 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Human-imperceptible, Machine-recognizable Images
Jun 06, 2023

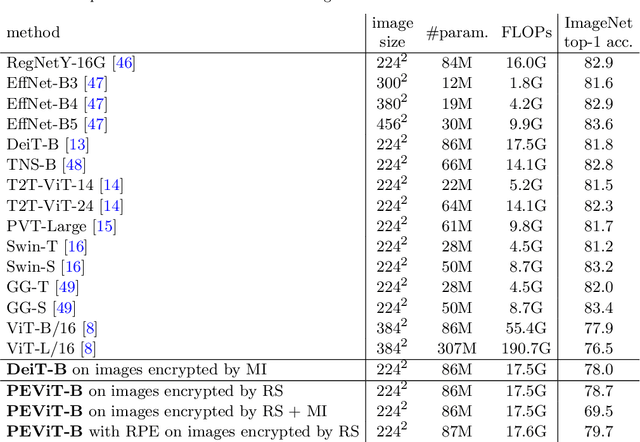
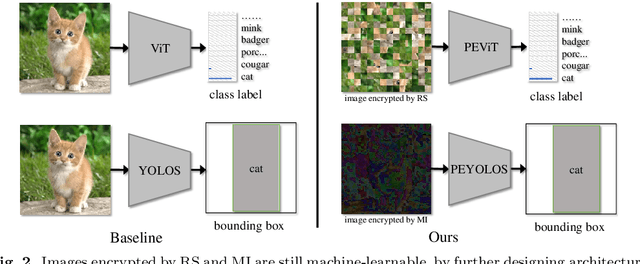
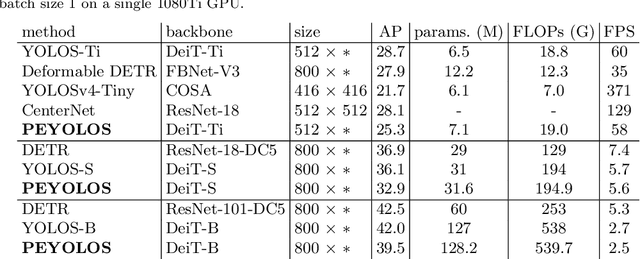
Massive human-related data is collected to train neural networks for computer vision tasks. A major conflict is exposed relating to software engineers between better developing AI systems and distancing from the sensitive training data. To reconcile this conflict, this paper proposes an efficient privacy-preserving learning paradigm, where images are first encrypted to become ``human-imperceptible, machine-recognizable'' via one of the two encryption strategies: (1) random shuffling to a set of equally-sized patches and (2) mixing-up sub-patches of the images. Then, minimal adaptations are made to vision transformer to enable it to learn on the encrypted images for vision tasks, including image classification and object detection. Extensive experiments on ImageNet and COCO show that the proposed paradigm achieves comparable accuracy with the competitive methods. Decrypting the encrypted images requires solving an NP-hard jigsaw puzzle or an ill-posed inverse problem, which is empirically shown intractable to be recovered by various attackers, including the powerful vision transformer-based attacker. We thus show that the proposed paradigm can ensure the encrypted images have become human-imperceptible while preserving machine-recognizable information. The code is available at \url{https://github.com/FushengHao/PrivacyPreservingML.}
A Novel Approach To User Agent String Parsing For Vulnerability Analysis Using Mutli-Headed Attention
Jun 06, 2023
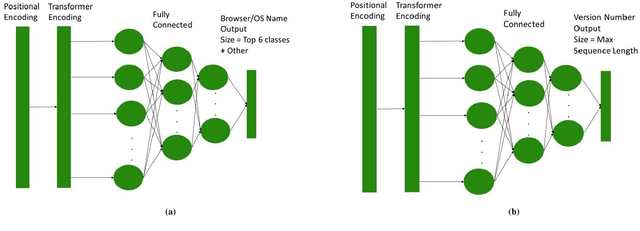
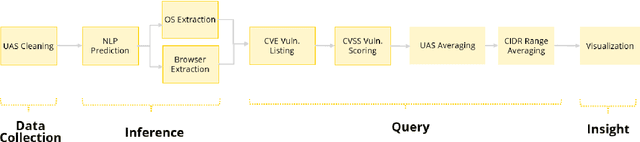

The increasing reliance on the internet has led to the proliferation of a diverse set of web-browsers and operating systems (OSs) capable of browsing the web. User agent strings (UASs) are a component of web browsing that are transmitted with every Hypertext Transfer Protocol (HTTP) request. They contain information about the client device and software, which is used by web servers for various purposes such as content negotiation and security. However, due to the