 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePinCLIP: Large-scale Foundational Multimodal Representation at Pinterest
Mar 03, 2026While multi-modal Visual Language Models (VLMs) have demonstrated significant success across various domains, the integration of VLMs into recommendation and retrieval systems remains a challenge, due to issues like training objective discrepancies and serving efficiency bottlenecks. This paper introduces PinCLIP, a large-scale visual representation learning approach developed to enhance retrieval and ranking models at Pinterest by leveraging VLMs to learn image-text alignment. We propose a novel hybrid Vision Transformer architecture that utilizes a VLM backbone and a hybrid fusion mechanism to capture multi-modality content representation at varying granularities. Beyond standard image-to-text alignment objectives, we introduce a neighbor alignment objective to model the cross-fusion of multi-modal representations within the Pinterest Pin-Board graph. Offline evaluations show that PinCLIP outperforms state-of-the-art baselines, such as Qwen, by 20% in multi-modal retrieval tasks. Online A/B testing demonstrates significant business impact, including substantial engagement gains across all major surfaces in Pinterest. Notably, PinCLIP significantly addresses the "cold-start" problem, enhancing fresh content distribution with a 15% Repin increase in organic content and 8.7% higher click for new Ads.
Closer Look at Efficient Inference Methods: A Survey of Speculative Decoding
Nov 20, 2024


Efficient inference in large language models (LLMs) has become a critical focus as their scale and complexity grow. Traditional autoregressive decoding, while effective, suffers from computational inefficiencies due to its sequential token generation process. Speculative decoding addresses this bottleneck by introducing a two-stage framework: drafting and verification. A smaller, efficient model generates a preliminary draft, which is then refined by a larger, more sophisticated model. This paper provides a comprehensive survey of speculative decoding methods, categorizing them into draft-centric and model-centric approaches. We discuss key ideas associated with each method, highlighting their potential for scaling LLM inference. This survey aims to guide future research in optimizing speculative decoding and its integration into real-world LLM applications.
