 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Exposure Fusion for Hand-held Camera Inputs with Optical Flow and PatchMatch
Apr 10, 2023




This paper proposes a hybrid synthesis method for multi-exposure image fusion taken by hand-held cameras. Motions either due to the shaky camera or caused by dynamic scenes should be compensated before any content fusion. Any misalignment can easily cause blurring/ghosting artifacts in the fused result. Our hybrid method can deal with such motions and maintain the exposure information of each input effectively. In particular, the proposed method first applies optical flow for a coarse registration, which performs well with complex non-rigid motion but produces deformations at regions with missing correspondences. The absence of correspondences is due to the occlusions of scene parallax or the moving contents. To correct such error registration, we segment images into superpixels and identify problematic alignments based on each superpixel, which is further aligned by PatchMatch. The method combines the efficiency of optical flow and the accuracy of PatchMatch. After PatchMatch correction, we obtain a fully aligned image stack that facilitates a high-quality fusion that is free from blurring/ghosting artifacts. We compare our method with existing fusion algorithms on various challenging examples, including the static/dynamic, the indoor/outdoor and the daytime/nighttime scenes. Experiment results demonstrate the effectiveness and robustness of our method.
Graph Attention for Automated Audio Captioning
Apr 10, 2023
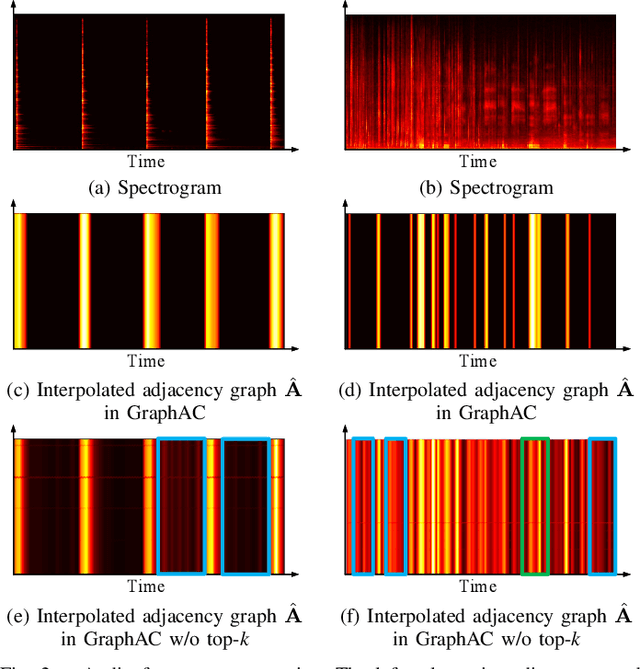

State-of-the-art audio captioning methods typically use the encoder-decoder structure with pretrained audio neural networks (PANNs) as encoders for feature extraction. However, the convolution operation used in PANNs is limited in capturing the long-time dependencies within an audio signal, thereby leading to potential performance degradation in audio captioning. This letter presents a novel method using graph attention (GraphAC) for encoder-decoder based audio captioning. In the encoder, a graph attention module is introduced after the PANNs to learn contextual association (i.e. the dependency among the audio features over different time frames) through an adjacency graph, and a top-k mask is used to mitigate the interference from noisy nodes. The learnt contextual association leads to a more effective feature representation with feature node aggregation. As a result, the decoder can predict important semantic information about the acoustic scene and events based on the contextual associations learned from the audio signal. Experimental results show that GraphAC outperforms the state-of-the-art methods with PANNs as the encoders, thanks to the incorporation of the graph attention module into the encoder for capturing the long-time dependencies within the audio signal. The source code is available at https://github.com/LittleFlyingSheep/GraphAC.
