 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Deepfake Detection, NTIRE 2026 Challenge: Report
Apr 27, 2026Robustness is a long-overlooked problem in deepfake detection. However, detection performance is nearly worthless in the real world if it suffers under exposure to even slight image degradation. In addition to weaker degradations that can accidentally occur in the image processing pipeline, there is another risk of malicious deepfakes that specifically introduce degradations, purposefully exploiting the detector's weaknesses in that regard. Here, we present an overview of the NTIRE 2026 Robust Deepfake Detection Challenge, which specifically addresses that problem. Participants were tasked with building a detector that would later be tested on an unknown test-set, which included both common and uncommon degradations of various strengths. With a total number of 337 participants and 57 submissions to the final leaderboard, the first edition of the challenge was well received. To ensure the reliability of the results, participants were given only 24h to complete the test run with no labels provided, limiting the possibility of training on the test data. Furthermore, the top solutions were scored on a private test-set to detect any such overfitting. This report presents the competition setting, dataset preparation, as well as details and performance of methods. Top methods rely on large foundation models, ensembles, and degradation training to combine generality and robustness.
NTIRE 2026 Challenge on Robust AI-Generated Image Detection in the Wild
Apr 13, 2026This paper presents an overview of the NTIRE 2026 Challenge on Robust AI-Generated Image Detection in the Wild, held in conjunction with the NTIRE workshop at CVPR 2026. The goal of this challenge was to develop detection models capable of distinguishing real images from generated ones in realistic scenarios: the images are often transformed (cropped, resized, compressed, blurred) for practical usage, and therefore, the detection models should be robust to such transformations. The challenge is based on a novel dataset consisting of 108,750 real and 185,750 AI-generated images from 42 generators comprising a large variety of open-source and closed-source models of various architectures, augmented with 36 image transformations. Methods were evaluated using ROC AUC on the full test set, including both transformed and untransformed images. A total of 511 participants registered, with 20 teams submitting valid final solutions. This report provides a comprehensive overview of the challenge, describes the proposed solutions, and can be used as a valuable reference for researchers and practitioners in increasing the robustness of the detection models to real-world transformations.
LOGER: Local--Global Ensemble for Robust Deepfake Detection in the Wild
Apr 04, 2026Robust deepfake detection in the wild remains challenging due to the ever-growing variety of manipulation techniques and uncontrolled real-world degradations. Forensic cues for deepfake detection reside at two complementary levels: global-level anomalies in semantics and statistics that require holistic image understanding, and local-level forgery traces concentrated in manipulated regions that are easily diluted by global averaging. Since no single backbone or input scale can effectively cover both levels, we propose LOGER, a LOcal--Global Ensemble framework for Robust deepfake detection. The global branch employs heterogeneous vision foundation model backbones at multiple resolutions to capture holistic anomalies with diverse visual priors. The local branch performs patch-level modeling with a Multiple Instance Learning top-$k$ aggregation strategy that selectively pools only the most suspicious regions, mitigating evidence dilution caused by the dominance of normal patches; dual-level supervision at both the aggregated image level and individual patch level keeps local responses discriminative. Because the two branches differ in both granularity and backbone, their errors are largely decorrelated, a property that logit-space fusion exploits for more robust prediction. LOGER achieves 2nd place in the NTIRE 2026 Robust Deepfake Detection Challenge, and further evaluation on multiple public benchmarks confirms its strong robustness and generalization across diverse manipulation methods and real-world degradation conditions.
HEDGE: Heterogeneous Ensemble for Detection of AI-GEnerated Images in the Wild
Apr 04, 2026Robust detection of AI-generated images in the wild remains challenging due to the rapid evolution of generative models and varied real-world distortions. We argue that relying on a single training regime, resolution, or backbone is insufficient to handle all conditions, and that structured heterogeneity across these dimensions is essential for robust detection. To this end, we propose HEDGE, a Heterogeneous Ensemble for Detection of AI-GEnerated images, that introduces complementary detection routes along three axes: diverse training data with strong augmentation, multi-scale feature extraction, and backbone heterogeneity. Specifically, Route~A progressively constructs DINOv3-based detectors through staged data expansion and augmentation escalation, Route~B incorporates a higher-resolution branch for fine-grained forensic cues, and Route~C adds a MetaCLIP2-based branch for backbone diversity. All outputs are fused via logit-space weighted averaging, refined by a lightweight dual-gating mechanism that handles branch-level outliers and majority-dominated fusion errors. HEDGE achieves 4th place in the NTIRE 2026 Robust AI-Generated Image Detection in the Wild Challenge and attains state-of-the-art performance with strong robustness on multiple AIGC image detection benchmarks.