3D-GMIC: an efficient deep neural network to find small objects in large 3D images
Oct 16, 2022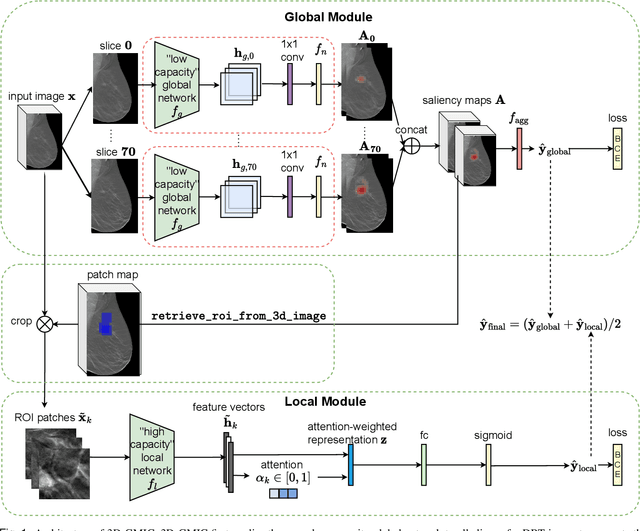
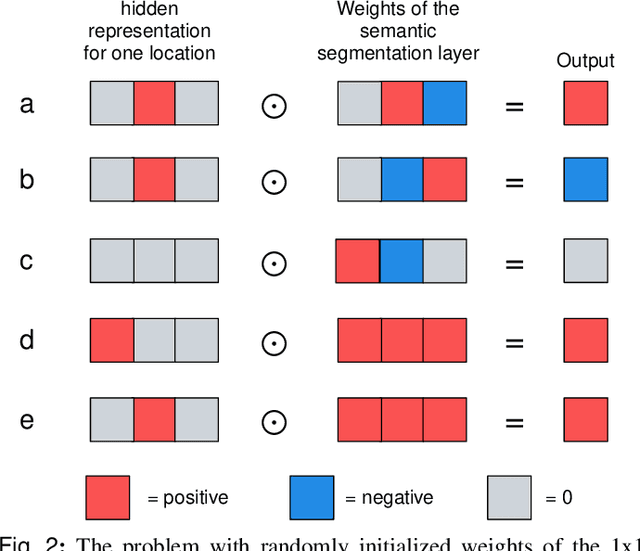
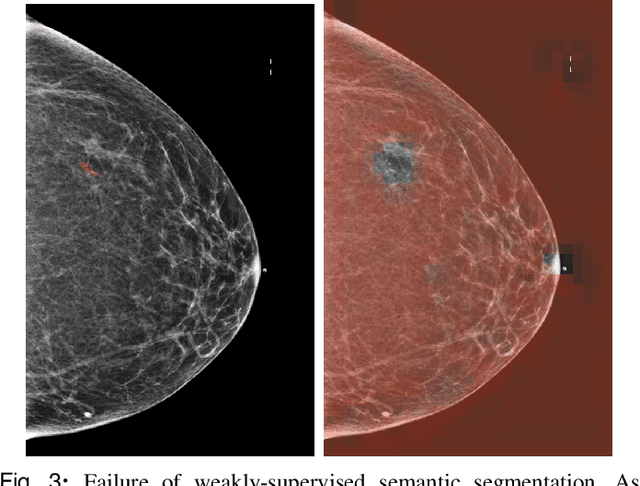
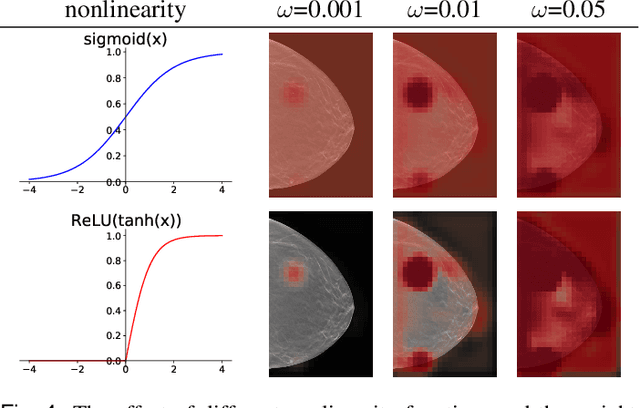
3D imaging enables a more accurate diagnosis by providing spatial information about organ anatomy. However, using 3D images to train AI models is computationally challenging because they consist of tens or hundreds of times more pixels than their 2D counterparts. To train with high-resolution 3D images, convolutional neural networks typically resort to downsampling them or projecting them to two dimensions. In this work, we propose an effective alternative, a novel neural network architecture that enables computationally efficient classification of 3D medical images in their full resolution. Compared to off-the-shelf convolutional neural networks, 3D-GMIC uses 77.98%-90.05% less GPU memory and 91.23%-96.02% less computation. While our network is trained only with image-level labels, without segmentation labels, it explains its classification predictions by providing pixel-level saliency maps. On a dataset collected at NYU Langone Health, including 85,526 patients with full-field 2D mammography (FFDM), synthetic 2D mammography, and 3D mammography (DBT), our model, the 3D Globally-Aware Multiple Instance Classifier (3D-GMIC), achieves a breast-wise AUC of 0.831 (95% CI: 0.769-0.887) in classifying breasts with malignant findings using DBT images. As DBT and 2D mammography capture different information, averaging predictions on 2D and 3D mammography together leads to a diverse ensemble with an improved breast-wise AUC of 0.841 (95% CI: 0.768-0.895). Our model generalizes well to an external dataset from Duke University Hospital, achieving an image-wise AUC of 0.848 (95% CI: 0.798-0.896) in classifying DBT images with malignant findings.
