 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStronger Baselines for Retrieval-Augmented Generation with Long-Context Language Models
Jun 04, 2025With the rise of long-context language models (LMs) capable of processing tens of thousands of tokens in a single pass, do multi-stage retrieval-augmented generation (RAG) pipelines still offer measurable benefits over simpler, single-stage approaches? To assess this question, we conduct a controlled evaluation for QA tasks under systematically scaled token budgets, comparing two recent multi-stage pipelines, ReadAgent and RAPTOR, against three baselines, including DOS RAG (Document's Original Structure RAG), a simple retrieve-then-read method that preserves original passage order. Despite its straightforward design, DOS RAG consistently matches or outperforms more intricate methods on multiple long-context QA benchmarks. We recommend establishing DOS RAG as a simple yet strong baseline for future RAG evaluations, pairing it with emerging embedding and language models to assess trade-offs between complexity and effectiveness as model capabilities evolve.
Inference and Verbalization Functions During In-Context Learning
Oct 12, 2024



Large language models (LMs) are capable of in-context learning from a few demonstrations (example-label pairs) to solve new tasks during inference. Despite the intuitive importance of high-quality demonstrations, previous work has observed that, in some settings, ICL performance is minimally affected by irrelevant labels (Min et al., 2022). We hypothesize that LMs perform ICL with irrelevant labels via two sequential processes: an inference function that solves the task, followed by a verbalization function that maps the inferred answer to the label space. Importantly, we hypothesize that the inference function is invariant to remappings of the label space (e.g., "true"/"false" to "cat"/"dog"), enabling LMs to share the same inference function across settings with different label words. We empirically validate this hypothesis with controlled layer-wise interchange intervention experiments. Our findings confirm the hypotheses on multiple datasets and tasks (natural language inference, sentiment analysis, and topic classification) and further suggest that the two functions can be localized in specific layers across various open-sourced models, including GEMMA-7B, MISTRAL-7B-V0.3, GEMMA-2-27B, and LLAMA-3.1-70B.
Instruction Following without Instruction Tuning
Sep 21, 2024



Instruction tuning commonly means finetuning a language model on instruction-response pairs. We discover two forms of adaptation (tuning) that are deficient compared to instruction tuning, yet still yield instruction following; we call this implicit instruction tuning. We first find that instruction-response pairs are not necessary: training solely on responses, without any corresponding instructions, yields instruction following. This suggests pretrained models have an instruction-response mapping which is revealed by teaching the model the desired distribution of responses. However, we then find it's not necessary to teach the desired distribution of responses: instruction-response training on narrow-domain data like poetry still leads to broad instruction-following behavior like recipe generation. In particular, when instructions are very different from those in the narrow finetuning domain, models' responses do not adhere to the style of the finetuning domain. To begin to explain implicit instruction tuning, we hypothesize that very simple changes to a language model's distribution yield instruction following. We support this by hand-writing a rule-based language model which yields instruction following in a product-of-experts with a pretrained model. The rules are to slowly increase the probability of ending the sequence, penalize repetition, and uniformly change 15 words' probabilities. In summary, adaptations made without being designed to yield instruction following can do so implicitly.
Lost in the Middle: How Language Models Use Long Contexts
Jul 31, 2023While recent language models have the ability to take long contexts as input, relatively little is known about how well they use longer context. We analyze language model performance on two tasks that require identifying relevant information within their input contexts: multi-document question answering and key-value retrieval. We find that performance is often highest when relevant information occurs at the beginning or end of the input context, and significantly degrades when models must access relevant information in the middle of long contexts. Furthermore, performance substantially decreases as the input context grows longer, even for explicitly long-context models. Our analysis provides a better understanding of how language models use their input context and provides new evaluation protocols for future long-context models.
