 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
To Copy Rather Than Memorize: A Vertical Learning Paradigm for Knowledge Graph Completion
May 23, 2023
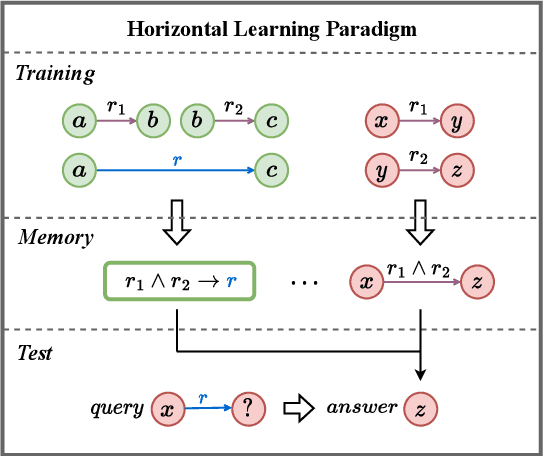

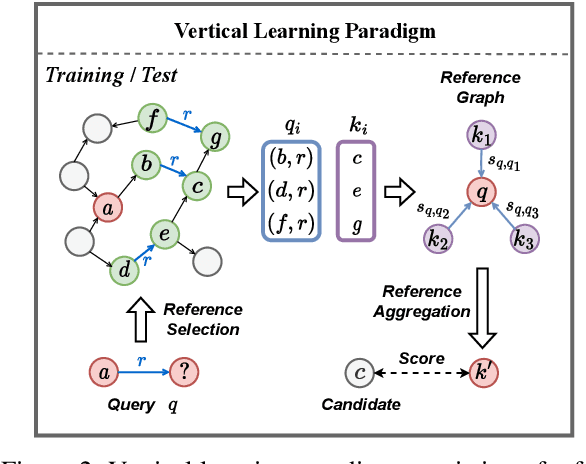
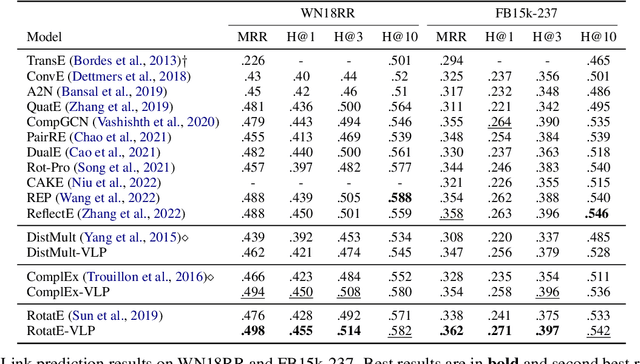
Embedding models have shown great power in knowledge graph completion (KGC) task. By learning structural constraints for each training triple, these methods implicitly memorize intrinsic relation rules to infer missing links. However, this paper points out that the multi-hop relation rules are hard to be reliably memorized due to the inherent deficiencies of such implicit memorization strategy, making embedding models underperform in predicting links between distant entity pairs. To alleviate this problem, we present Vertical Learning Paradigm (VLP), which extends embedding models by allowing to explicitly copy target information from related factual triples for more accurate prediction. Rather than solely relying on the implicit memory, VLP directly provides additional cues to improve the generalization ability of embedding models, especially making the distant link prediction significantly easier. Moreover, we also propose a novel relative distance based negative sampling technique (ReD) for more effective optimization. Experiments demonstrate the validity and generality of our proposals on two standard benchmarks. Our code is available at https://github.com/rui9812/VLP.
