 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
CRIN: Rotation-Invariant Point Cloud Analysis and Rotation Estimation via Centrifugal Reference Frame
Mar 06, 2023
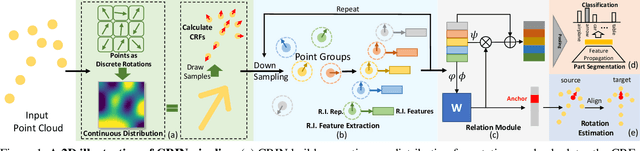
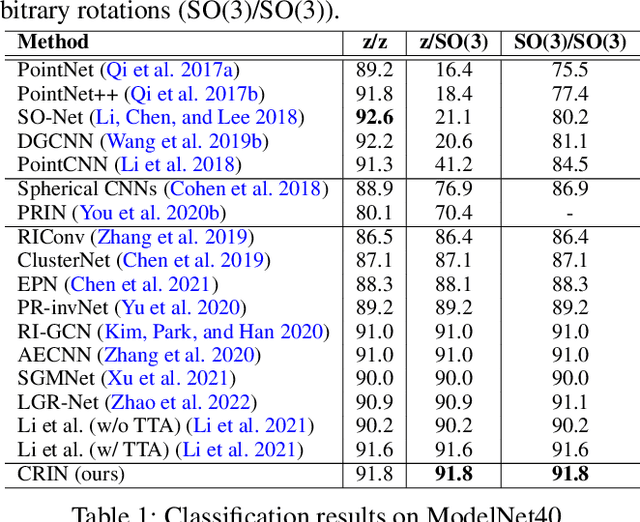
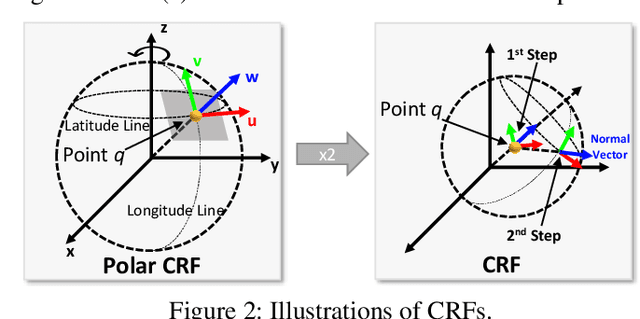
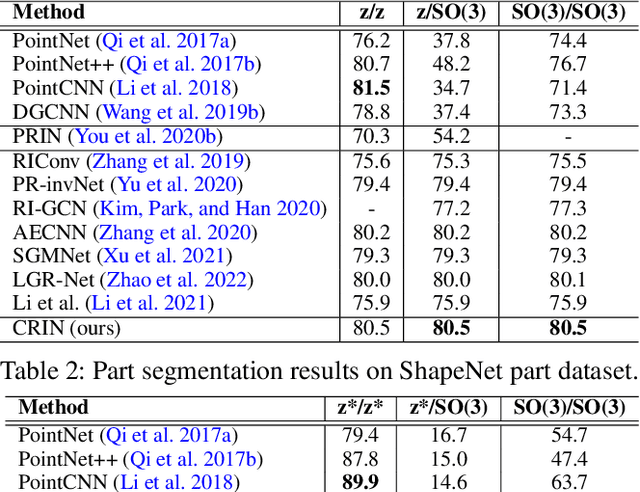
Various recent methods attempt to implement rotation-invariant 3D deep learning by replacing the input coordinates of points with relative distances and angles. Due to the incompleteness of these low-level features, they have to undertake the expense of losing global information. In this paper, we propose the CRIN, namely Centrifugal Rotation-Invariant Network. CRIN directly takes the coordinates of points as input and transforms local points into rotation-invariant representations via centrifugal reference frames. Aided by centrifugal reference frames, each point corresponds to a discrete rotation so that the information of rotations can be implicitly stored in point features. Unfortunately, discrete points are far from describing the whole rotation space. We further introduce a continuous distribution for 3D rotations based on points. Furthermore, we propose an attention-based down-sampling strategy to sample points invariant to rotations. A relation module is adopted at last for reinforcing the long-range dependencies between sampled points and predicts the anchor point for unsupervised rotation estimation. Extensive experiments show that our method achieves rotation invariance, accurately estimates the object rotation, and obtains state-of-the-art results on rotation-augmented classification and part segmentation. Ablation studies validate the effectiveness of the network design.
