 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
A Unified and General Framework for Continual Learning
Mar 20, 2024
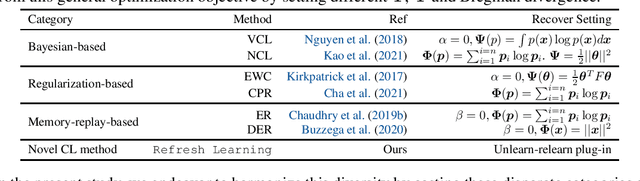
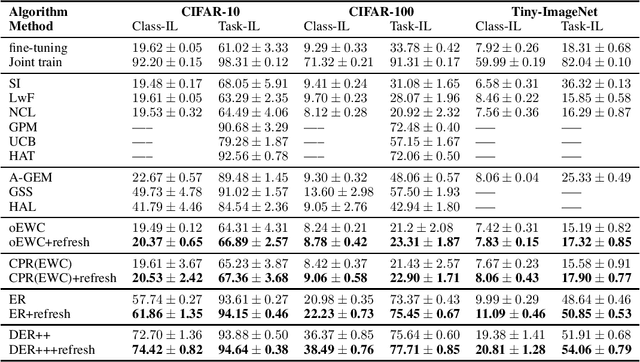
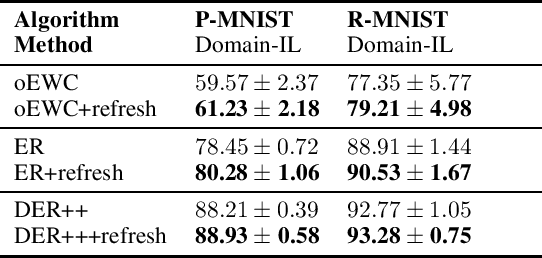

Continual Learning (CL) focuses on learning from dynamic and changing data distributions while retaining previously acquired knowledge. Various methods have been developed to address the challenge of catastrophic forgetting, including regularization-based, Bayesian-based, and memory-replay-based techniques. However, these methods lack a unified framework and common terminology for describing their approaches. This research aims to bridge this gap by introducing a comprehensive and overarching framework that encompasses and reconciles these existing methodologies. Notably, this new framework is capable of encompassing established CL approaches as special instances within a unified and general optimization objective. An intriguing finding is that despite their diverse origins, these methods share common mathematical structures. This observation highlights the compatibility of these seemingly distinct techniques, revealing their interconnectedness through a shared underlying optimization objective. Moreover, the proposed general framework introduces an innovative concept called refresh learning, specifically designed to enhance the CL performance. This novel approach draws inspiration from neuroscience, where the human brain often sheds outdated information to improve the retention of crucial knowledge and facilitate the acquisition of new information. In essence, refresh learning operates by initially unlearning current data and subsequently relearning it. It serves as a versatile plug-in that seamlessly integrates with existing CL methods, offering an adaptable and effective enhancement to the learning process. Extensive experiments on CL benchmarks and theoretical analysis demonstrate the effectiveness of the proposed refresh learning. Code is available at \url{https://github.com/joey-wang123/CL-refresh-learning}.
