 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHDBFormer: Efficient RGB-D Semantic Segmentation with A Heterogeneous Dual-Branch Framework
Apr 18, 2025



In RGB-D semantic segmentation for indoor scenes, a key challenge is effectively integrating the rich color information from RGB images with the spatial distance information from depth images. However, most existing methods overlook the inherent differences in how RGB and depth images express information. Properly distinguishing the processing of RGB and depth images is essential to fully exploiting their unique and significant characteristics. To address this, we propose a novel heterogeneous dual-branch framework called HDBFormer, specifically designed to handle these modality differences. For RGB images, which contain rich detail, we employ both a basic and detail encoder to extract local and global features. For the simpler depth images, we propose LDFormer, a lightweight hierarchical encoder that efficiently extracts depth features with fewer parameters. Additionally, we introduce the Modality Information Interaction Module (MIIM), which combines transformers with large kernel convolutions to interact global and local information across modalities efficiently. Extensive experiments show that HDBFormer achieves state-of-the-art performance on the NYUDepthv2 and SUN-RGBD datasets. The code is available at: https://github.com/Weishuobin/HDBFormer.
* 6 pages, 4 figures, published to IEEE Signal Processing Letter
GIU-GANs: Global Information Utilization for Generative Adversarial Networks
Jan 25, 2022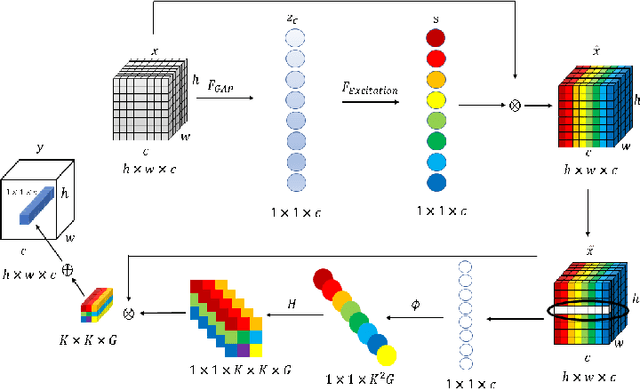

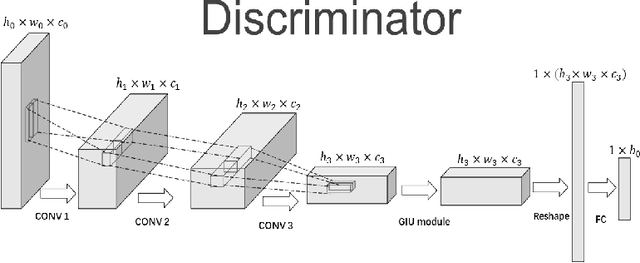

In recent years, with the rapid development of artificial intelligence, image generation based on deep learning has dramatically advanced. Image generation based on Generative Adversarial Networks (GANs) is a promising study. However, since convolutions are limited by spatial-agnostic and channel-specific, features extracted by traditional GANs based on convolution are constrained. Therefore, GANs are unable to capture any more details per image. On the other hand, straightforwardly stacking of convolutions causes too many parameters and layers in GANs, which will lead to a high risk of overfitting. To overcome the aforementioned limitations, in this paper, we propose a new GANs called Involution Generative Adversarial Networks (GIU-GANs). GIU-GANs leverages a brand new module called the Global Information Utilization (GIU) module, which integrates Squeeze-and-Excitation Networks (SENet) and involution to focus on global information by channel attention mechanism, leading to a higher quality of generated images. Meanwhile, Batch Normalization(BN) inevitably ignores the representation differences among noise sampled by the generator, and thus degrade the generated image quality. Thus we introduce Representative Batch Normalization(RBN) to the GANs architecture for this issue. The CIFAR-10 and CelebA datasets are employed to demonstrate the effectiveness of our proposed model. A large number of experiments prove that our model achieves state-of-the-art competitive performance.