 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
MMA-RNN: A Multi-level Multi-task Attention-based Recurrent Neural Network for Discrimination and Localization of Atrial Fibrillation
Feb 07, 2023
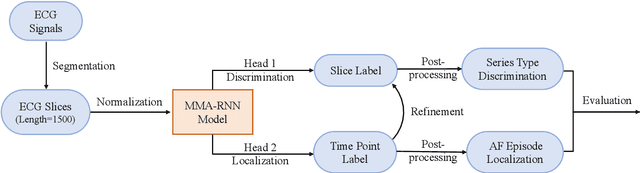

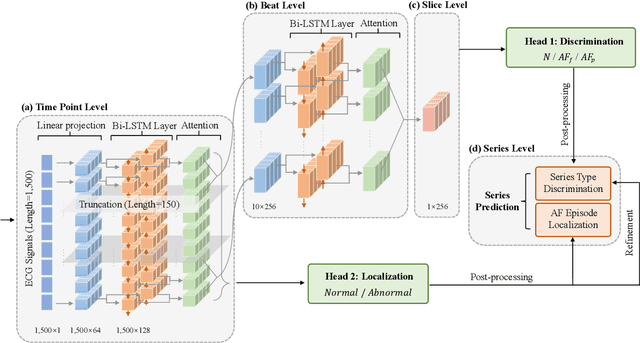

The automatic detection of atrial fibrillation based on electrocardiograph (ECG) signals has received wide attention both clinically and practically. It is challenging to process ECG signals with cyclical pattern, varying length and unstable quality due to noise and distortion. Besides, there has been insufficient research on separating persistent atrial fibrillation from paroxysmal atrial fibrillation, and little discussion on locating the onsets and end points of AF episodes. It is even more arduous to perform well on these two distinct but interrelated tasks, while avoiding the mistakes inherent from stage-by-stage approaches. This paper proposes the Multi-level Multi-task Attention-based Recurrent Neural Network for three-class discrimination on patients and localization of the exact timing of AF episodes. Our model captures three-level sequential features based on a hierarchical architecture utilizing Bidirectional Long and Short-Term Memory Network (Bi-LSTM) and attention layers, and accomplishes the two tasks simultaneously with a multi-head classifier. The model is designed as an end-to-end framework to enhance information interaction and reduce error accumulation. Finally, we conduct experiments on CPSC 2021 dataset and the result demonstrates the superior performance of our method, indicating the potential application of MMA-RNN to wearable mobile devices for routine AF monitoring and early diagnosis.
Cluster-Level Contrastive Learning for Emotion Recognition in Conversations
Feb 07, 2023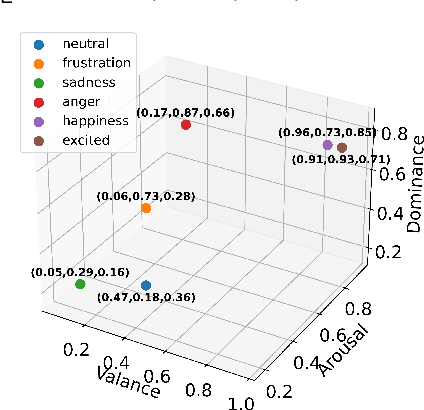

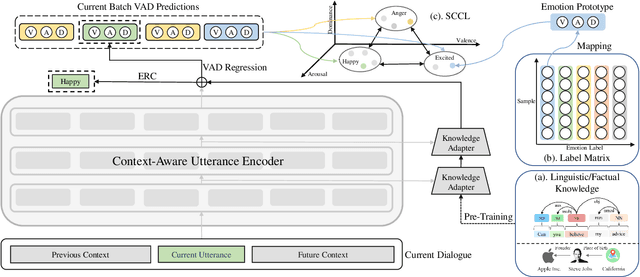
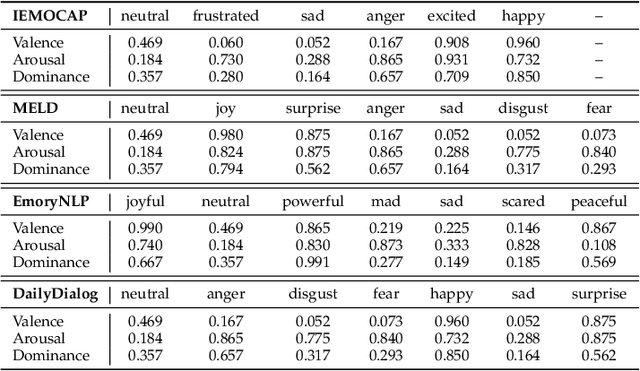
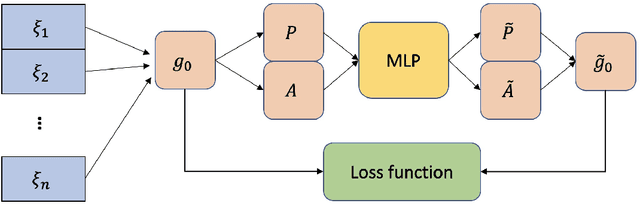
A key challenge for Emotion Recognition in Conversations (ERC) is to distinguish semantically similar emotions. Some works utilise Supervised Contrastive Learning (SCL) which uses categorical emotion labels as supervision signals and contrasts in high-dimensional semantic space. However, categorical labels fail to provide quantitative information between emotions. ERC is also not equally dependent on all embedded features in the semantic space, which makes the high-dimensional SCL inefficient. To address these issues, we