 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntention-Aware Semantic Agent Communications for AI Glasses
Apr 26, 2026Smart glasses are emerging as a promising interface between humans and artificial intelligence (AI) agents, enabling first-person perception, contextual awareness, and real-time assistance. However, continuous offloading of visual data from wearable devices to cloud-based vision-language models (VLMs) is fundamentally constrained by limited wireless bandwidth and energy resources. This paper proposes an intention-aware semantic agent communication framework for AI glasses, where data transmission is guided by user intention rather than raw pixel fidelity. In the proposed architecture, AI glasses act as an edge semantic agent while a server-side VLM executes high-level cognition and reasoning. The user intention can be inferred by the server-side VLM through the current transmitted content and the historical prompts. Driven by specific user intentions, the glasses adaptively preserve textual content, document layout, or object semantics before transmission. We evaluate three representative scenarios with different lightweight preprocessing tools on the AI glasses. Simulation results demonstrate that intention-aware preprocessing significantly achieves more than 50% bandwidth reduction depending on the current task while maintaining task performance. Moreover, semantic transmission exhibits graceful degradation under low SNRs. The findings demonstrate that aligning communication resources with user intention is essential for robust and efficient wearable AI agent systems.
AgentComm: Semantic Communication for Embodied Agents
Apr 15, 2026The increasing deployment of agentic artificial intelligence (AI) systems has intensified the demand for efficient agent to agent communication, particularly over bandwidth limited wireless links. In embodied AI applications, agents must exchange task related information under strict latency and reliability constraints. Existing agent communication methods primarily focus on connectivity and protocol efficiency, but lack effective mechanisms to reduce physical layer transmission overhead while preserving task semantics.To address this challenge, this paper proposes a semantic agent communication framework that reduces communication overhead while maintaining task performance and shared understanding among agents. An LLM based semantic processor is first introduced to reorganize and condense agent generated messages by extracting task relevant semantic content. To cope with information loss introduced by aggressive message reduction, an importance-aware semantic transmission strategy is developed, which adaptively protects semantic components according to their task importance. Furthermore, a task specific knowledge base is incorporated as long term semantic memory to support recurring tasks and further reduce bandwidth consumption with minimal performance degradation. Experimental results and ablation studies demonstrate that the proposed framework achieves nearly 50% bandwidth reduction with negligible loss in task completion performance compared to conventional transmission schemes.
Multimodal-NF: A Wireless Dataset for Near-Field Low-Altitude Sensing and Communications
Mar 30, 2026Environment-aware 6G wireless networks demand the deep integration of multimodal and wireless data. However, most existing datasets are confined to 2D terrestrial far-field scenarios, lacking the 3D spatial context and near-field characteristics crucial for low-altitude extremely large-scale multiple-input multiple-output (XL-MIMO) systems. To bridge this gap, this letter introduces Multimodal-NF, a large-scale dataset and specialized generation framework. Operating in the upper midband, it synchronizes high-fidelity near-field channel state information (CSI) and precise wireless labels (e.g., Top-5 beam indices, LoS/NLoS) with comprehensive sensory modalities (RGB images, LiDAR point clouds, and GPS). Crucially, these multimodal priors provide spatial semantics that help reduce the near-field search space and thereby lower the overhead of wireless sensing and communication tasks. Finally, we validate the dataset through representative case studies, demonstrating its utility and effectiveness. The open-source generator and dataset are available at https://lmyxxn.github.io/6GXLMIMODatasets/.
Semantic Satellite Communications for Synchronized Audiovisual Reconstruction
Mar 11, 2026Satellite communications face severe bottlenecks in supporting high-fidelity synchronized audiovisual services, as conventional schemes struggle with cross-modal coherence under fluctuating channel conditions, limited bandwidth, and long propagation delays. To address these limitations, this paper proposes an adaptive multimodal semantic transmission system tailored for satellite scenarios, aiming for high-quality synchronized audiovisual reconstruction under bandwidth constraints. Unlike static schemes with fixed modal priorities, our framework features a dual-stream generative architecture that flexibly switches between video-driven audio generation and audio-driven video generation. This allows the system to dynamically decouple semantics, transmitting only the most important modality while employing cross-modal generation to recover the other. To balance reconstruction quality and transmission overhead, a dynamic keyframe update mechanism adaptively maintains the shared knowledge base according to wireless scenarios and user requirements. Furthermore, a large language model based decision module is introduced to enhance system adaptability. By integrating satellite-specific knowledge, this module jointly considers task requirements and channel factors such as weather-induced fading to proactively adjust transmission paths and generation workflows. Simulation results demonstrate that the proposed system significantly reduces bandwidth consumption while achieving high-fidelity audiovisual synchronization, improving transmission efficiency and robustness in challenging satellite scenarios.
