 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModality-Aware Out-of-Distribution Detection for Multi-Modal Action Recognition
Jun 23, 2026The incorporation of additional modalities into action recognition models increases their performance across a wide range of settings. However, how this additional information can contribute to making the models more robust remains underexplored, particularly for the case of multi-modal out-of-distribution (OOD) detection. While methods exist that regularize the multi-modal training process with OOD detection in mind, they still apply off-the-shelf OOD detectors designed for the uni-modal case during inference, discarding important information. Based on an interesting relationship we find between the multi-modal and uni-modal predictions, we propose to use this signal to build a post-hoc detector explicitly designed for the multi-modal scenario. We combine this new source of information with a feature-space score, which detects off-manifold samples in the multi-modal space, and normalize them by the multi-modal logits. In doing so, the proposed hybrid detector is compatible with existing training-time approaches and consistently improves performance. Experiments on a wide range of established datasets from the MultiOOD benchmark show that, on average, our approach outperforms the state of the art. Our results show the importance of explicitly considering the different modalities at inference time for multi-modal OOD detection.
The Unreasonable Effectiveness of VLMs for Zero-shot Procedural Mistake Detection
Jun 19, 2026Procedural mistake detection is important for quality control and user assistance across many disciplines. Recent work in this field has achieved significant gains by using the reasoning capabilities of Video-Language Models (VLMs) as components within multi-stage pipelines, which consist of separate modules for supervised temporal action segmentation, error detection, and explainability. Consequently, they remain dependent on tailored training datasets and require task-specific training, limiting their wider applicability. To remedy this, we introduce zero-shot procedural mistake detection and propose a unified Zero-shot Procedural Mistake detection (ZeProM) framework that jointly solves procedural mistake detection and temporal action segmentation with a single pre-trained VLM. By evaluating our framework on two canonical mistake detection benchmarks, EgoPER and CaptainCook4D, we find that ZeProM can perform these tasks successfully, while approaching, or even outperforming, the performance of fully supervised methods. For instance, we achieve a 4.4 point improvement in EDA and a 2.0 point improvement in F1@.5 on average over all five EgoPER tasks compared to the strongest supervised methods. Overall, our results show the potential of unified methods for procedural mistake detection, and we hope this will steer the field away from highly complex pipelines and toward more generally applicable solutions.
Self-Supervised Learning with an Information Maximization Criterion
Sep 16, 2022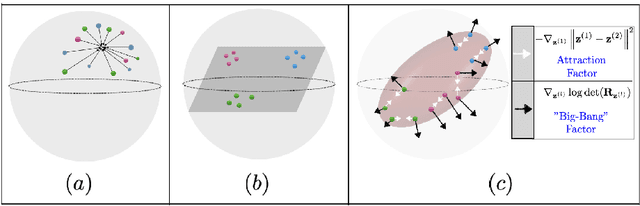
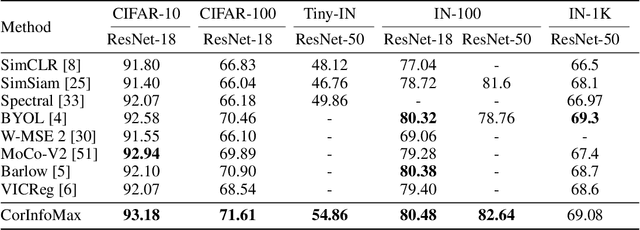
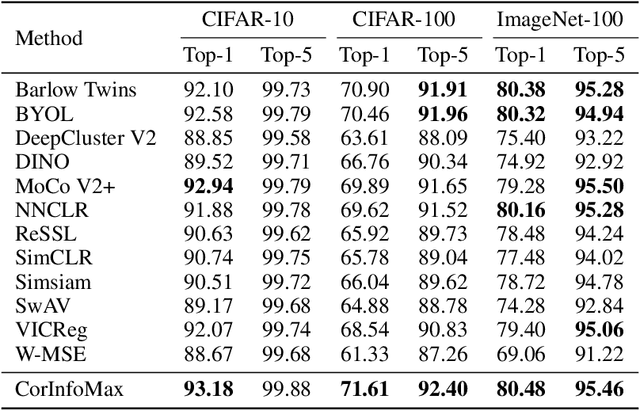
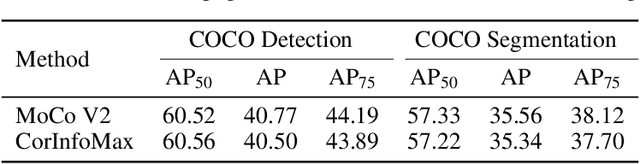
Self-supervised learning allows AI systems to learn effective representations from large amounts of data using tasks that do not require costly labeling. Mode collapse, i.e., the model producing identical representations for all inputs, is a central problem to many self-supervised learning approaches, making self-supervised tasks, such as matching distorted variants of the inputs, ineffective. In this article, we argue that a straightforward application of information maximization among alternative latent representations of the same input naturally solves the collapse problem and achieves competitive empirical results. We propose a self-supervised learning method, CorInfoMax, that uses a second-order statistics-based mutual information measure that reflects the level of correlation among its arguments. Maximizing this correlative information measure between alternative representations of the same input serves two purposes: (1) it avoids the collapse problem by generating feature vectors with non-degenerate covariances; (2) it establishes relevance among alternative representations by increasing the linear dependence among them. An approximation of the proposed information maximization objective simplifies to a Euclidean distance-based objective function regularized by the log-determinant of the feature covariance matrix. The regularization term acts as a natural barrier against feature space degeneracy. Consequently, beyond avoiding complete output collapse to a single point, the proposed approach also prevents dimensional collapse by encouraging the spread of information across the whole feature space. Numerical experiments demonstrate that CorInfoMax achieves better or competitive performance results relative to the state-of-the-art SSL approaches.