propose a novel low-dimensional Supervised Cluster-level Contrastive Learning (SCCL) method, which first reduces the high-dimensional SCL space to a three-dimensional affect representation space Valence-Arousal-Dominance (VAD), then performs cluster-level contrastive learning to incorporate measurable emotion prototypes. To help modelling the dialogue and enriching the context, we leverage the pre-trained knowledge adapters to infuse linguistic and factual knowledge. Experiments show that our method achieves new state-of-the-art results with 69.81% on IEMOCAP, 65.7% on MELD, and 62.51% on DailyDialog datasets. The analysis also proves that the VAD space is not only suitable for ERC but also interpretable, with VAD prototypes enhancing its performance and stabilising the training of SCCL. In addition, the pre-trained knowledge adapters benefit the performance of the utterance encoder and SCCL. Our code is available at: https://github.com/SteveKGYang/SCCL
Learning Discretized Neural Networks under Ricci Flow
Feb 07, 2023
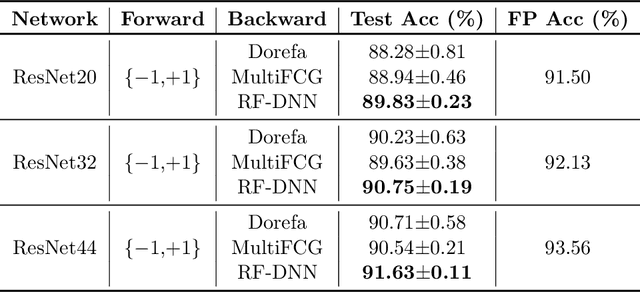
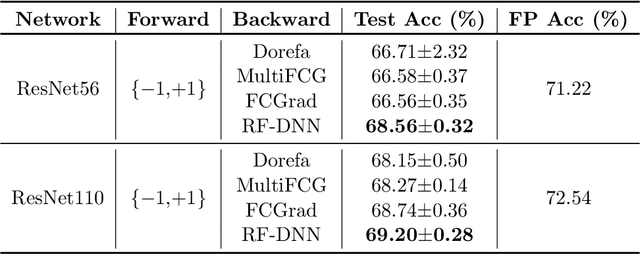
In this paper, we consider Discretized Neural Networks (DNNs) consisting of low-precision weights and activations, which suffer from either infinite or zero gradients caused by the non-differentiable discrete function in the training process. In this case, most training-based DNNs use the standard Straight-Through Estimator (STE) to approximate the gradient w.r.t. discrete value. However, the standard STE will cause the gradient mismatch problem, i.e., the approximated gradient direction may deviate from the steepest descent direction. In other words, the gradient mismatch implies the approximated gradient with perturbations. To address this problem, we introduce the duality theory to regard the perturbation of the approximated gradient as the perturbation of the metric in Linearly Nearly Euclidean (LNE) manifolds. Simultaneously, under the Ricci-DeTurck flow, we prove the dynamical stability and convergence of the LNE metric with the $L^2$-norm perturbation, which can provide a theoretical solution for the gradient mismatch problem. In practice, we also present the steepest descent gradient flow for DNNs on LNE manifolds from the viewpoints of the information geometry and mirror descent. The experimental results on various datasets demonstrate that our method achieves better and more stable performance for DNNs than other representative training-based methods.