FairGen: Towards Fair Graph Generation
Mar 30, 2023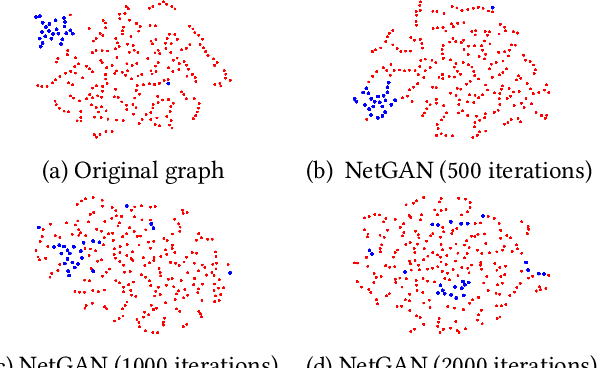
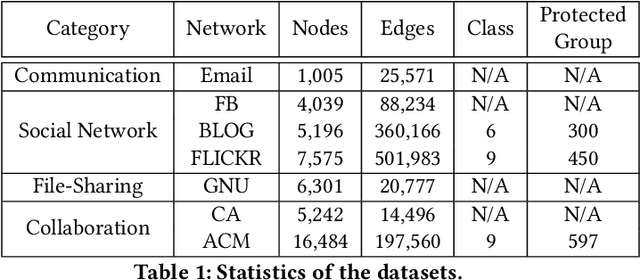
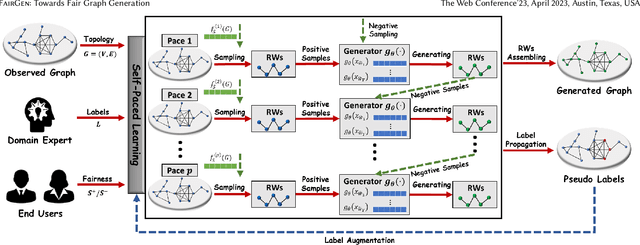
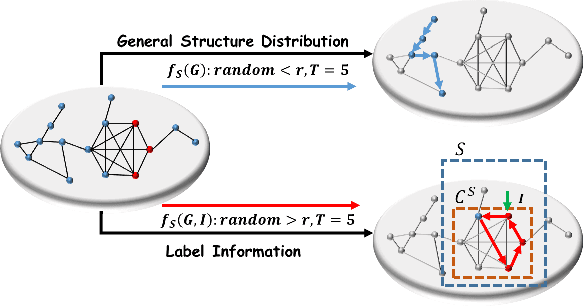
There have been tremendous efforts over the past decades dedicated to the generation of realistic graphs in a variety of domains, ranging from social networks to computer networks, from gene regulatory networks to online transaction networks. Despite the remarkable success, the vast majority of these works are unsupervised in nature and are typically trained to minimize the expected graph reconstruction loss, which would result in the representation disparity issue in the generated graphs, i.e., the protected groups (often minorities) contribute less to the objective and thus suffer from systematically higher errors. In this paper, we aim to tailor graph generation to downstream mining tasks by leveraging label information and user-preferred parity constraint. In particular, we start from the investigation of representation disparity in the context of graph generative models. To mitigate the disparity, we propose a fairness-aware graph generative model named FairGen. Our model jointly trains a label-informed graph generation module and a fair representation learning module by progressively learning the behaviors of the protected and unprotected groups, from the `easy' concepts to the `hard' ones. In addition, we propose a generic context sampling strategy for graph generative models, which is proven to be capable of fairly capturing the contextual information of each group with a high probability. Experimental results on seven real-world data sets, including web-based graphs, demonstrate that FairGen (1) obtains performance on par with state-of-the-art graph generative models across six network properties, (2) mitigates the representation disparity issues in the generated graphs, and (3) substantially boosts the model performance by up to 17% in downstream tasks via data augmentation.