Graph-based View Motion Planning for Fruit Detection
Mar 06, 2023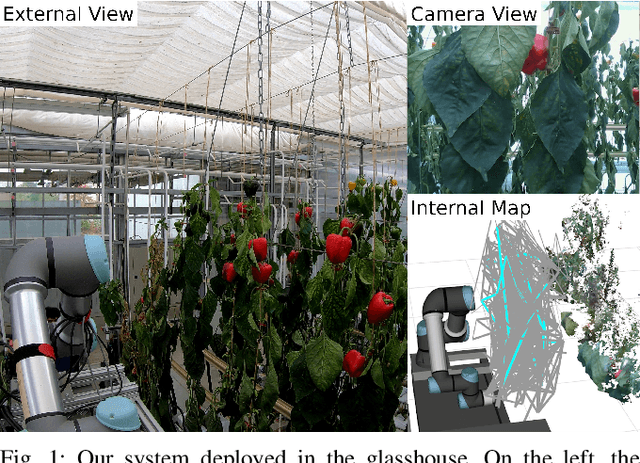
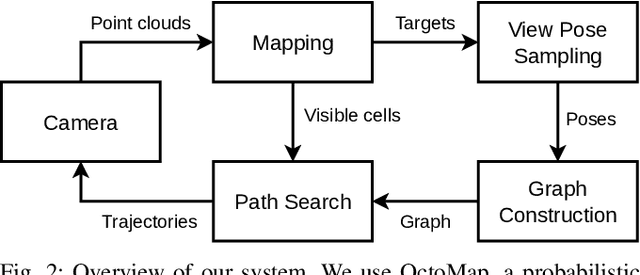
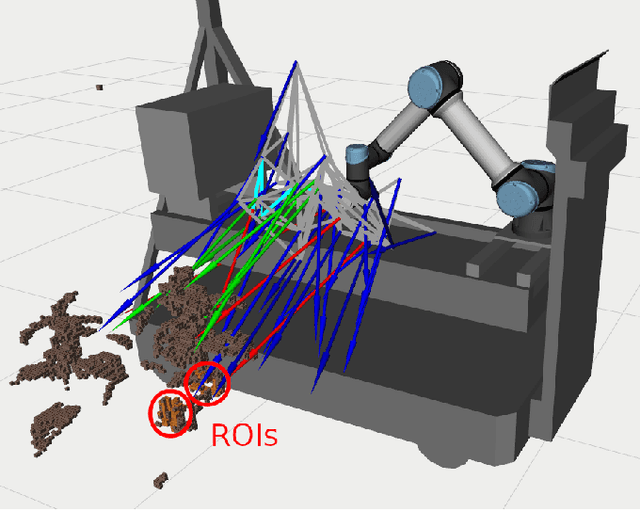
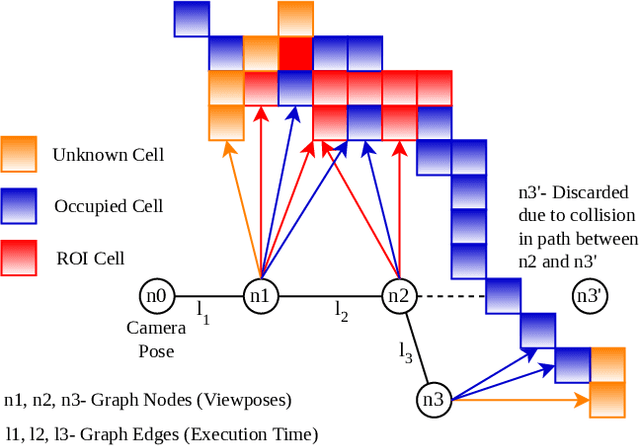
Crop monitoring is crucial for maximizing agricultural productivity and efficiency. However, monitoring large and complex structures such as sweet pepper plants presents significant challenges, especially due to frequent occlusions of the fruits. Traditional next-best view planning can lead to unstructured and inefficient coverage of the crops. To address this, we propose a novel view motion planner that builds a graph network of viable view poses and trajectories between nearby poses, thereby considering robot motion constraints. The planner searches the graphs for view sequences with the highest accumulated information gain, allowing for efficient pepper plant monitoring while minimizing occlusions. The generated view poses aim at both sufficiently covering already detected and discovering new fruits. The graph and the corresponding best view pose sequence are computed with a limited horizon and are adaptively updated in fixed time intervals as the system gathers new information. We demonstrate the effectiveness of our approach through simulated and real-world experiments using a robotic arm equipped with an RGB-D camera and mounted on a trolley. As the experimental results show, our planner produces view pose sequences to systematically cover the crops and leads to increased fruit coverage when given a limited time in comparison to a state-of-the-art single next-best view planner.
