 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeForward and inverse problems for measure flows in Bayes Hilbert spaces
Mar 20, 2026We study forward and inverse problems for time-dependent probability measures in Bayes--Hilbert spaces. On the forward side, we show that each sufficiently regular Bayes--Hilbert path admits a canonical dynamical realization: a weighted Neumann problem transforms the log-density variation into the unique gradient velocity field of minimum kinetic energy. This construction induces a transport form on Bayes--Hilbert tangent directions, which measures the dynamical cost of realizing prescribed motions, and yields a flow-matching interpretation in which the canonical velocity field is the minimum-energy execution of the prescribed path. On the inverse side, we formulate reconstruction directly on Bayes--Hilbert path space from time-dependent indirect observations. The resulting variational problem combines a data-misfit term with the transport action induced by the forward geometry. In our infinite-dimensional setting, however, this transport geometry alone does not provide sufficient compactness, so we add explicit temporal and spatial regularization to close the theory. The linearized observation operator induces a complementary observability form, which quantifies how strongly tangent directions are seen through the data. Under explicit Sobolev regularity and observability assumptions, we prove existence of minimizers, derive first-variation formulas, establish local stability of the observation map, and deduce recovery of the evolving law, its score, and its canonical velocity field under the strong topologies furnished by the compactness theory.
Dimension-Free Multimodal Sampling via Preconditioned Annealed Langevin Dynamics
Feb 01, 2026Designing algorithms that can explore multimodal target distributions accurately across successive refinements of an underlying high-dimensional problem is a central challenge in sampling. Annealed Langevin dynamics (ALD) is a widely used alternative to classical Langevin since it often yields much faster mixing on multimodal targets, but there is still a gap between this empirical success and existing theory: when, and under which design choices, can ALD be guaranteed to remain stable as dimension increases? In this paper, we help bridge this gap by providing a uniform-in-dimension analysis of continuous-time ALD for multimodal targets that can be well-approximated by Gaussian mixture models. Along an explicit annealing path obtained by progressively removing Gaussian smoothing of the target, we identify sufficient spectral conditions - linking smoothing covariance and the covariances of the Gaussian components of the mixture - under which ALD achieves a prescribed accuracy within a single, dimension-uniform time horizon. We then establish dimension-robustness to imperfect initialization and score approximation: under a misspecified-mixture score model, we derive explicit conditions showing that preconditioning the ALD algorithm with a sufficiently decaying spectrum is necessary to prevent error terms from accumulating across coordinates and destroying dimension-uniform control. Finally, numerical experiments illustrate and validate the theory.
Rates and architectures for learning geometrically non-trivial operators
Dec 10, 2025Deep learning methods have proven capable of recovering operators between high-dimensional spaces, such as solution maps of PDEs and similar objects in mathematical physics, from very few training samples. This phenomenon of data-efficiency has been proven for certain classes of elliptic operators with simple geometry, i.e., operators that do not change the domain of the function or propagate singularities. However, scientific machine learning is commonly used for problems that do involve the propagation of singularities in a priori unknown ways, such as waves, advection, and fluid dynamics. In light of this, we expand the learning theory to include double fibration transforms--geometric integral operators that include generalized Radon and geodesic ray transforms. We prove that this class of operators does not suffer from the curse of dimensionality: the error decays superalgebraically, that is, faster than any fixed power of the reciprocal of the number of training samples. Furthermore, we investigate architectures that explicitly encode the geometry of these transforms, demonstrating that an architecture reminiscent of cross-attention based on levelset methods yields a parameterization that is universal, stable, and learns double fibration transforms from very few training examples. Our results contribute to a rapidly-growing line of theoretical work on learning operators for scientific machine learning.