MultiBiSage: A Web-Scale Recommendation System Using Multiple Bipartite Graphs at Pinterest
May 21, 2022

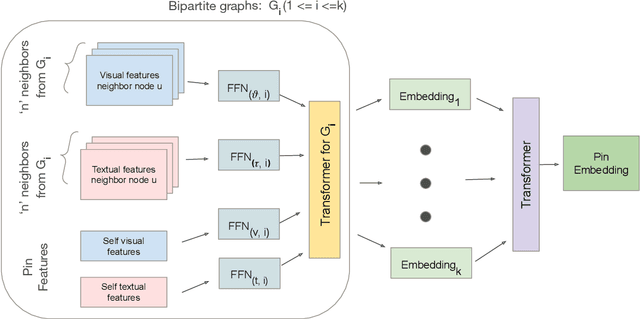
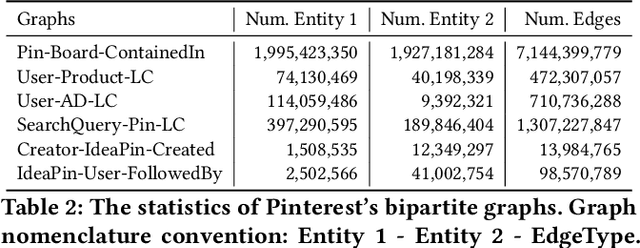
Graph Convolutional Networks (GCN) can efficiently integrate graph structure and node features to learn high-quality node embeddings. These embeddings can then be used for several tasks such as recommendation and search. At Pinterest, we have developed and deployed PinSage, a data-efficient GCN that learns pin embeddings from the Pin-Board graph. The Pin-Board graph contains pin and board entities and the graph captures the pin belongs to a board interaction. However, there exist several entities at Pinterest such as users, idea pins, creators, and there exist heterogeneous interactions among these entities such as add-to-cart, follow, long-click. In this work, we show that training deep learning models on graphs that captures these diverse interactions would result in learning higher-quality pin embeddings than training PinSage on only the Pin-Board graph. To that end, we model the diverse entities and their diverse interactions through multiple bipartite graphs and propose a novel data-efficient MultiBiSage model. MultiBiSage can capture the graph structure of multiple bipartite graphs to learn high-quality pin embeddings. We take this pragmatic approach as it allows us to utilize the existing infrastructure developed at Pinterest -- such as Pixie system that can perform optimized random-walks on billion node graphs, along with existing training and deployment workflows. We train MultiBiSage on six bipartite graphs including our Pin-Board graph. Our offline metrics show that MultiBiSage significantly outperforms the deployed latest version of PinSage on multiple user engagement metrics.
CausalX: Causal Explanations and Block Multilinear Factor Analysis
Feb 27, 2021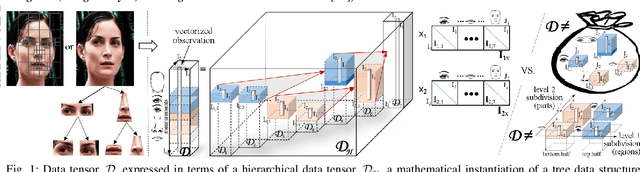
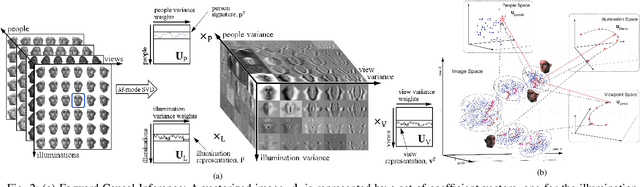
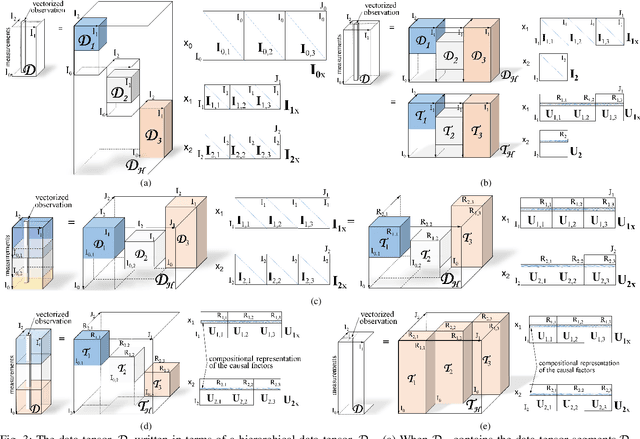
By adhering to the dictum, "No causation without manipulation (treatment, intervention)", cause and effect data analysis represents changes in observed data in terms of changes in the causal factors. When causal factors are not amenable for active manipulation in the real world due to current technological limitations or ethical considerations, a counterfactual approach performs an intervention on the model of data formation. In the case of object representation or activity (temporal object) representation, varying object parts is generally unfeasible whether they be spatial and/or temporal. Multilinear algebra, the algebra of higher-order tensors, is a suitable and transparent framework for disentangling the causal factors of data formation. Learning a part-based intrinsic causal factor representations in a multilinear framework requires applying a set of interventions on a part-based multilinear model. We propose a unified multilinear model of wholes and parts. We derive a hierarchical block multilinear factorization, the M-mode Block SVD, that computes a disentangled representation of the causal factors by optimizing simultaneously across the entire object hierarchy. Given computational efficiency considerations, we introduce an incremental bottom-up computational alternative, the Incremental M-mode Block SVD, that employs the lower-level abstractions, the part representations, to represent the higher level of abstractions, the parent wholes. This incremental computational approach may also be employed to update the causal model parameters when data becomes available incrementally. The resulting object representation is an interpretable combinatorial choice of intrinsic causal factor representations related to an object's recursive hierarchy of wholes and parts that renders object recognition robust to occlusion and reduces training data requirements.