CHiLS: Zero-Shot Image Classification with Hierarchical Label Sets
Feb 07, 2023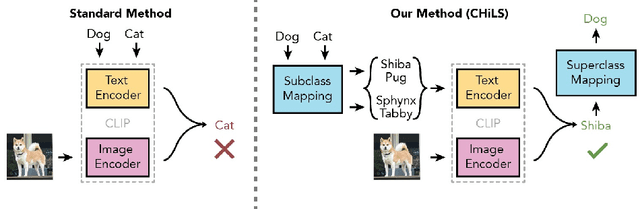
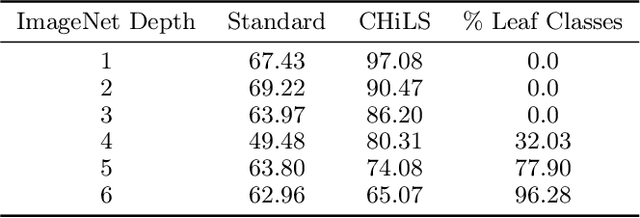

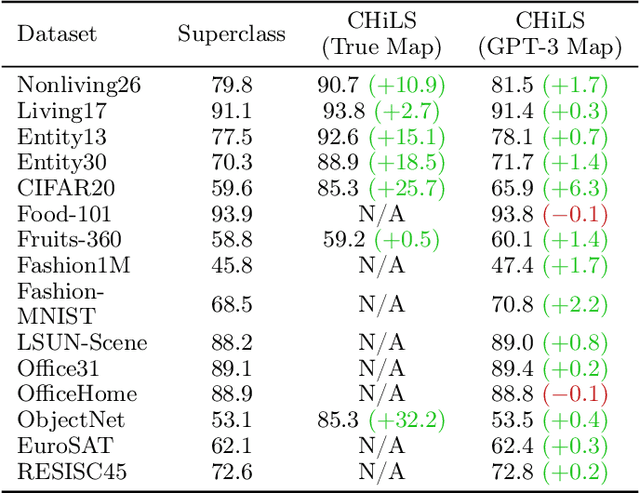
Open vocabulary models (e.g. CLIP) have shown strong performance on zero-shot classification through their ability generate embeddings for each class based on their (natural language) names. Prior work has focused on improving the accuracy of these models through prompt engineering or by incorporating a small amount of labeled downstream data (via finetuning). However, there has been little focus on improving the richness of the class names themselves, which can pose issues when class labels are coarsely-defined and uninformative. We propose Classification with Hierarchical Label Sets (or CHiLS), an alternative strategy for zero-shot classification specifically designed for datasets with implicit semantic hierarchies. CHiLS proceeds in three steps: (i) for each class, produce a set of subclasses, using either existing label hierarchies or by querying GPT-3; (ii) perform the standard zero-shot CLIP procedure as though these subclasses were the labels of interest; (iii) map the predicted subclass back to its parent to produce the final prediction. Across numerous datasets with underlying hierarchical structure, CHiLS leads to improved accuracy in situations both with and without ground-truth hierarchical information. CHiLS is simple to implement within existing CLIP pipelines and requires no additional training cost. Code is available at: https://github.com/acmi-lab/CHILS.
