 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTriForces: Augmenting Atomistic GNNs for Transferable Representations
May 20, 2026Machine learning interatomic potentials (MLIPs) achieve excellent accuracy when trained on large Density Functional Theory (DFT) data. To be useful in practice, they must often be adapted to target chemistries using small and expensive task-specific datasets. However, MLIPs transfer inconsistently across domains, with representations that often loose accessible composition and structure information. To address this, we present TriForces, a model-agnostic three-stream framework that separates composition and structure information, combined with self-supervised learning to preserve transferable representations. TriForces improves performance on MatBench and QM9 over baselines without needing DFT labels and enables efficient similar structure retrieval through its learned latent space. On OMat24, in limited-data training regime, TriForces reduces energy MAE by 57% at 20K samples only and improves force MAE across sample sizes. We release pretrained TriForces variants across multiple MLIP architectures with code at https://github.com/Ramlaoui/triforces.
Generalization Bounds for Spectral GNNs via Fourier Domain Analysis
Apr 01, 2026Spectral graph neural networks learn graph filters, but their behavior with increasing depth and polynomial order is not well understood. We analyze these models in the graph Fourier domain, where each layer becomes an element-wise frequency update, separating the fixed spectrum from trainable parameters and making depth and order explicit. In this setting, we show that Gaussian complexity is invariant under the Graph Fourier Transform, which allows us to derive data-dependent, depth, and order-aware generalization bounds together with stability estimates. In the linear case, our bounds are tighter, and on real graphs, the data-dependent term correlates with the generalization gap across polynomial bases, highlighting practical choices that avoid frequency amplification across layers.
GICDM: Mitigating Hubness for Reliable Distance-Based Generative Model Evaluation
Feb 18, 2026Generative model evaluation commonly relies on high-dimensional embedding spaces to compute distances between samples. We show that dataset representations in these spaces are affected by the hubness phenomenon, which distorts nearest neighbor relationships and biases distance-based metrics. Building on the classical Iterative Contextual Dissimilarity Measure (ICDM), we introduce Generative ICDM (GICDM), a method to correct neighborhood estimation for both real and generated data. We introduce a multi-scale extension to improve empirical behavior. Extensive experiments on synthetic and real benchmarks demonstrate that GICDM resolves hubness-induced failures, restores reliable metric behavior, and improves alignment with human judgment.
Multi-fidelity graph-based neural networks architectures to learn Navier-Stokes solutions on non-parametrized 2D domains
Jan 05, 2026We propose a graph-based, multi-fidelity learning framework for the prediction of stationary Navier--Stokes solutions in non-parametrized two-dimensional geometries. The method is designed to guide the learning process through successive approximations, starting from reduced-order and full Stokes models, and progressively approaching the Navier--Stokes solution. To effectively capture both local and long-range dependencies in the velocity and pressure fields, we combine graph neural networks with Transformer and Mamba architectures. While Transformers achieve the highest accuracy, we show that Mamba can be successfully adapted to graph-structured data through an unsupervised node-ordering strategy. The Mamba approach significantly reduces computational cost while maintaining performance. Physical knowledge is embedded directly into the architecture through an encoding -- processing -- physics informed decoding pipeline. Derivatives are computed through algebraic operators constructed via the Weighted Least Squares method. The flexibility of these operators allows us not only to make the output obey the governing equations, but also to constrain selected hidden features to satisfy mass conservation. We introduce additional physical biases through an enriched graph convolution with the same differential operators describing the PDEs. Overall, we successfully guide the learning process by physical knowledge and fluid dynamics insights, leading to more regular and accurate predictions
Enhanced Generative Model Evaluation with Clipped Density and Coverage
Jul 02, 2025

