 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRedefining Proactivity for Information Seeking Dialogue
Oct 20, 2024



Information-Seeking Dialogue (ISD) agents aim to provide accurate responses to user queries. While proficient in directly addressing user queries, these agents, as well as LLMs in general, predominantly exhibit reactive behavior, lacking the ability to generate proactive responses that actively engage users in sustained conversations. However, existing definitions of proactive dialogue in this context do not focus on how each response actively engages the user and sustains the conversation. Hence, we present a new definition of proactivity that focuses on enhancing the `proactiveness' of each generated response via the introduction of new information related to the initial query. To this end, we construct a proactive dialogue dataset comprising 2,000 single-turn conversations, and introduce several automatic metrics to evaluate response `proactiveness' which achieved high correlation with human annotation. Additionally, we introduce two innovative Chain-of-Thought (CoT) prompts, the 3-step CoT and the 3-in-1 CoT prompts, which consistently outperform standard prompts by up to 90% in the zero-shot setting.
Mitigating Bias for Question Answering Models by Tracking Bias Influence
Oct 13, 2023



Models of various NLP tasks have been shown to exhibit stereotypes, and the bias in the question answering (QA) models is especially harmful as the output answers might be directly consumed by the end users. There have been datasets to evaluate bias in QA models, while bias mitigation technique for the QA models is still under-explored. In this work, we propose BMBI, an approach to mitigate the bias of multiple-choice QA models. Based on the intuition that a model would lean to be more biased if it learns from a biased example, we measure the bias level of a query instance by observing its influence on another instance. If the influenced instance is more biased, we derive that the query instance is biased. We then use the bias level detected as an optimization objective to form a multi-task learning setting in addition to the original QA task. We further introduce a new bias evaluation metric to quantify bias in a comprehensive and sensitive way. We show that our method could be applied to multiple QA formulations across multiple bias categories. It can significantly reduce the bias level in all 9 bias categories in the BBQ dataset while maintaining comparable QA accuracy.
Parameter-Efficient Low-Resource Dialogue State Tracking by Prompt Tuning
Jan 26, 2023



Dialogue state tracking (DST) is an important step in dialogue management to keep track of users' beliefs. Existing works fine-tune all language model (LM) parameters to tackle the DST task, which requires significant data and computing resources for training and hosting. The cost grows exponentially in the real-world deployment where dozens of fine-tuned LM are used for different domains and tasks. To reduce parameter size and better utilize cross-task shared information, we propose to use soft prompt token embeddings to learn task properties. Without tuning LM parameters, our method drastically reduces the number of parameters needed to less than 0.5% of prior works while achieves better low-resource DST performance.
Style Control for Schema-Guided Natural Language Generation
Sep 24, 2021

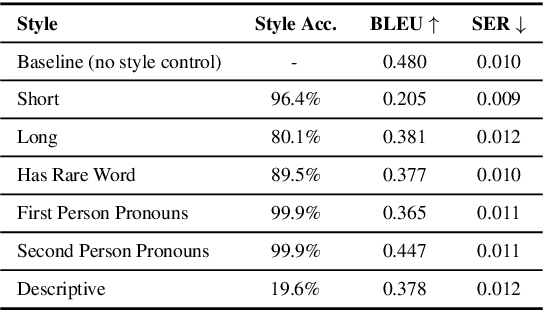

Natural Language Generation (NLG) for task-oriented dialogue systems focuses on communicating specific content accurately, fluently, and coherently. While these attributes are crucial for a successful dialogue, it is also desirable to simultaneously accomplish specific stylistic goals, such as response length, point-of-view, descriptiveness, sentiment, formality, and empathy. In this work, we focus on stylistic control and evaluation for schema-guided NLG, with joint goals of achieving both semantic and stylistic control. We experiment in detail with various controlled generation methods for large pretrained language models: specifically, conditional training, guided fine-tuning, and guided decoding. We discuss their advantages and limitations, and evaluate them with a broad range of automatic and human evaluation metrics. Our results show that while high style accuracy and semantic correctness are easier to achieve for more lexically-defined styles with conditional training, stylistic control is also achievable for more semantically complex styles using discriminator-based guided decoding methods. The results also suggest that methods that are more scalable (with less hyper-parameters tuning) and that disentangle content generation and stylistic variations are more effective at achieving semantic correctness and style accuracy.
Alexa Conversations: An Extensible Data-driven Approach for Building Task-oriented Dialogue Systems
Apr 19, 2021
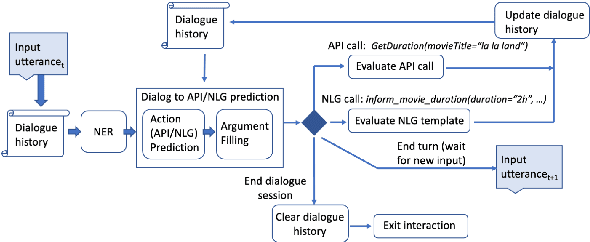