Making Vision Transformers Efficient from A Token Sparsification View
Mar 30, 2023
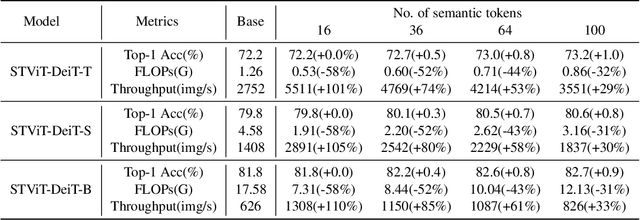
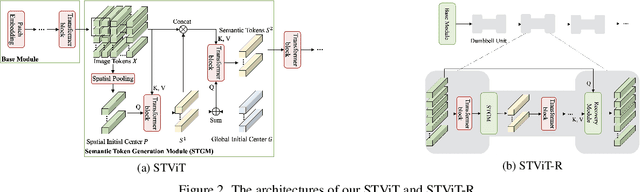
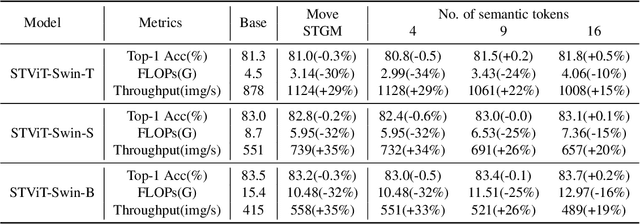
The quadratic computational complexity to the number of tokens limits the practical applications of Vision Transformers (ViTs). Several works propose to prune redundant tokens to achieve efficient ViTs. However, these methods generally suffer from (i) dramatic accuracy drops, (ii) application difficulty in the local vision transformer, and (iii) non-general-purpose networks for downstream tasks. In this work, we propose a novel Semantic Token ViT (STViT), for efficient global and local vision transformers, which can also be revised to serve as backbone for downstream tasks. The semantic tokens represent cluster centers, and they are initialized by pooling image tokens in space and recovered by attention, which can adaptively represent global or local semantic information. Due to the cluster properties, a few semantic tokens can attain the same effect as vast image tokens, for both global and local vision transformers. For instance, only 16 semantic tokens on DeiT-(Tiny,Small,Base) can achieve the same accuracy with more than 100% inference speed improvement and nearly 60% FLOPs reduction; on Swin-(Tiny,Small,Base), we can employ 16 semantic tokens in each window to further speed it up by around 20% with slight accuracy increase. Besides great success in image classification, we also extend our method to video recognition. In addition, we design a STViT-R(ecover) network to restore the detailed spatial information based on the STViT, making it work for downstream tasks, which is powerless for previous token sparsification methods. Experiments demonstrate that our method can achieve competitive results compared to the original networks in object detection and instance segmentation, with over 30% FLOPs reduction for backbone. Code is available at http://github.com/changsn/STViT-R
