 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
GIU-GANs: Global Information Utilization for Generative Adversarial Networks
Jan 25, 2022
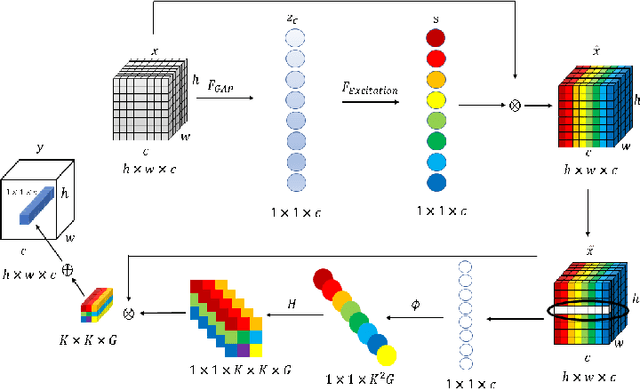

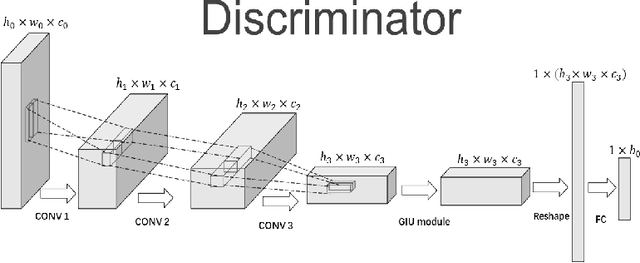

In recent years, with the rapid development of artificial intelligence, image generation based on deep learning has dramatically advanced. Image generation based on Generative Adversarial Networks (GANs) is a promising study. However, since convolutions are limited by spatial-agnostic and channel-specific, features extracted by traditional GANs based on convolution are constrained. Therefore, GANs are unable to capture any more details per image. On the other hand, straightforwardly stacking of convolutions causes too many parameters and layers in GANs, which will lead to a high risk of overfitting. To overcome the aforementioned limitations, in this paper, we propose a new GANs called Involution Generative Adversarial Networks (GIU-GANs). GIU-GANs leverages a brand new module called the Global Information Utilization (GIU) module, which integrates Squeeze-and-Excitation Networks (SENet) and involution to focus on global information by channel attention mechanism, leading to a higher quality of generated images. Meanwhile, Batch Normalization(BN) inevitably ignores the representation differences among noise sampled by the generator, and thus degrade the generated image quality. Thus we introduce Representative Batch Normalization(RBN) to the GANs architecture for this issue. The CIFAR-10 and CelebA datasets are employed to demonstrate the effectiveness of our proposed model. A large number of experiments prove that our model achieves state-of-the-art competitive performance.
A Transformer-based deep neural network model for SSVEP classification
Oct 09, 2022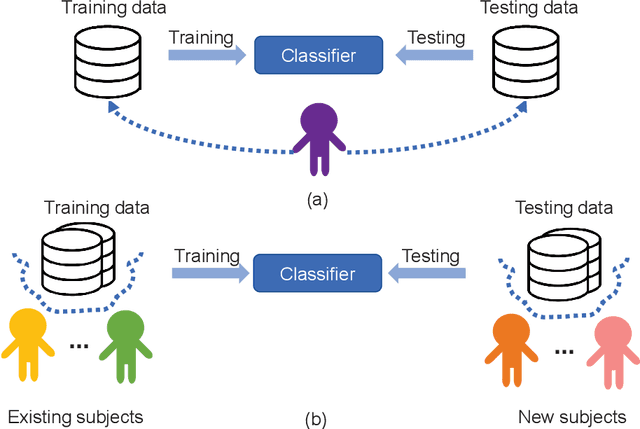
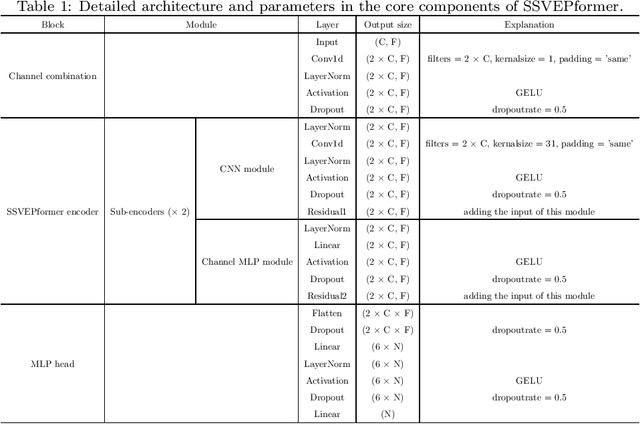
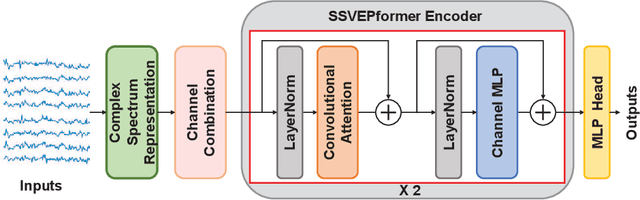
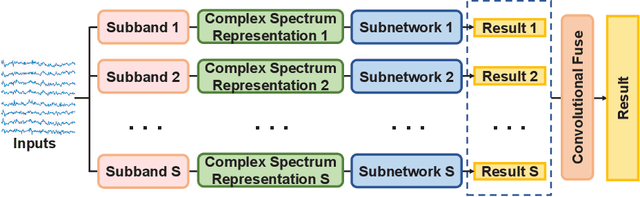