DCCRN-KWS: an audio bias based model for noise robust small-footprint keyword spotting
May 23, 2023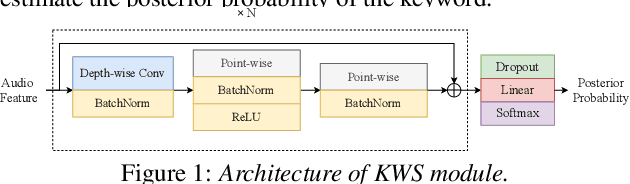

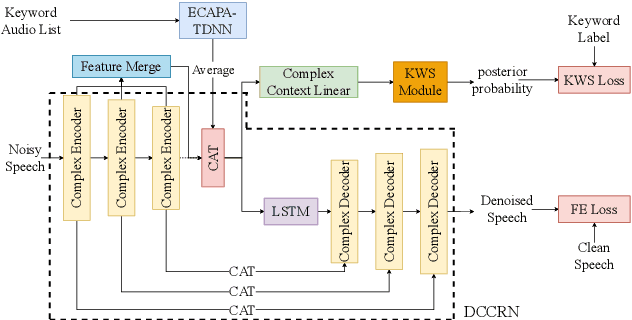
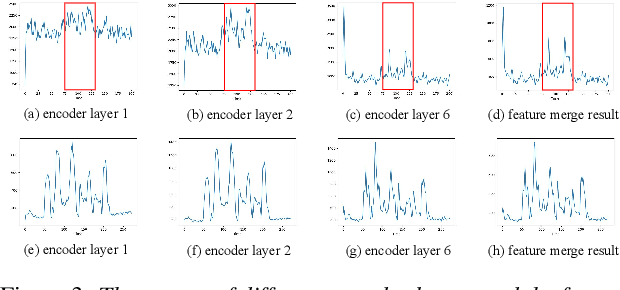
Real-world complex acoustic environments especially the ones with a low signal-to-noise ratio (SNR) will bring tremendous challenges to a keyword spotting (KWS) system. Inspired by the recent advances of neural speech enhancement and context bias in speech recognition, we propose a robust audio context bias based DCCRN-KWS model to address this challenge. We form the whole architecture as a multi-task learning framework for both denosing and keyword spotting, where the DCCRN encoder is connected with the KWS model. Helped with the denoising task, we further introduce an audio context bias module to leverage the real keyword samples and bias the network to better iscriminate keywords in noisy conditions. Feature merge and complex context linear modules are also introduced to strength such discrimination and to effectively leverage contextual information respectively. Experiments on the internal challenging dataset and the HIMIYA public dataset show that our DCCRN-KWS system is superior in performance, while ablation study demonstrates the good design of the whole model.
Explanations as Features: LLM-Based Features for Text-Attributed Graphs
May 31, 2023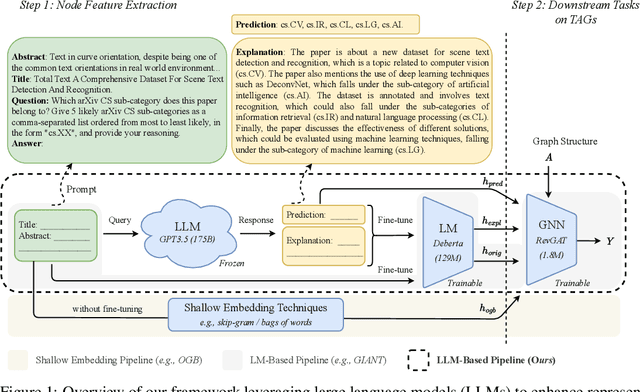
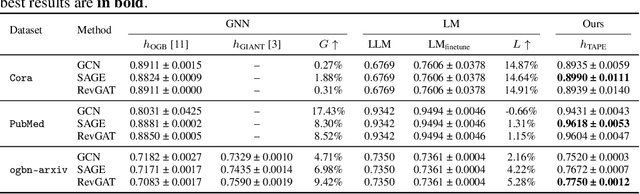
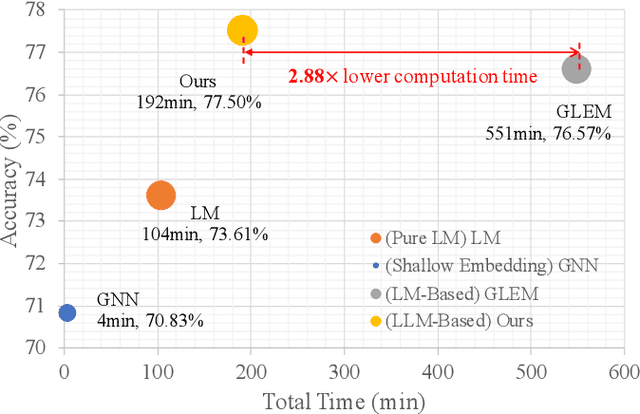
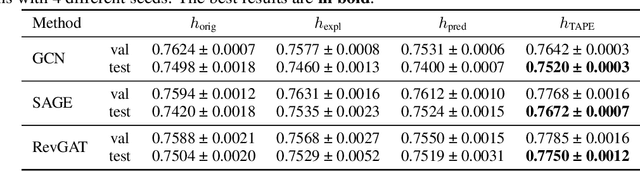
Representation learning on text-attributed graphs (TAGs) has become a critical research problem in recent years. A typical example of a TAG is a paper citation graph, where the text of each paper serves as node attributes. Most graph neural network (GNN) pipelines handle these text attributes by transforming them into shallow or hand-crafted features, such as skip-gram or bag-of-words features. Recent efforts have focused on enhancing these pipelines with language models. With the advent of powerful large language models (LLMs) such as GPT, which demonstrate an ability to reason and to utilize general knowledge, there is a growing need for techniques which combine the textual modelling abilities of LLMs with the structural learning capabilities of GNNs. Hence, in this work, we focus on leveraging LLMs to capture textual information as features, which can be used to boost GNN performance on downstream tasks. A key innovation is our use of \emph{explanations as features}: we prompt an LLM to perform zero-shot classification and to provide textual explanations