 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWISP: Waste- and Interference-Suppressed Distributed Speculative LLM Serving at the Edge via Dynamic Drafting and SLO-Aware Batching
Jan 15, 2026As Large Language Models (LLMs) become increasingly accessible to end users, an ever-growing number of inference requests are initiated from edge devices and computed on centralized GPU clusters. However, the resulting exponential growth in computation workload is placing significant strain on data centers, while edge devices remain largely underutilized, leading to imbalanced workloads and resource inefficiency across the network. Integrating edge devices into the LLM inference process via speculative decoding helps balance the workload between the edge and the cloud, while maintaining lossless prediction accuracy. In this paper, we identify and formalize two critical bottlenecks that limit the efficiency and scalability of distributed speculative LLM serving: Wasted Drafting Time and Verification Interference. To address these challenges, we propose WISP, an efficient and SLO-aware distributed LLM inference system that consists of an intelligent speculation controller, a verification time estimator, and a verification batch scheduler. These components collaboratively enhance drafting efficiency and optimize verification request scheduling on the server. Extensive numerical results show that WISP improves system capacity by up to 2.1x and 4.1x, and increases system goodput by up to 1.94x and 3.7x, compared to centralized serving and SLED, respectively.
Optimizing Resource Allocation for Geographically-Distributed Inference by Large Language Models
Dec 26, 2025Large language models have demonstrated extraordinary performance in many AI tasks but are expensive to use, even after training, due to their requirement of high-end GPUs. Recently, a distributed system called PETALS was developed to lower the barrier for deploying LLMs by splitting the model blocks across multiple servers with low-end GPUs distributed over the Internet, which was much faster than swapping the model parameters between the GPU memory and other cheaper but slower local storage media. However, the performance of such a distributed system critically depends on the resource allocation, and how to do so optimally remains unknown. In this work, we present the first systematic study of the resource allocation problem in distributed LLM inference, with focus on two important decisions: block placement and request routing. Our main results include: experimentally validated performance models that can predict the inference performance under given block placement and request routing decisions, a formulation of the offline optimization of block placement and request routing as a mixed integer linear programming problem together with the NP-hardness proof and a polynomial-complexity algorithm with guaranteed performance, and an adaptation of the offline algorithm for the online setting with the same performance guarantee under bounded load. Through both experiments and experimentally-validated simulations, we have verified that the proposed solution can substantially reduce the inference time compared to the state-of-the-art solution in diverse settings with geographically-distributed servers. As a byproduct, we have also developed a light-weighted CPU-only simulator capable of predicting the performance of distributed LLM inference on GPU servers, which can evaluate large deployments and facilitate future research for researchers with limited GPU access.
iMAD: Intelligent Multi-Agent Debate for Efficient and Accurate LLM Inference
Nov 14, 2025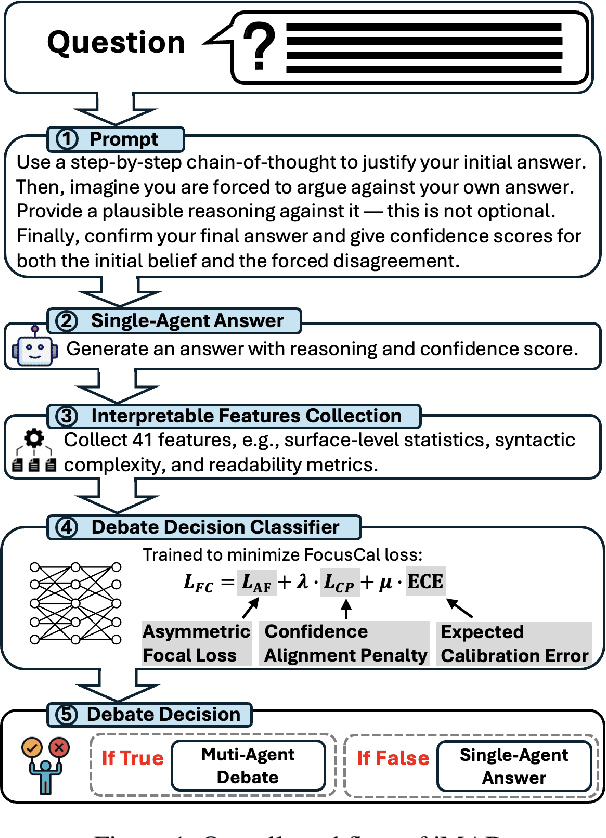
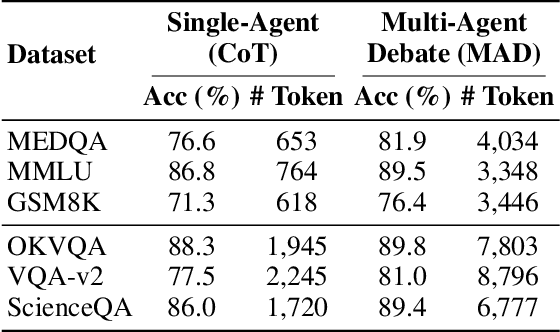
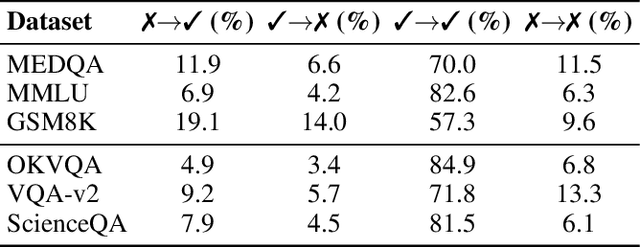
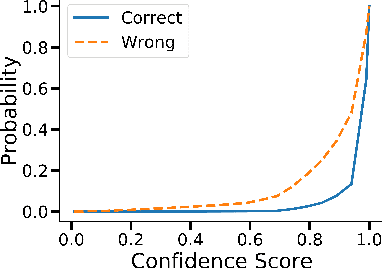
Large Language Model (LLM) agent systems have advanced rapidly, driven by their strong generalization in zero-shot settings. To further enhance reasoning and accuracy on complex tasks, Multi-Agent Debate (MAD) has emerged as a promising framework that engages multiple LLM agents in structured debates to encourage diverse reasoning. However, triggering MAD for every query is inefficient, as it incurs substantial computational (token) cost and may even degrade accuracy by overturning correct single-agent answers. To address these limitations, we propose intelligent Multi-Agent Debate (iMAD), a token-efficient framework that selectively triggers MAD only when it is likely to be beneficial (i.e., correcting an initially wrong answer). To achieve this goal, iMAD learns generalizable model behaviors to make accurate debate decisions. Specifically, iMAD first prompts a single agent to produce a structured self-critique response, from which we extract 41 interpretable linguistic and semantic features capturing hesitation cues. Then, iMAD uses a lightweight debate-decision classifier, trained using our proposed FocusCal loss, to determine whether to trigger MAD, enabling robust debate decisions without test dataset-specific tuning. Through extensive experiments using six (visual) question answering datasets against five competitive baselines, we have shown that iMAD significantly reduces token usage (by up to 92%) while also improving final answer accuracy (by up to 13.5%).
Multimodal Remote Inference
Aug 11, 2025We consider a remote inference system with multiple modalities, where a multimodal machine learning (ML) model performs real-time inference using features collected from remote sensors. As sensor observations may change dynamically over time, fresh features are critical for inference tasks. However, timely delivering features from all modalities is often infeasible due to limited network resources. To this end, we study a two-modality scheduling problem to minimize the ML model's inference error, which is expressed as a penalty function of AoI for both modalities. We develop an index-based threshold policy and prove its optimality. Specifically, the scheduler switches modalities when the current modality's index function exceeds a threshold. We show that the two modalities share the same threshold, and both the index functions and the threshold can be computed efficiently. The optimality of our policy holds for (i) general AoI functions that are \emph{non-monotonic} and \emph{non-additive} and (ii) \emph{heterogeneous} transmission times. Numerical results show that our policy reduces inference error by up to 55% compared to round-robin and uniform random policies, which are oblivious to the AoI-based inference error function. Our results shed light on how to improve remote inference accuracy by optimizing task-oriented AoI functions.
P3SL: Personalized Privacy-Preserving Split Learning on Heterogeneous Edge Devices
Jul 23, 2025