proliferation of various browsers and devices, parsing UASs is a non-trivial task due to a lack of standardization of UAS formats. Current rules-based approaches are often brittle and can fail when encountering such non-standard formats. In this work, a novel methodology for parsing UASs using Multi-Headed Attention Based transformers is proposed. The proposed methodology exhibits strong performance in parsing a variety of UASs with differing formats. Furthermore, a framework to utilize parsed UASs to estimate the vulnerability scores for large sections of publicly visible IT networks or regions is also discussed. The methodology present here can also be easily extended or deployed for real-time parsing of logs in enterprise settings.
MetaGait: Learning to Learn an Omni Sample Adaptive Representation for Gait Recognition
Jun 06, 2023Gait recognition, which aims at identifying individuals by their walking patterns, has recently drawn increasing research attention. However, gait recognition still suffers from the conflicts between the limited binary visual clues of the silhouette and numerous covariates with diverse scales, which brings challenges to the model's adaptiveness. In this paper, we address this conflict by developing a novel MetaGait that learns to learn an omni sample adaptive representation. Towards this goal, MetaGait injects meta-knowledge, which could guide the model to perceive sample-specific properties, into the calibration network of the attention mechanism to improve the adaptiveness from the omni-scale, omni-dimension, and omni-process perspectives. Specifically, we leverage the meta-knowledge across the entire process, where Meta Triple Attention and Meta Temporal Pooling are presented respectively to adaptively capture omni-scale dependency from spatial/channel/temporal dimensions simultaneously and to adaptively aggregate temporal information through integrating the merits of three complementary temporal aggregation methods. Extensive experiments demonstrate the state-of-the-art performance of the proposed MetaGait. On CASIA-B, we achieve rank-1 accuracy of 98.7%, 96.0%, and 89.3% under three conditions, respectively. On OU-MVLP, we achieve rank-1 accuracy of 92.4%.
Can Transformers Learn to Solve Problems Recursively?