Learning-augmented Online Minimization of Age of Information and Transmission Costs
Mar 05, 2024
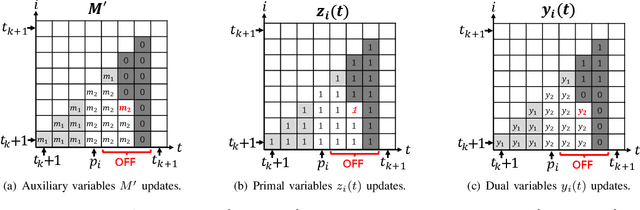
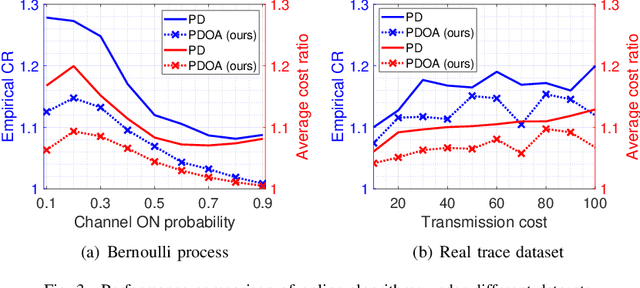
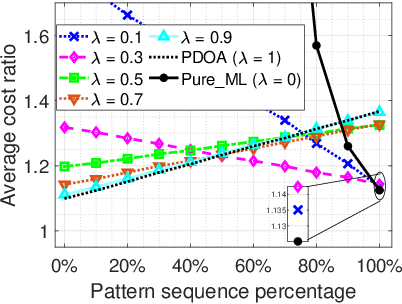
We consider a discrete-time system where a resource-constrained source (e.g., a small sensor) transmits its time-sensitive data to a destination over a time-varying wireless channel. Each transmission incurs a fixed transmission cost (e.g., energy cost), and no transmission results in a staleness cost represented by the Age-of-Information. The source must balance the tradeoff between transmission and staleness costs. To address this challenge, we develop a robust online algorithm to minimize the sum of transmission and staleness costs, ensuring a worst-case performance guarantee. While online algorithms are robust, they are usually overly conservative and may have a poor average performance in typical scenarios. In contrast, by leveraging historical data and prediction models, machine learning (ML) algorithms perform well in average cases. However, they typically lack worst-case performance guarantees. To achieve the best of both worlds, we design a learning-augmented online algorithm that exhibits two desired properties: (i) consistency: closely approximating the optimal offline algorithm when the ML prediction is accurate and trusted; (ii) robustness: ensuring worst-case performance guarantee even ML predictions are inaccurate. Finally, we perform extensive simulations to show that our online algorithm performs well empirically and that our learning-augmented algorithm achieves both consistency and robustness.
Combining Local and Global Perception for Autonomous Navigation on Nano-UAVs
Mar 18, 2024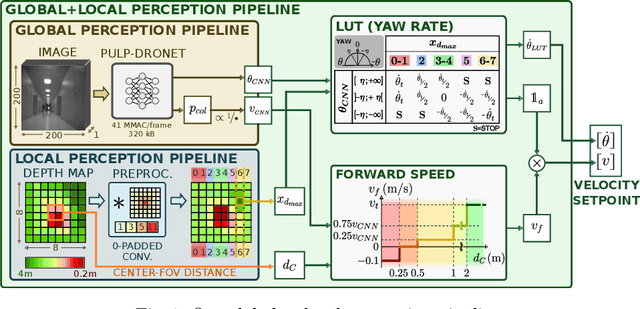

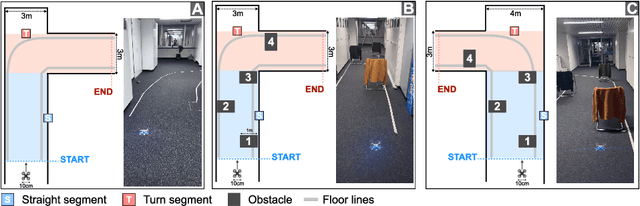
A critical challenge in deploying unmanned aerial vehicles (UAVs) for autonomous tasks is their ability to navigate in an unknown environment. This paper introduces a novel vision-depth fusion approach for autonomous navigation on nano-UAVs. We combine the visual-based PULP-Dronet convolutional neural network for semantic information extraction, i.e., serving as the global perception, with 8x8px depth maps for close-proximity maneuvers, i.e., the local perception. When tested in-field, our integration strategy highlights the complementary strengths of both visual and depth sensory information. We achieve a 100% success rate over 15 flights in a complex navigation scenario, encompassing straight pathways, static obstacle avoidance, and 90{\deg} turns.