Split Learning (SL) is an emerging privacy-preserving machine learning technique that enables resource constrained edge devices to participate in model training by partitioning a model into client-side and server-side sub-models. While SL reduces computational overhead on edge devices, it encounters significant challenges in heterogeneous environments where devices vary in computing resources, communication capabilities, environmental conditions, and privacy requirements. Although recent studies have explored heterogeneous SL frameworks that optimize split points for devices with varying resource constraints, they often neglect personalized privacy requirements and local model customization under varying environmental conditions. To address these limitations, we propose P3SL, a Personalized Privacy-Preserving Split Learning framework designed for heterogeneous, resource-constrained edge device systems. The key contributions of this work are twofold. First, we design a personalized sequential split learning pipeline that allows each client to achieve customized privacy protection and maintain personalized local models tailored to their computational resources, environmental conditions, and privacy needs. Second, we adopt a bi-level optimization technique that empowers clients to determine their own optimal personalized split points without sharing private sensitive information (i.e., computational resources, environmental conditions, privacy requirements) with the server. This approach balances energy consumption and privacy leakage risks while maintaining high model accuracy. We implement and evaluate P3SL on a testbed consisting of 7 devices including 4 Jetson Nano P3450 devices, 2 Raspberry Pis, and 1 laptop, using diverse model architectures and datasets under varying environmental conditions.
On the Low-Complexity of Fair Learning for Combinatorial Multi-Armed Bandit
Jan 04, 2025