Steady-state visual evoked potential (SSVEP) is one of the most commonly used control signal in the brain-computer interface (BCI) systems. However, the conventional spatial filtering methods for SSVEP classification highly depend on the subject-specific calibration data. The need for the methods that can alleviate the demand for the calibration data become urgent. In recent years, developing the methods that can work in inter-subject classification scenario has become a promising new direction. As the popular deep learning model nowadays, Transformer has excellent performance and has been used in EEG signal classification tasks. Therefore, in this study, we propose a deep learning model for SSVEP classification based on Transformer structure in inter-subject classification scenario, termed as SSVEPformer, which is the first application of the transformer to the classification of SSVEP. Inspired by previous studies, the model adopts the frequency spectrum of SSVEP data as input, and explores the spectral and spatial domain information for classification. Furthermore, to fully utilize the harmonic information, an extended SSVEPformer based on the filter bank technology (FB-SSVEPformer) is proposed to further improve the classification performance. Experiments were conducted using two open datasets (Dataset 1: 10 subjects, 12-class task; Dataset 2: 35 subjects, 40-class task) in the inter-subject classification scenario. The experimental results show that the proposed models could achieve better results in terms of classification accuracy and information transfer rate, compared with other baseline methods. The proposed model validates the feasibility of deep learning models based on Transformer structure for SSVEP classification task, and could serve as a potential model to alleviate the calibration procedure in the practical application of SSVEP-based BCI systems.
STGIN: A Spatial Temporal Graph-Informer Network for Long Sequence Traffic Speed Forecasting
Oct 01, 2022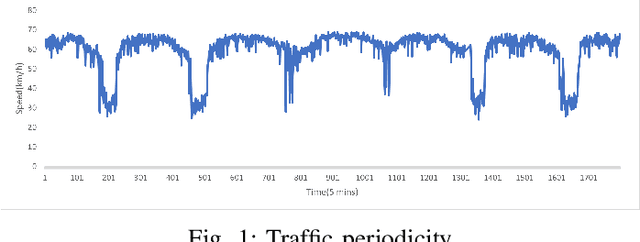
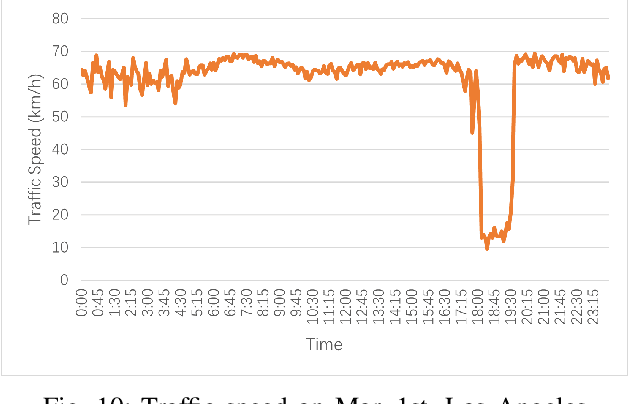
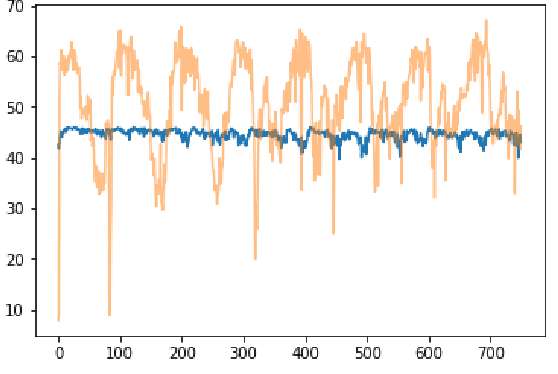
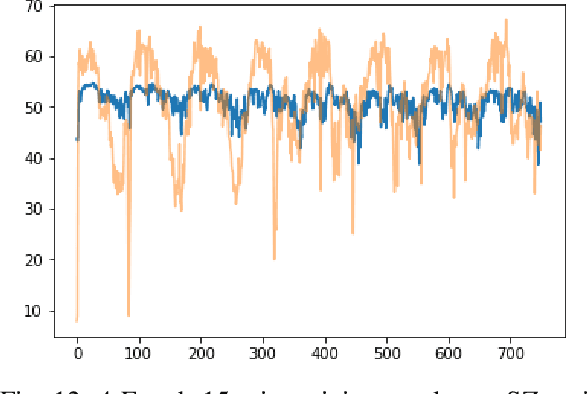
Accurate long series forecasting of traffic information is critical for the development of intelligent traffic systems. We may benefit from the rapid growth of neural network analysis technology to better understand the underlying functioning patterns of traffic networks as a result of this progress. Due to the fact that traffic data and facility utilization circumstances are sequentially dependent on past and present situations, several related neural