Multimodal Data Integration for Oncology in the Era of Deep Neural Networks: A Review
Mar 11, 2023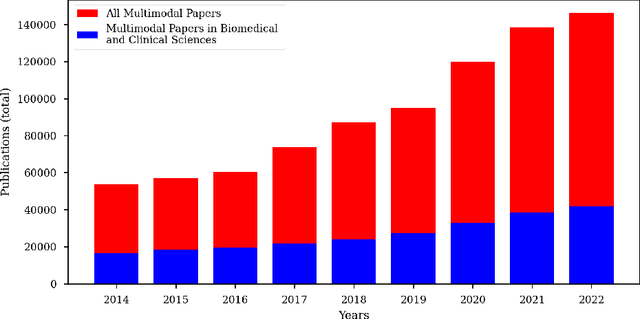
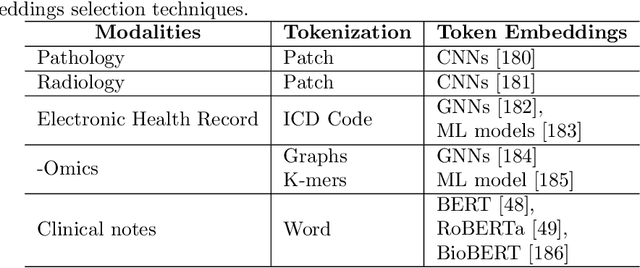
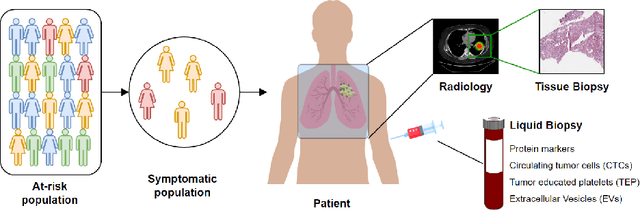
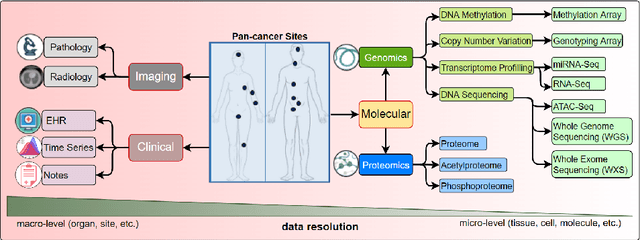
Cancer has relational information residing at varying scales, modalities, and resolutions of the acquired data, such as radiology, pathology, genomics, proteomics, and clinical records. Integrating diverse data types can improve the accuracy and reliability of cancer diagnosis and treatment. There can be disease-related information that is too subtle for humans or existing technological tools to discern visually. Traditional methods typically focus on partial or unimodal information about biological systems at individual scales and fail to encapsulate the complete spectrum of the heterogeneous nature of data. Deep neural networks have facilitated the development of sophisticated multimodal data fusion approaches that can extract and integrate relevant information from multiple sources. Recent deep learning frameworks such as Graph Neural Networks (GNNs) and Transformers have shown remarkable success in multimodal learning. This review article provides an in-depth analysis of the state-of-the-art in GNNs and Transformers for multimodal data fusion in oncology settings, highlighting notable research studies and their findings. We also discuss the foundations of multimodal learning, inherent challenges, and opportunities for integrative learning in oncology. By examining the current state and potential future developments of multimodal data integration in oncology, we aim to demonstrate the promising role that multimodal neural networks can play in cancer prevention, early detection, and treatment through informed oncology practices in personalized settings.
IDa-Det: An Information Discrepancy-aware Distillation for 1-bit Detectors
Oct 07, 2022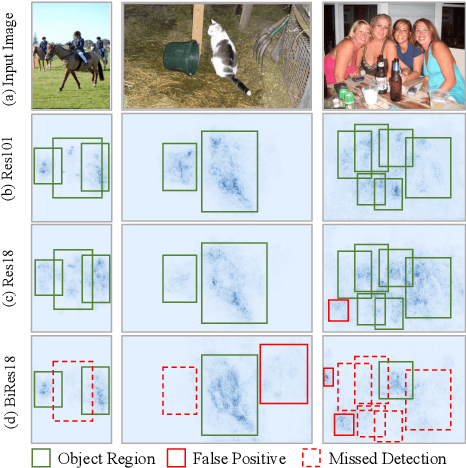
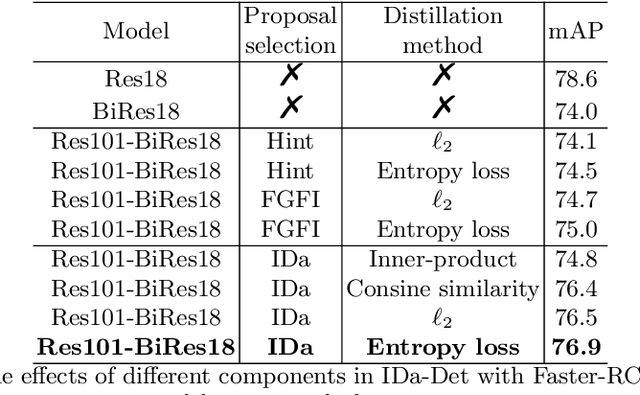