May 24, 2023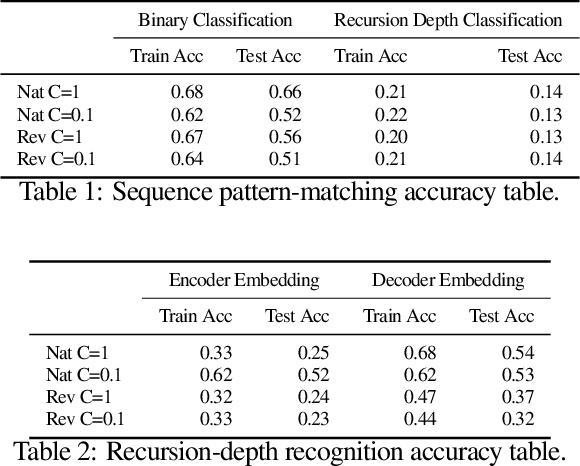
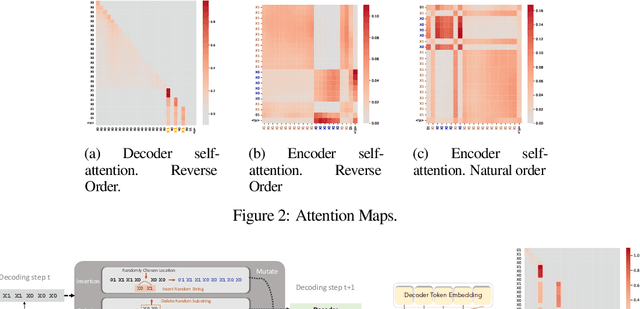
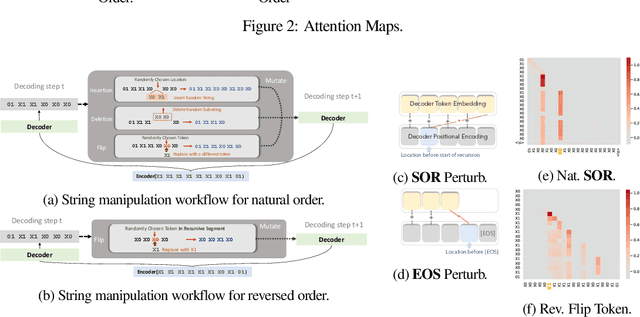
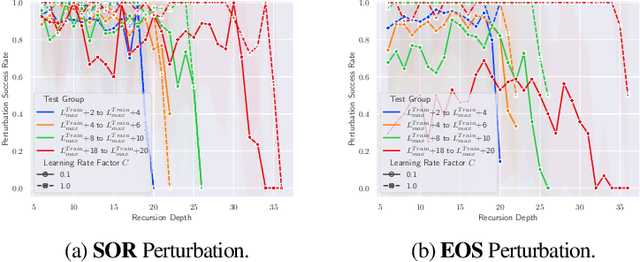
Neural networks have in recent years shown promise for helping software engineers write programs and even formally verify them. While semantic information plays a crucial part in these processes, it remains unclear to what degree popular neural architectures like transformers are capable of modeling that information. This paper examines the behavior of neural networks learning algorithms relevant to programs and formal verification proofs through the lens of mechanistic interpretability, focusing in particular on structural recursion. Structural recursion is at the heart of tasks on which symbolic tools currently outperform neural models, like inferring semantic relations between datatypes and emulating program behavior. We evaluate the ability of transformer models to learn to emulate the behavior of structurally recursive functions from input-output examples. Our evaluation includes empirical and conceptual analyses of the limitations and capabilities of transformer models in approximating these functions, as well as reconstructions of the ``shortcut" algorithms the model learns. By reconstructing these algorithms, we are able to correctly predict 91 percent of failure cases for one of the approximated functions. Our work provides a new foundation for understanding the behavior of neural networks that fail to solve the very tasks they are trained for.
HiTIN: Hierarchy-aware Tree Isomorphism Network for Hierarchical Text Classification
May 24, 2023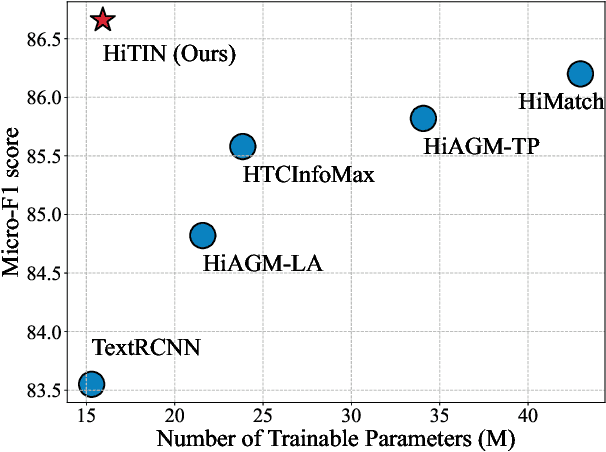

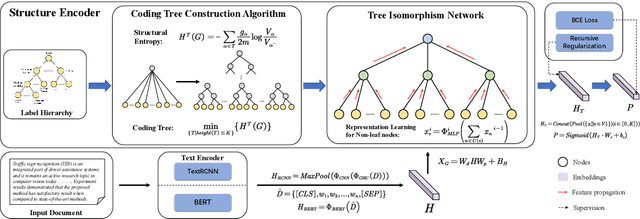

Hierarchical text classification (HTC) is a challenging subtask of multi-label classification as the labels form a complex hierarchical structure. Existing dual-encoder methods in HTC achieve weak performance gains with huge memory overheads and their structure encoders heavily rely on domain knowledge. Under such observation, we tend to investigate the feasibility of a memory-friendly model with strong generalization capability that could boost the performance of HTC without prior statistics