network techniques based on temporal dependency extraction models have been developed to solve the problem. The complicated topological road structure, on the other hand, amplifies the effect of spatial interdependence, which cannot be captured by pure temporal extraction approaches. Additionally, the typical Deep Recurrent Neural Network (RNN) topology has a constraint on global information extraction, which is required for comprehensive long-term prediction. This study proposes a new spatial-temporal neural network architecture, called Spatial-Temporal Graph-Informer (STGIN), to handle the long-term traffic parameters forecasting issue by merging the Informer and Graph Attention Network (GAT) layers for spatial and temporal relationships extraction. The attention mechanism potentially guarantees long-term prediction performance without significant information loss from distant inputs. On two real-world traffic datasets with varying horizons, experimental findings validate the long sequence prediction abilities, and further interpretation is provided.
Heterogeneous Graph Contrastive Multi-view Learning
Oct 01, 2022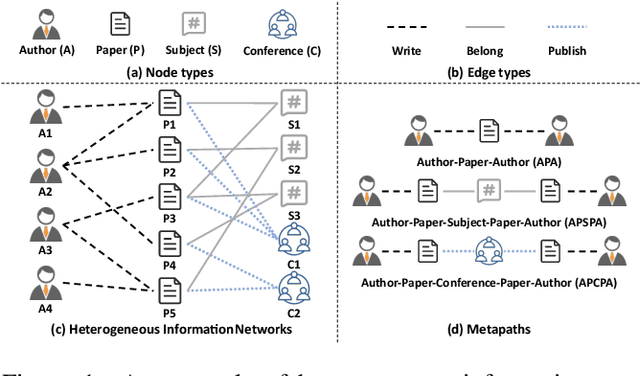
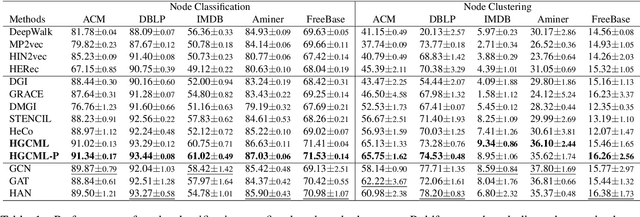
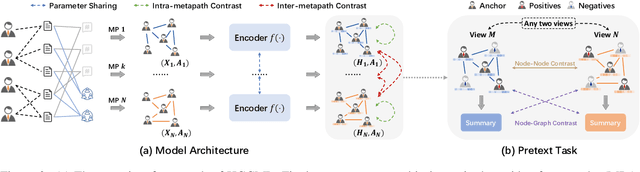
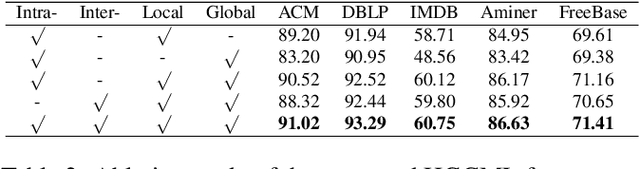
Inspired by the success of contrastive learning (CL) in computer vision and natural language processing, graph contrastive learning (GCL) has been developed to learn discriminative node representations on graph datasets. However, the development of GCL on Heterogeneous Information Networks (HINs) is still in the infant stage. For example, it is unclear how to augment the HINs without substantially altering the underlying semantics, and how to design the contrastive objective to fully capture the rich semantics. Moreover, early investigations demonstrate that CL suffers from sampling bias, whereas conventional debiasing techniques are empirically shown to be inadequate for GCL. How to mitigate the sampling bias for heterogeneous GCL is another important problem. To address the aforementioned challenges, we propose a novel Heterogeneous Graph Contrastive Multi-view Learning (HGCML) model. In particular, we use metapaths as the augmentation to generate multiple subgraphs as multi-views, and