 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXCR-Bench: A Multi-Task Benchmark for Evaluating Cultural Reasoning in LLMs
Jan 20, 2026Cross-cultural competence in large language models (LLMs) requires the ability to identify Culture-Specific Items (CSIs) and to adapt them appropriately across cultural contexts. Progress in evaluating this capability has been constrained by the scarcity of high-quality CSI-annotated corpora with parallel cross-cultural sentence pairs. To address this limitation, we introduce XCR-Bench, a Cross(X)-Cultural Reasoning Benchmark consisting of 4.9k parallel sentences and 1,098 unique CSIs, spanning three distinct reasoning tasks with corresponding evaluation metrics. Our corpus integrates Newmark's CSI framework with Hall's Triad of Culture, enabling systematic analysis of cultural reasoning beyond surface-level artifacts and into semi-visible and invisible cultural elements such as social norms, beliefs, and values. Our findings show that state-of-the-art LLMs exhibit consistent weaknesses in identifying and adapting CSIs related to social etiquette and cultural reference. Additionally, we find evidence that LLMs encode regional and ethno-religious biases even within a single linguistic setting during cultural adaptation. We release our corpus and code to facilitate future research on cross-cultural NLP.
Alexandria: A Multi-Domain Dialectal Arabic Machine Translation Dataset for Culturally Inclusive and Linguistically Diverse LLMs
Jan 19, 2026Arabic is a highly diglossic language where most daily communication occurs in regional dialects rather than Modern Standard Arabic. Despite this, machine translation (MT) systems often generalize poorly to dialectal input, limiting their utility for millions of speakers. We introduce \textbf{Alexandria}, a large-scale, community-driven, human-translated dataset designed to bridge this gap. Alexandria covers 13 Arab countries and 11 high-impact domains, including health, education, and agriculture. Unlike previous resources, Alexandria provides unprecedented granularity by associating contributions with city-of-origin metadata, capturing authentic local varieties beyond coarse regional labels. The dataset consists of multi-turn conversational scenarios annotated with speaker-addressee gender configurations, enabling the study of gender-conditioned variation in dialectal use. Comprising 107K total samples, Alexandria serves as both a training resource and a rigorous benchmark for evaluating MT and Large Language Models (LLMs). Our automatic and human evaluation of Arabic-aware LLMs benchmarks current capabilities in translating across diverse Arabic dialects and sub-dialects, while exposing significant persistent challenges.
AraHealthQA 2025: The First Shared Task on Arabic Health Question Answering
Aug 28, 2025We introduce {AraHealthQA 2025}, the {Comprehensive Arabic Health Question Answering Shared Task}, held in conjunction with {ArabicNLP 2025} (co-located with EMNLP 2025). This shared task addresses the paucity of high-quality Arabic medical QA resources by offering two complementary tracks: {MentalQA}, focusing on Arabic mental health Q\&A (e.g., anxiety, depression, stigma reduction), and {MedArabiQ}, covering broader medical domains such as internal medicine, pediatrics, and clinical decision making. Each track comprises multiple subtasks, evaluation datasets, and standardized metrics, facilitating fair benchmarking. The task was structured to promote modeling under realistic, multilingual, and culturally nuanced healthcare contexts. We outline the dataset creation, task design and evaluation framework, participation statistics, baseline systems, and summarize the overall outcomes. We conclude with reflections on the performance trends observed and prospects for future iterations in Arabic health QA.