or label semantics. In this paper, we propose Hierarchy-aware Tree Isomorphism Network (HiTIN) to enhance the text representations with only syntactic information of the label hierarchy. Specifically, we convert the label hierarchy into an unweighted tree structure, termed coding tree, with the guidance of structural entropy. Then we design a structure encoder to incorporate hierarchy-aware information in the coding tree into text representations. Besides the text encoder, HiTIN only contains a few multi-layer perceptions and linear transformations, which greatly saves memory. We conduct experiments on three commonly used datasets and the results demonstrate that HiTIN could achieve better test performance and less memory consumption than state-of-the-art (SOTA) methods.
Enabling Large Language Models to Generate Text with Citations
May 24, 2023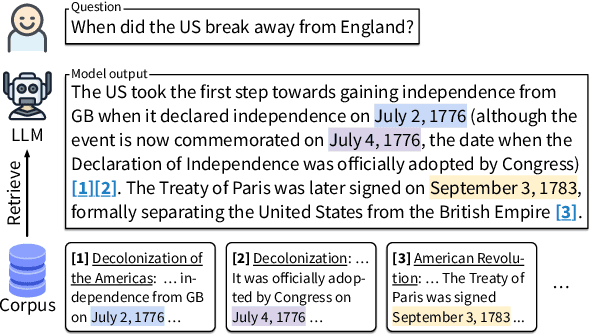

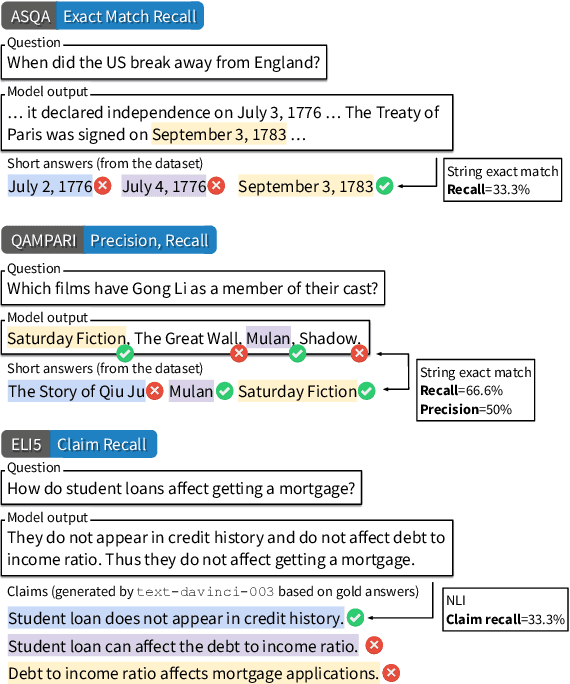

Large language models (LLMs) have emerged as a widely-used tool for information seeking, but their generated outputs are prone to hallucination. In this work, we aim to enable LLMs to generate text with citations, improving their factual correctness and verifiability. Existing work mainly relies on commercial search engines and human evaluation, making it challenging to reproduce and compare with different modeling approaches. We propose ALCE, the first benchmark for Automatic LLMs' Citation Evaluation. ALCE collects a diverse set of questions and retrieval corpora and requires building end-to-end systems to retrieve supporting evidence and generate answers with citations. We build automatic metrics along three dimensions -- fluency, correctness, and citation quality -- and demonstrate their strong correlation with human judgements. Our experiments with state-of-the-art LLMs and novel prompting strategies show that current systems have considerable room for improvements -- for example, on the ELI5 dataset, even the best model has 49% of its generations lacking complete citation support. Our extensive analyses further highlight promising future directions, including developing better retrievers, advancing long-context LLMs, and improving the ability to synthesize information from multiple sources.