* arXiv admin note: text overlap with arXiv:1911.04180
Toward Transformer-Based Object Detection
Dec 17, 2020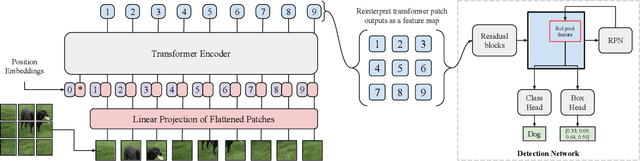
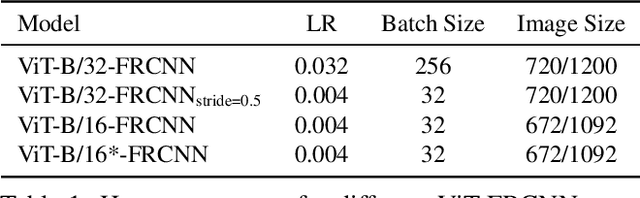
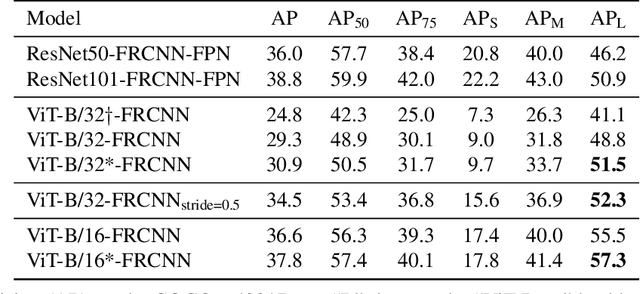
Transformers have become the dominant model in natural language processing, owing to their ability to pretrain on massive amounts of data, then transfer to smaller, more specific tasks via fine-tuning. The Vision Transformer was the first major attempt to apply a pure transformer model directly to images as input, demonstrating that as compared to convolutional networks, transformer-based architectures can achieve competitive results on benchmark classification tasks. However, the computational complexity of the attention operator means that we are limited to low-resolution inputs. For more complex tasks such as detection or segmentation, maintaining a high input resolution is crucial to ensure that models can properly identify and reflect fine details in their output. This naturally raises the question of whether or not transformer-based architectures such as the Vision Transformer are capable of performing tasks other than classification. In this paper, we determine that Vision Transformers can be used as a backbone by a common detection task head to produce competitive COCO results. The model that we propose, ViT-FRCNN, demonstrates several known properties associated with transformers, including large pretraining capacity and fast fine-tuning performance. We also investigate improvements over a standard detection backbone, including superior performance on out-of-domain images, better performance on large objects, and a lessened reliance on non-maximum suppression. We view ViT-FRCNN as an important stepping stone toward a pure-transformer solution of complex vision tasks such as object detection.