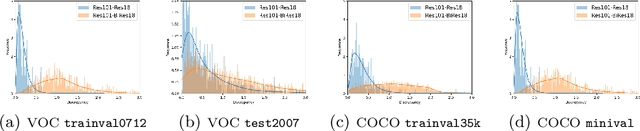
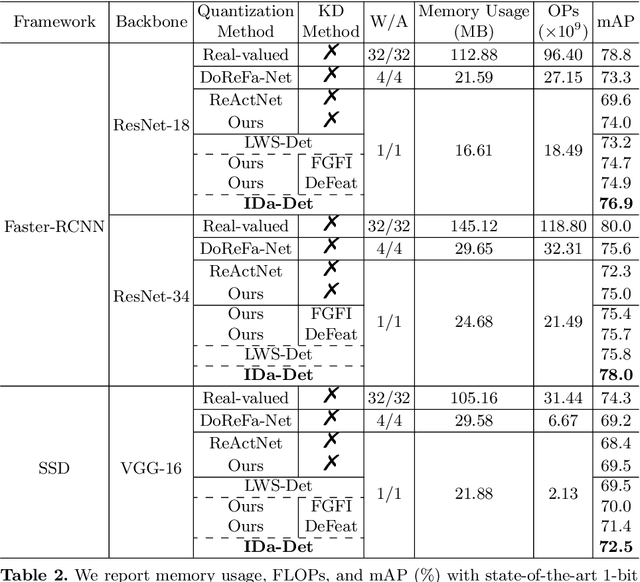
Knowledge distillation (KD) has been proven to be useful for training compact object detection models. However, we observe that KD is often effective when the teacher model and student counterpart share similar proposal information. This explains why existing KD methods are less effective for 1-bit detectors, caused by a significant information discrepancy between the real-valued teacher and the 1-bit student. This paper presents an Information Discrepancy-aware strategy (IDa-Det) to distill 1-bit detectors that can effectively eliminate information discrepancies and significantly reduce the performance gap between a 1-bit detector and its real-valued counterpart. We formulate the distillation process as a bi-level optimization formulation. At the inner level, we select the representative proposals with maximum information discrepancy. We then introduce a novel entropy distillation loss to reduce the disparity based on the selected proposals. Extensive experiments demonstrate IDa-Det's superiority over state-of-the-art 1-bit detectors and KD methods on both PASCAL VOC and COCO datasets. IDa-Det achieves a 76.9% mAP for a 1-bit Faster-RCNN with ResNet-18 backbone. Our code is open-sourced on https://github.com/SteveTsui/IDa-Det.
Active Exploration based on Information Gain by Particle Filter for Efficient Spatial Concept Formation
Nov 20, 2022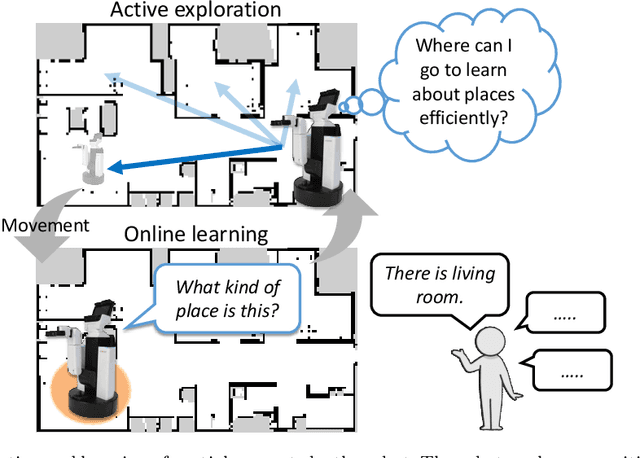

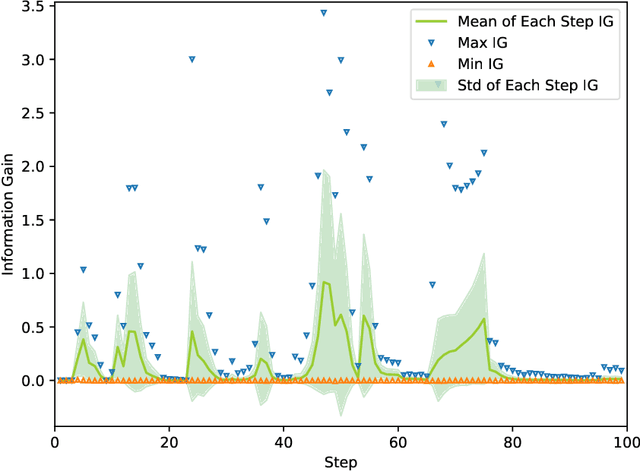
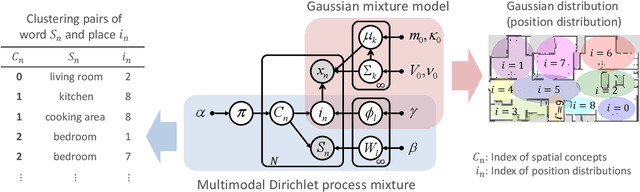
Autonomous robots are required to actively and adaptively learn the categories and words of various places by exploring the surrounding environment and interacting with users. In semantic mapping and spatial language acquisition conducted using robots, it is costly and labor-intensive to prepare training datasets that contain linguistic instructions from users. Therefore, we aimed to enable mobile robots to learn spatial concepts through autonomous active