 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Hallucinations in Inverse Problems: Fundamental Limits and Provable Assessment Methods
May 13, 2026Artificial intelligence (AI) has transformed imaging inverse problems, from medical diagnostics to Earth observation. Yet deep neural networks can produce hallucinations, realistic-looking but incorrect details, undermining their reliability, especially when ground truth data is unavailable. We develop a theoretical framework showing that such hallucinations are not merely artifacts of particular models, but can arise from the ill-posed nature of the inverse problem itself. We derive necessary and sufficient conditions for hallucinations, together with computable bounds on their magnitude that depend only on the forward model. Building on this theory, we introduce algorithms to: (1) estimate the minimum hallucination magnitude achievable by any reconstruction model for a given input; (2) assess the faithfulness of reconstructed details by a given reconstruction model. Experiments across three imaging tasks demonstrate that our approach applies broadly, including to modern generative models, and provides a principled way to quantify and evaluate AI hallucinations.
Multifidelity Gaussian process regression for solving nonlinear partial differential equations
May 11, 2026Solving nonlinear partial differential equations (PDEs) using kernel methods offers a compelling alternative to traditional numerical solvers. However, the performance of these methods strongly depends on the choice of kernel. In this work, as the available information is inherently multifidelity, we propose a kernel learning approach based on cokriging, leveraging empirical information from multifidelity simulations. In the first step, we fit a differentiable non-stationary kernel to an empirical kernel obtained from low-fidelity simulations. In the second step, we derive a high-fidelity kernel with estimated hyperparameters, and construct a corresponding high-fidelity mean using the multifidelity framework. These components can then be used within a Gaussian process framework for solving PDEs. Finally, we demonstrate the performance of the proposed physics-informed method on the Burgers' equation.
Passive Imaging with Ambient Noise Under Wave Speed Mismatch: Mathematical Analysis and Wave Speed Estimation
Feb 17, 2026It is known that waves generated by ambient noise sources and recorded by passive receivers can be used to image the reflectivities of an unknown medium. However, reconstructing the reflectivity of the medium from partial boundary measurements remains a challenging problem, particularly when the background wave speed is unknown. In this paper, we investigate passive correlation-based imaging in the daylight configuration, where uncontrolled noise sources illuminate the medium and only ambient fields are recorded by a sensor array. We first analyze daylight migration for a point reflector embedded in a homogeneous background. By introducing a searching wave speed into the migration functional, we derive an explicit characterization of the deterministic shift and defocusing effects induced by wave-speed mismatch. We show that the maximum of the envelope of the resulting functional provides a reliable estimator of the true wave speed. We then extend the analysis to a random medium with correlation length smaller than the wavelength. Leveraging the shift formula obtained in the homogeneous case, we introduce a virtual guide star that remains fixed under migration with different searching speeds. This property enables an effective wave-speed estimation strategy based on spatial averaging around the virtual guide star. For both homogeneous and random media, we establish resolution analyses for the proposed wave-speed estimators. Numerical experiments are conducted to validate the theoretical result.
Dimension-Free Multimodal Sampling via Preconditioned Annealed Langevin Dynamics
Feb 01, 2026Designing algorithms that can explore multimodal target distributions accurately across successive refinements of an underlying high-dimensional problem is a central challenge in sampling. Annealed Langevin dynamics (ALD) is a widely used alternative to classical Langevin since it often yields much faster mixing on multimodal targets, but there is still a gap between this empirical success and existing theory: when, and under which design choices, can ALD be guaranteed to remain stable as dimension increases? In this paper, we help bridge this gap by providing a uniform-in-dimension analysis of continuous-time ALD for multimodal targets that can be well-approximated by Gaussian mixture models. Along an explicit annealing path obtained by progressively removing Gaussian smoothing of the target, we identify sufficient spectral conditions - linking smoothing covariance and the covariances of the Gaussian components of the mixture - under which ALD achieves a prescribed accuracy within a single, dimension-uniform time horizon. We then establish dimension-robustness to imperfect initialization and score approximation: under a misspecified-mixture score model, we derive explicit conditions showing that preconditioning the ALD algorithm with a sufficiently decaying spectrum is necessary to prevent error terms from accumulating across coordinates and destroying dimension-uniform control. Finally, numerical experiments illustrate and validate the theory.
Quantitative synthetic aperture radar inversion
Jan 28, 2026We study an inverse scattering problem for monostatic synthetic aperture radar (SAR): Estimate the wave speed in a heterogeneous, isotropic and nonmagnetic medium probed by waves emitted and measured by a moving antenna. The forward map, from the wave speed to the measurements, is derived from Maxwell's equations. It is a nonlinear map that accounts for multiple scattering and it is very oscillatory at high frequencies. This makes the standard, nonlinear least squares data fitting formulation of the inverse problem difficult to solve. We introduce an alternative, two-step approach: The first step computes the nonlinear map from the measurements to an approximation of the electric field inside the unknown medium aka, the internal wave. This is done for each antenna location in a non-iterative manner. The internal wave fits the data by construction, but it does not solve Maxwell's equations. The second step uses optimization to minimize the discrepancy between the internal wave and the solution of Maxwell's equations, for all antenna locations. The optimization is iterative. The first step defines an imaging function whose computational cost is comparable to that of standard SAR imaging, but it gives a better estimate of the support of targets. Further iterations improve the quantitative estimation of the wave speed. We assess the performance of the method with numerical simulations and compare the results with those of standard inversion.
A reproducible comparative study of categorical kernels for Gaussian process regression, with new clustering-based nested kernels
Oct 02, 2025