Raw Instinct: Trust Your Classifiers and Skip the Conversion
Mar 21, 2024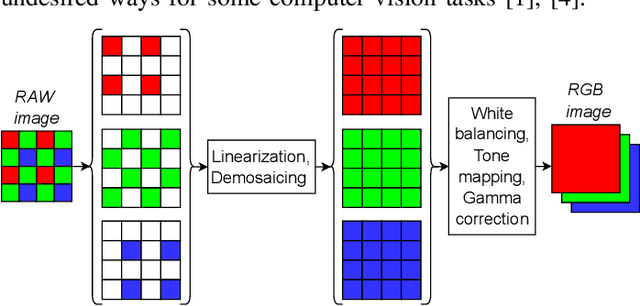
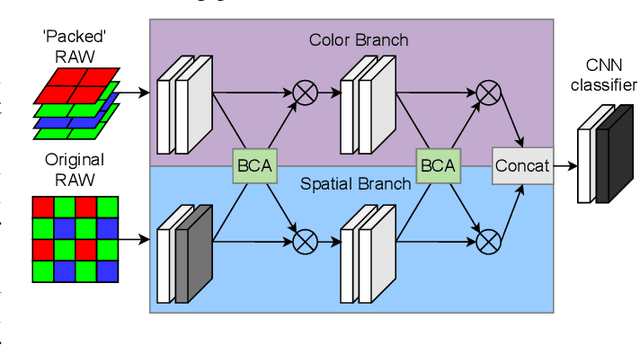

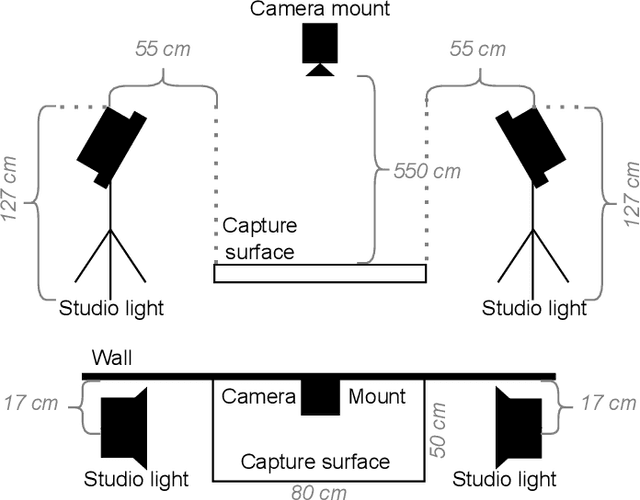
Using RAW-images in computer vision problems is surprisingly underexplored considering that converting from RAW to RGB does not introduce any new capture information. In this paper, we show that a sufficiently advanced classifier can yield equivalent results on RAW input compared to RGB and present a new public dataset consisting of RAW images and the corresponding converted RGB images. Classifying images directly from RAW is attractive, as it allows for skipping the conversion to RGB, lowering computation time significantly. Two CNN classifiers are used to classify the images in both formats, confirming that classification performance can indeed be preserved. We furthermore show that the total computation time from RAW image data to classification results for RAW images can be up to 8.46 times faster than RGB. These results contribute to the evidence found in related works, that using RAW images as direct input to computer vision algorithms looks very promising.