Differences between human and machine perception in medical diagnosis
Nov 28, 2020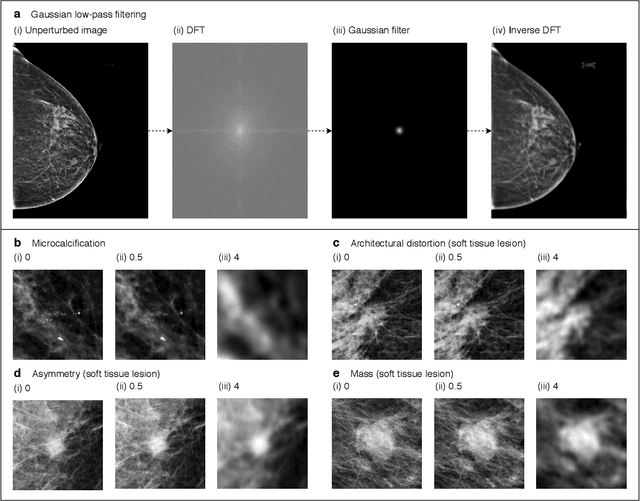
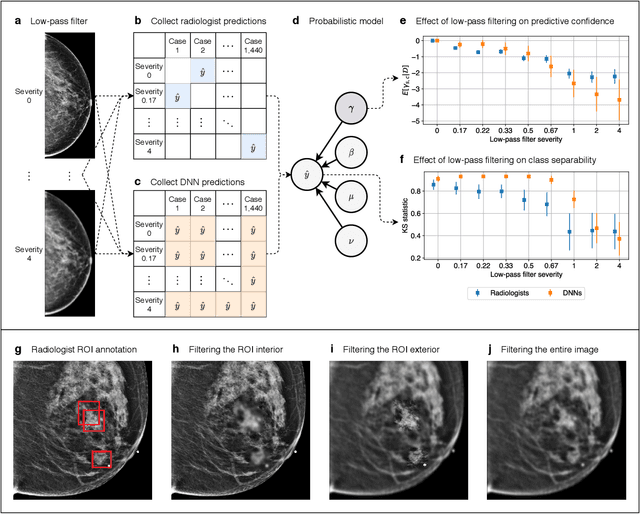
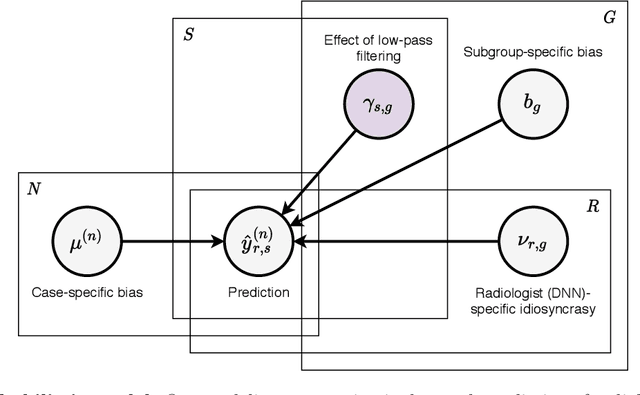
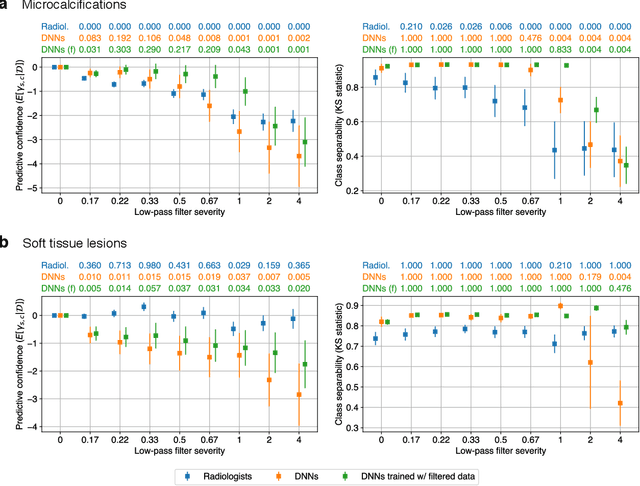
Deep neural networks (DNNs) show promise in image-based medical diagnosis, but cannot be fully trusted since their performance can be severely degraded by dataset shifts to which human perception remains invariant. If we can better understand the differences between human and machine perception, we can potentially characterize and mitigate this effect. We therefore propose a framework for comparing human and machine perception in medical diagnosis. The two are compared with respect to their sensitivity to the removal of clinically meaningful information, and to the regions of an image deemed most suspicious. Drawing inspiration from the natural image domain, we frame both comparisons in terms of perturbation robustness. The novelty of our framework is that separate analyses are performed for subgroups with clinically meaningful differences. We argue that this is necessary in order to avert Simpson's paradox and draw correct conclusions. We demonstrate our framework with a case study in breast cancer screening, and reveal significant differences between radiologists and DNNs. We compare the two with respect to their robustness to Gaussian low-pass filtering, performing a subgroup analysis on microcalcifications and soft tissue lesions. For microcalcifications, DNNs use a separate set of high frequency components than radiologists, some of which lie outside the image regions considered most suspicious by radiologists. These features run the risk of being spurious, but if not, could represent potential new biomarkers. For soft tissue lesions, the divergence between radiologists and DNNs is even starker, with DNNs relying heavily on spurious high frequency components ignored by radiologists. Importantly, this deviation in soft tissue lesions was only observable through subgroup analysis, which highlights the importance of incorporating medical domain knowledge into our comparison framework.
