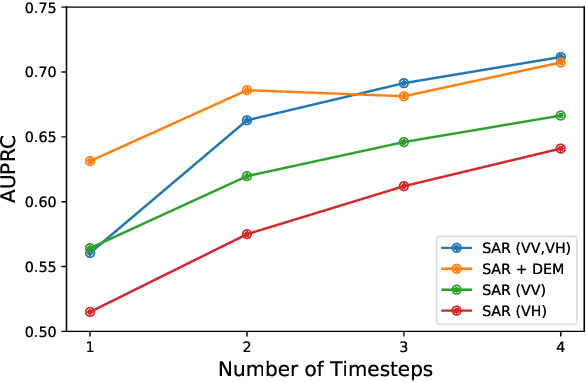
With climate change predicted to increase the likelihood of landslide events, there is a growing need for rapid landslide detection technologies that help inform emergency responses. Synthetic Aperture Radar (SAR) is a remote sensing technique that can provide measurements of affected areas independent of weather or lighting conditions. Usage of SAR, however, is hindered by domain knowledge that is necessary for the pre-processing steps and its interpretation requires expert knowledge. We provide simplified, pre-processed, machine-learning ready SAR datacubes for four globally located landslide events obtained from several Sentinel-1 satellite passes before and after a landslide triggering event together with segmentation maps of the landslides. From this dataset, using the Hokkaido, Japan datacube, we study the feasibility of SAR-based landslide detection with supervised deep learning (DL). Our results demonstrate that DL models can be used to detect landslides from SAR data, achieving an Area under the Precision-Recall curve exceeding 0.7. We find that additional satellite visits enhance detection performance, but that early detection is possible when SAR data is combined with terrain information from a digital elevation model. This can be especially useful for time-critical emergency interventions. Code is made publicly available at https://github.com/iprapas/landslide-sar-unet.
3D-GMIC: an efficient deep neural network to find small objects in large 3D images
Oct 16, 2022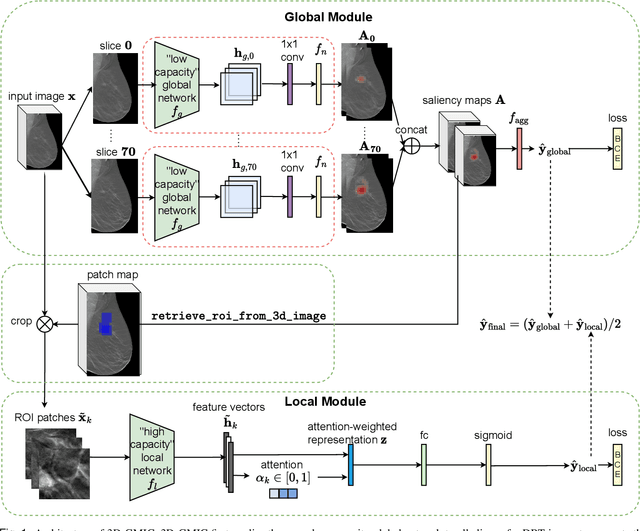
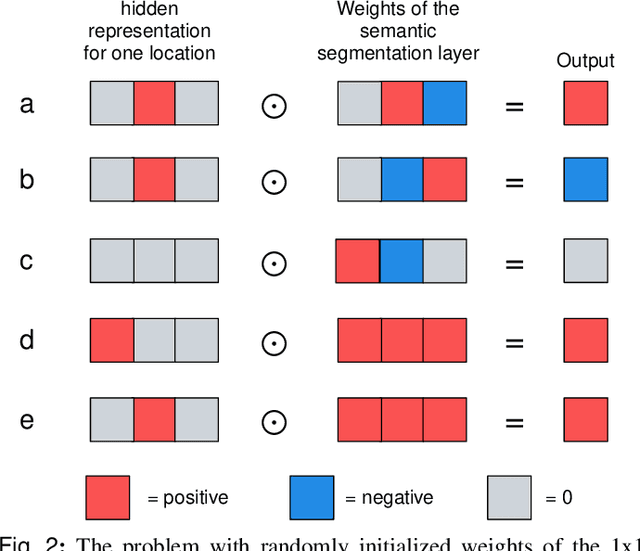
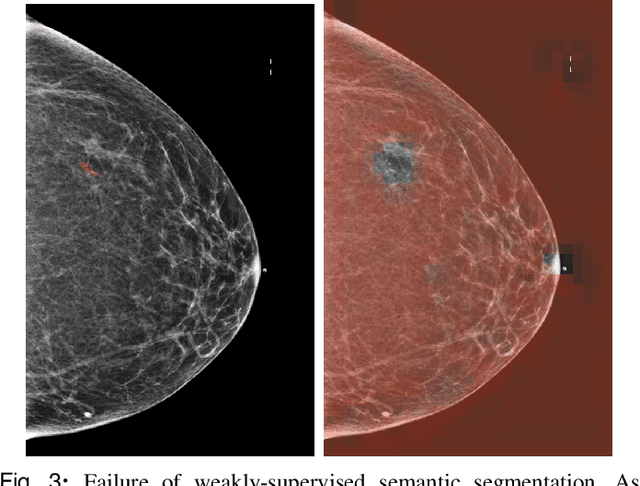