Evaluating the Effectiveness of the Foundational Models for Q&A Classification in Mental Health care
Jun 23, 2024



Pre-trained Language Models (PLMs) have the potential to transform mental health support by providing accessible and culturally sensitive resources. However, despite this potential, their effectiveness in mental health care and specifically for the Arabic language has not been extensively explored. To bridge this gap, this study evaluates the effectiveness of foundational models for classification of Questions and Answers (Q&A) in the domain of mental health care. We leverage the MentalQA dataset, an Arabic collection featuring Q&A interactions related to mental health. In this study, we conducted experiments using four different types of learning approaches: traditional feature extraction, PLMs as feature extractors, Fine-tuning PLMs and prompting large language models (GPT-3.5 and GPT-4) in zero-shot and few-shot learning settings. While traditional feature extractors combined with Support Vector Machines (SVM) showed promising performance, PLMs exhibited even better results due to their ability to capture semantic meaning. For example, MARBERT achieved the highest performance with a Jaccard Score of 0.80 for question classification and a Jaccard Score of 0.86 for answer classification. We further conducted an in-depth analysis including examining the effects of fine-tuning versus non-fine-tuning, the impact of varying data size, and conducting error analysis. Our analysis demonstrates that fine-tuning proved to be beneficial for enhancing the performance of PLMs, and the size of the training data played a crucial role in achieving high performance. We also explored prompting, where few-shot learning with GPT-3.5 yielded promising results. There was an improvement of 12% for question and classification and 45% for answer classification. Based on our findings, it can be concluded that PLMs and prompt-based approaches hold promise for mental health support in Arabic.
MentalQA: An Annotated Arabic Corpus for Questions and Answers of Mental Healthcare
May 21, 2024Mental health disorders significantly impact people globally, regardless of background, education, or socioeconomic status. However, access to adequate care remains a challenge, particularly for underserved communities with limited resources. Text mining tools offer immense potential to support mental healthcare by assisting professionals in diagnosing and treating patients. This study addresses the scarcity of Arabic mental health resources for developing such tools. We introduce MentalQA, a novel Arabic dataset featuring conversational-style question-and-answer (QA) interactions. To ensure data quality, we conducted a rigorous annotation process using a well-defined schema with quality control measures. Data was collected from a question-answering medical platform. The annotation schema for mental health questions and corresponding answers draws upon existing classification schemes with some modifications. Question types encompass six distinct categories: diagnosis, treatment, anatomy \& physiology, epidemiology, healthy lifestyle, and provider choice. Answer strategies include information provision, direct guidance, and emotional support. Three experienced annotators collaboratively annotated the data to ensure consistency. Our findings demonstrate high inter-annotator agreement, with Fleiss' Kappa of $0.61$ for question types and $0.98$ for answer strategies. In-depth analysis revealed insightful patterns, including variations in question preferences across age groups and a strong correlation between question types and answer strategies. MentalQA offers a valuable foundation for developing Arabic text mining tools capable of supporting mental health professionals and individuals seeking information.
Investigating Persuasion Techniques in Arabic: An Empirical Study Leveraging Large Language Models
May 21, 2024



In the current era of digital communication and widespread use of social media, it is crucial to develop an understanding of persuasive techniques employed in written text. This knowledge is essential for effectively discerning accurate information and making informed decisions. To address this need, this paper presents a comprehensive empirical study focused on identifying persuasive techniques in Arabic social media content. To achieve this objective, we utilize Pre-trained Language Models (PLMs) and leverage the ArAlEval dataset, which encompasses two tasks: binary classification to determine the presence or absence of persuasion techniques, and multi-label classification to identify the specific types of techniques employed in the text. Our study explores three different learning approaches by harnessing the power of PLMs: feature extraction, fine-tuning, and prompt engineering techniques. Through extensive experimentation, we find that the fine-tuning approach yields the highest results on the aforementioned dataset, achieving an f1-micro score of 0.865 and an f1-weighted score of 0.861. Furthermore, our analysis sheds light on an interesting finding. While the performance of the GPT model is relatively lower compared to the other approaches, we have observed that by employing few-shot learning techniques, we can enhance its results by up to 20\%. This offers promising directions for future research and exploration in this topic\footnote{Upon Acceptance, the source code will be released on GitHub.}.