GraphTEN: Graph Enhanced Texture Encoding Network
Mar 18, 2025



Texture recognition is a fundamental problem in computer vision and pattern recognition. Recent progress leverages feature aggregation into discriminative descriptions based on convolutional neural networks (CNNs). However, modeling non-local context relations through visual primitives remains challenging due to the variability and randomness of texture primitives in spatial distributions. In this paper, we propose a graph-enhanced texture encoding network (GraphTEN) designed to capture both local and global features of texture primitives. GraphTEN models global associations through fully connected graphs and captures cross-scale dependencies of texture primitives via bipartite graphs. Additionally, we introduce a patch encoding module that utilizes a codebook to achieve an orderless representation of texture by encoding multi-scale patch features into a unified feature space. The proposed GraphTEN achieves superior performance compared to state-of-the-art methods across five publicly available datasets.
VI3DRM:Towards meticulous 3D Reconstruction from Sparse Views via Photo-Realistic Novel View Synthesis
Sep 12, 2024



Recently, methods like Zero-1-2-3 have focused on single-view based 3D reconstruction and have achieved remarkable success. However, their predictions for unseen areas heavily rely on the inductive bias of large-scale pretrained diffusion models. Although subsequent work, such as DreamComposer, attempts to make predictions more controllable by incorporating additional views, the results remain unrealistic due to feature entanglement in the vanilla latent space, including factors such as lighting, material, and structure. To address these issues, we introduce the Visual Isotropy 3D Reconstruction Model (VI3DRM), a diffusion-based sparse views 3D reconstruction model that operates within an ID consistent and perspective-disentangled 3D latent space. By facilitating the disentanglement of semantic information, color, material properties and lighting, VI3DRM is capable of generating highly realistic images that are indistinguishable from real photographs. By leveraging both real and synthesized images, our approach enables the accurate construction of pointmaps, ultimately producing finely textured meshes or point clouds. On the NVS task, tested on the GSO dataset, VI3DRM significantly outperforms state-of-the-art method DreamComposer, achieving a PSNR of 38.61, an SSIM of 0.929, and an LPIPS of 0.027. Code will be made available upon publication.
Effective Motion Modeling for UAV-platform Multiple Object Tracking with Re-Margin Loss
Jul 15, 2024



Multiple object tracking (MOT) from unmanned aerial vehicle (UAV) platforms requires efficient motion modeling. This is because UAV-MOT faces tracking difficulties caused by large and irregular motion, and insufficient training due to the motion long-tailed distribution of current UAV-MOT datasets. Previous UAV-MOT methods either extract motion and detection features redundantly or supervise motion model in a sparse scheme, which limited their tracking performance and speed. To this end, we propose a flowing-by-detection module to realize accurate motion modeling with a minimum cost. Focusing on the motion long-tailed problem that were ignored by previous works, the flow-guided margin loss is designed to enable more complete training of large moving objects. Experiments on two widely open-source datasets show that our proposed model can successfully track objects with large and irregular motion and outperform existing state-of-the-art methods in UAV-MOT tasks.
FOLT: Fast Multiple Object Tracking from UAV-captured Videos Based on Optical Flow
Aug 15, 2023Multiple object tracking (MOT) has been successfully investigated in computer vision. However, MOT for the videos captured by unmanned aerial vehicles (UAV) is still challenging due to small object size, blurred object appearance, and very large and/or irregular motion in both ground objects and UAV platforms. In this paper, we propose FOLT to mitigate these problems and reach fast and accurate MOT in UAV view. Aiming at speed-accuracy trade-off, FOLT adopts a modern detector and light-weight optical flow extractor to extract object detection features and motion features at a minimum cost. Given the extracted flow, the flow-guided feature augmentation is designed to augment the object detection feature based on its optical flow, which improves the detection of small objects. Then the flow-guided motion prediction is also proposed to predict the object's position in the next frame, which improves the tracking performance of objects with very large displacements between adjacent frames. Finally, the tracker matches the detected objects and predicted objects using a spatially matching scheme to generate tracks for every object. Experiments on Visdrone and UAVDT datasets show that our proposed model can successfully track small objects with large and irregular motion and outperform existing state-of-the-art methods in UAV-MOT tasks.