Anchor Prediction: Automatic Refinement of Internet Links
May 24, 2023Internet links enable users to deepen their understanding of a topic by providing convenient access to related information. However, the majority of links are unanchored -- they link to a target webpage as a whole, and readers may expend considerable effort localizing the specific parts of the target webpage that enrich their understanding of the link's source context. To help readers effectively find information in linked webpages, we introduce the task of anchor prediction, where the goal is to identify the specific part of the linked target webpage that is most related to the source linking context. We release the AuthorAnchors dataset, a collection of 34K naturally-occurring anchored links, which reflect relevance judgments by the authors of the source article. To model reader relevance judgments, we annotate and release ReaderAnchors, an evaluation set of anchors that readers find useful. Our analysis shows that effective anchor prediction often requires jointly reasoning over lengthy source and target webpages to determine their implicit relations and identify parts of the target webpage that are related but not redundant. We benchmark a performant T5-based ranking approach to establish baseline performance on the task, finding ample room for improvement.
Evaluating Verifiability in Generative Search Engines
Apr 19, 2023Generative search engines directly generate responses to user queries, along with in-line citations. A prerequisite trait of a trustworthy generative search engine is verifiability, i.e., systems should cite comprehensively (high citation recall; all statements are fully supported by citations) and accurately (high citation precision; every cite supports its associated statement). We conduct human evaluation to audit four popular generative search engines -- Bing Chat, NeevaAI, perplexity.ai, and YouChat -- across a diverse set of queries from a variety of sources (e.g., historical Google user queries, dynamically-collected open-ended questions on Reddit, etc.). We find that responses from existing generative search engines are fluent and appear