for its decisions, and find that the resulting explanations can be transformed into useful and informative features to augment downstream GNNs. Through experiments we show that our enriched features improve the performance of a variety of GNN models across different datasets. Notably, we achieve top-1 performance on \texttt{ogbn-arxiv} by a significant margin over the closest baseline even with $2.88\times$ lower computation time, as well as top-1 performance on TAG versions of the widely used \texttt{PubMed} and \texttt{Cora} benchmarks~\footnote{Our codes and datasets are available at: \url{https://github.com/XiaoxinHe/TAPE}}.
MSKdeX: Musculoskeletal (MSK) decomposition from an X-ray image for fine-grained estimation of lean muscle mass and muscle volume
May 31, 2023

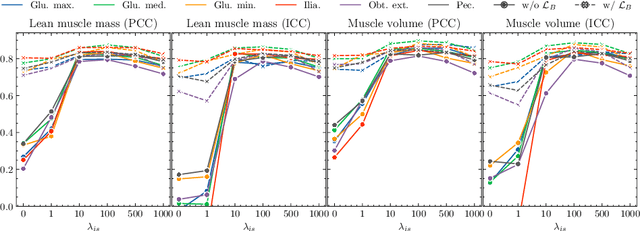
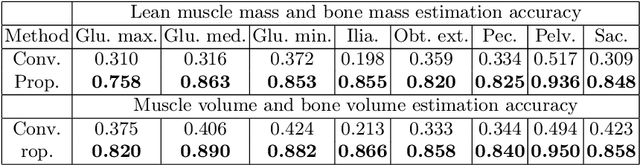
Musculoskeletal diseases such as sarcopenia and osteoporosis are major obstacles to health during aging. Although dual-energy X-ray absorptiometry (DXA) and computed tomography (CT) can be used to evaluate musculoskeletal conditions, frequent monitoring is difficult due to the cost and accessibility (as well as high radiation exposure in the case of CT). We propose a method (named MSKdeX) to estimate fine-grained muscle properties from a plain X-ray image, a low-cost, low-radiation, and highly accessible imaging modality, through musculoskeletal decomposition leveraging fine-grained segmentation in CT. We train a multi-channel quantitative image translation model to decompose an X-ray image into projections of CT of individual muscles to infer the lean muscle mass and muscle volume. We propose the object-wise intensity-sum loss, a simple yet surprisingly effective metric invariant to muscle deformation and projection direction, utilizing information in CT and X-ray images collected from the same patient. While our method is basically an unpaired image-to-image translation, we also exploit the nature of the bone's rigidity, which provides the paired data through 2D-3D rigid registration, adding strong pixel-wise supervision in unpaired training. Through the evaluation using a 539-patient dataset, we showed that the proposed method significantly outperformed conventional methods. The average Pearson correlation coefficient between the predicted and CT-derived ground truth metrics was increased from 0.460 to 0.863. We believe our method opened up a new musculoskeletal diagnosis method and has the potential to be extended to broader applications in multi-channel quantitative image translation tasks. Our source code will be released soon.