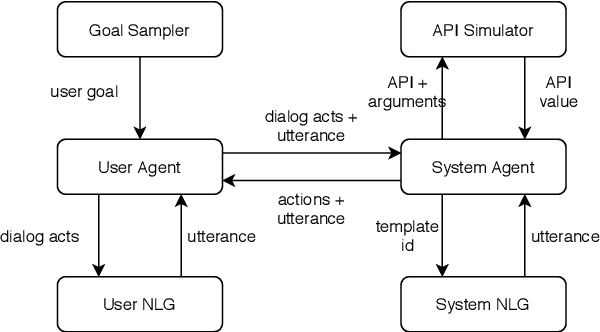
Traditional goal-oriented dialogue systems rely on various components such as natural language understanding, dialogue state tracking, policy learning and response generation. Training each component requires annotations which are hard to obtain for every new domain, limiting scalability of such systems. Similarly, rule-based dialogue systems require extensive writing and maintenance of rules and do not scale either. End-to-End dialogue systems, on the other hand, do not require module-specific annotations but need a large amount of data for training. To overcome these problems, in this demo, we present Alexa Conversations, a new approach for building goal-oriented dialogue systems that is scalable, extensible as well as data efficient. The components of this system are trained in a data-driven manner, but instead of collecting annotated conversations for training, we generate them using a novel dialogue simulator based on a few seed dialogues and specifications of APIs and entities provided by the developer. Our approach provides out-of-the-box support for natural conversational phenomena like entity sharing across turns or users changing their mind during conversation without requiring developers to provide any such dialogue flows. We exemplify our approach using a simple pizza ordering task and showcase its value in reducing the developer burden for creating a robust experience. Finally, we evaluate our system using a typical movie ticket booking task and show that the dialogue simulator is an essential component of the system that leads to over $50\%$ improvement in turn-level action signature prediction accuracy.
MMM: Multi-stage Multi-task Learning for Multi-choice Reading Comprehension
Oct 01, 2019
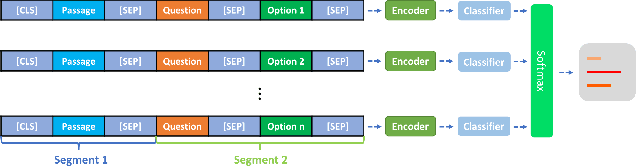
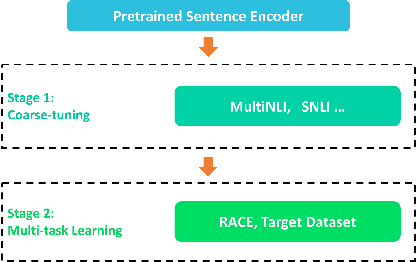

Machine Reading Comprehension (MRC) for question answering (QA), which aims to answer a question given the relevant context passages, is an important way to test the ability of intelligence systems to understand human language. Multiple-Choice QA (MCQA) is one of the most difficult tasks in MRC because it often requires more advanced reading comprehension skills such as logical reasoning, summarization, and arithmetic operations, compared to the extractive counterpart where answers are usually spans of text within given passages. Moreover, most existing MCQA datasets are small in size, making the learning task even harder. We introduce MMM, a Multi-stage Multi-task learning framework for Multi-choice reading comprehension. Our method involves two sequential stages: coarse-tuning stage using out-of-domain datasets and multi-task learning stage using a larger in-domain dataset to help model generalize better with limited data. Furthermore, we propose a novel multi-step attention network (MAN) as the top-level classifier for this task. We demonstrate MMM significantly advances the state-of-the-art on four representative MCQA datasets.