Deep Learning-based Low-Overhead Beam Alignment for mmWave Massive MIMO Systems
Feb 25, 2026Millimeter-wave massive multiple-input multiple-output systems employ highly directional beamforming to overcome severe path loss, and their performance critically depends on accurate beam alignment. Conventional codebook-based methods offer low training overhead but suffer from limited angular resolution and sensitivity to hardware impairments. To address these challenges, we propose a deep learning-enhanced super-resolution beam alignment framework with three key components. First, we design the Quaternary Search-based Super-Resolution (QSSR) algorithm, which leverages the monotonic power ratio property between two discrete Fourier transform (DFT) codebook beams to achieve super-resolution angle estimation without increasing measurement complexity relative to binary search. Second, we develop QSSR-Net, a gated recurrent unit-based neural network that exploits sequential multi-layer beam measurements to capture angular dependencies, thereby improving estimation accuracy, robustness to noise, and generalization across diverse propagation environments. Third, to mitigate the adverse effects of hardware impairments such as antenna position and phase errors, we propose a parametric self-calibration method that requires no additional hardware overhead and adapts compensation parameters in real time. Simulation results show that the proposed framework consistently outperforms binary search and even exhaustive search at high signal-to-noise ratios, achieving substantial performance gains while maintaining low overhead.
Active RIS-Assisted MIMO System for Vital Signs Extraction: ISAC Modeling, Deep Learning, and Prototype Measurements
Feb 18, 2026We present the RIS-VSign system, an active reconfigurable intelligent surface (RIS)-assisted multiple-input multiple-output orthogonal frequency division multiplexing (MIMO-OFDM) framework for vital signs extraction under an integrated sensing and communication (ISAC) model. The system consists of two stages: the phase selector of RIS and the extraction of respiration rate. To mitigate synchronization-induced common phase drifts, the difference of Möbius transformation (DMT) is integrated into the deep learning framework, named DMTNet, to jointly configure multiple active RIS elements. Notably, the training data are generated in simulation without collecting real-world measurements, and the resulting phase selector is validated experimentally. For sensing, multi-antenna measurements are fused by the DC-offset calibration and the DeepMining-MMV processing with CA-CFAR detection and Newton's refinements. Prototype experiments indicate that active RIS deployment improves respiration detectability while simultaneously enabling higher-order modulation; without RIS, respiration detection is unreliable and only lower-order modulation is supported.
FPNet: Joint Wi-Fi Beamforming Matrix Feedback and Anomaly-Aware Indoor Positioning
Feb 13, 2026Channel State Information (CSI) provides a detailed description of the wireless channel and has been widely adopted for Wi-Fi sensing, particularly for high-precision indoor positioning. However, complete CSI is rarely available in real-world deployments due to hardware constraints and the high communication overhead required for feedback. Moreover, existing positioning models lack mechanisms to detect when users move outside their trained regions, leading to unreliable estimates in dynamic environments. In this paper, we present FPNet, a unified deep learning framework that jointly addresses channel feedback compression, accurate indoor positioning, and robust anomaly detection (AD). FPNet leverages the beamforming feedback matrix (BFM), a compressed CSI representation natively supported by IEEE 802.11ac/ax/be protocols, to minimize feedback overhead while preserving critical positioning features. To enhance reliability, we integrate ADBlock, a lightweight AD module trained on normal BFM samples, which identifies out-of-distribution scenarios when users exit predefined spatial regions. Experimental results using standard 2.4 GHz Wi-Fi hardware show that FPNet achieves positioning accuracy above 97% with only 100 feedback bits, boosts net throughput by up to 22.92%, and attains AD accuracy over 99% with a false alarm rate below 1.5%. These results demonstrate FPNet's ability to deliver efficient, accurate, and reliable indoor positioning on commodity Wi-Fi devices.