DEDGAT: Dual Embedding of Directed Graph Attention Networks for Detecting Financial Risk
Mar 06, 2023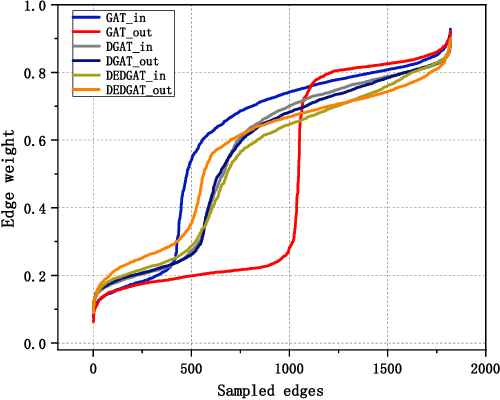
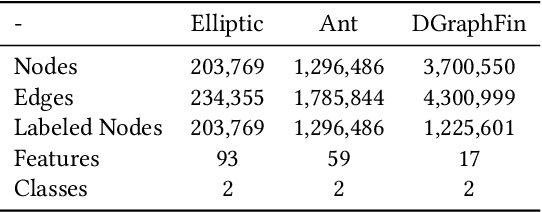
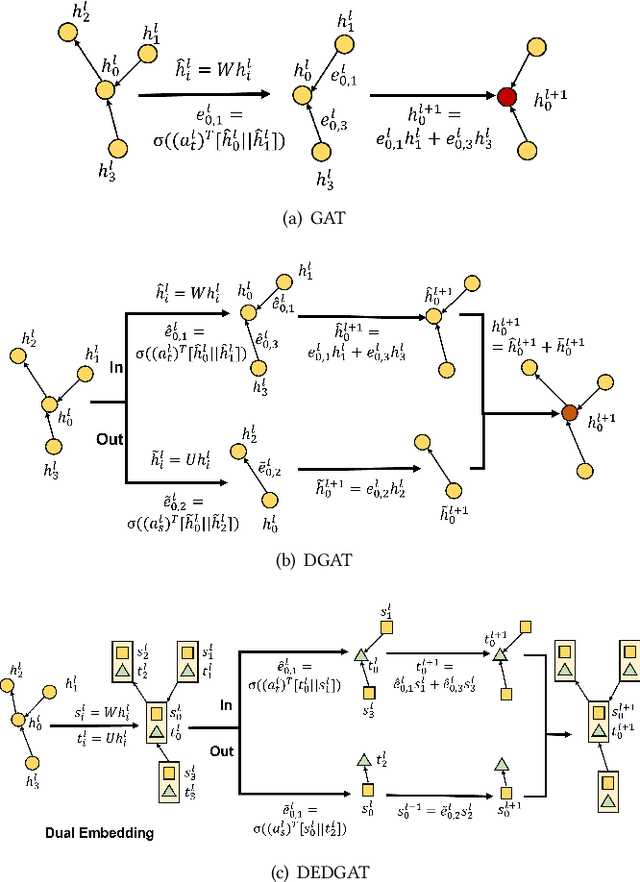
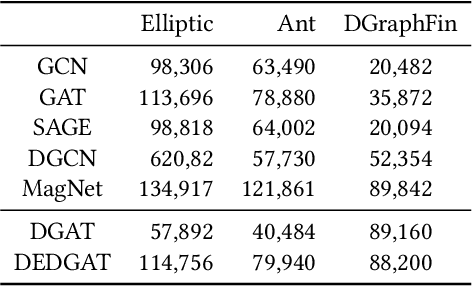
Graph representation plays an important role in the field of financial risk control, where the relationship among users can be constructed in a graph manner. In practical scenarios, the relationships between nodes in risk control tasks are bidirectional, e.g., merchants having both revenue and expense behaviors. Graph neural networks designed for undirected graphs usually aggregate discriminative node or edge representations with an attention strategy, but cannot fully exploit the out-degree information when used for the tasks built on directed graph, which leads to the problem of a directional bias. To tackle this problem, we propose a Directed Graph ATtention network called DGAT, which explicitly takes out-degree into attention calculation. In addition to having directional requirements, the same node might have different representations of its input and output, and thus we further propose a dual embedding of DGAT, referred to as DEDGAT. Specifically, DEDGAT assigns in-degree and out-degree representations to each node and uses these two embeddings to calculate the attention weights of in-degree and out-degree nodes, respectively. Experiments performed on the benchmark datasets show that DGAT and DEDGAT obtain better classification performance compared to undirected GAT. Also,the visualization results demonstrate that our methods can fully use both in-degree and out-degree information.