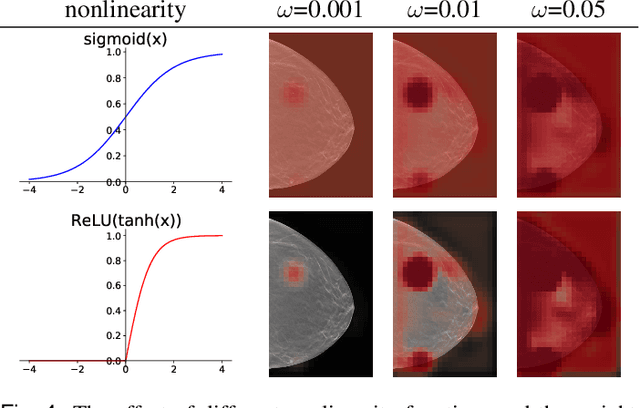
3D imaging enables a more accurate diagnosis by providing spatial information about organ anatomy. However, using 3D images to train AI models is computationally challenging because they consist of tens or hundreds of times more pixels than their 2D counterparts. To train with high-resolution 3D images, convolutional neural networks typically resort to downsampling them or projecting them to two dimensions. In this work, we propose an effective alternative, a novel neural network architecture that enables computationally efficient classification of 3D medical images in their full resolution. Compared to off-the-shelf convolutional neural networks, 3D-GMIC uses 77.98%-90.05% less GPU memory and 91.23%-96.02% less computation. While our network is trained only with image-level labels, without segmentation labels, it explains its classification predictions by providing pixel-level saliency maps. On a dataset collected at NYU Langone Health, including 85,526 patients with full-field 2D mammography (FFDM), synthetic 2D mammography, and 3D mammography (DBT), our model, the 3D Globally-Aware Multiple Instance Classifier (3D-GMIC), achieves a breast-wise AUC of 0.831 (95% CI: 0.769-0.887) in classifying breasts with malignant findings using DBT images. As DBT and 2D mammography capture different information, averaging predictions on 2D and 3D mammography together leads to a diverse ensemble with an improved breast-wise AUC of 0.841 (95% CI: 0.768-0.895). Our model generalizes well to an external dataset from Duke University Hospital, achieving an image-wise AUC of 0.848 (95% CI: 0.798-0.896) in classifying DBT images with malignant findings.