propose a contrastive objective to maximize the mutual information between any pairs of metapath-induced views. To alleviate the sampling bias, we further propose a positive sampling strategy to explicitly select positives for each node via jointly considering semantic and structural information preserved on each metapath view. Extensive experiments demonstrate HGCML consistently outperforms state-of-the-art baselines on five real-world benchmark datasets.
Evaluating the Factual Consistency of Large Language Models Through Summarization
Nov 15, 2022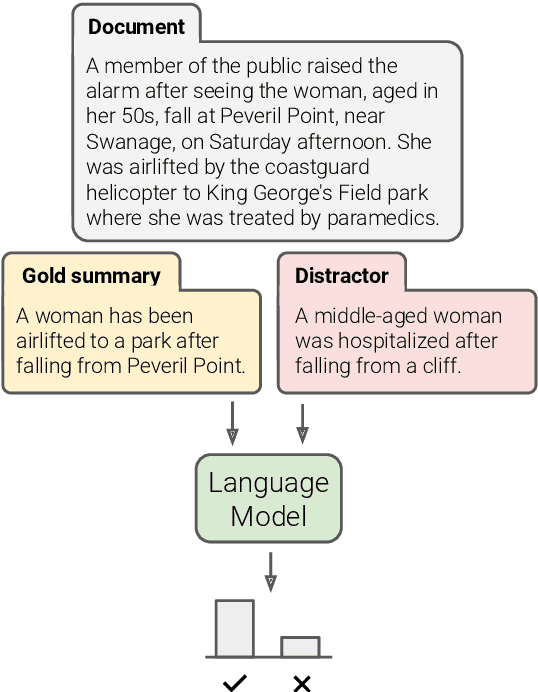

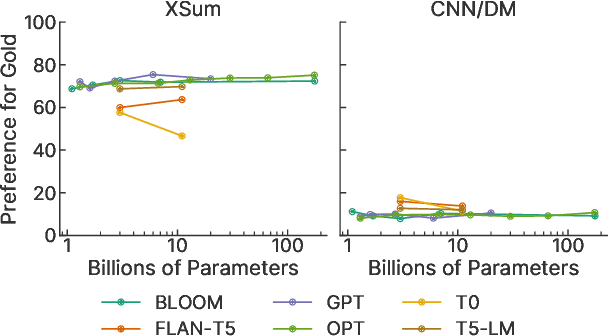
While large language models (LLMs) have proven to be effective on a large variety of tasks, they are also known to hallucinate information. To measure whether an LLM prefers factually consistent continuations of its input, we propose a new benchmark called FIB(Factual Inconsistency Benchmark) that focuses on the task of summarization. Specifically, our benchmark involves comparing the scores an LLM assigns to a factually consistent versus a factually inconsistent summary for an input news article. For factually consistent summaries, we use human-written reference summaries that we manually verify as factually consistent. To generate summaries that are factually inconsistent, we generate summaries from a suite of summarization models that we have manually annotated as factually inconsistent. A model's factual consistency is then measured according to its accuracy, i.e.\ the proportion of documents where it assigns a higher score to the factually consistent summary. To validate the usefulness of FIB, we evaluate 23 large language models ranging from 1B to 176B parameters from six different model families including BLOOM and OPT. We find that existing LLMs generally assign a higher score to factually consistent summaries than to factually inconsistent summaries. However, if the factually inconsistent summaries occur verbatim in the document, then LLMs assign a higher score to these factually inconsistent summaries than factually consistent summaries. We validate design choices in our benchmark including the scoring method and source of distractor summaries. Our code and benchmark data can be found at https://github.com/r-three/fib.