Dual-Attention Model for Aspect-Level Sentiment Classification
Mar 14, 2023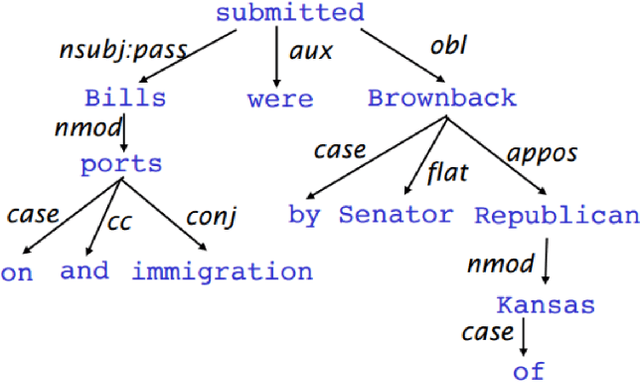
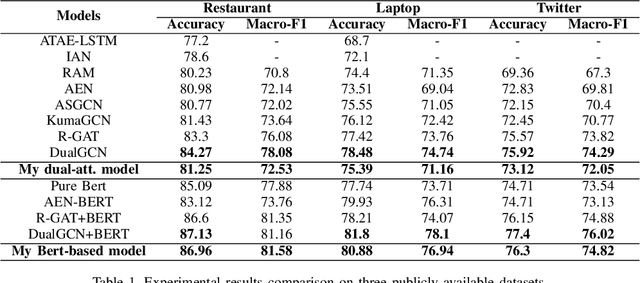
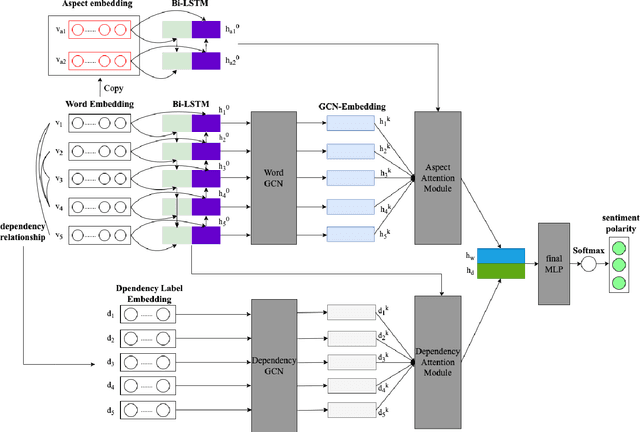

I propose a novel dual-attention model(DAM) for aspect-level sentiment classification. Many methods have been proposed, such as support vector machines for artificial design features, long short-term memory networks based on attention mechanisms, and graph neural networks based on dependency parsing. While these methods all have decent performance, I think they all miss one important piece of syntactic information: dependency labels. Based on this idea, this paper proposes a model using dependency labels for the attention mechanism to do this task. We evaluate the proposed approach on three datasets: laptop and restaurant are from SemEval 2014, and the last one is a twitter dataset. Experimental results show that the dual attention model has good performance on all three datasets.
Evaluation of Automatically Constructed Word Meaning Explanations
Feb 27, 2023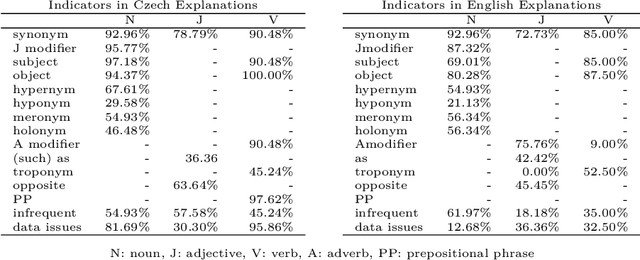

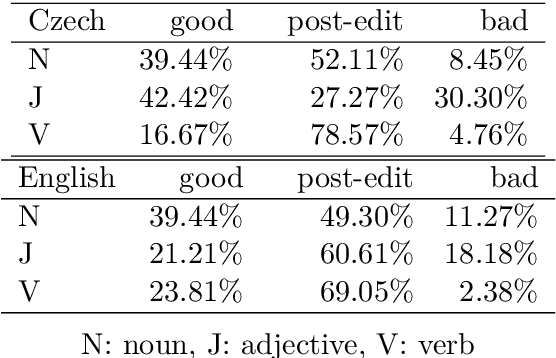

Preparing exact and comprehensive word meaning explanations is one of the key steps in the process of monolingual dictionary writing. In standard methodology, the explanations need an expert lexicographer who spends a substantial amount of time checking the consistency between the descriptive text and corpus evidence. In the following text, we present a new tool that derives explanations automatically based on collective information from very large corpora, particularly on word sketches. We also propose a quantitative evaluation of the constructed explanations, concentrating on explanations of nouns. The methodology is to a certain extent language independent; however, the presented verification is limited to Czech and English. We show that the presented approach allows to create explanations that contain data useful for understanding the word meaning in approximately 90% of cases. However, in many cases, the result requires post-editing to remove redundant information.