Goniometers are a Powerful Acoustic Feature for Music Information Retrieval Tasks
Feb 02, 2023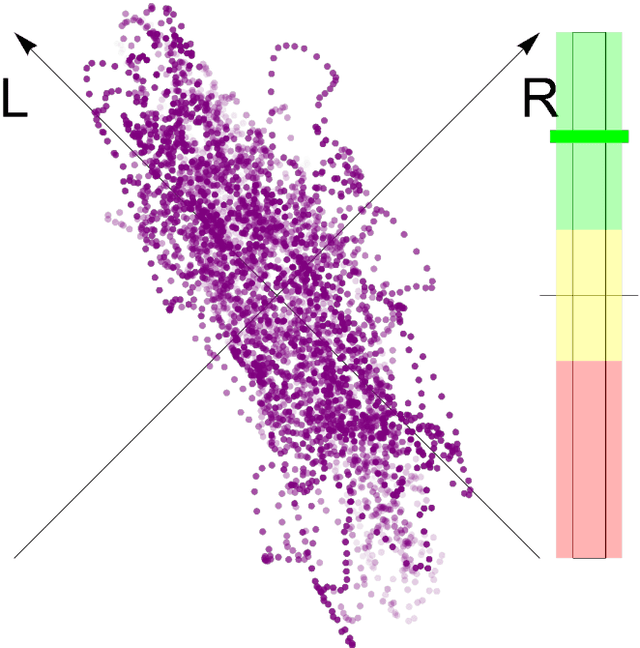
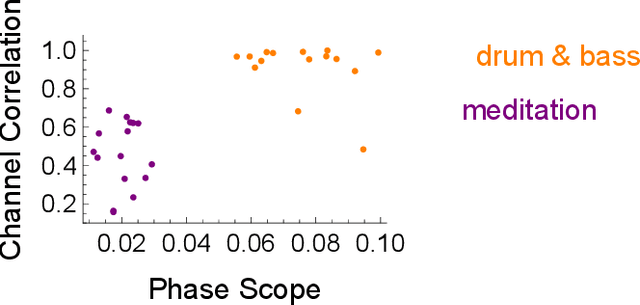
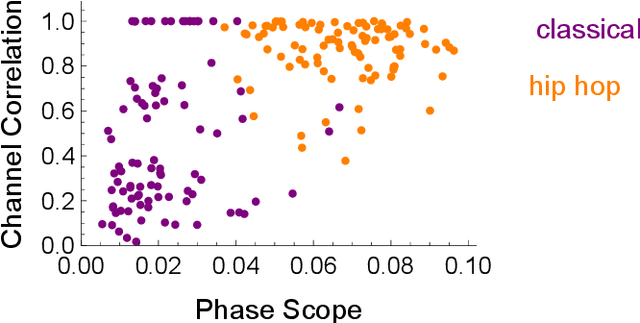
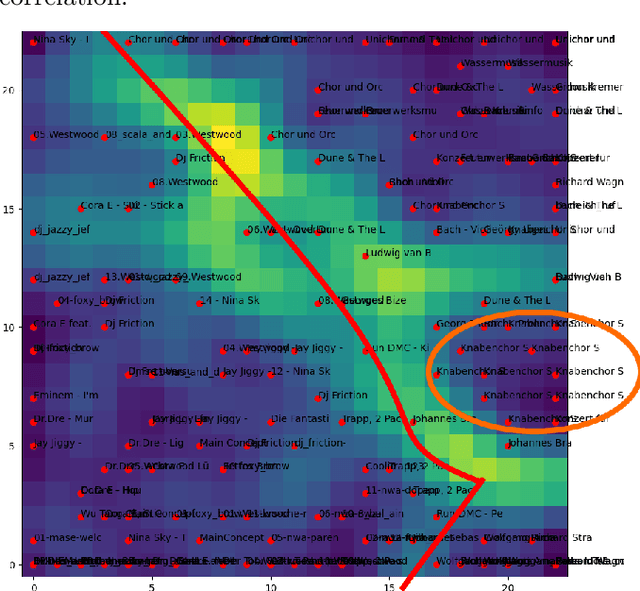
Goniometers, also known as Phase Scopes or Vector Scopes, are audio metering tools that help music producers and mixing engineers monitor spatial aspects of a music mix, such as the stereo panorama, the width of single sources, the amount and diffuseness of reverberation as well as phase cancellations that may occur on the sweet-spot and in a mono-mixdown. In addition, they implicitly inform about the dynamics of the sound. Self-organizing maps trained with a goniometer, are consulted to explore the usefulness of this acoustic feature for music information retrieval tasks. One can see that goniometers are able to classify different genres and cluster a single album. The advantage of goniometers is the causality: Music producers and mixing engineers consciously consult goniometers to reach their desired sound, which is not the case for other acoustic features, from Zero-Crossing Rate to Mel-Frequency Cepstral Coefficients.
Reward Collapse in Aligning Large Language Models
May 28, 2023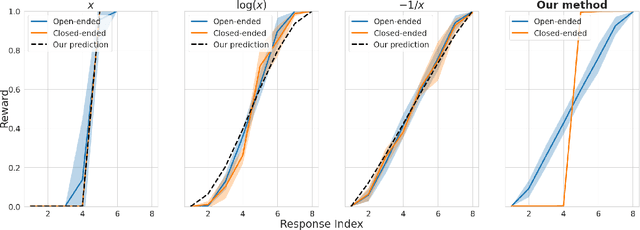
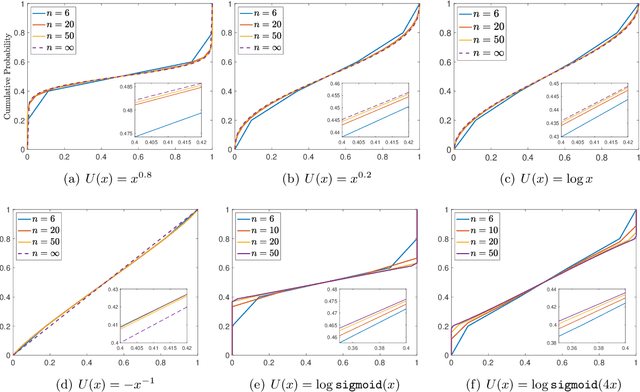
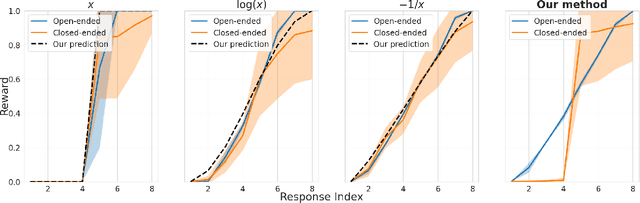
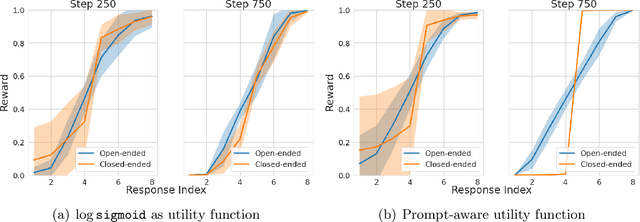
The extraordinary capabilities of large language models (LLMs) such as ChatGPT and GPT-4 are in part unleashed by aligning them with reward models that are trained on human preferences, which are often represented as rankings of responses to prompts. In this paper, we document the phenomenon of \textit{reward collapse}, an empirical observation where the prevailing ranking-based approach results in an \textit{identical} reward distribution \textit{regardless} of the prompts during the terminal phase of training. This outcome is undesirable as open-ended prompts like ``write a short story about your best friend'' should yield a continuous range of rewards for their completions, while specific prompts like ``what is the capital of New Zealand'' should generate either high or low rewards. Our theoretical investigation reveals that reward collapse is primarily due to the insufficiency of the ranking-based objective function to incorporate prompt-related information during optimization. This insight allows us to derive closed-form expressions for the reward distribution associated with a set of utility functions in an asymptotic regime. To overcome reward collapse, we introduce a prompt-aware optimization scheme that provably admits a prompt-dependent reward distribution within the interpolating regime. Our experimental results suggest that our proposed prompt-aware utility functions significantly alleviate reward collapse during the training of reward models.