Cluster-Level Contrastive Learning for Emotion Recognition in Conversations
Feb 07, 2023A key challenge for Emotion Recognition in Conversations (ERC) is to distinguish semantically similar emotions. Some works utilise Supervised Contrastive Learning (SCL) which uses categorical emotion labels as supervision signals and contrasts in high-dimensional semantic space. However, categorical labels fail to provide quantitative information between emotions. ERC is also not equally dependent on all embedded features in the semantic space, which makes the high-dimensional SCL inefficient. To address these issues, we propose a novel low-dimensional Supervised Cluster-level Contrastive Learning (SCCL) method, which first reduces the high-dimensional SCL space to a three-dimensional affect representation space Valence-Arousal-Dominance (VAD), then performs cluster-level contrastive learning to incorporate measurable emotion prototypes. To help modelling the dialogue and enriching the context, we leverage the pre-trained knowledge adapters to infuse linguistic and factual knowledge. Experiments show that our method achieves new state-of-the-art results with 69.81% on IEMOCAP, 65.7% on MELD, and 62.51% on DailyDialog datasets. The analysis also proves that the VAD space is not only suitable for ERC but also interpretable, with VAD prototypes enhancing its performance and stabilising the training of SCCL. In addition, the pre-trained knowledge adapters benefit the performance of the utterance encoder and SCCL. Our code is available at: https://github.com/SteveKGYang/SCCL
SpanEmo: Casting Multi-label Emotion Classification as Span-prediction
Jan 25, 2021
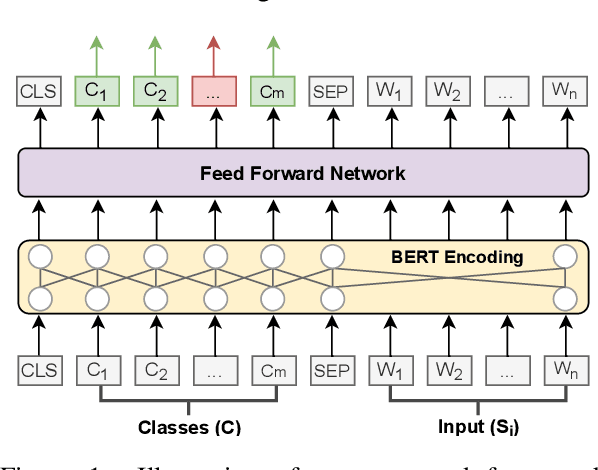
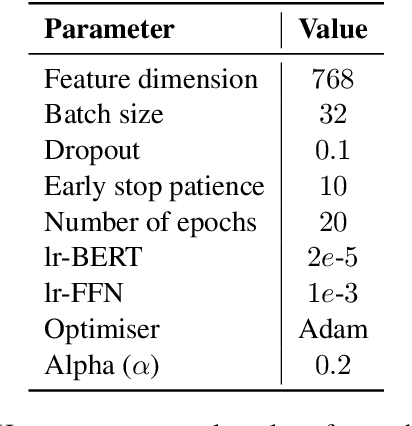
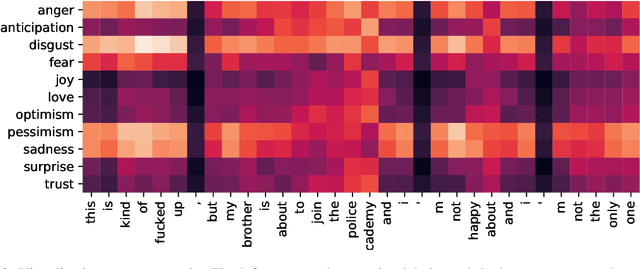
Emotion recognition (ER) is an important task in Natural Language Processing (NLP), due to its high impact in real-world applications from health and well-being to author profiling, consumer analysis and security. Current approaches to ER, mainly classify emotions independently without considering that emotions can co-exist. Such approaches overlook potential ambiguities, in which multiple emotions overlap. We propose a new model "SpanEmo" casting multi-label emotion classification as span-prediction, which can aid ER models to learn associations between labels and words in a sentence. Furthermore, we introduce a loss function focused on modelling multiple co-existing emotions in the input sentence. Experiments performed on the SemEval2018 multi-label emotion data over three language sets (i.e., English, Arabic and Spanish) demonstrate our method's effectiveness. Finally, we present different analyses that illustrate the benefits of our method in terms of improving the model performance and learning meaningful associations between emotion classes and words in the sentence.