Preconditioned Langevin Dynamics with Score-Based Generative Models for Infinite-Dimensional Linear Bayesian Inverse Problems
May 23, 2025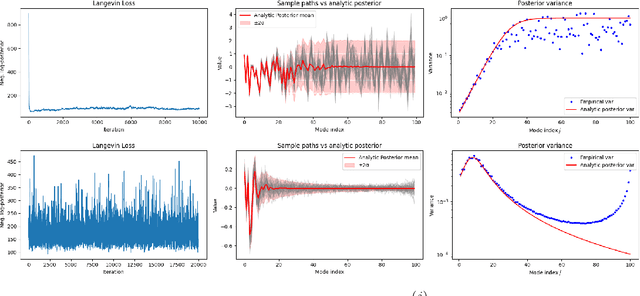
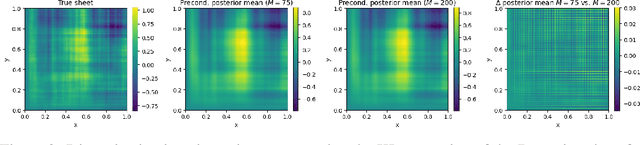


Designing algorithms for solving high-dimensional Bayesian inverse problems directly in infinite-dimensional function spaces - where such problems are naturally formulated - is crucial to ensure stability and convergence as the discretization of the underlying problem is refined. In this paper, we contribute to this line of work by analyzing a widely used sampler for linear inverse problems: Langevin dynamics driven by score-based generative models (SGMs) acting as priors, formulated directly in function space. Building on the theoretical framework for SGMs in Hilbert spaces, we give a rigorous definition of this sampler in the infinite-dimensional setting and derive, for the first time, error estimates that explicitly depend on the approximation error of the score. As a consequence, we obtain sufficient conditions for global convergence in Kullback-Leibler divergence on the underlying function space. Preventing numerical instabilities requires preconditioning of the Langevin algorithm and we prove the existence and the form of an optimal preconditioner. The preconditioner depends on both the score error and the forward operator and guarantees a uniform convergence rate across all posterior modes. Our analysis applies to both Gaussian and a general class of non-Gaussian priors. Finally, we present examples that illustrate and validate our theoretical findings.
Neural equilibria for long-term prediction of nonlinear conservation laws
Jan 12, 2025We introduce Neural Discrete Equilibrium (NeurDE), a machine learning (ML) approach for long-term forecasting of flow phenomena that relies on a "lifting" of physical conservation laws into the framework of kinetic theory. The kinetic formulation provides an excellent structure for ML algorithms by separating nonlinear, non-local physics into a nonlinear but local relaxation to equilibrium and a linear non-local transport. This separation allows the ML to focus on the local nonlinear components while addressing the simpler linear transport with efficient classical numerical algorithms. To accomplish this, we design an operator network that maps macroscopic observables to equilibrium states in a manner that maximizes entropy, yielding expressive BGK-type collisions. By incorporating our surrogate equilibrium into the lattice Boltzmann (LB) algorithm, we achieve accurate flow forecasts for a wide range of challenging flows. We show that NeurDE enables accurate prediction of compressible flows, including supersonic flows, while tracking shocks over hundreds of time steps, using a small velocity lattice-a heretofore unattainable feat without expensive numerical root finding.
Semialgebraic Neural Networks: From roots to representations
Jan 02, 2025Many numerical algorithms in scientific computing -- particularly in areas like numerical linear algebra, PDE simulation, and inverse problems -- produce outputs that can be represented by semialgebraic functions; that is, the graph of the computed function can be described by finitely many polynomial equalities and inequalities. In this work, we introduce Semialgebraic Neural Networks (SANNs), a neural network architecture capable of representing any bounded semialgebraic function, and computing such functions up to the accuracy of a numerical ODE solver chosen by the programmer. Conceptually, we encode the graph of the learned function as the kernel of a piecewise polynomial selected from a class of functions whose roots can be evaluated using a particular homotopy continuation method. We show by construction that the SANN architecture is able to execute this continuation method, thus evaluating the learned semialgebraic function. Furthermore, the architecture can exactly represent even discontinuous semialgebraic functions by executing a continuation method on each connected component of the target function. Lastly, we provide example applications of these networks and show they can be trained with traditional deep-learning techniques.