Jointly Optimizing Image Compression with Low-light Image Enhancement
May 24, 2023
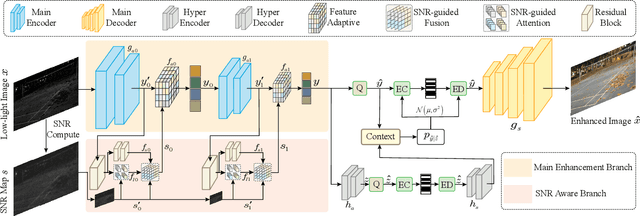
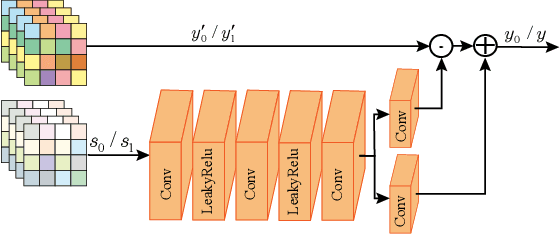
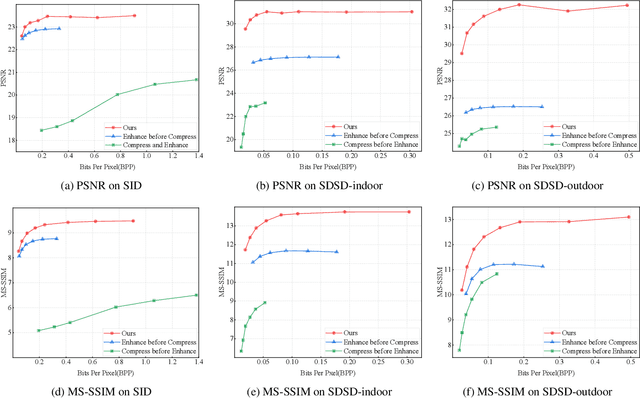
Learning-based image compression methods have made great progress. Most of them are designed for generic natural images. In fact, low-light images frequently occur due to unavoidable environmental influences or technical limitations, such as insufficient lighting or limited exposure time. %When general-purpose image compression algorithms compress low-light images, useful detail information is lost, resulting in a dramatic decrease in image enhancement. Once low-light images are compressed by existing general image compression approaches, useful information(e.g., texture details) would be lost resulting in a dramatic performance decrease in low-light image enhancement. To simultaneously achieve a higher compression rate and better enhancement performance for low-light images, we propose a novel image compression framework with joint optimization of low-light image enhancement. We design an end-to-end trainable two-branch architecture with lower computational cost, which includes the main enhancement branch and the signal-to-noise ratio~(SNR) aware branch. Experimental results show that our proposed joint optimization framework achieves a significant improvement over existing ``Compress before Enhance" or ``Enhance before Compress" sequential solutions for low-light images. Source codes are included in the supplementary material.