* https://www.kaggle.com/datasets/mathiasviborg/raw-instinct
Varroa destructor detection on honey bees using hyperspectral imagery
Mar 21, 2024
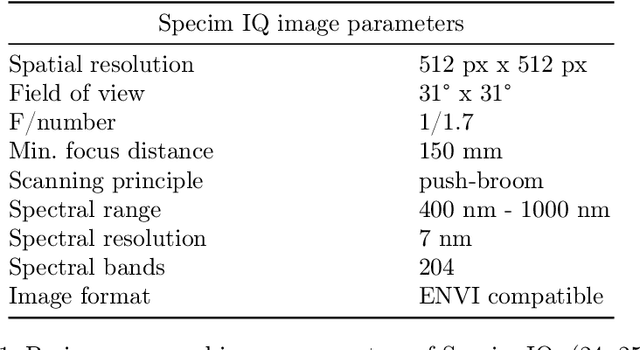


Hyperspectral (HS) imagery in agriculture is becoming increasingly common. These images have the advantage of higher spectral resolution. Advanced spectral processing techniques are required to unlock the information potential in these HS images. The present paper introduces a method rooted in multivariate statistics designed to detect parasitic Varroa destructor mites on the body of western honey bee Apis mellifera, enabling easier and continuous monitoring of the bee hives. The methodology explores unsupervised (K-means++) and recently developed supervised (Kernel Flows - Partial Least-Squares, KF-PLS) methods for parasitic identification. Additionally, in light of the emergence of custom-band multispectral cameras, the present research outlines a strategy for identifying the specific wavelengths necessary for effective bee-mite separation, suitable for implementation in a custom-band camera. Illustrated with a real-case dataset, our findings demonstrate that as few as four spectral bands are sufficient for accurate parasite identification.
Large Language Models Powered Context-aware Motion Prediction
Mar 17, 2024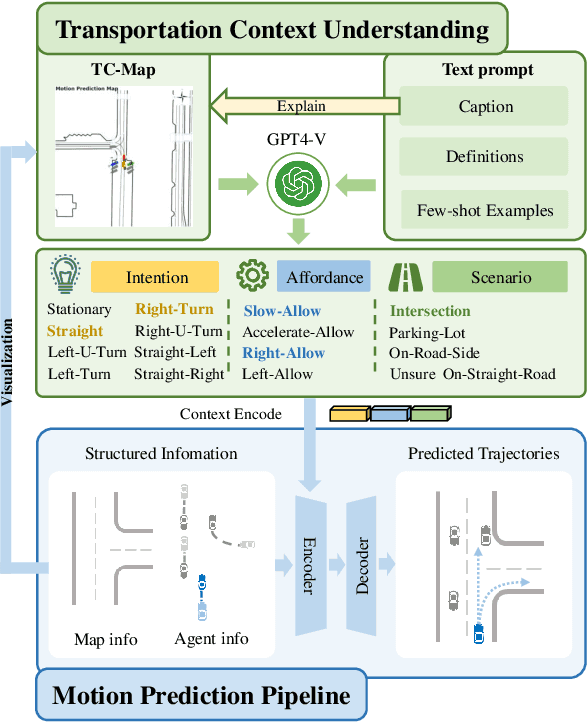
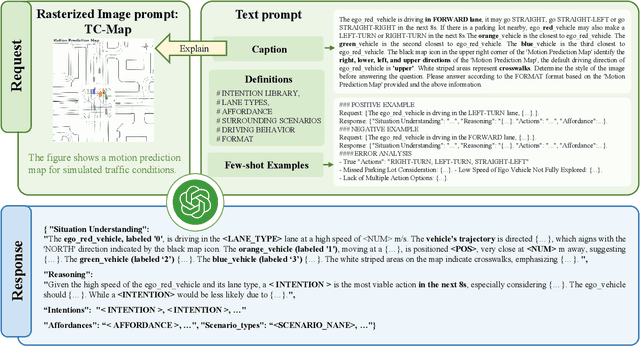
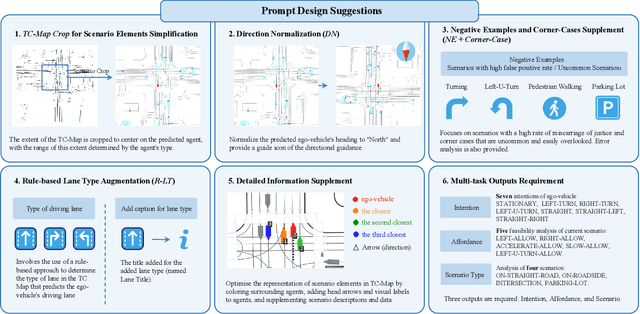
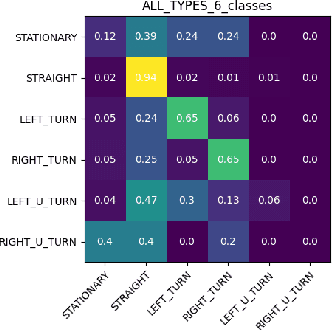
Motion prediction is among the most fundamental tasks in autonomous driving. Traditional methods of motion forecasting primarily encode vector information of maps and historical trajectory data of traffic participants, lacking a comprehensive understanding of overall traffic semantics, which in turn affects the performance of prediction tasks. In this paper, we utilized Large Language Models (LLMs) to enhance the global traffic context understanding for motion prediction tasks. We first conducted systematic prompt engineering, visualizing complex traffic environments and historical trajectory information of traffic participants into image prompts -- Transportation Context Map (TC-Map), accompanied by corresponding text prompts. Through this approach, we obtained rich traffic context information from the LLM. By integrating this information into the motion prediction model, we demonstrate that such context can enhance the accuracy of motion predictions. Furthermore, considering the cost associated with LLMs, we propose a cost-effective deployment strategy: enhancing the accuracy of motion prediction tasks at scale with 0.7\% LLM-augmented datasets. Our research offers valuable insights into enhancing the understanding of traffic scenes of LLMs and the motion prediction performance of autonomous driving.