A Framework to Evaluate Independent Component Analysis applied to EEG signal: testing on the Picard algorithm
Oct 16, 2022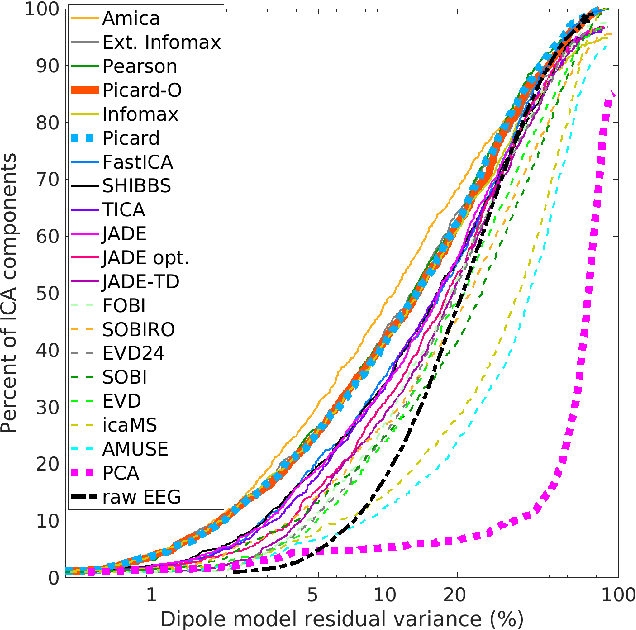
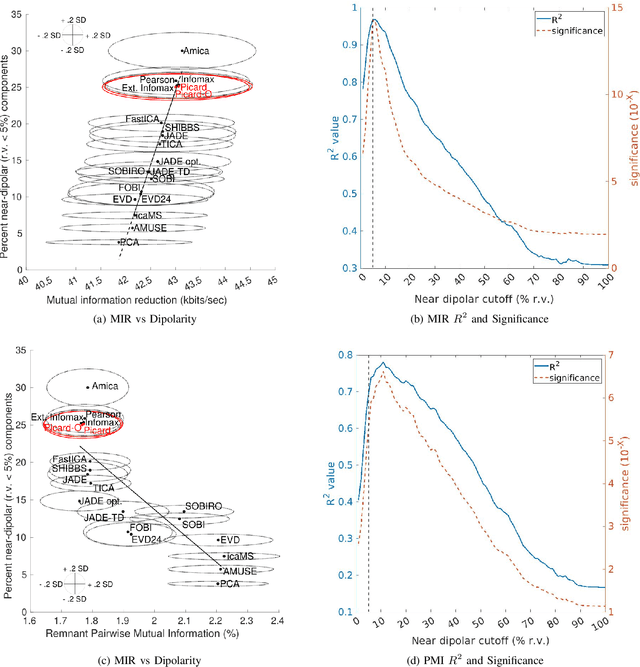
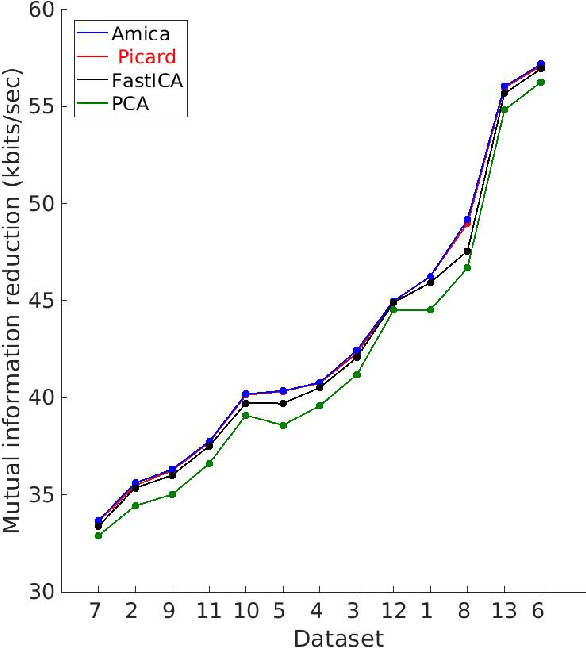
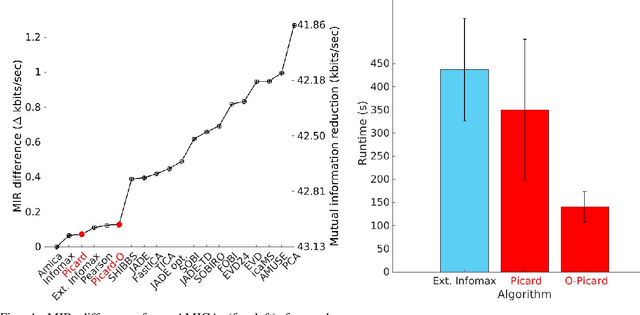
Independent component analysis (ICA), is a blind source separation method that is becoming increasingly used to separate brain and non-brain related activities in electroencephalographic (EEG) and other electrophysiological recordings. It can be used to extract effective brain source activities and estimate their cortical source areas, and is commonly used in machine learning applications to classify EEG artifacts. Previously, we compared results of decomposing 13 71-channel scalp EEG datasets using 22 ICA and other blind source separation (BSS) algorithms. We are now making this framework available to the scientific community and, in the process of its release are testing a recent ICA algorithm (Picard) not included in the previous assay. Our test framework uses three main metrics to assess BSS performance: Pairwise Mutual Information (PMI) between scalp channel pairs; PMI remaining between component pairs after decomposition; and, the complete (not pairwise) Mutual Information Reduction (MIR) produced by each algorithm. We also measure the "dipolarity" of the scalp projection maps for the decomposed component, defined by the number of components whose scalp projection maps nearly match the projection of a single equivalent dipole. Within this framework, Picard performed similarly to Infomax ICA. This is not surprising since Picard is a type of Infomax algorithm that uses the L-BFGS method for faster convergence, in contrast to Infomax and Extended Infomax (runica) which use gradient descent. Our results show that Picard performs similarly to Infomax and, likewise, better than other BSS algorithms, excepting the more computationally complex AMICA. We have released the source code of our framework and the test data through GitHub.