exploration. This study is characterized by interpreting the `action' of the robot that asks the user the question `What kind of place is this?' in the context of active inference. We propose an active inference method, spatial concept formation with information gain-based active exploration (SpCoAE), that combines sequential Bayesian inference by particle filters and position determination based on information gain in a probabilistic generative model. Our experiment shows that the proposed method can efficiently determine a position to form appropriate spatial concepts in home environments. In particular, it is important to conduct efficient exploration that leads to appropriate concept formation and quickly covers the environment without adopting a haphazard exploration strategy.
Bridging Imitation and Online Reinforcement Learning: An Optimistic Tale
Mar 20, 2023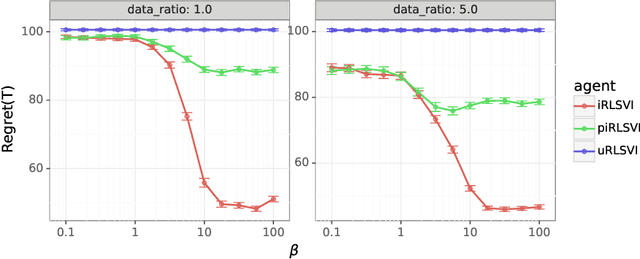
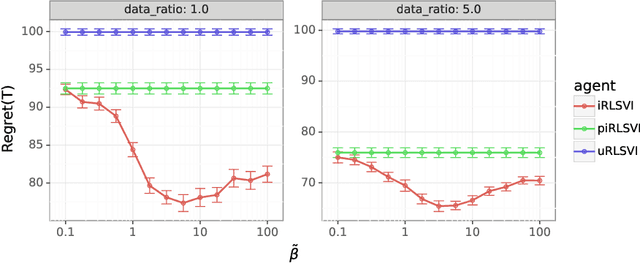
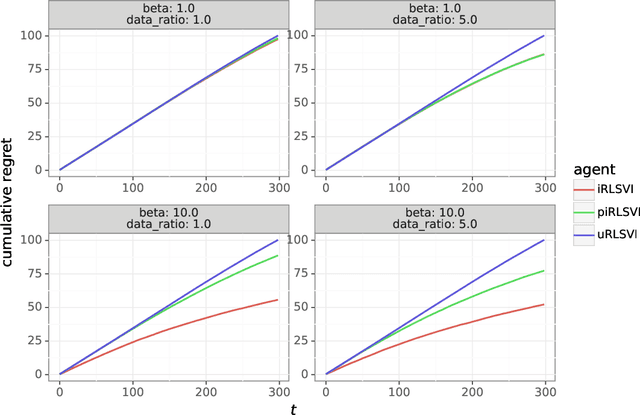
In this paper, we address the following problem: Given an offline demonstration dataset from an imperfect expert, what is the best way to leverage it to bootstrap online learning performance in MDPs. We first propose an Informed Posterior Sampling-based RL (iPSRL) algorithm that uses the offline dataset, and information about the expert's behavioral policy used to generate the offline dataset. Its cumulative Bayesian regret goes down to zero exponentially fast in N, the offline dataset size if the expert is competent enough. Since this algorithm is computationally impractical, we then propose the iRLSVI algorithm that can be seen as a combination of the RLSVI algorithm for online RL, and imitation learning. Our empirical results show that the proposed iRLSVI algorithm is able to achieve significant reduction in regret as compared to two baselines: no offline data, and offline dataset but used without information about the generative policy. Our algorithm bridges online RL and imitation learning for the first time.