informative, but frequently contain unsupported statements and inaccurate citations: on average, a mere 51.5% of generated sentences are fully supported by citations and only 74.5% of citations support their associated sentence. We believe that these results are concerningly low for systems that may serve as a primary tool for information-seeking users, especially given their facade of trustworthiness. We hope that our results further motivate the development of trustworthy generative search engines and help researchers and users better understand the shortcomings of existing commercial systems.
Are Sample-Efficient NLP Models More Robust?
Oct 12, 2022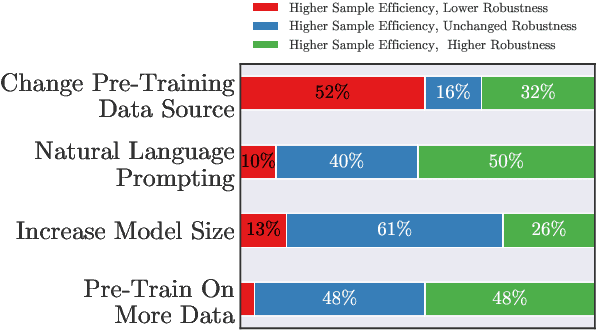
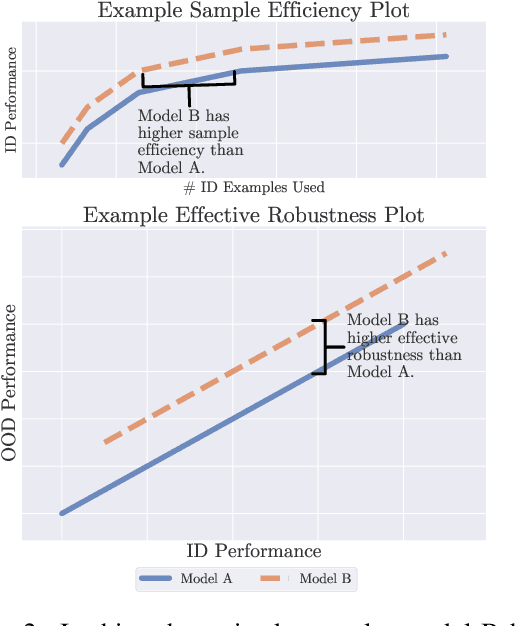
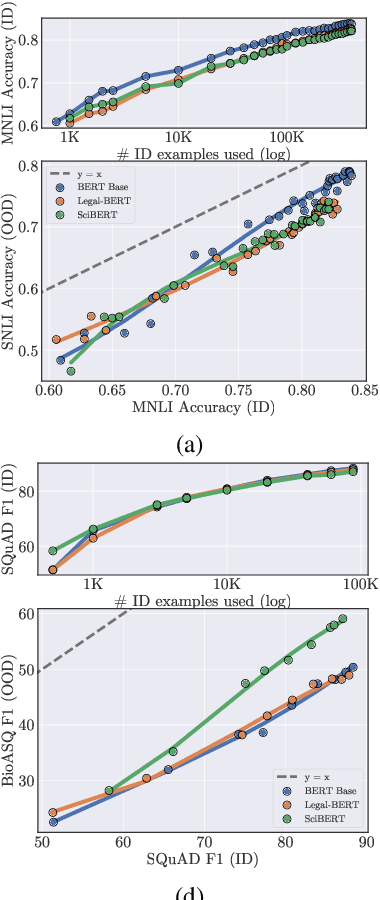
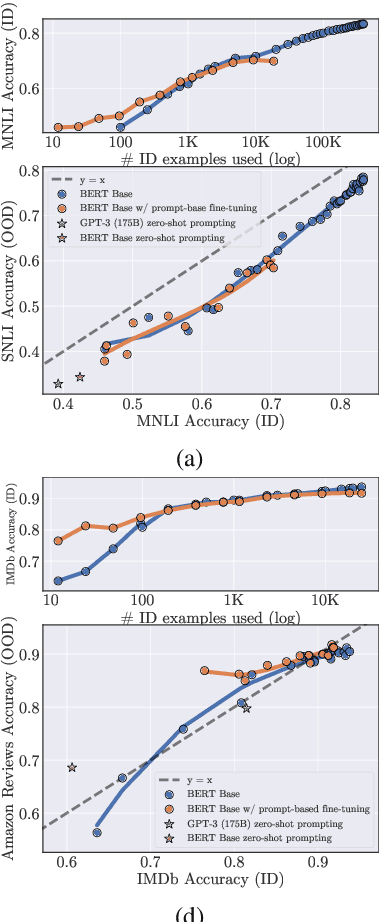
Recent work has observed that pre-trained models have higher out-of-distribution (OOD) robustness when they are exposed to less in-distribution (ID) training data (Radford et al., 2021). In particular, zero-shot models (e.g., GPT-3 and CLIP) have higher robustness than conventionally fine-tuned models, but these robustness gains fade as zero-shot models are fine-tuned on more ID data. We study this relationship between sample efficiency and robustness -- if two models have the same ID performance, does the model trained on fewer examples (higher sample efficiency) perform better OOD (higher robustness)? Surprisingly, experiments across three tasks, 23 total ID-OOD settings, and 14 models do not reveal a consistent relationship between sample efficiency and robustness -- while models with higher sample efficiency are sometimes more robust, most often there is no change in robustness, with some cases even showing decreased robustness. Since results vary on a case-by-case basis, we conduct detailed case studies of two particular ID-OOD pairs (SST-2 -> IMDb sentiment and SNLI -> HANS) to better understand why better sample efficiency may or may not yield higher robustness; attaining such an understanding requires case-by-case analysis of why models are not robust on a particular ID-OOD setting and how modeling techniques affect model capabilities.