Backdoor Attacks for Remote Sensing Data with Wavelet Transform
Nov 15, 2022
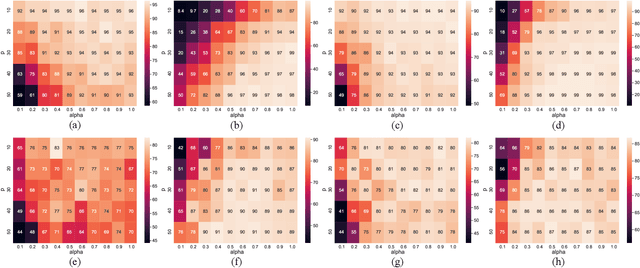

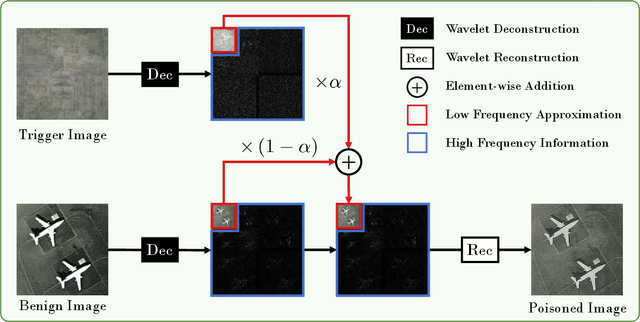
Recent years have witnessed the great success of deep learning algorithms in the geoscience and remote sensing realm. Nevertheless, the security and robustness of deep learning models deserve special attention when addressing safety-critical remote sensing tasks. In this paper, we provide a systematic analysis of backdoor attacks for remote sensing data, where both scene classification and semantic segmentation tasks are considered. While most of the existing backdoor attack algorithms rely on visible triggers like squared patches with well-designed patterns, we propose a novel wavelet transform-based attack (WABA) method, which can achieve invisible attacks by injecting the trigger image into the poisoned image in the low-frequency domain. In this way, the high-frequency information in the trigger image can be filtered out in the attack, resulting in stealthy data poisoning. Despite its simplicity, the proposed method can significantly cheat the current state-of-the-art deep learning models with a high attack success rate. We further analyze how different trigger images and the hyper-parameters in the wavelet transform would influence the performance of the proposed method. Extensive experiments on four benchmark remote sensing datasets demonstrate the effectiveness of the proposed method for both scene classification and semantic segmentation tasks and thus highlight the importance of designing advanced backdoor defense algorithms to address this threat in remote sensing scenarios. The code will be available online at \url{https://github.com/ndraeger/waba}.