Preventing Verbatim Memorization in Language Models Gives a False Sense of Privacy
Oct 31, 2022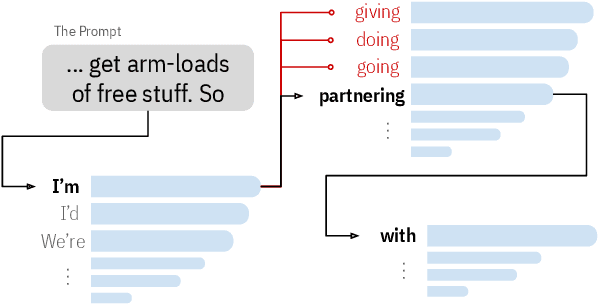
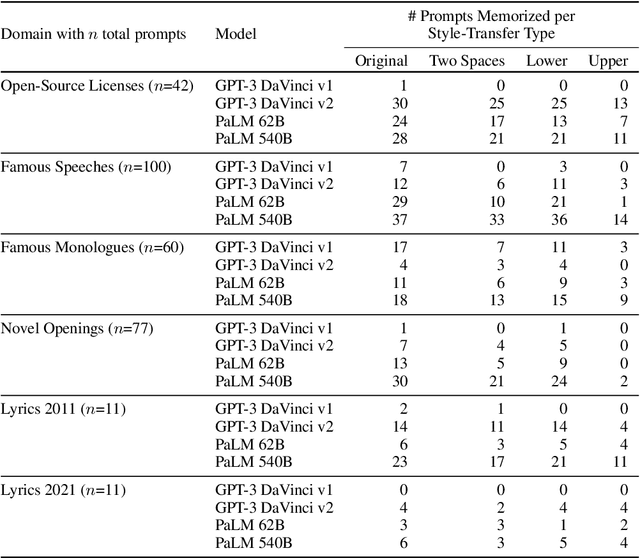

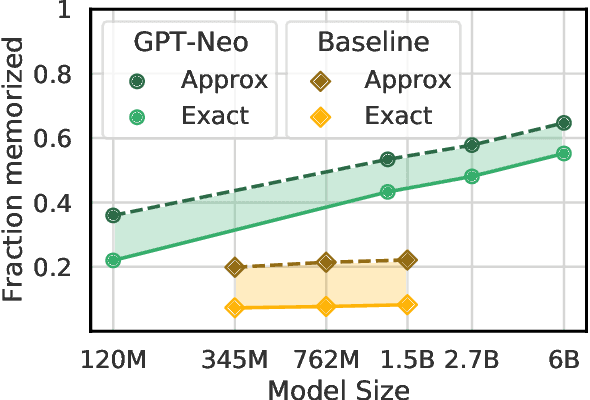
Studying data memorization in neural language models helps us understand the risks (e.g., to privacy or copyright) associated with models regurgitating training data, and aids in the evaluation of potential countermeasures. Many prior works -- and some recently deployed defenses -- focus on "verbatim memorization", defined as a model generation that exactly matches a substring from the training set. We argue that verbatim memorization definitions are too restrictive and fail to capture more subtle forms of memorization. Specifically, we design and implement an efficient defense based on Bloom filters that perfectly prevents all verbatim memorization. And yet, we demonstrate that this "perfect" filter does not prevent the leakage of training data. Indeed, it is easily circumvented by plausible and minimally modified "style-transfer" prompts -- and in some cases even the non-modified original prompts -- to extract memorized information. For example, instructing the model to output ALL-CAPITAL texts bypasses memorization checks based on verbatim matching. We conclude by discussing potential alternative definitions and why defining memorization is a difficult yet crucial open question for neural language models.