Making Heads and Tails of Models with Marginal Calibration for Sparse Tagsets
Sep 15, 2021
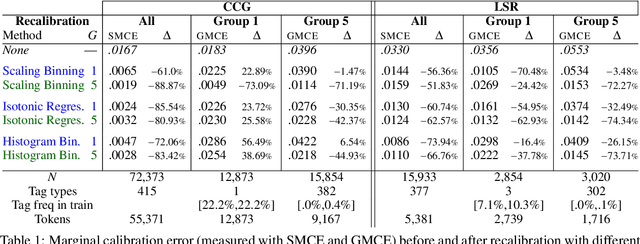
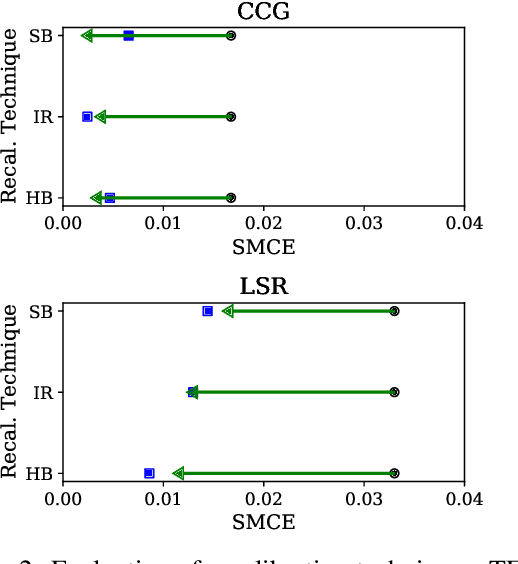
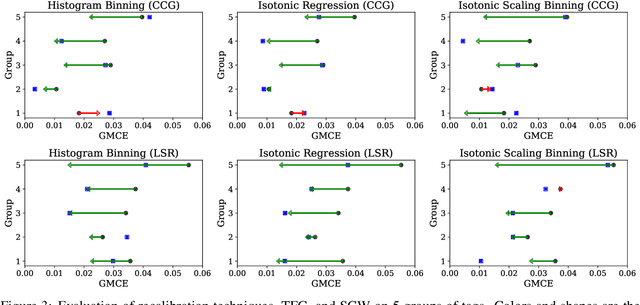
For interpreting the behavior of a probabilistic model, it is useful to measure a model's calibration--the extent to which it produces reliable confidence scores. We address the open problem of calibration for tagging models with sparse tagsets, and recommend strategies to measure and reduce calibration error (CE) in such models. We show that several post-hoc recalibration techniques all reduce calibration error across the marginal distribution for two existing sequence taggers. Moreover, we propose tag frequency grouping (TFG) as a way to measure calibration error in different frequency bands. Further, recalibrating each group separately promotes a more equitable reduction of calibration error across the tag frequency spectrum.
Identifying the Limits of Cross-Domain Knowledge Transfer for Pretrained Models
Apr 17, 2021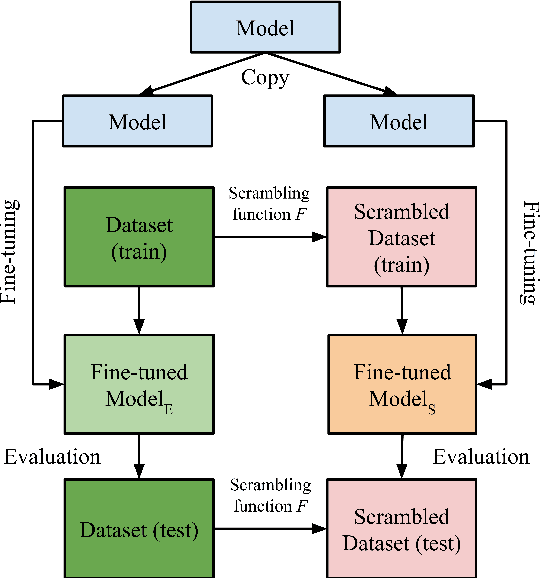

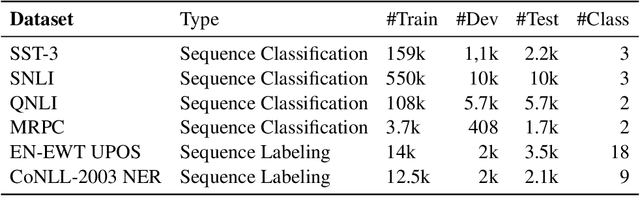
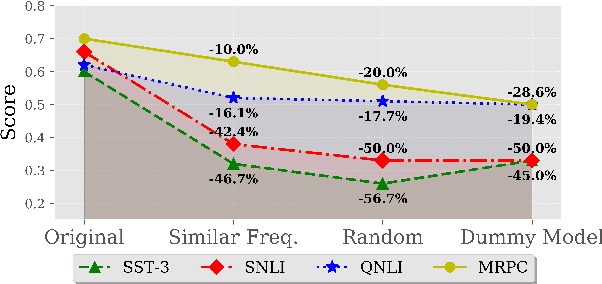
There is growing evidence that pretrained language models improve task-specific fine-tuning not just for the languages seen in pretraining, but also for new languages and even non-linguistic data. What is the nature of this surprising cross-domain transfer? We offer a partial answer via a systematic exploration of how much transfer occurs when models are denied any information about word identity via random scrambling. In four classification tasks and two sequence labeling tasks, we evaluate baseline models, LSTMs using GloVe embeddings, and BERT. We find that only BERT shows high rates of transfer into our scrambled domains, and for classification but not sequence labeling tasks. Our analyses seek to explain why transfer succeeds for some tasks but not others, to isolate the separate contributions of pretraining versus fine-tuning, and to quantify the role of word frequency. These findings help explain where and why cross-domain transfer occurs, which can guide future studies and practical fine-tuning efforts.