HGV4Risk: Hierarchical Global View-guided Sequence Representation Learning for Risk Prediction
Nov 15, 2022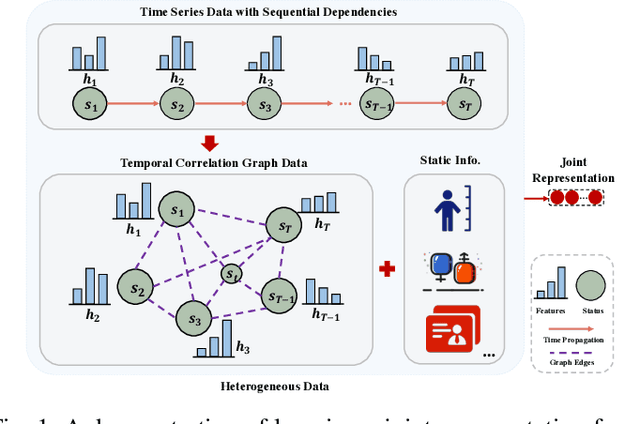
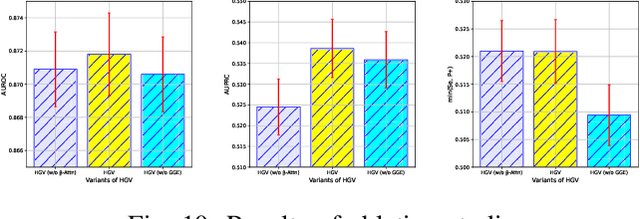
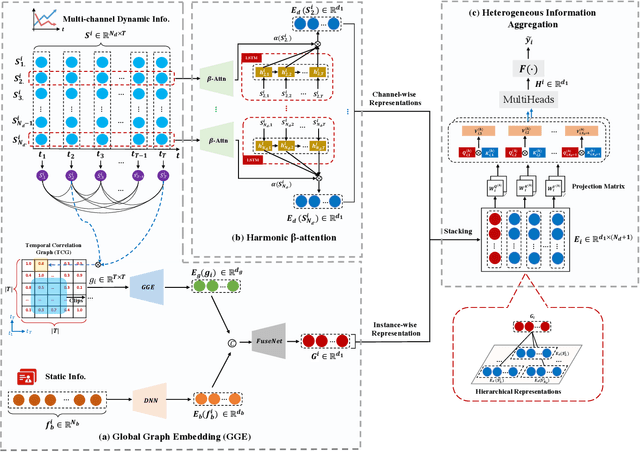
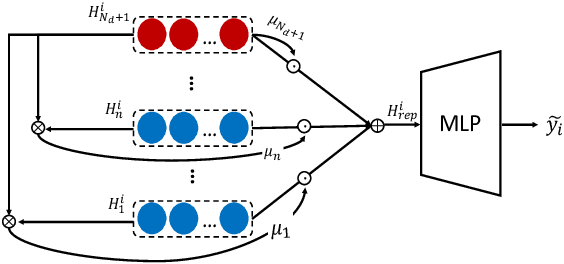
Risk prediction, as a typical time series modeling problem, is usually achieved by learning trends in markers or historical behavior from sequence data, and has been widely applied in healthcare and finance. In recent years, deep learning models, especially Long Short-Term Memory neural networks (LSTMs), have led to superior performances in such sequence representation learning tasks. Despite that some attention or self-attention based models with time-aware or feature-aware enhanced strategies have achieved better performance compared with other temporal modeling methods, such improvement is limited due to a lack of guidance from global view. To address this issue, we propose a novel end-to-end Hierarchical Global View-guided (HGV) sequence representation learning framework. Specifically, the Global Graph Embedding (GGE) module is proposed to learn sequential clip-aware representations from temporal correlation graph at instance level. Furthermore, following the way of key-query attention, the harmonic $\beta$-attention ($\beta$-Attn) is also developed for making a global trade-off between time-aware decay and observation significance at channel level adaptively. Moreover, the hierarchical representations at both instance level and channel level can be coordinated by the heterogeneous information aggregation under the guidance of global view. Experimental results on a benchmark dataset for healthcare risk prediction, and a real-world industrial scenario for Small and Mid-size Enterprises (SMEs) credit overdue risk prediction in MYBank, Ant Group, have illustrated that the proposed model can achieve competitive prediction performance compared with other known baselines.