DEDGAT: Dual Embedding of Directed Graph Attention Networks for Detecting Financial Risk
Mar 06, 2023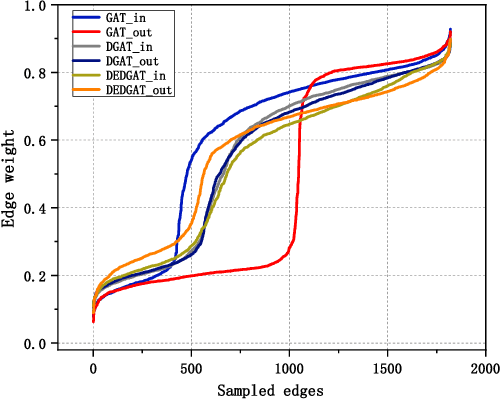
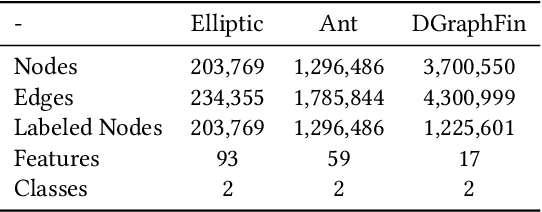
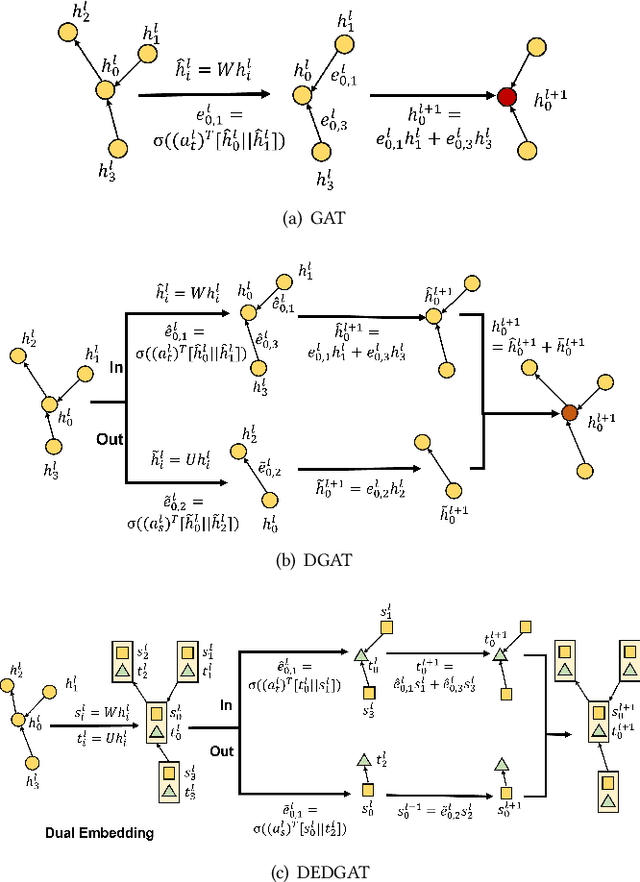
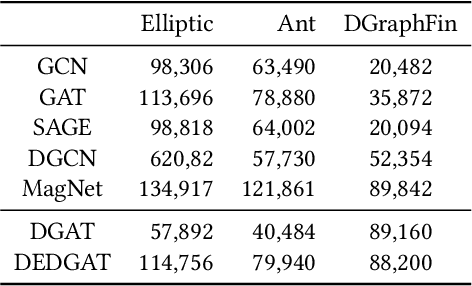
Graph representation plays an important role in the field of financial risk control, where the relationship among users can be constructed in a graph manner. In practical scenarios, the relationships between nodes in risk control tasks are bidirectional, e.g., merchants having both revenue and expense behaviors. Graph neural networks designed for undirected graphs usually aggregate discriminative node or edge representations with an attention strategy, but cannot fully exploit the out-degree information when used for the tasks built on directed graph, which leads to the problem of a directional bias. To tackle this problem, we propose a Directed Graph ATtention network called DGAT, which explicitly takes out-degree into attention calculation. In addition to having directional requirements, the same node might have different representations of its input and output, and thus we further propose a dual embedding of DGAT, referred to as DEDGAT. Specifically, DEDGAT assigns in-degree and out-degree representations to each node and uses these two embeddings to calculate the attention weights of in-degree and out-degree nodes, respectively. Experiments performed on the benchmark datasets show that DGAT and DEDGAT obtain better classification performance compared to undirected GAT. Also,the visualization results demonstrate that our methods can fully use both in-degree and out-degree information.