HiDAnet: RGB-D Salient Object Detection via Hierarchical Depth Awareness
Jan 18, 2023

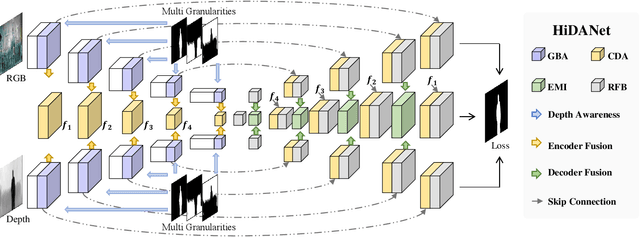
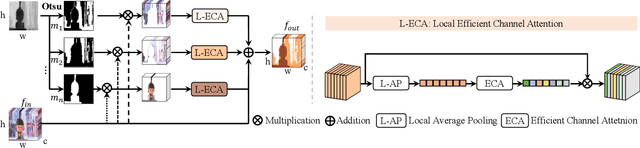
RGB-D saliency detection aims to fuse multi-modal cues to accurately localize salient regions. Existing works often adopt attention modules for feature modeling, with few methods explicitly leveraging fine-grained details to merge with semantic cues. Thus, despite the auxiliary depth information, it is still challenging for existing models to distinguish objects with similar appearances but at distinct camera distances. In this paper, from a new perspective, we propose a novel Hierarchical Depth Awareness network (HiDAnet) for RGB-D saliency detection. Our motivation comes from the observation that the multi-granularity properties of geometric priors correlate well with the neural network hierarchies. To realize multi-modal and multi-level fusion, we first use a granularity-based attention scheme to strengthen the discriminatory power of RGB and depth features separately. Then we introduce a unified cross dual-attention module for multi-modal and multi-level fusion in a coarse-to-fine manner. The encoded multi-modal features are gradually aggregated into a shared decoder. Further, we exploit a multi-scale loss to take full advantage of the hierarchical information. Extensive experiments on challenging benchmark datasets demonstrate that our HiDAnet performs favorably over the state-of-the-art methods by large margins.
Label Inference Attack against Split Learning under Regression Setting
Jan 18, 2023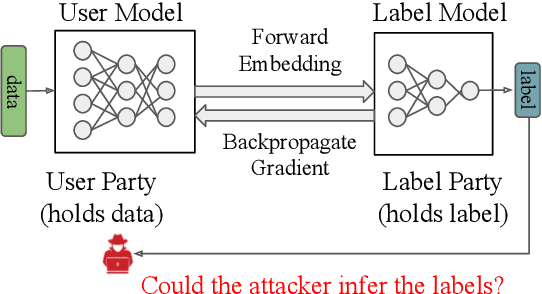
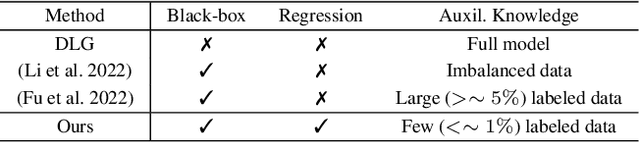
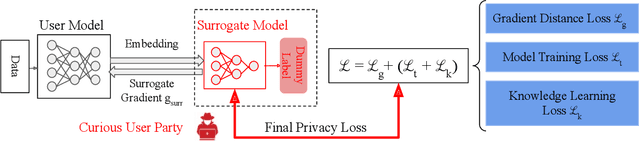
As a crucial building block in vertical Federated Learning (vFL), Split Learning (SL) has demonstrated its practice in the two-party model training collaboration, where one party holds the features of data samples and another party holds the corresponding labels. Such method is claimed to be private considering the shared information is only the embedding vectors and gradients instead of private raw data and labels. However, some recent works have shown that the private labels could be leaked by the gradients. These existing attack only works under the classification setting where the private labels are discrete. In this work, we step further to study the leakage in the scenario of the regression model, where the private labels are continuous numbers (instead of discrete labels in classification). This makes previous attacks harder to infer the continuous labels due to the unbounded output range. To address the limitation, we propose a novel learning-based attack that integrates gradient information and extra learning regularization objectives in aspects of model training properties, which can infer the labels under regression settings effectively. The comprehensive experiments on various datasets and models have demonstrated the effectiveness of our proposed attack. We hope our work can pave the way for future analyses that make the vFL framework more secure.