BiFSMNv2: Pushing Binary Neural Networks for Keyword Spotting to Real-Network Performance
Nov 13, 2022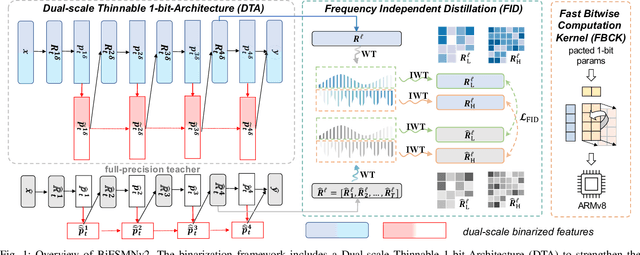
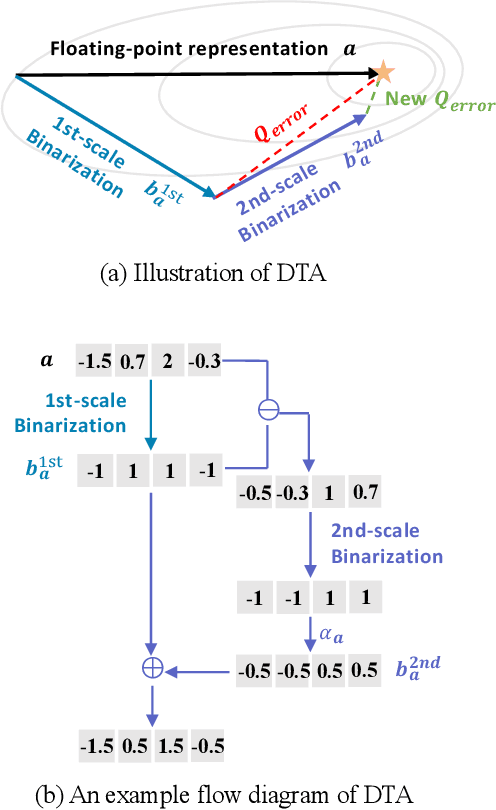
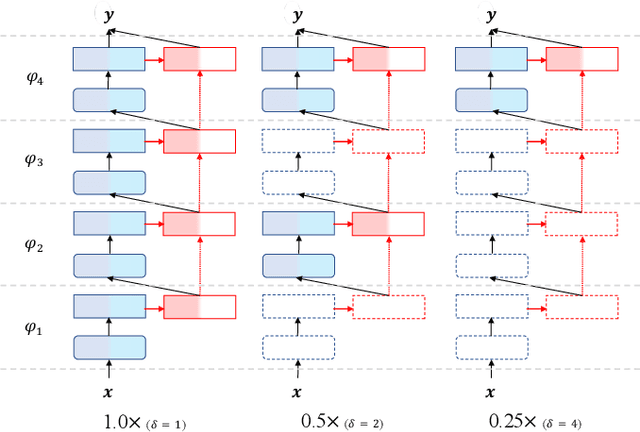
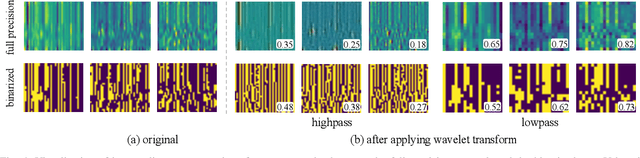
Deep neural networks, such as the Deep-FSMN, have been widely studied for keyword spotting (KWS) applications while suffering expensive computation and storage. Therefore, network compression technologies like binarization are studied to deploy KWS models on edge. In this paper, we present a strong yet efficient binary neural network for KWS, namely BiFSMNv2, pushing it to the real-network accuracy performance. First, we present a Dual-scale Thinnable 1-bit-Architecture to recover the representation capability of the binarized computation units by dual-scale activation binarization and liberate the speedup potential from an overall architecture perspective. Second, we also construct a Frequency Independent Distillation scheme for KWS binarization-aware training, which distills the high and low-frequency components independently to mitigate the information mismatch between full-precision and binarized representations. Moreover, we implement BiFSMNv2 on ARMv8 real-world hardware with a novel Fast Bitwise Computation Kernel, which is proposed to fully utilize registers and increase instruction throughput. Comprehensive experiments show our BiFSMNv2 outperforms existing binary networks for KWS by convincing margins across different datasets and even achieves comparable accuracy with the full-precision networks (e.g., only 1.59% drop on Speech Commands V1-12). We highlight that benefiting from the compact architecture and optimized hardware kernel, BiFSMNv2 can achieve an impressive 25.1x speedup and 20.2x storage-saving on edge hardware.