Bootstrapping Complete The Look at Pinterest
Jun 29, 2020
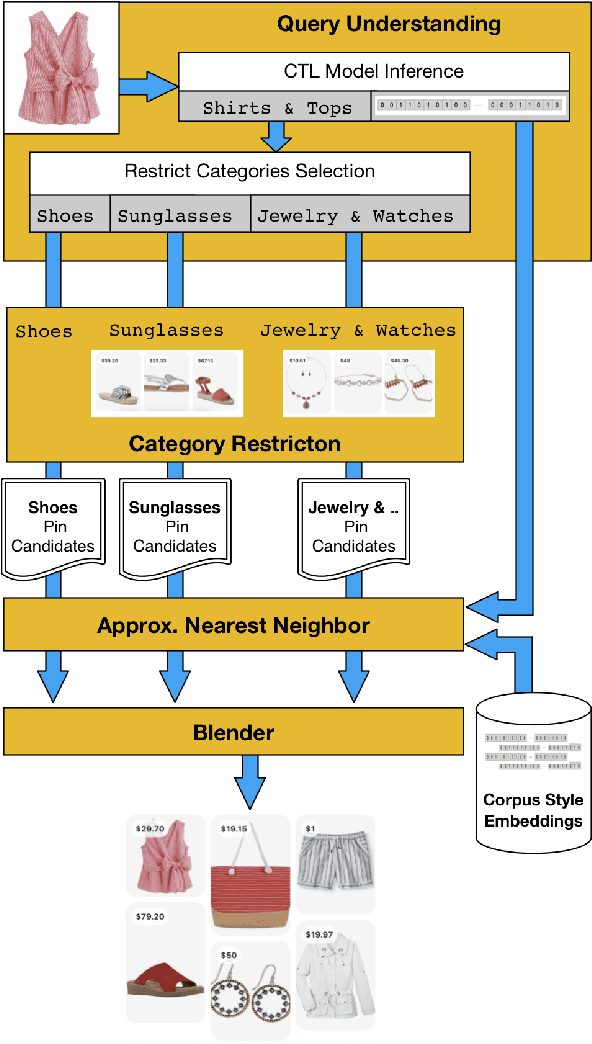
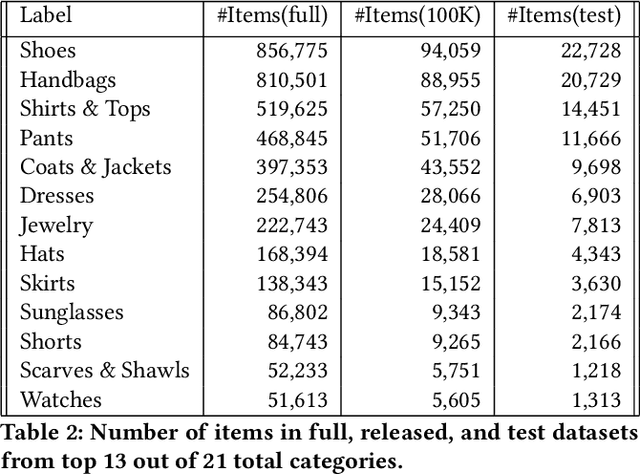
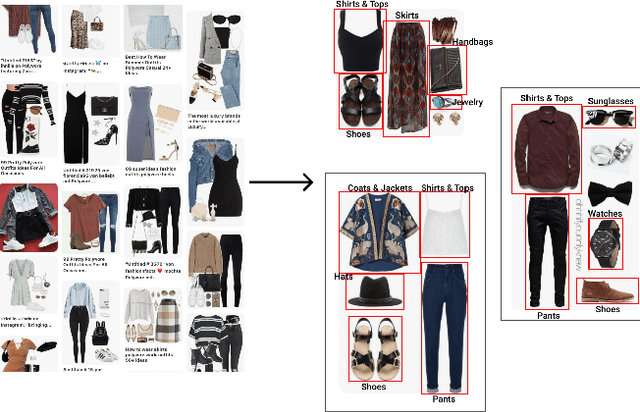
Putting together an ideal outfit is a process that involves creativity and style intuition. This makes it a particularly difficult task to automate. Existing styling products generally involve human specialists and a highly curated set of fashion items. In this paper, we will describe how we bootstrapped the Complete The Look (CTL) system at Pinterest. This is a technology that aims to learn the subjective task of "style compatibility" in order to recommend complementary items that complete an outfit. In particular, we want to show recommendations from other categories that are compatible with an item of interest. For example, what are some heels that go well with this cocktail dress? We will introduce our outfit dataset of over 1 million outfits and 4 million objects, a subset of which we will make available to the research community, and describe the pipeline used to obtain and refresh this dataset. Furthermore, we will describe how we evaluate this subjective task and compare model performance across multiple training methods. Lastly, we will share our lessons going from experimentation to working prototype, and how to mitigate failure modes in the production environment. Our work represents one of the first examples of an industrial-scale solution for compatibility-based fashion recommendation.