Approximation and bounding techniques for the Fisher-Rao distances
Mar 19, 2024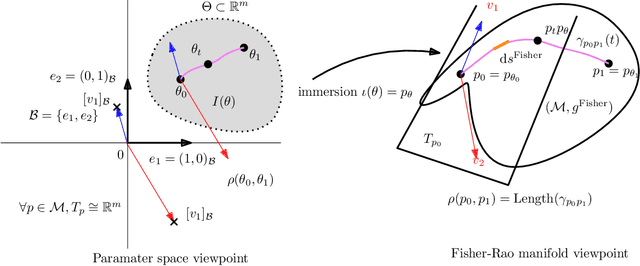
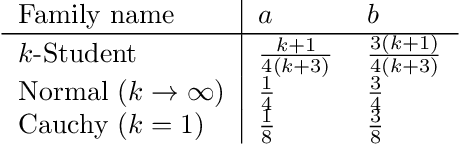
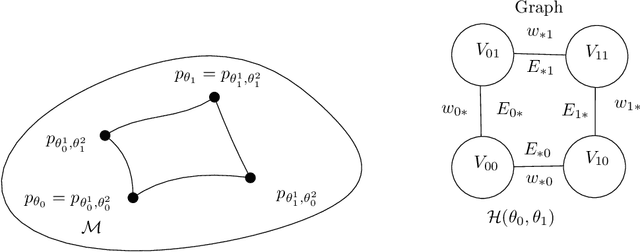
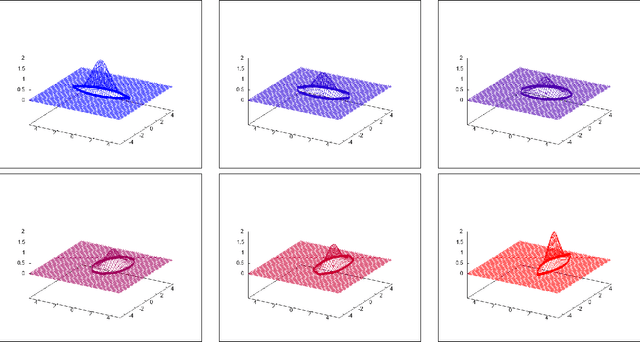
The Fisher-Rao distance between two probability distributions of a statistical model is defined as the Riemannian geodesic distance induced by the Fisher information metric. In order to calculate the Fisher-Rao distance in closed-form, we need (1) to elicit a formula for the Fisher-Rao geodesics, and (2) to integrate the Fisher length element along those geodesics. We consider several numerically robust approximation and bounding techniques for the Fisher-Rao distances: First, we report generic upper bounds on Fisher-Rao distances based on closed-form 1D Fisher-Rao distances of submodels. Second, we describe several generic approximation schemes depending on whether the Fisher-Rao geodesics or pregeodesics are available in closed-form or not. In particular, we obtain a generic method to guarantee an arbitrarily small additive error on the approximation provided that Fisher-Rao pregeodesics and tight lower and upper bounds are available. Third, we consider the case of Fisher metrics being Hessian metrics, and report generic tight upper bounds on the Fisher-Rao distances using techniques of information geometry. Uniparametric and biparametric statistical models always have Fisher Hessian metrics, and in general a simple test allows to check whether the Fisher information matrix yields a Hessian metric or not. Fourth, we consider elliptical distribution families and show how to apply the above techniques to these models. We also propose two new distances based either on the Fisher-Rao lengths of curves serving as proxies of Fisher-Rao geodesics, or based on the Birkhoff/Hilbert projective cone distance. Last, we consider an alternative group-theoretic approach for statistical transformation models based on the notion of maximal invariant which yields insights on the structures of the Fisher-Rao distance formula which may be used fruitfully in applications.