Anchor Prediction: Automatic Refinement of Internet Links
May 24, 2023
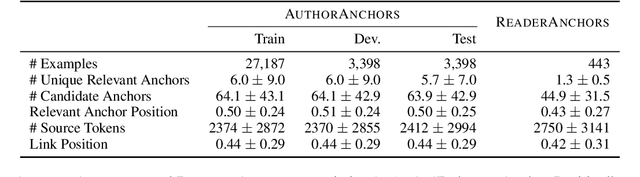

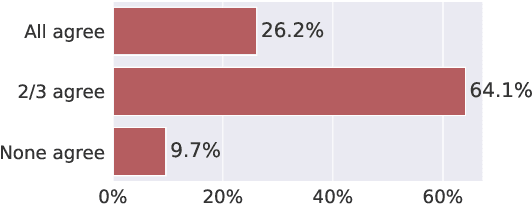
Internet links enable users to deepen their understanding of a topic by providing convenient access to related information. However, the majority of links are unanchored -- they link to a target webpage as a whole, and readers may expend considerable effort localizing the specific parts of the target webpage that enrich their understanding of the link's source context. To help readers effectively find information in linked webpages, we introduce the task of anchor prediction, where the goal is to identify the specific part of the linked target webpage that is most related to the source linking context. We release the AuthorAnchors dataset, a collection of 34K naturally-occurring anchored links, which reflect relevance judgments by the authors of the source article. To model reader relevance judgments, we annotate and release ReaderAnchors, an evaluation set of anchors that readers find useful. Our analysis shows that effective anchor prediction often requires jointly reasoning over lengthy source and target webpages to determine their implicit relations and identify parts of the target webpage that are related but not redundant. We benchmark a performant T5-based ranking approach to establish baseline performance on the task, finding ample room for improvement.
Adaptive Chameleon or Stubborn Sloth: Unraveling the Behavior of Large Language Models in Knowledge Clashes
May 24, 2023
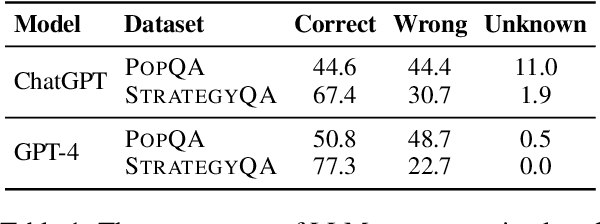
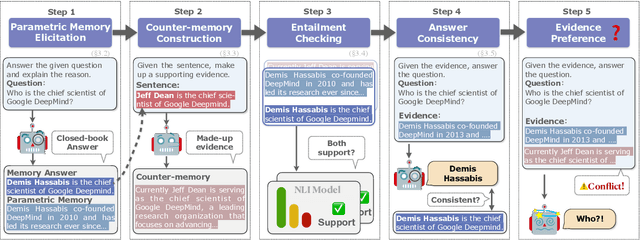
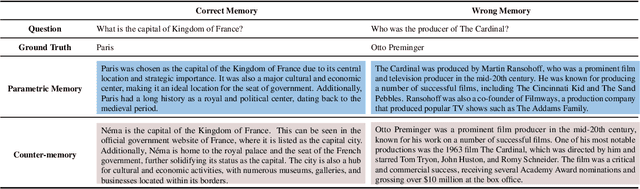
By providing external information to large language models (LLMs), tool augmentation (including retrieval augmentation) has emerged as a promising solution for addressing the limitations of LLMs' static parametric memory. However, how receptive are LLMs to such external evidence, especially when the evidence conflicts with their parametric memory? We present the first comprehensive and controlled investigation into the behavior of LLMs when encountering knowledge conflicts. We propose a systematic framework to elicit high-quality parametric memory from LLMs and construct the corresponding counter-memory, which enables us to conduct a series of controlled experiments. Our investigation reveals seemingly contradicting behaviors of LLMs. On the one hand, different from prior wisdom, we find that LLMs can be highly receptive to external evidence even when that conflicts with their parametric memory, given that the external evidence is coherent and convincing. On the other hand, LLMs also demonstrate a strong confirmation bias when the external evidence contains some information that is consistent with their parametric memory, despite being presented with conflicting evidence at the same time. These results pose important implications that are worth careful consideration for the further development and deployment of tool- and retrieval-augmented LLMs.