Multi-compartment Neuron and Population Encoding improved Spiking Neural Network for Deep Distributional Reinforcement Learning
Jan 18, 2023
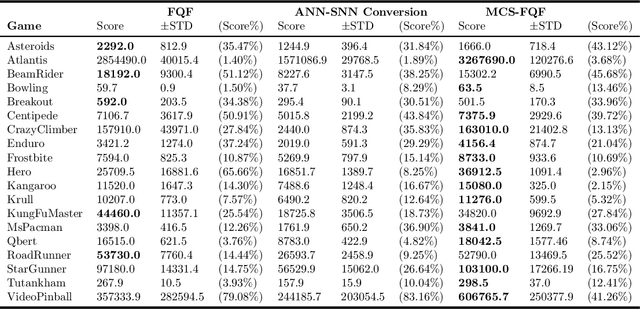
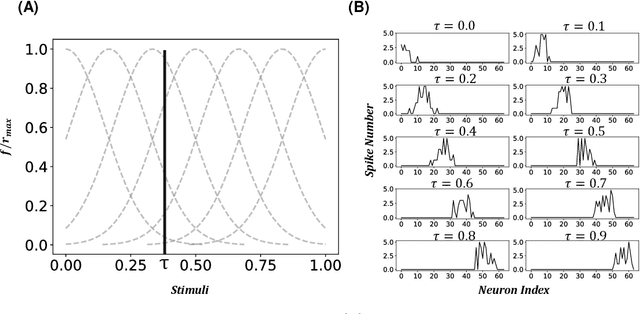
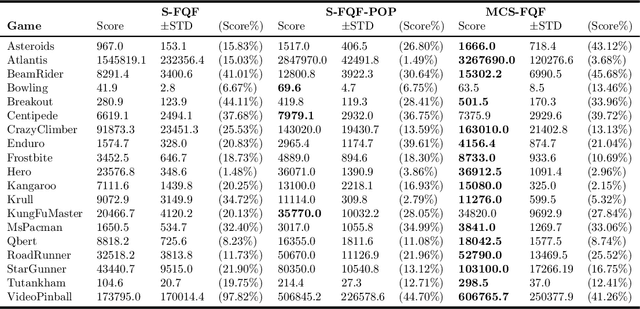
Inspired by the information processing with binary spikes in the brain, the spiking neural networks (SNNs) exhibit significant low energy consumption and are more suitable for incorporating multi-scale biological characteristics. Spiking Neurons, as the basic information processing unit of SNNs, are often simplified in most SNNs which only consider LIF point neuron and do not take into account the multi-compartmental structural properties of biological neurons. This limits the computational and learning capabilities of SNNs. In this paper, we proposed a brain-inspired SNN-based deep distributional reinforcement learning algorithm with combination of bio-inspired multi-compartment neuron (MCN) model and population coding method. The proposed multi-compartment neuron built the structure and function of apical dendritic, basal dendritic, and somatic computing compartments to achieve the computational power close to that of biological neurons. Besides, we present an implicit fractional embedding method based on spiking neuron population encoding. We tested our model on Atari games, and the experiment results show that the performance of our model surpasses the vanilla ANN-based FQF model and ANN-SNN conversion method based Spiking-FQF models. The ablation experiments show that the proposed multi-compartment neural model and quantile fraction implicit population spike representation play an important role in realizing SNN-based deep distributional reinforcement learning.
Towards Long-Term Time-Series Forecasting: Feature, Pattern, and Distribution
Jan 05, 2023
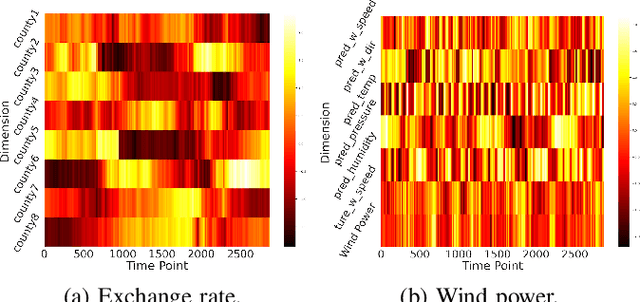
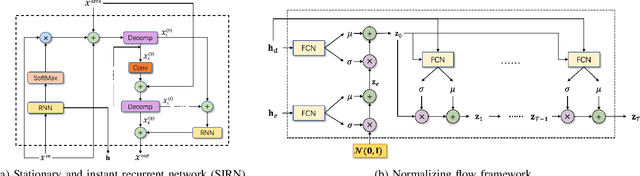
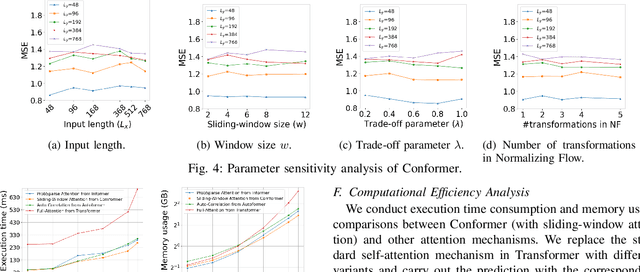
Long-term time-series forecasting (LTTF) has become a pressing demand in many applications, such as wind power supply planning. Transformer models have been adopted to deliver high prediction capacity because of the high computational self-attention mechanism. Though one could lower the complexity of Transformers by inducing the sparsity in point-wise self-attentions for LTTF, the limited information utilization prohibits the model from exploring the complex dependencies comprehensively. To this end, we propose an efficient Transformerbased model, named Conformer, which differentiates itself from existing methods for LTTF in three aspects: (i) an encoder-decoder architecture incorporating a linear complexity without sacrificing information utilization is proposed on top of sliding-window attention and Stationary and Instant Recurrent Network (SIRN); (ii) a module derived from the normalizing flow is devised to further improve the information utilization by inferring the outputs with the latent variables in SIRN directly; (iii) the inter-series correlation and temporal dynamics in time-series data are modeled explicitly to fuel the downstream self-attention mechanism. Extensive experiments on seven real-world datasets demonstrate that Conformer outperforms the state-of-the-art methods on LTTF and generates reliable prediction results with uncertainty quantification.