Shop The Look: Building a Large Scale Visual Shopping System at Pinterest
Jun 18, 2020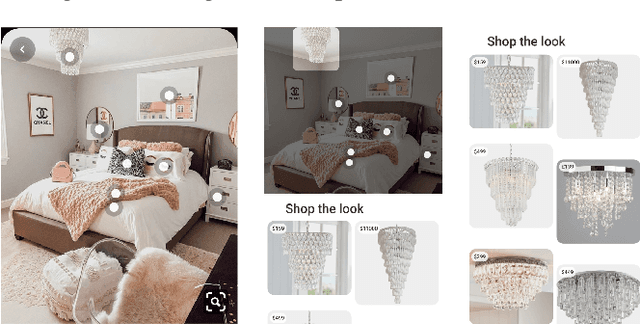

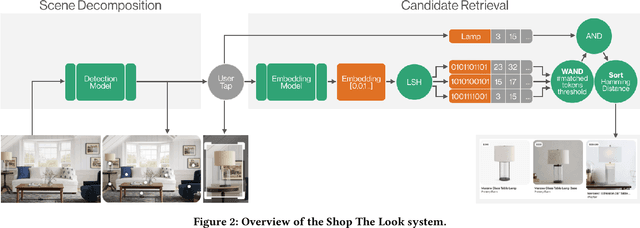
As online content becomes ever more visual, the demand for searching by visual queries grows correspondingly stronger. Shop The Look is an online shopping discovery service at Pinterest, leveraging visual search to enable users to find and buy products within an image. In this work, we provide a holistic view of how we built Shop The Look, a shopping oriented visual search system, along with lessons learned from addressing shopping needs. We discuss topics including core technology across object detection and visual embeddings, serving infrastructure for realtime inference, and data labeling methodology for training/evaluation data collection and human evaluation. The user-facing impacts of our system design choices are measured through offline evaluations, human relevance judgements, and online A/B experiments. The collective improvements amount to cumulative relative gains of over 160% in end-to-end human relevance judgements and over 80% in engagement. Shop The Look is deployed in production at Pinterest.