AI-Driven Subcarrier-Level CQI Feedback
Dec 22, 2025The Channel Quality Indicator (CQI) is a fundamental component of channel state information (CSI) that enables adaptive modulation and coding by selecting the optimal modulation and coding scheme to meet a target block error rate. While AI-enabled CSI feedback has achieved significant advances, especially in precoding matrix index feedback, AI-based CQI feedback remains underexplored. Conventional subband-based CQI approaches, due to coarse granularity, often fail to capture fine frequency-selective variations and thus lead to suboptimal resource allocation. In this paper, we propose an AI-driven subcarrier-level CQI feedback framework tailored for 6G and NextG systems. First, we introduce CQInet, an autoencoder-based scheme that compresses per-subcarrier CQI at the user equipment and reconstructs it at the base station, significantly reducing feedback overhead without compromising CQI accuracy. Simulation results show that CQInet increases the effective data rate by 7.6% relative to traditional subband CQI under equivalent feedback overhead. Building on this, we develop SR-CQInet, which leverages super-resolution to infer fine-grained subcarrier CQI from sparsely reported CSI reference signals (CSI-RS). SR-CQInet reduces CSI-RS overhead to 3.5% of CQInet's requirements while maintaining comparable throughput. These results demonstrate that AI-driven subcarrier-level CQI feedback can substantially enhance spectral efficiency and reliability in future wireless networks.
Reducing Pilots in Channel Estimation With Predictive Foundation Models
Dec 17, 2025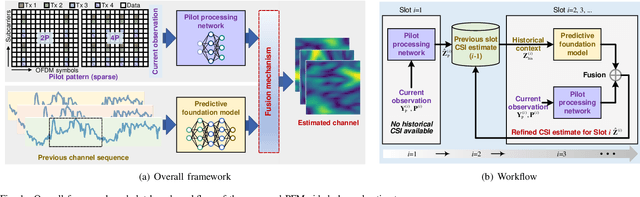
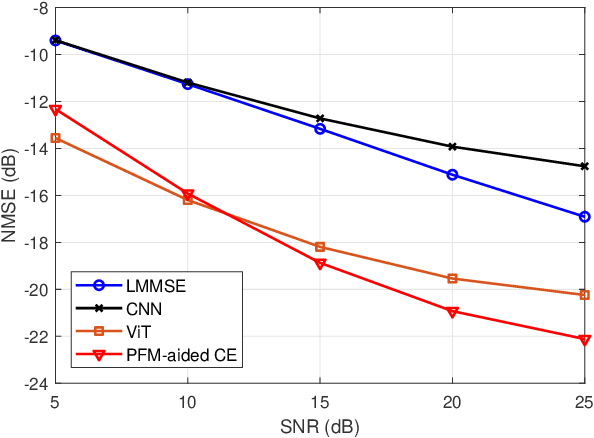
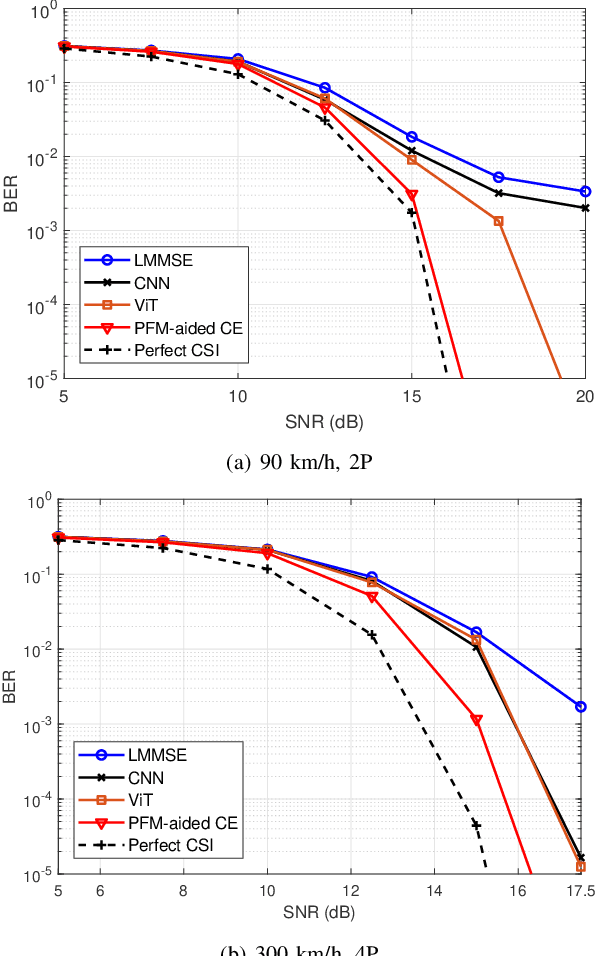
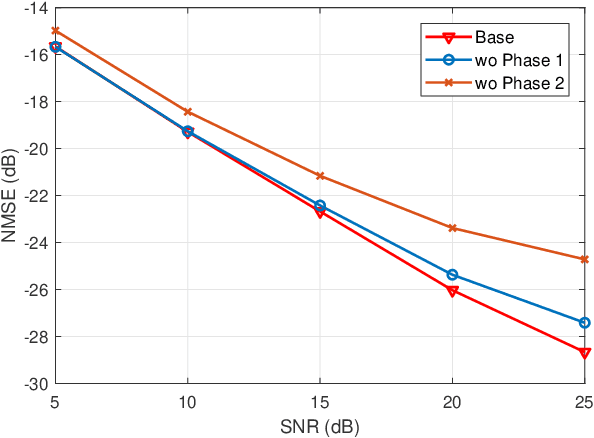
Accurate channel state information (CSI) acquisition is essential for modern wireless systems, which becomes increasingly difficult under large antenna arrays, strict pilot overhead constraints, and diverse deployment environments. Existing artificial intelligence-based solutions often lack robustness and fail to generalize across scenarios. To address this limitation, this paper introduces a predictive-foundation-model-based channel estimation framework that enables accurate, low-overhead, and generalizable CSI acquisition. The