Parameter-Efficient Low-Resource Dialogue State Tracking by Prompt Tuning
Jan 26, 2023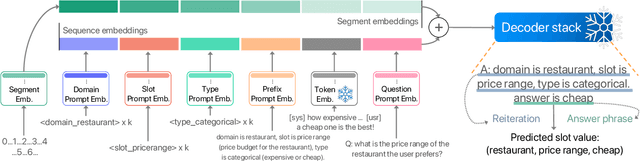
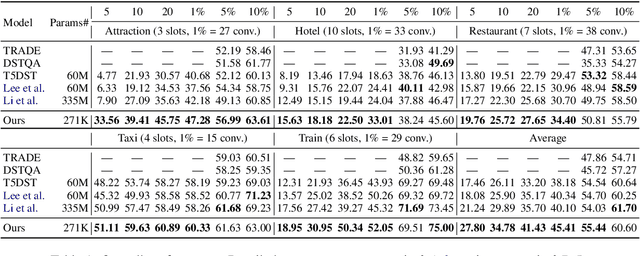
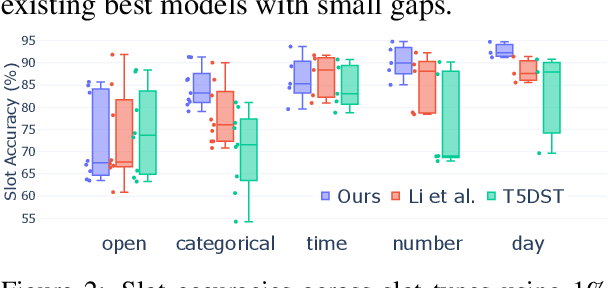
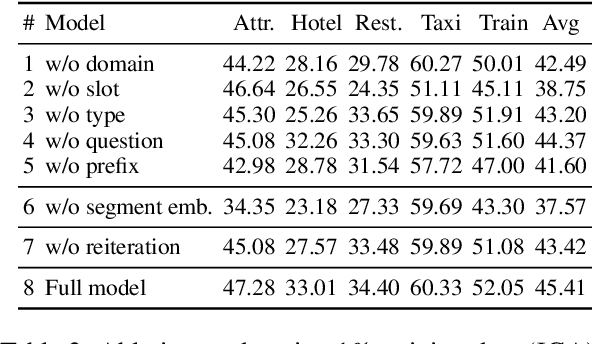
Dialogue state tracking (DST) is an important step in dialogue management to keep track of users' beliefs. Existing works fine-tune all language model (LM) parameters to tackle the DST task, which requires significant data and computing resources for training and hosting. The cost grows exponentially in the real-world deployment where dozens of fine-tuned LM are used for different domains and tasks. To reduce parameter size and better utilize cross-task shared information, we propose to use soft prompt token embeddings to learn task properties. Without tuning LM parameters, our method drastically reduces the number of parameters needed to less than 0.5% of prior works while achieves better low-resource DST performance.