Deep Neural Networks Improve Radiologists' Performance in Breast Cancer Screening
Mar 20, 2019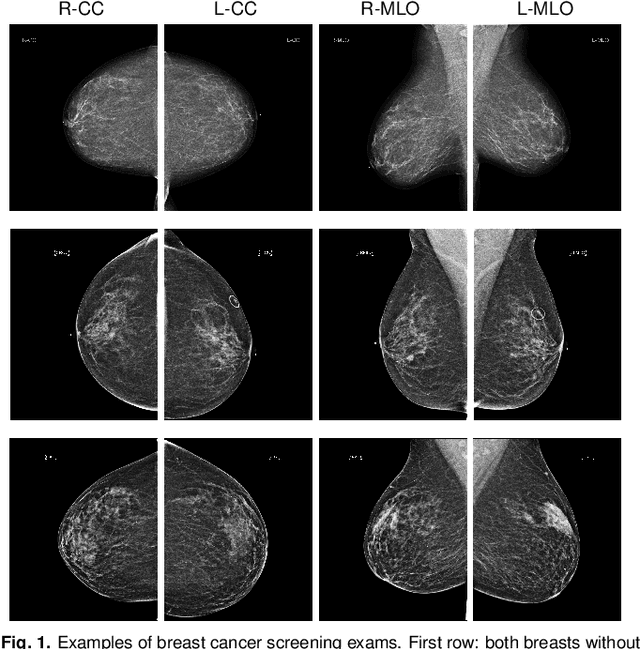
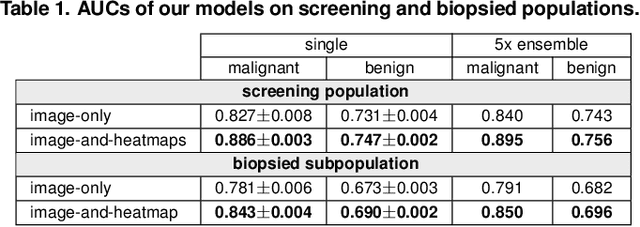
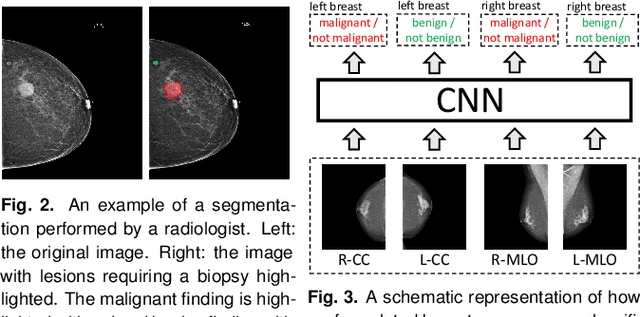
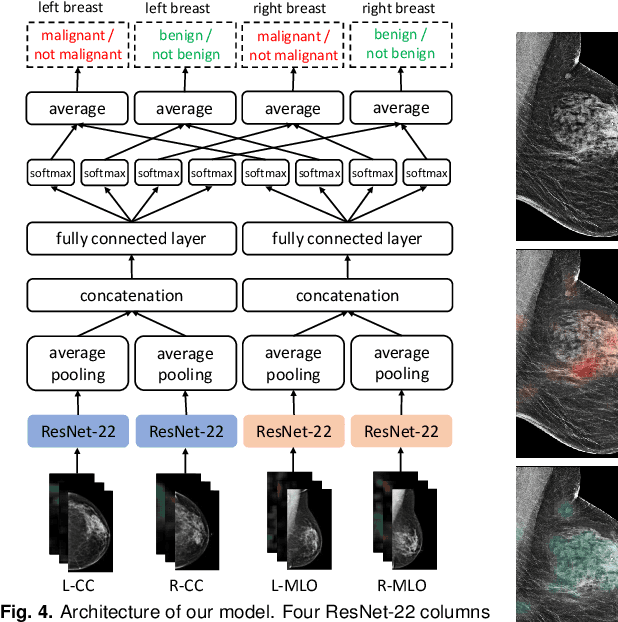
We present a deep convolutional neural network for breast cancer screening exam classification, trained and evaluated on over 200,000 exams (over 1,000,000 images). Our network achieves an AUC of 0.895 in predicting whether there is a cancer in the breast, when tested on the screening population. We attribute the high accuracy of our model to a two-stage training procedure, which allows us to use a very high-capacity patch-level network to learn from pixel-level labels alongside a network learning from macroscopic breast-level labels. To validate our model, we conducted a reader study with 14 readers, each reading 720 screening mammogram exams, and find our model to be as accurate as experienced radiologists when presented with the same data. Finally, we show that a hybrid model, averaging probability of malignancy predicted by a radiologist with a prediction of our neural network, is more accurate than either of the two separately. To better understand our results, we conduct a thorough analysis of our network's performance on different subpopulations of the screening population, model design, training procedure, errors, and properties of its internal representations.