proposed framework employs a predictive foundation model trained on large-scale cross-domain CSI data to extract universal channel representations and provide predictive priors with strong cross-scenario transferability. A pilot processing network based on a vision transformer architecture is further designed to capture spatial, temporal, and frequency correlations from pilot observations. An efficient fusion mechanism integrates predictive priors with real-time measurements, enabling reliable CSI reconstruction even under sparse or noisy conditions. Extensive evaluations across diverse configurations demonstrate that the proposed estimator significantly outperforms both classical and data-driven baselines in accuracy, robustness, and generalization capability.
Power Consumption and Energy Efficiency of Mid-Band XL-MIMO: Modeling, Scaling Laws, and Performance Insights
Dec 14, 2025Mid-band extra-large-scale multiple-input multiple-output (XL-MIMO), emerging as a critical enabler for future communication systems, is expected to deliver significantly higher throughput by leveraging the extended bandwidth and enlarged antenna aperture. However, power consumption remains a significant concern due to the enlarged system dimension, underscoring the need for thorough investigations into efficient system design and deployment. To this end, an in-depth study is conducted on mid-band XL-MIMO systems. Specifically, a comprehensive power consumption model is proposed, encompassing the power consumption of major hardware components and signal processing procedures, while capturing the influence of key system parameters. Considering typical near-field propagation characteristics, closed-form approximations of throughput are derived, providing an analytical framework for assessing energy efficiency (EE). Based on the proposed framework, the scaling law of EE with respect to key system configurations is derived, offering valuable insights for system design. Subsequently, extensions and comparisons are conducted among representative multi-antenna technologies, demonstrating the superiority of mid-band XL-MIMO in EE. Extensive numerical results not only verify the tightness of the throughput analysis but also validate the EE evaluations, unveiling the potential of energy-efficient mid-band XL-MIMO systems.