Can neural operators always be continuously discretized?
Dec 04, 2024
We consider the problem of discretization of neural operators between Hilbert spaces in a general framework including skip connections. We focus on bijective neural operators through the lens of diffeomorphisms in infinite dimensions. Framed using category theory, we give a no-go theorem that shows that diffeomorphisms between Hilbert spaces or Hilbert manifolds may not admit any continuous approximations by diffeomorphisms on finite-dimensional spaces, even if the approximations are nonlinear. The natural way out is the introduction of strongly monotone diffeomorphisms and layerwise strongly monotone neural operators which have continuous approximations by strongly monotone diffeomorphisms on finite-dimensional spaces. For these, one can guarantee discretization invariance, while ensuring that finite-dimensional approximations converge not only as sequences of functions, but that their representations converge in a suitable sense as well. Finally, we show that bilipschitz neural operators may always be written in the form of an alternating composition of strongly monotone neural operators, plus a simple isometry. Thus we realize a rigorous platform for discretization of a generalization of a neural operator. We also show that neural operators of this type may be approximated through the composition of finite-rank residual neural operators, where each block is strongly monotone, and may be inverted locally via iteration. We conclude by providing a quantitative approximation result for the discretization of general bilipschitz neural operators.
SeisLM: a Foundation Model for Seismic Waveforms
Oct 21, 2024



We introduce the Seismic Language Model (SeisLM), a foundational model designed to analyze seismic waveforms -- signals generated by Earth's vibrations such as the ones originating from earthquakes. SeisLM is pretrained on a large collection of open-source seismic datasets using a self-supervised contrastive loss, akin to BERT in language modeling. This approach allows the model to learn general seismic waveform patterns from unlabeled data without being tied to specific downstream tasks. When fine-tuned, SeisLM excels in seismological tasks like event detection, phase-picking, onset time regression, and foreshock-aftershock classification. The code has been made publicly available on https://github.com/liutianlin0121/seisLM.
Transformers are Universal In-context Learners
Aug 02, 2024Transformers are deep architectures that define "in-context mappings" which enable predicting new tokens based on a given set of tokens (such as a prompt in NLP applications or a set of patches for vision transformers). This work studies in particular the ability of these architectures to handle an arbitrarily large number of context tokens. To mathematically and uniformly address the expressivity of these architectures, we consider the case that the mappings are conditioned on a context represented by a probability distribution of tokens (discrete for a finite number of tokens). The related notion of smoothness corresponds to continuity in terms of the Wasserstein distance between these contexts. We demonstrate that deep transformers are universal and can approximate continuous in-context mappings to arbitrary precision, uniformly over compact token domains. A key aspect of our results, compared to existing findings, is that for a fixed precision, a single transformer can operate on an arbitrary (even infinite) number of tokens. Additionally, it operates with a fixed embedding dimension of tokens (this dimension does not increase with precision) and a fixed number of heads (proportional to the dimension). The use of MLP layers between multi-head attention layers is also explicitly controlled.
Taming Score-Based Diffusion Priors for Infinite-Dimensional Nonlinear Inverse Problems
May 24, 2024

This work introduces a sampling method capable of solving Bayesian inverse problems in function space. It does not assume the log-concavity of the likelihood, meaning that it is compatible with nonlinear inverse problems. The method leverages the recently defined infinite-dimensional score-based diffusion models as a learning-based prior, while enabling provable posterior sampling through a Langevin-type MCMC algorithm defined on function spaces. A novel convergence analysis is conducted, inspired by the fixed-point methods established for traditional regularization-by-denoising algorithms and compatible with weighted annealing. The obtained convergence bound explicitly depends on the approximation error of the score; a well-approximated score is essential to obtain a well-approximated posterior. Stylized and PDE-based examples are provided, demonstrating the validity of our convergence analysis. We conclude by presenting a discussion of the method's challenges related to learning the score and computational complexity.