TAPTR: Tracking Any Point with Transformers as Detection
Mar 19, 2024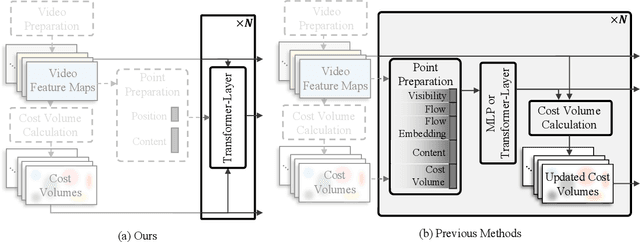
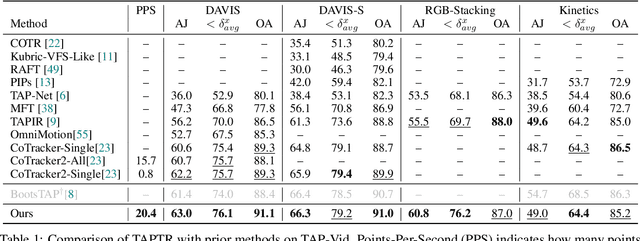
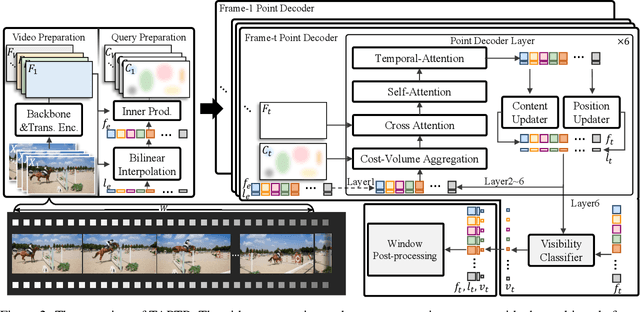

In this paper, we propose a simple and strong framework for Tracking Any Point with TRansformers (TAPTR). Based on the observation that point tracking bears a great resemblance to object detection and tracking, we borrow designs from DETR-like algorithms to address the task of TAP. In the proposed framework, in each video frame, each tracking point is represented as a point query, which consists of a positional part and a content part. As in DETR, each query (its position and content feature) is naturally updated layer by layer. Its visibility is predicted by its updated content feature. Queries belonging to the same tracking point can exchange information through self-attention along the temporal dimension. As all such operations are well-designed in DETR-like algorithms, the model is conceptually very simple. We also adopt some useful designs such as cost volume from optical flow models and develop simple designs to provide long temporal information while mitigating the feature drifting issue. Our framework demonstrates strong performance with state-of-the-art performance on various TAP datasets with faster inference speed.