Lightweight Neural Network with Knowledge Distillation for CSI Feedback
Oct 31, 2022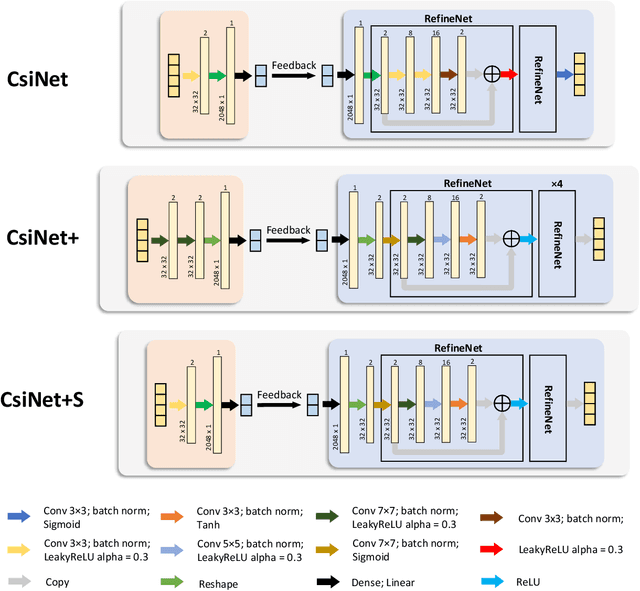
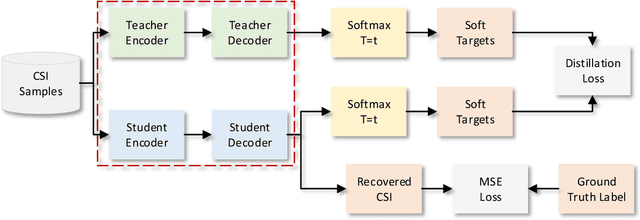
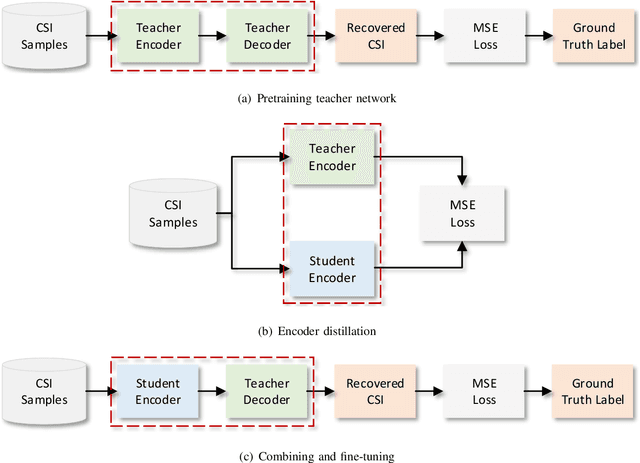
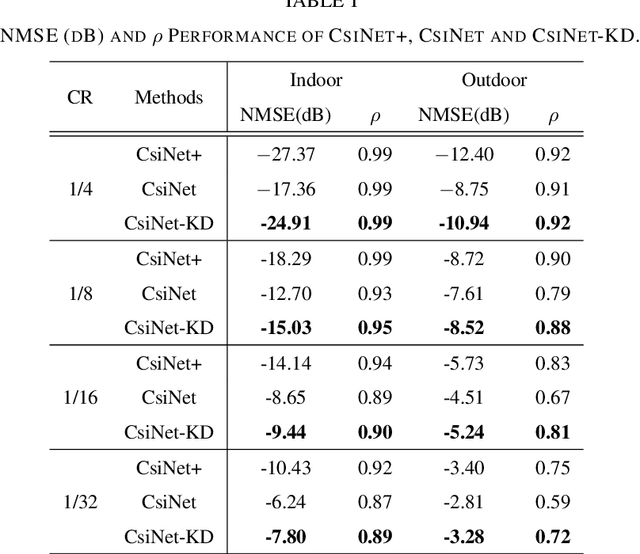
Deep learning-based autoencoder has shown considerable potential in channel state information (CSI) feedback. However, the excellent feedback performance achieved by autoencoder is at the expense of a high computational complexity. In this paper, a knowledge distillation-based neural network lightweight strategy is introduced to deep learning-based CSI feedback to reduce the computational requirement. The key idea is to transfer the dark knowledge learned by a complicated teacher network to a lightweight student network, thereby improving the performance of the student network. First, an autoencoder distillation method is proposed by forcing the student autoencoder to mimic the output of the teacher autoencoder. Then, given the more limited computational power at the user equipment, an encoder distillation method is proposed where distillation is only performed to student encoder at the user equipment and the teacher decoder is directly used at the base stataion. The numerical simulation results show that the performance of student autoencoder can be considerably improved after knowledge distillation and encoder distillation can further improve the feedback performance and reduce the complexity.