Conditional score-based diffusion models for Bayesian inference in infinite dimensions
May 28, 2023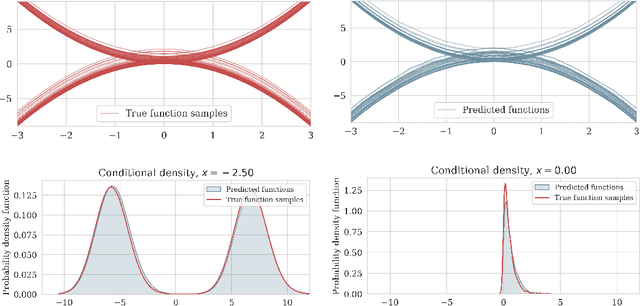
Since their first introduction, score-based diffusion models (SDMs) have been successfully applied to solve a variety of linear inverse problems in finite-dimensional vector spaces due to their ability to efficiently approximate the posterior distribution. However, using SDMs for inverse problems in infinite-dimensional function spaces has only been addressed recently and by learning the unconditional score. While this approach has some advantages, depending on the specific inverse problem at hand, in order to sample from the conditional distribution it needs to incorporate the information from the observed data with a proximal optimization step, solving an optimization problem numerous times. This may not be feasible in inverse problems with computationally costly forward operators. To address these limitations, in this work we propose a method to learn the posterior distribution in infinite-dimensional Bayesian linear inverse problems using amortized conditional SDMs. In particular, we prove that the conditional denoising estimator is a consistent estimator of the conditional score in infinite dimensions. We show that the extension of SDMs to the conditional setting requires some care because the conditional score typically blows up for small times contrarily to the unconditional score. We also discuss the robustness of the learned distribution against perturbations of the observations. We conclude by presenting numerical examples that validate our approach and provide additional insights.
TaleCrafter: Interactive Story Visualization with Multiple Characters
May 30, 2023

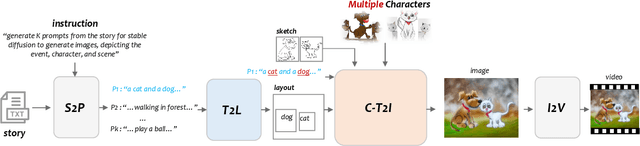
Accurate Story visualization requires several necessary elements, such as identity consistency across frames, the alignment between plain text and visual content, and a reasonable layout of objects in images. Most previous works endeavor to meet these requirements by fitting a text-to-image (T2I) model on a set of videos in the same style and with the same characters, e.g., the FlintstonesSV dataset. However, the learned T2I models typically struggle to adapt to new characters, scenes, and styles, and often lack the flexibility to revise the layout of the synthesized images. This paper proposes a system for generic interactive story visualization, capable of handling multiple novel characters and supporting the editing of layout and local structure. It is developed by leveraging the prior knowledge of large language and T2I models, trained on massive corpora. The system comprises four interconnected components: story-to-prompt generation (S2P), text-to-layout generation (T2L), controllable text-to-image generation (C-T2I), and image-to-video animation (I2V). First, the S2P module converts concise story information into detailed prompts required for subsequent stages. Next, T2L generates diverse and reasonable layouts based on the prompts, offering users the ability to adjust and refine the layout to their preference. The core component, C-T2I, enables the creation of images guided by layouts, sketches, and actor-specific identifiers to maintain consistency and detail across visualizations. Finally, I2V enriches the visualization process by animating the generated images. Extensive experiments and a user study are conducted to validate the effectiveness and flexibility of interactive editing of the proposed system.