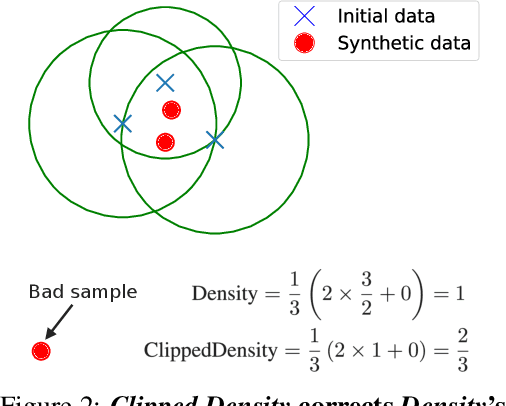

Although generative models have made remarkable progress in recent years, their use in critical applications has been hindered by their incapacity to reliably evaluate sample quality. Quality refers to at least two complementary concepts: fidelity and coverage. Current quality metrics often lack reliable, interpretable values due to an absence of calibration or insufficient robustness to outliers. To address these shortcomings, we introduce two novel metrics, Clipped Density and Clipped Coverage. By clipping individual sample contributions and, for fidelity, the radii of nearest neighbor balls, our metrics prevent out-of-distribution samples from biasing the aggregated values. Through analytical and empirical calibration, these metrics exhibit linear score degradation as the proportion of poor samples increases. Thus, they can be straightforwardly interpreted as equivalent proportions of good samples. Extensive experiments on synthetic and real-world datasets demonstrate that Clipped Density and Clipped Coverage outperform existing methods in terms of robustness, sensitivity, and interpretability for evaluating generative models.
3DDX: Bone Surface Reconstruction from a Single Standard-Geometry Radiograph via Dual-Face Depth Estimation
Sep 25, 2024Radiography is widely used in orthopedics for its affordability and low radiation exposure. 3D reconstruction from a single radiograph, so-called 2D-3D reconstruction, offers the possibility of various clinical applications, but achieving clinically viable accuracy and computational efficiency is still an unsolved challenge. Unlike other areas in computer vision, X-ray imaging's unique properties, such as ray penetration and fixed geometry, have not been fully exploited. We propose a novel approach that simultaneously learns multiple depth maps (front- and back-surface of multiple bones) derived from the X-ray image to computed tomography registration. The proposed method not only leverages the fixed geometry characteristic of X-ray imaging but also enhances the precision of the reconstruction of the whole surface. Our study involved 600 CT and 2651 X-ray images (4 to 5 posed X-ray images per patient), demonstrating our method's superiority over traditional approaches with a surface reconstruction error reduction from 4.78 mm to 1.96 mm. This significant accuracy improvement and enhanced computational efficiency suggest our approach's potential for clinical application.
Enhancing Quantitative Image Synthesis through Pretraining and Resolution Scaling for Bone Mineral Density Estimation from a Plain X-ray Image
Jul 30, 2024While most vision tasks are essentially visual in nature (for recognition), some important tasks, especially in the medical field, also require quantitative analysis (for quantification) using quantitative images. Unlike in visual analysis, pixel values in quantitative images correspond to physical metrics measured by specific devices (e.g., a depth image). However, recent work has shown that it is sometimes possible to synthesize accurate quantitative values from visual ones (e.g., depth from visual cues or defocus). This research aims to improve quantitative image synthesis (QIS) by exploring pretraining and image resolution scaling. We propose a benchmark for evaluating pretraining performance using the task of QIS-based bone mineral density (BMD) estimation from plain X-ray images, where the synthesized quantitative image is used to derive BMD. Our results show that appropriate pretraining can improve QIS performance, significantly raising the correlation of BMD estimation from 0.820 to 0.898, while others do not help or even hinder it. Scaling-up the resolution can further boost the correlation up to 0.923, a significant enhancement over conventional methods. Future work will include exploring more pretraining strategies and validating them on other image synthesis tasks.
Learning truly monotone operators with applications to nonlinear inverse problems
Mar 30, 2024



This article introduces a novel approach to learning monotone neural networks through a newly defined penalization loss. The proposed method is particularly effective in solving classes of variational problems, specifically monotone inclusion problems, commonly encountered in image processing tasks. The Forward-Backward-Forward (FBF) algorithm is employed to address these problems, offering a solution even when the Lipschitz constant of the neural network is unknown. Notably, the FBF algorithm provides convergence guarantees under the condition that the learned operator is monotone. Building on plug-and-play methodologies, our objective is to apply these newly learned operators to solving non-linear inverse problems. To achieve this, we initially formulate the problem as a variational inclusion problem. Subsequently, we train a monotone neural network to approximate an operator that may not inherently be monotone. Leveraging the FBF algorithm, we then show simulation examples where the non-linear inverse problem is successfully solved.
A foundation for exact binarized morphological neural networks
Jan 08, 2024Training and running deep neural networks (NNs) often demands a lot of computation and energy-intensive specialized hardware (e.g. GPU, TPU...). One way to reduce the computation and power cost is to use binary weight NNs, but these are hard to train because the sign function has a non-smooth gradient. We present a model based on Mathematical Morphology (MM), which can binarize ConvNets without losing performance under certain conditions, but these conditions may not be easy to satisfy in real-world scenarios. To solve this, we propose two new approximation methods and develop a robust theoretical framework for ConvNets binarization using MM. We propose as well regularization losses to improve the optimization. We empirically show that our model can learn a complex morphological network, and explore its performance on a classification task.
On the detection of Out-Of-Distribution samples in Multiple Instance Learning
Sep 11, 2023

The deployment of machine learning solutions in real-world scenarios often involves addressing the challenge of out-of-distribution (OOD) detection. While significant efforts have been devoted to OOD detection in classical supervised settings, the context of weakly supervised learning, particularly the Multiple Instance Learning (MIL) framework, remains under-explored. In this study, we tackle this challenge by adapting post-hoc OOD detection methods to the MIL setting while introducing a novel benchmark specifically designed to assess OOD detection performance in weakly supervised scenarios. Extensive experiments based on diverse public datasets do not reveal a single method with a clear advantage over the others. Although DICE emerges as the best-performing method overall, it exhibits significant shortcomings on some datasets, emphasizing the complexity of this under-explored and challenging topic. Our findings shed light on the complex nature of OOD detection under the MIL framework, emphasizing the importance of developing novel, robust, and reliable methods that can generalize effectively in a weakly supervised context. The code for the paper is available here: https://github.com/loic-lb/OOD_MIL.