Point Cloud Quality Assessment using 3D Saliency Maps
Sep 30, 2022Point cloud quality assessment (PCQA) has become an appealing research field in recent days. Considering the importance of saliency detection in quality assessment, we propose an effective full-reference PCQA metric which makes the first attempt to utilize the saliency information to facilitate quality prediction, called point cloud quality assessment using 3D saliency maps (PQSM). Specifically, we first propose a projection-based point cloud saliency map generation method, in which depth information is introduced to better reflect the geometric characteristics of point clouds. Then, we construct point cloud local neighborhoods to derive three structural descriptors to indicate the geometry, color and saliency discrepancies. Finally, a saliency-based pooling strategy is proposed to generate the final quality score. Extensive experiments are performed on four independent PCQA databases. The results demonstrate that the proposed PQSM shows competitive performances compared to multiple state-of-the-art PCQA metrics.
Visual Privacy Protection Based on Type-I Adversarial Attack
Sep 30, 2022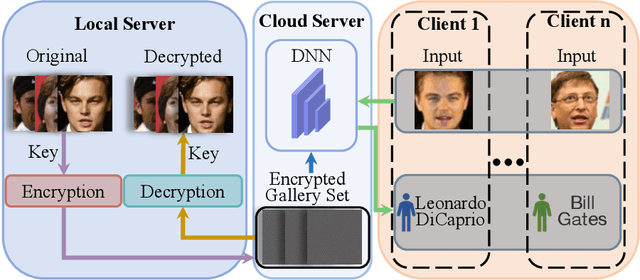
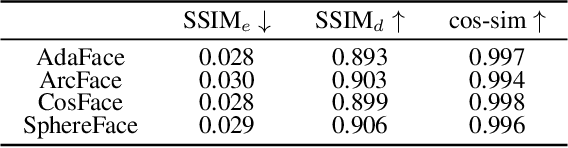
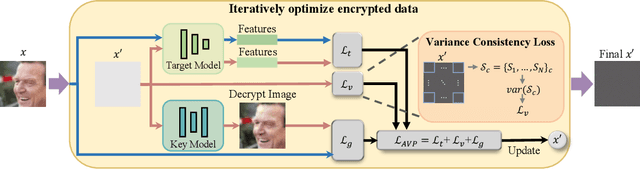
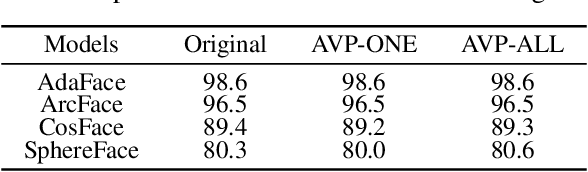
With the development of online artificial intelligence systems, many deep neural networks (DNNs) have been deployed in cloud environments. In practical applications, developers or users need to provide their private data to DNNs, such as faces. However, data transmitted and stored in the cloud is insecure and at risk of privacy leakage. In this work, inspired by Type-I adversarial attack, we propose an adversarial attack-based method to protect visual privacy of data. Specifically, the method encrypts the visual information of private data while maintaining them correctly predicted by DNNs, without modifying the model parameters. The empirical results on face recognition tasks show that the proposed method can deeply hide the visual information in face images and hardly affect the accuracy of the recognition models. In addition, we further extend the method to classification tasks and also achieve state-of-the-art performance.