* preprint of a chapter published by College Publications at https://www.collegepublications.co.uk/tributes/?00049
Hyneter: Hybrid Network Transformer for Object Detection
Feb 18, 2023
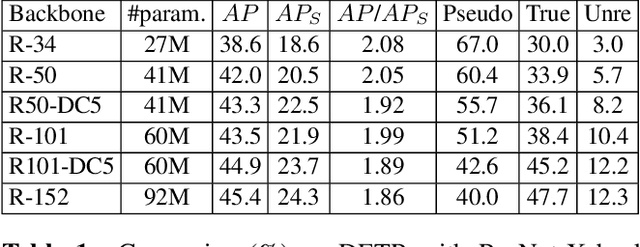
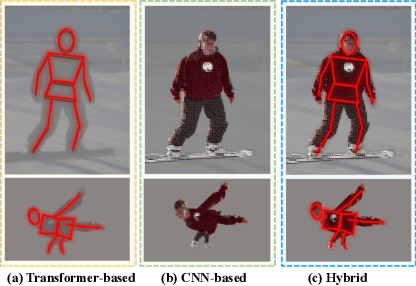
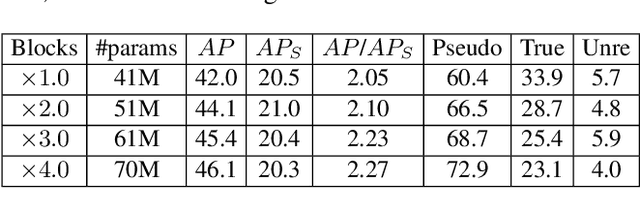
In this paper, we point out that the essential differences between CNN-based and Transformer-based detectors, which cause the worse performance of small objects in Transformer-based methods, are the gap between local information and global dependencies in feature extraction and propagation. To address these differences, we propose a new vision Transformer, called Hybrid Network Transformer (Hyneter), after pre-experiments that indicate the gap causes CNN-based and Transformer-based methods to increase size-different objects result unevenly. Different from the divide and conquer strategy in previous methods, Hyneters consist of Hybrid Network Backbone (HNB) and Dual Switching module (DS), which integrate local information and global dependencies, and transfer them simultaneously. Based on the balance strategy, HNB extends the range of local information by embedding convolution layers into Transformer blocks, and DS adjusts excessive reliance on global dependencies outside the patch.