Improving accuracy of GPT-3/4 results on biomedical data using a retrieval-augmented language model
May 30, 2023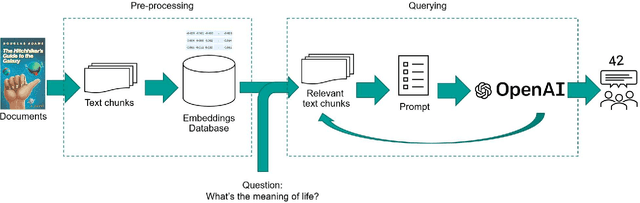
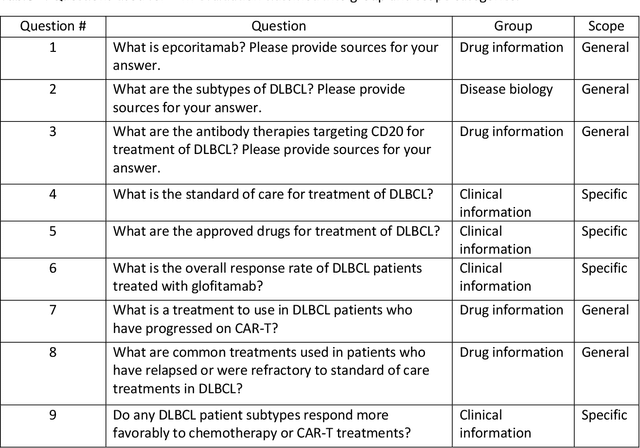

Large language models (LLMs) have made significant advancements in natural language processing (NLP). Broad corpora capture diverse patterns but can introduce irrelevance, while focused corpora enhance reliability by reducing misleading information. Training LLMs on focused corpora poses computational challenges. An alternative approach is to use a retrieval-augmentation (RetA) method tested in a specific domain. To evaluate LLM performance, OpenAI's GPT-3, GPT-4, Bing's Prometheus, and a custom RetA model were compared using 19 questions on diffuse large B-cell lymphoma (DLBCL) disease. Eight independent reviewers assessed responses based on accuracy, relevance, and readability (rated 1-3). The RetA model performed best in accuracy (12/19 3-point scores, total=47) and relevance (13/19, 50), followed by GPT-4 (8/19, 43; 11/19, 49). GPT-4 received the highest readability scores (17/19, 55), followed by GPT-3 (15/19, 53) and the RetA model (11/19, 47). Prometheus underperformed in accuracy (34), relevance (32), and readability (38). Both GPT-3.5 and GPT-4 had more hallucinations in all 19 responses compared to the RetA model and Prometheus. Hallucinations were mostly associated with non-existent references or fabricated efficacy data. These findings suggest that RetA models, supplemented with domain-specific corpora, may outperform general-purpose LLMs in accuracy and relevance within specific domains. However, this evaluation was limited to specific questions and metrics and may not capture challenges in semantic search and other NLP tasks. Further research will explore different LLM architectures, RetA methodologies, and evaluation methods to assess strengths and limitations more comprehensively.