TKN: Transformer-based Keypoint Prediction Network For Real-time Video Prediction
Mar 20, 2023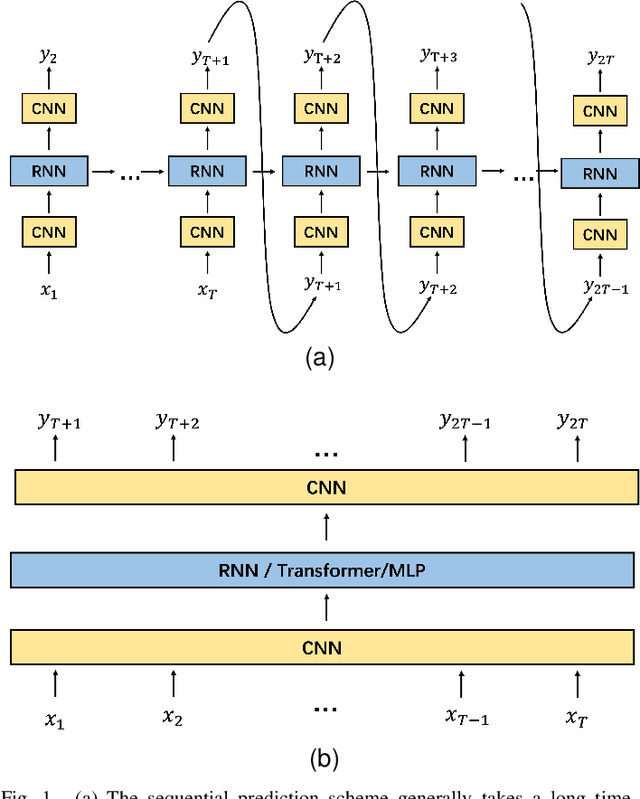
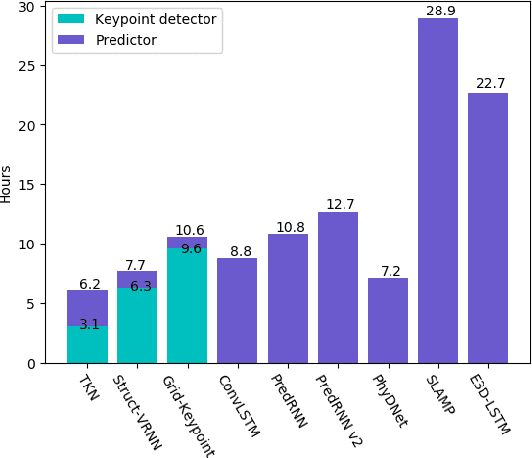

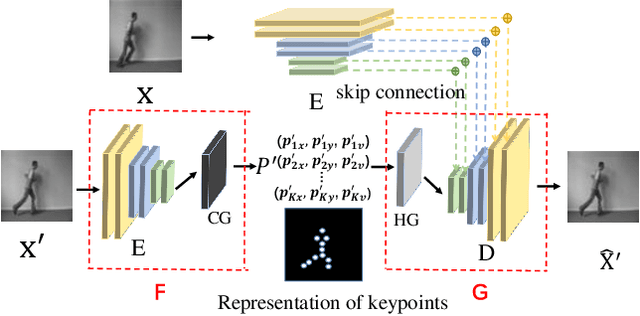
Video prediction is a complex time-series forecasting task with great potential in many use cases. However, conventional methods overemphasize accuracy while ignoring the slow prediction speed caused by complicated model structures that learn too much redundant information with excessive GPU memory consumption. Furthermore, conventional methods mostly predict frames sequentially (frame-by-frame) and thus are hard to accelerate. Consequently, valuable use cases such as real-time danger prediction and warning cannot achieve fast enough inference speed to be applicable in reality. Therefore, we propose a transformer-based keypoint prediction neural network (TKN), an unsupervised learning method that boost the prediction process via constrained information extraction and parallel prediction scheme. TKN is the first real-time video prediction solution to our best knowledge, while significantly reducing computation costs and maintaining other performance. Extensive experiments on KTH and Human3.6 datasets demonstrate that TKN predicts 11 times faster than existing methods while reducing memory consumption by 17.4% and achieving state-of-the-art prediction performance on average.