A large-scale multimodal dataset of human speech recognition
Mar 15, 2023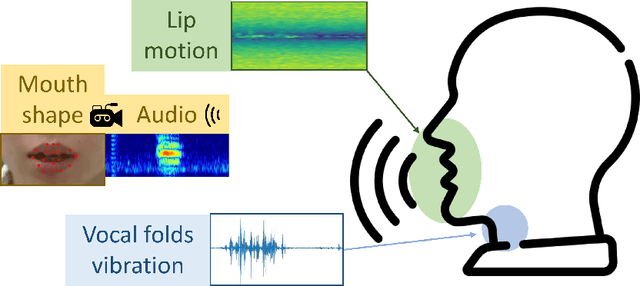

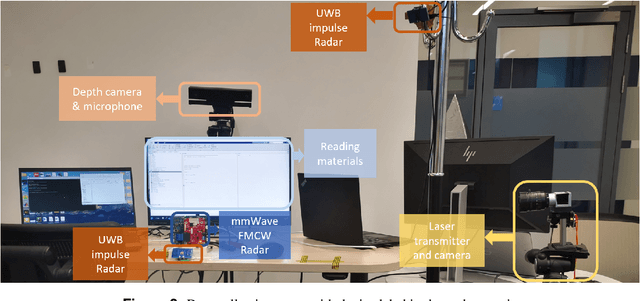
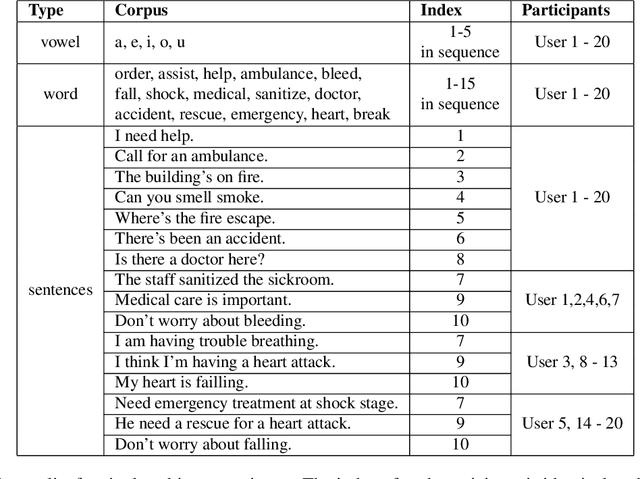
Nowadays, non-privacy small-scale motion detection has attracted an increasing amount of research in remote sensing in speech recognition. These new modalities are employed to enhance and restore speech information from speakers of multiple types of data. In this paper, we propose a dataset contains 7.5 GHz Channel Impulse Response (CIR) data from ultra-wideband (UWB) radars, 77-GHz frequency modulated continuous wave (FMCW) data from millimetre wave (mmWave) radar, and laser data. Meanwhile, a depth camera is adopted to record the landmarks of the subject's lip and voice. Approximately 400 minutes of annotated speech profiles are provided, which are collected from 20 participants speaking 5 vowels, 15 words and 16 sentences. The dataset has been validated and has potential for the research of lip reading and multimodal speech recognition.
ABC: Attention with Bilinear Correlation for Infrared Small Target Detection
Mar 18, 2023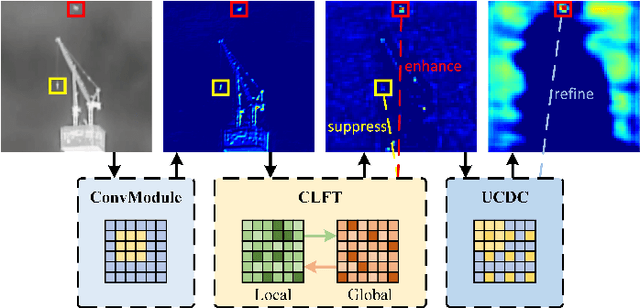
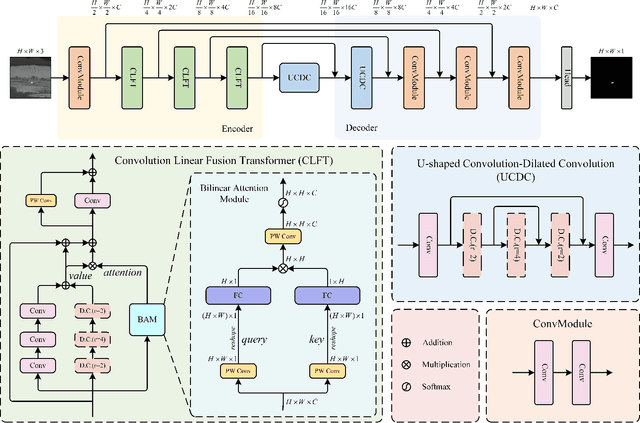
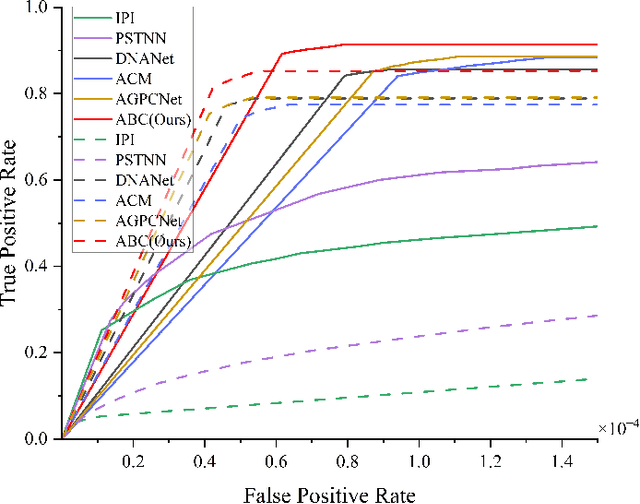
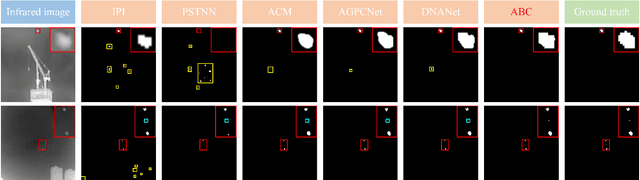
Infrared small target detection (ISTD) has a wide range of applications in early warning, rescue, and guidance. However, CNN based deep learning methods are not effective at segmenting infrared small target (IRST) that it lack of clear contour and texture features, and transformer based methods also struggle to achieve significant results due to the absence of convolution induction bias. To address these issues, we propose a new model called attention with bilinear correlation (ABC), which is based on the transformer architecture