Personalizing Sustainable Agriculture with Causal Machine Learning
Nov 06, 2022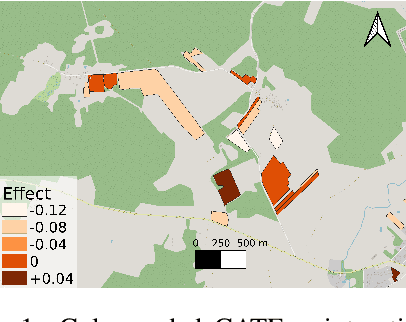
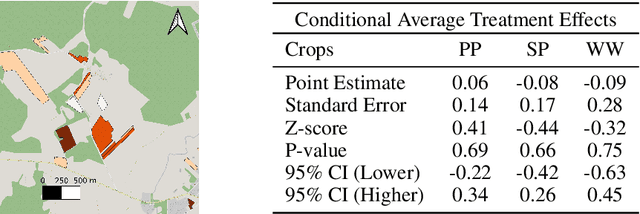
To fight climate change and accommodate the increasing population, global crop production has to be strengthened. To achieve the "sustainable intensification" of agriculture, transforming it from carbon emitter to carbon sink is a priority, and understanding the environmental impact of agricultural management practices is a fundamental prerequisite to that. At the same time, the global agricultural landscape is deeply heterogeneous, with differences in climate, soil, and land use inducing variations in how agricultural systems respond to farmer actions. The "personalization" of sustainable agriculture with the provision of locally adapted management advice is thus a necessary condition for the efficient uplift of green metrics, and an integral development in imminent policies. Here, we formulate personalized sustainable agriculture as a Conditional Average Treatment Effect estimation task and use Causal Machine Learning for tackling it. Leveraging climate data, land use information and employing Double Machine Learning, we estimate the heterogeneous effect of sustainable practices on the field-level Soil Organic Carbon content in Lithuania. We thus provide a data-driven perspective for targeting sustainable practices and effectively expanding the global carbon sink.
Preserving background sound in noise-robust voice conversion via multi-task learning
Nov 06, 2022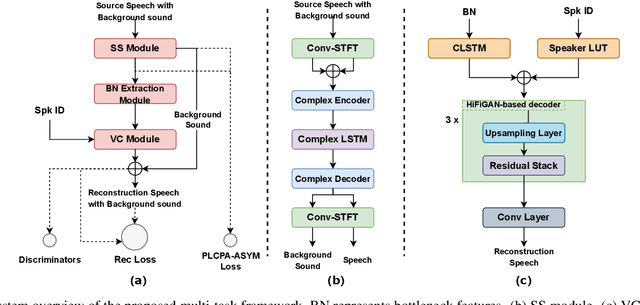
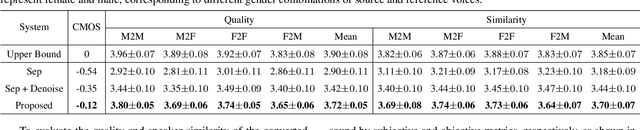
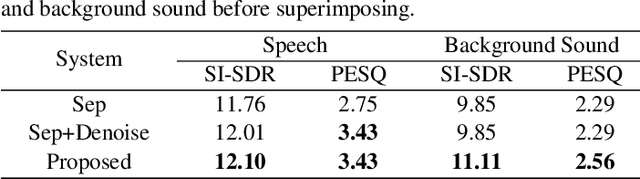
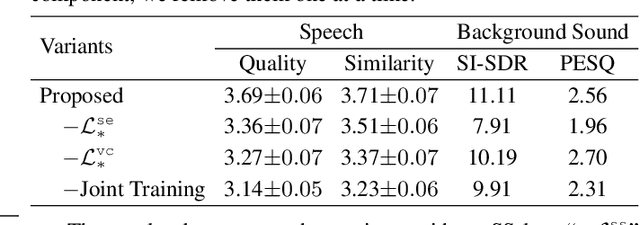
Background sound is an informative form of art that is helpful in providing a more immersive experience in real-application voice conversion (VC) scenarios. However, prior research about VC, mainly focusing on clean voices, pay rare attention to VC with background sound. The critical problem for preserving background sound in VC is inevitable speech distortion by the neural separation model and the cascade mismatch between the source separation model and the VC model. In this paper, we propose an end-to-end framework via multi-task learning which sequentially cascades a source separation (SS) module, a bottleneck feature extraction module and a VC module. Specifically, the source separation task explicitly considers critical phase information and confines the distortion caused by the imperfect separation process. The source separation task, the typical VC task and the unified task shares a uniform reconstruction loss constrained by joint training to reduce the mismatch between the SS and VC modules. Experimental results demonstrate that our proposed framework significantly outperforms the baseline systems while achieving comparable quality and speaker similarity to the VC models trained with clean data.