Self-Supervised Learning with an Information Maximization Criterion
Sep 16, 2022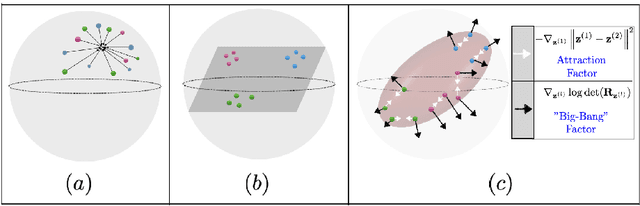
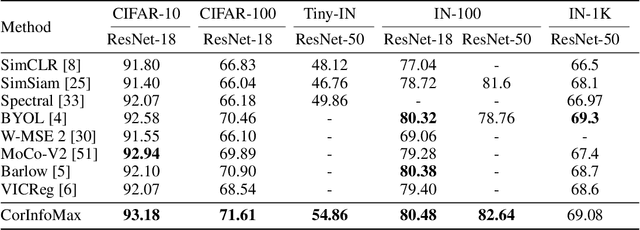
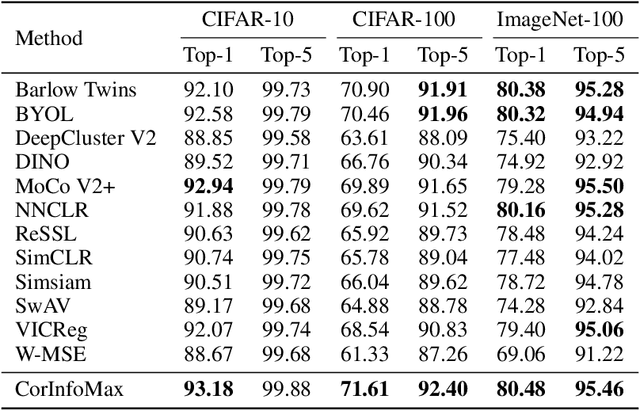
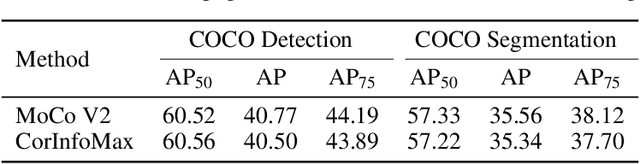
Self-supervised learning allows AI systems to learn effective representations from large amounts of data using tasks that do not require costly labeling. Mode collapse, i.e., the model producing identical representations for all inputs, is a central problem to many self-supervised learning approaches, making self-supervised tasks, such as matching distorted variants of the inputs, ineffective. In this article, we argue that a straightforward application of information maximization among alternative latent representations of the same input naturally solves the collapse problem and achieves competitive empirical results. We propose a self-supervised learning method, CorInfoMax, that uses a second-order statistics-based mutual information measure that reflects the level of correlation among its arguments. Maximizing this correlative information measure between alternative representations of the same input serves two purposes: (1) it avoids the collapse problem by generating feature vectors with non-degenerate covariances; (2) it establishes relevance among alternative representations by increasing the linear dependence among them. An approximation of the proposed information maximization objective simplifies to a Euclidean distance-based objective function regularized by the log-determinant of the feature covariance matrix. The regularization term acts as a natural barrier against feature space degeneracy. Consequently, beyond avoiding complete output collapse to a single point, the proposed approach also prevents dimensional collapse by encouraging the spread of information across the whole feature space. Numerical experiments demonstrate that CorInfoMax achieves better or competitive performance results relative to the state-of-the-art SSL approaches.