Designing categorical kernels is a major challenge for Gaussian process regression with continuous and categorical inputs. Despite previous studies, it is difficult to identify a preferred method, either because the evaluation metrics, the optimization procedure, or the datasets change depending on the study. In particular, reproducible code is rarely available. The aim of this paper is to provide a reproducible comparative study of all existing categorical kernels on many of the test cases investigated so far. We also propose new evaluation metrics inspired by the optimization community, which provide quantitative rankings of the methods across several tasks. From our results on datasets which exhibit a group structure on the levels of categorical inputs, it appears that nested kernels methods clearly outperform all competitors. When the group structure is unknown or when there is no prior knowledge of such a structure, we propose a new clustering-based strategy using target encodings of categorical variables. We show that on a large panel of datasets, which do not necessarily have a known group structure, this estimation strategy still outperforms other approaches while maintaining low computational cost.
Preconditioned Langevin Dynamics with Score-Based Generative Models for Infinite-Dimensional Linear Bayesian Inverse Problems
May 23, 2025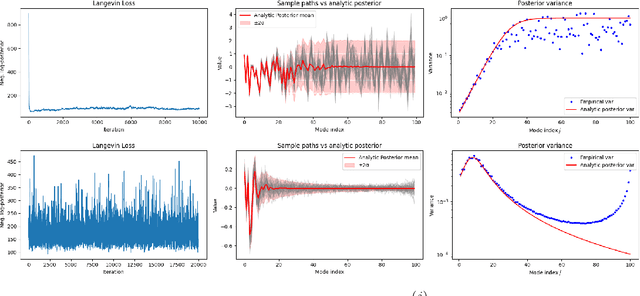
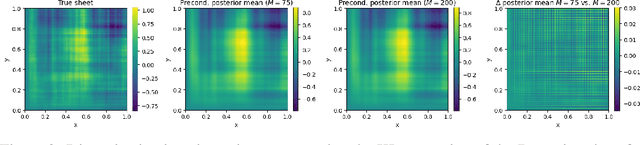


Designing algorithms for solving high-dimensional Bayesian inverse problems directly in infinite-dimensional function spaces - where such problems are naturally formulated - is crucial to ensure stability and convergence as the discretization of the underlying problem is refined. In this paper, we contribute to this line of work by analyzing a widely used sampler for linear inverse problems: Langevin dynamics driven by score-based generative models (SGMs) acting as priors, formulated directly in function space. Building on the theoretical framework for SGMs in Hilbert spaces, we give a rigorous definition of this sampler in the infinite-dimensional setting and derive, for the first time, error estimates that explicitly depend on the approximation error of the score. As a consequence, we obtain sufficient conditions for global convergence in Kullback-Leibler divergence on the underlying function space. Preventing numerical instabilities requires preconditioning of the Langevin algorithm and we prove the existence and the form of an optimal preconditioner. The preconditioner depends on both the score error and the forward operator and guarantees a uniform convergence rate across all posterior modes. Our analysis applies to both Gaussian and a general class of non-Gaussian priors. Finally, we present examples that illustrate and validate our theoretical findings.
General reproducing properties in RKHS with application to derivative and integral operators
Mar 20, 2025In this paper, we generalize the reproducing property in Reproducing Kernel Hilbert Spaces (RKHS). We establish a reproducing property for the closure of the class of combinations of composition operators under minimal conditions. As an application, we improve the existing sufficient conditions for the reproducing property to hold for the derivative operator, as well as for the existence of the mean embedding function. These results extend the scope of applicability of the representer theorem for regularized learning algorithms that involve data for function values, gradients, or any other operator from the considered class.
Learning signals defined on graphs with optimal transport and Gaussian process regression
Oct 21, 2024



In computational physics, machine learning has now emerged as a powerful complementary tool to explore efficiently candidate designs in engineering studies. Outputs in such supervised problems are signals defined on meshes, and a natural question is the extension of general scalar output regression models to such complex outputs. Changes between input geometries in terms of both size and adjacency structure in particular make this transition non-trivial. In this work, we propose an innovative strategy for Gaussian process regression where inputs are large and sparse graphs with continuous node attributes and outputs are signals defined on the nodes of the associated inputs. The methodology relies on the combination of regularized optimal transport, dimension reduction techniques, and the use of Gaussian processes indexed by graphs. In addition to enabling signal prediction, the main point of our proposal is to come with confidence intervals on node values, which is crucial for uncertainty quantification and active learning. Numerical experiments highlight the efficiency of the method to solve real problems in fluid dynamics and solid mechanics.
Taming Score-Based Diffusion Priors for Infinite-Dimensional Nonlinear Inverse Problems
May 24, 2024

This work introduces a sampling method capable of solving Bayesian inverse problems in function space. It does not assume the log-concavity of the likelihood, meaning that it is compatible with nonlinear inverse problems. The method leverages the recently defined infinite-dimensional score-based diffusion models as a learning-based prior, while enabling provable posterior sampling through a Langevin-type MCMC algorithm defined on function spaces. A novel convergence analysis is conducted, inspired by the fixed-point methods established for traditional regularization-by-denoising algorithms and compatible with weighted annealing. The obtained convergence bound explicitly depends on the approximation error of the score; a well-approximated score is essential to obtain a well-approximated posterior. Stylized and PDE-based examples are provided, demonstrating the validity of our convergence analysis. We conclude by presenting a discussion of the method's challenges related to learning the score and computational complexity.