Recursive Neural Networks with Bottlenecks Diagnose (Non-)Compositionality
Jan 31, 2023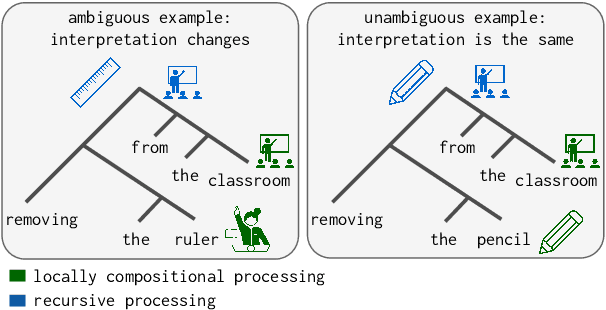
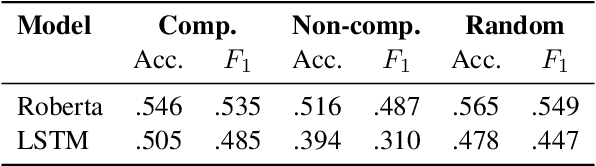
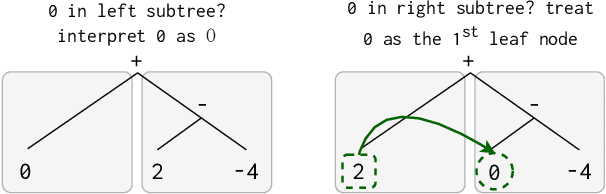
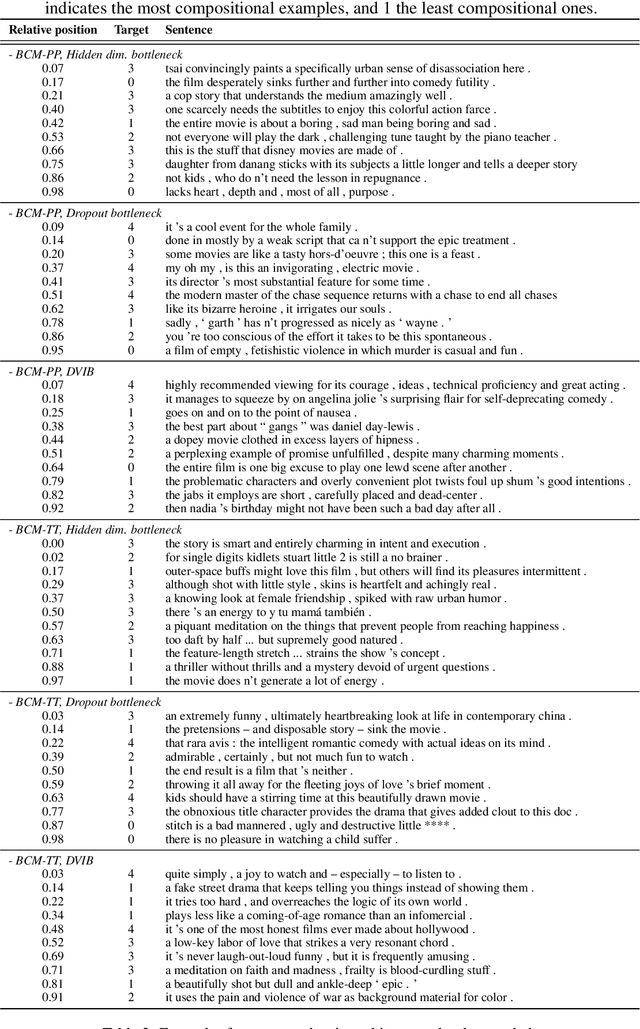
A recent line of work in NLP focuses on the (dis)ability of models to generalise compositionally for artificial languages. However, when considering natural language tasks, the data involved is not strictly, or locally, compositional. Quantifying the compositionality of data is a challenging task, which has been investigated primarily for short utterances. We use recursive neural models (Tree-LSTMs) with bottlenecks that limit the transfer of information between nodes. We illustrate that comparing data's representations in models with and without the bottleneck can be used to produce a compositionality metric. The procedure is applied to the evaluation of arithmetic expressions using synthetic data, and sentiment classification using natural language data. We demonstrate that compression through a bottleneck impacts non-compositional examples disproportionately and then use the bottleneck compositionality metric (BCM) to distinguish compositional from non-compositional samples, yielding a compositionality ranking over a dataset.