Differentially-Private Decision Trees with Probabilistic Robustness to Data Poisoning
May 24, 2023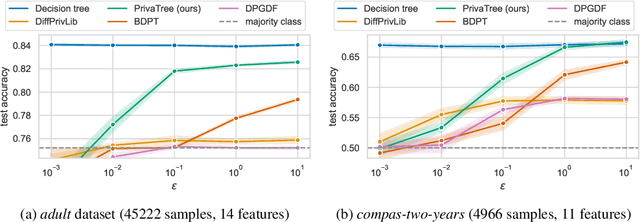
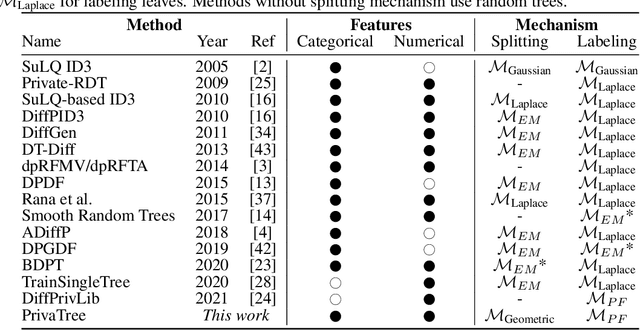
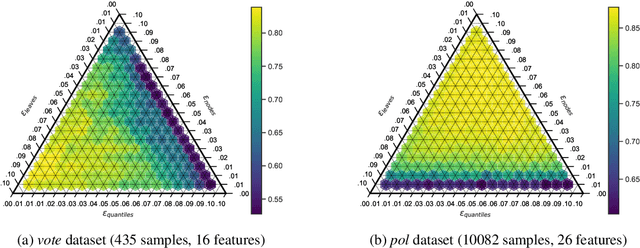
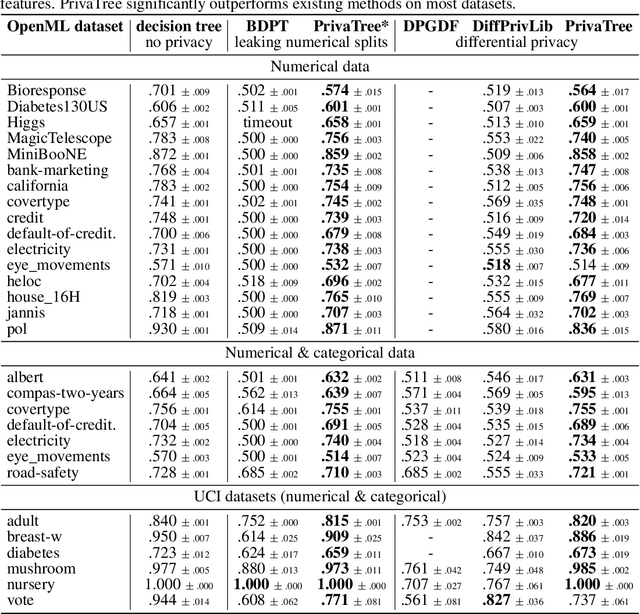
Decision trees are interpretable models that are well-suited to non-linear learning problems. Much work has been done on extending decision tree learning algorithms with differential privacy, a system that guarantees the privacy of samples within the training data. However, current state-of-the-art algorithms for this purpose sacrifice much utility for a small privacy benefit. These solutions create random decision nodes that reduce decision tree accuracy or spend an excessive share of the privacy budget on labeling leaves. Moreover, many works do not support or leak information about feature values when data is continuous. We propose a new method called PrivaTree based on private histograms that chooses good splits while consuming a small privacy budget. The resulting trees provide a significantly better privacy-utility trade-off and accept mixed numerical and categorical data without leaking additional information. Finally, while it is notoriously hard to give robustness guarantees against data poisoning attacks, we prove bounds for the expected success rates of backdoor attacks against differentially-private learners. Our experimental results show that PrivaTree consistently outperforms previous works on predictive accuracy and significantly improves robustness against backdoor attacks compared to regular decision trees.