and includes a convolution linear fusion transformer (CLFT) module with a novel attention mechanism for feature extraction and fusion, which effectively enhances target features and suppresses noise. Additionally, our model includes a u-shaped convolution-dilated convolution (UCDC) module located deeper layers of the network, which takes advantage of the smaller resolution of deeper features to obtain finer semantic information. Experimental results on public datasets demonstrate that our approach achieves state-of-the-art performance. Code is available at https://github.com/PANPEIWEN/ABC
Stop Words for Processing Software Engineering Documents: Do they Matter?
Mar 18, 2023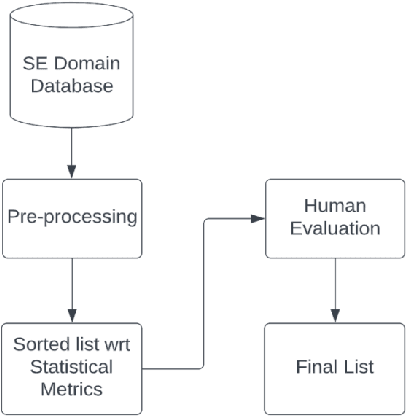
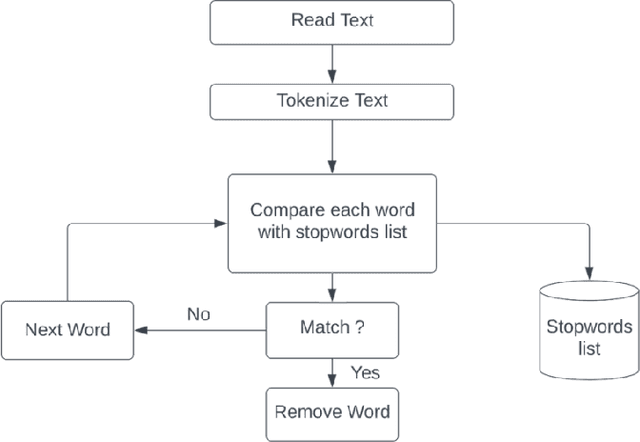

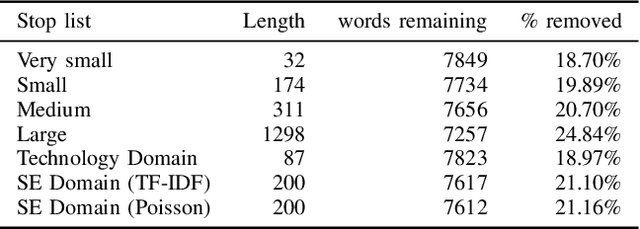
Stop words, which are considered non-predictive, are often eliminated in natural language processing tasks. However, the definition of uninformative vocabulary is vague, so most algorithms use general knowledge-based stop lists to remove stop words. There is an ongoing debate among academics about the usefulness of stop word elimination, especially in domain-specific settings. In this work, we investigate the usefulness of stop word removal in a software engineering context. To do this, we replicate and experiment with three software engineering research tools from related work. Additionally, we construct a corpus of software engineering domain-related text from 10,000 Stack Overflow questions and identify 200 domain-specific stop words using traditional information-theoretic methods. Our results show that the use of domain-specific stop words significantly improved the performance of research tools compared to the use of a general stop list and that 17 out of 19 evaluation measures showed better performance.