Intrinsic shape analysis in archaeology: A case study on ancient sundials
May 30, 2023
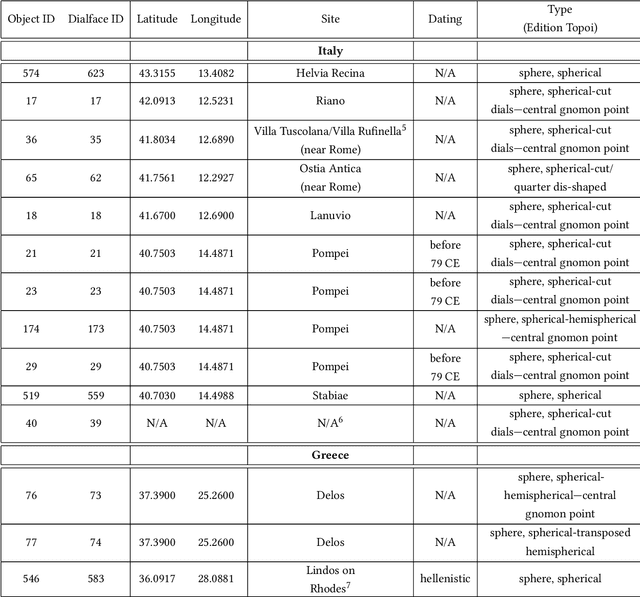
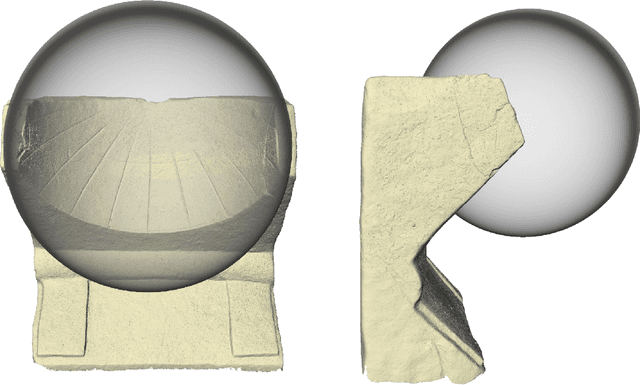
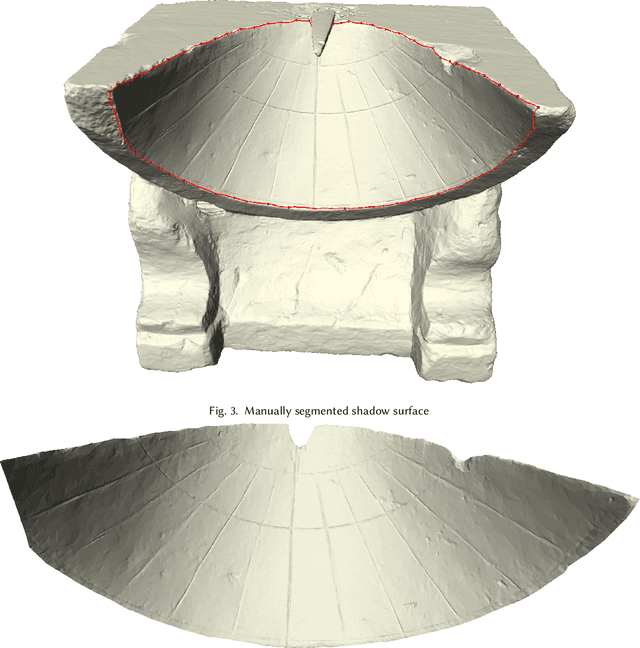
This paper explores a novel mathematical approach to extract archaeological insights from ensembles of similar artifact shapes. We show that by considering all the shape information in a find collection, it is possible to identify shape patterns that would be difficult to discern by considering the artifacts individually or by classifying shapes into predefined archaeological types and analyzing the associated distinguishing characteristics. Recently, series of high-resolution digital representations of artifacts have become available, and we explore their potential on a set of 3D models of ancient Greek and Roman sundials, with the aim of providing alternatives to the traditional archaeological method of ``trend extraction by ordination'' (typology). In the proposed approach, each 3D shape is represented as a point in a shape space -- a high-dimensional, curved, non-Euclidean space. By performing regression in shape space, we find that for Roman sundials, the bend of the sundials' shadow-receiving surface changes with the location's latitude. This suggests that, apart from the inscribed hour lines, also a sundial's shape was adjusted to the place of installation. As an example of more advanced inference, we use the identified trend to infer the latitude at which a sundial, whose installation location is unknown, was placed. We also derive a novel method for differentiated morphological trend assertion, building upon and extending the theory of geometric statistics and shape analysis. Specifically, we present a regression-based method for statistical normalization of shapes that serves as a means of disentangling parameter-dependent effects (trends) and unexplained variability.