Combinatorial Multi-Armed Bandit with fairness constraints is a framework where multiple arms form a super arm and can be pulled in each round under uncertainty to maximize cumulative rewards while ensuring the minimum average reward required by each arm. The existing pessimistic-optimistic algorithm linearly combines virtual queue-lengths (tracking the fairness violations) and Upper Confidence Bound estimates as a weight for each arm and selects a super arm with the maximum total weight. The number of super arms could be exponential to the number of arms in many scenarios. In wireless networks, interference constraints can cause the number of super arms to grow exponentially with the number of arms. Evaluating all the feasible super arms to find the one with the maximum total weight can incur extremely high computational complexity in the pessimistic-optimistic algorithm. To avoid this, we develop a low-complexity fair learning algorithm based on the so-called pick-and-compare approach that involves randomly picking $M$ feasible super arms to evaluate. By setting $M$ to a constant, the number of comparison steps in the pessimistic-optimistic algorithm can be reduced to a constant, thereby significantly reducing the computational complexity. Our theoretical proof shows this low-complexity design incurs only a slight sacrifice in fairness and regret performance. Finally, we validate the theoretical result by extensive simulations.
HS-FPN: High Frequency and Spatial Perception FPN for Tiny Object Detection
Dec 13, 2024



The introduction of Feature Pyramid Network (FPN) has significantly improved object detection performance. However, substantial challenges remain in detecting tiny objects, as their features occupy only a very small proportion of the feature maps. Although FPN integrates multi-scale features, it does not directly enhance or enrich the features of tiny objects. Furthermore, FPN lacks spatial perception ability. To address these issues, we propose a novel High Frequency and Spatial Perception Feature Pyramid Network (HS-FPN) with two innovative modules. First, we designed a high frequency perception module (HFP) that generates high frequency responses through high pass filters. These high frequency responses are used as mask weights from both spatial and channel perspectives to enrich and highlight the features of tiny objects in the original feature maps. Second, we developed a spatial dependency perception module (SDP) to capture the spatial dependencies that FPN lacks. Our experiments demonstrate that detectors based on HS-FPN exhibit competitive advantages over state-of-the-art models on the AI-TOD dataset for tiny object detection.
LocalSR: Image Super-Resolution in Local Region
Dec 05, 2024



Standard single-image super-resolution (SR) upsamples and restores entire images. Yet several real-world applications require higher resolutions only in specific regions, such as license plates or faces, making the super-resolution of the entire image, along with the associated memory and computational cost, unnecessary. We propose a novel task, called LocalSR, to restore only local regions of the low-resolution image. For this problem setting, we propose a context-based local super-resolution (CLSR) to super-resolve only specified regions of interest (ROI) while leveraging the entire image as context. Our method uses three parallel processing modules: a base module for super-resolving the ROI, a global context module for gathering helpful features from across the image, and a proximity integration module for concentrating on areas surrounding the ROI, progressively propagating features from distant pixels to the target region. Experimental results indicate that our approach, with its reduced low complexity, outperforms variants that focus exclusively on the ROI.
Adaptive High-Pass Kernel Prediction for Efficient Video Deblurring
Dec 02, 2024



State-of-the-art video deblurring methods use deep network architectures to recover sharpened video frames. Blurring especially degrades high-frequency (HF) information, yet this aspect is often overlooked by recent models that focus more on enhancing architectural design. Recovering these fine details is challenging, partly due to the spectral bias of neural networks, which are inclined towards learning low-frequency functions. To address this, we enforce explicit network structures to capture the fine details and edges. We dynamically predict adaptive high-pass kernels from a linear combination of high-pass basis kernels to extract high-frequency features. This strategy is highly efficient, resulting in low-memory footprints for training and fast run times for inference, all while achieving state-of-the-art when compared to low-budget models. The code is available at https://github.com/jibo27/AHFNet.
SfM-Free 3D Gaussian Splatting via Hierarchical Training
Dec 02, 2024



Standard 3D Gaussian Splatting (3DGS) relies on known or pre-computed camera poses and a sparse point cloud, obtained from structure-from-motion (SfM) preprocessing, to initialize and grow 3D Gaussians. We propose a novel SfM-Free 3DGS (SFGS) method for video input, eliminating the need for known camera poses and SfM preprocessing. Our approach introduces a hierarchical training strategy that trains and merges multiple 3D Gaussian representations -- each optimized for specific scene regions -- into a single, unified 3DGS model representing the entire scene. To compensate for large camera motions, we leverage video frame interpolation models. Additionally, we incorporate multi-source supervision to reduce overfitting and enhance representation. Experimental results reveal that our approach significantly surpasses state-of-the-art SfM-free novel view synthesis methods. On the Tanks and Temples dataset, we improve PSNR by an average of 2.25dB, with a maximum gain of 3.72dB in the best scene. On the CO3D-V2 dataset, we achieve an average PSNR boost of 1.74dB, with a top gain of 3.90dB. The code is available at https://github.com/jibo27/3DGS_Hierarchical_Training.