Position-Guided Point Cloud Panoptic Segmentation Transformer
Mar 23, 2023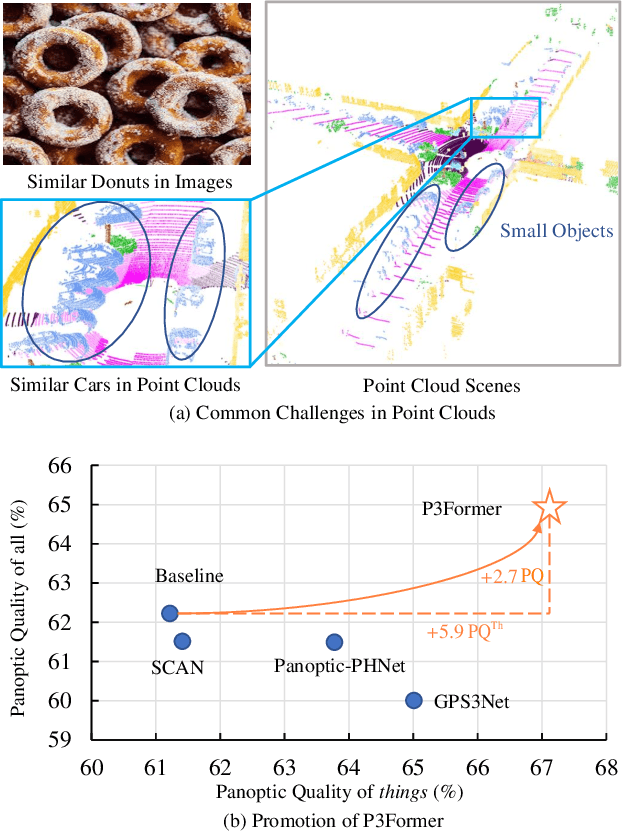
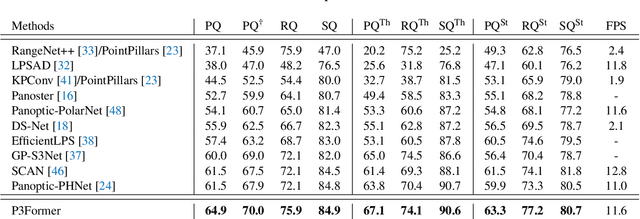
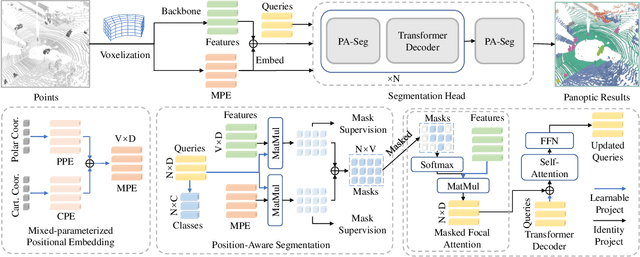
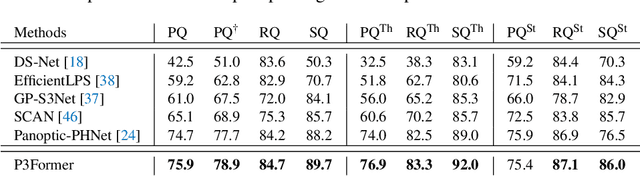
DEtection TRansformer (DETR) started a trend that uses a group of learnable queries for unified visual perception. This work begins by applying this appealing paradigm to LiDAR-based point cloud segmentation and obtains a simple yet effective baseline. Although the naive adaptation obtains fair results, the instance segmentation performance is noticeably inferior to previous works. By diving into the details, we observe that instances in the sparse point clouds are relatively small to the whole scene and often have similar geometry but lack distinctive appearance for segmentation, which are rare in the image domain. Considering instances in 3D are more featured by their positional information, we emphasize their roles during the modeling and design a robust Mixed-parameterized Positional Embedding (MPE) to guide the segmentation process. It is embedded into backbone features and later guides the mask prediction and query update processes iteratively, leading to Position-Aware Segmentation (PA-Seg) and Masked Focal Attention (MFA). All these designs impel the queries to attend to specific regions and identify various instances. The method, named Position-guided Point cloud Panoptic segmentation transFormer (P3Former), outperforms previous state-of-the-art methods by 3.4% and 1.2% PQ on SemanticKITTI and nuScenes benchmark, respectively. The source code and models are available at https://github.com/SmartBot-PJLab/P3Former .