Prompt-fused framework for Inductive Logical Query Answering
Mar 19, 2024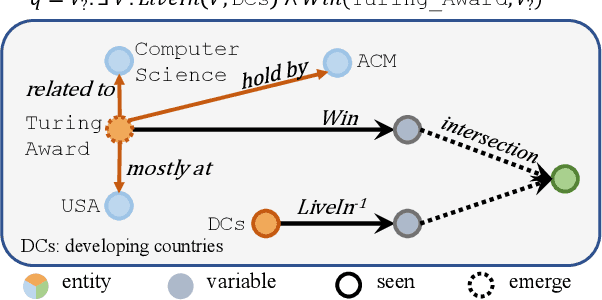

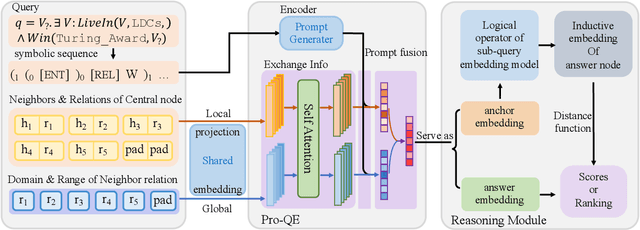
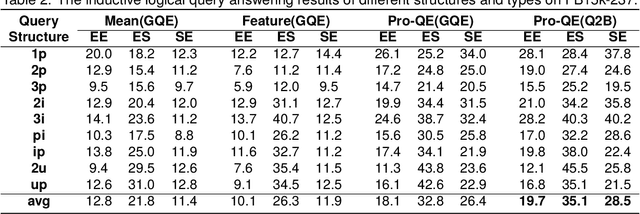
Answering logical queries on knowledge graphs (KG) poses a significant challenge for machine reasoning. The primary obstacle in this task stems from the inherent incompleteness of KGs. Existing research has predominantly focused on addressing the issue of missing edges in KGs, thereby neglecting another aspect of incompleteness: the emergence of new entities. Furthermore, most of the existing methods tend to reason over each logical operator separately, rather than comprehensively analyzing the query as a whole during the reasoning process. In this paper, we propose a query-aware prompt-fused framework named Pro-QE, which could incorporate existing query embedding methods and address the embedding of emerging entities through contextual information aggregation. Additionally, a query prompt, which is generated by encoding the symbolic query, is introduced to gather information relevant to the query from a holistic perspective. To evaluate the efficacy of our model in the inductive setting, we introduce two new challenging benchmarks. Experimental results demonstrate that our model successfully handles the issue of unseen entities in logical queries. Furthermore, the ablation study confirms the efficacy of the aggregator and prompt components.
PseudoTouch: Efficiently Imaging the Surface Feel of Objects for Robotic Manipulation
Mar 22, 2024Humans seemingly incorporate potential touch signals in their perception. Our goal is to equip robots with a similar capability, which we term \ourmodel. \ourmodel aims to predict the expected touch signal based on a visual patch representing the touched area. We frame this problem as the task of learning a low-dimensional visual-tactile embedding, wherein we encode a depth patch from which we decode the tactile signal. To accomplish this task, we employ ReSkin, an inexpensive and replaceable magnetic-based tactile sensor. Using ReSkin, we collect and train PseudoTouch on a dataset comprising aligned tactile and visual data pairs obtained through random touching of eight basic geometric shapes. We demonstrate the efficacy of PseudoTouch through its application to two downstream tasks: object recognition and grasp stability prediction. In the object recognition task, we evaluate the learned embedding's performance on a set of five basic geometric shapes and five household objects. Using PseudoTouch, we achieve an object recognition accuracy 84% after just ten touches, surpassing a proprioception baseline. For the grasp stability task, we use ACRONYM labels to train and evaluate a grasp success predictor using PseudoTouch's predictions derived from virtual depth information. Our approach yields an impressive 32% absolute improvement in accuracy compared to the baseline relying on partial point cloud data. We make the data, code, and trained models publicly available at http://pseudotouch.cs.uni-freiburg.de.