Can Small and Synthetic Benchmarks Drive Modeling Innovation? A Retrospective Study of Question Answering Modeling Approaches
Feb 01, 2021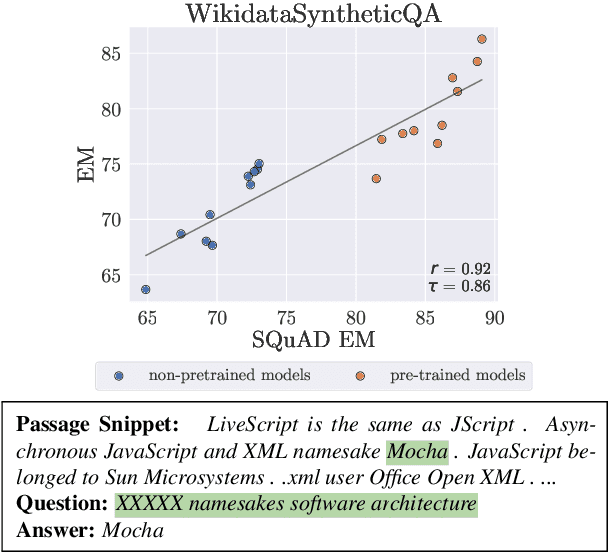
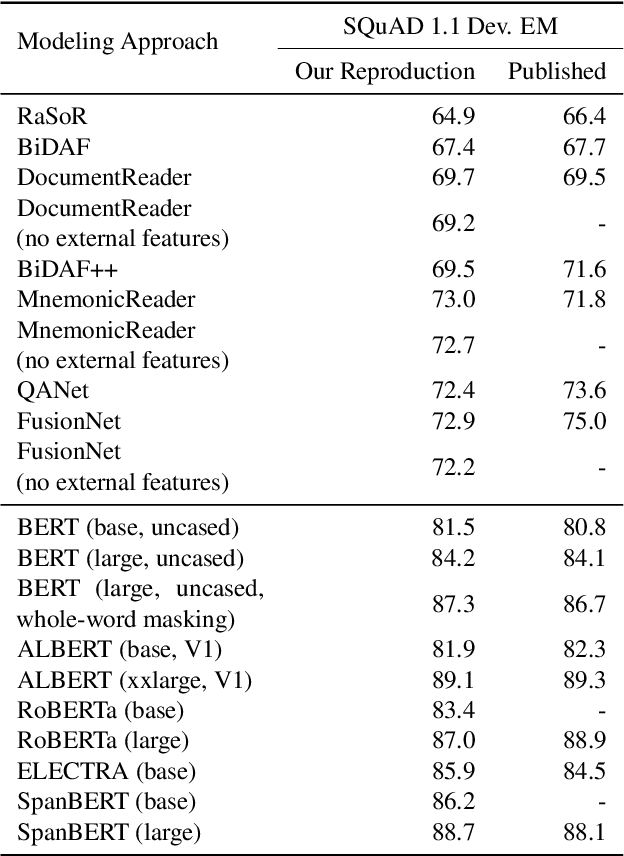
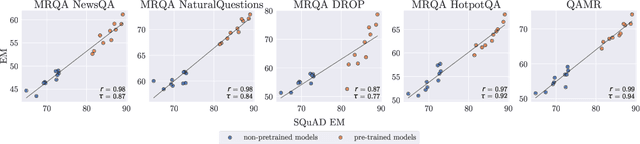
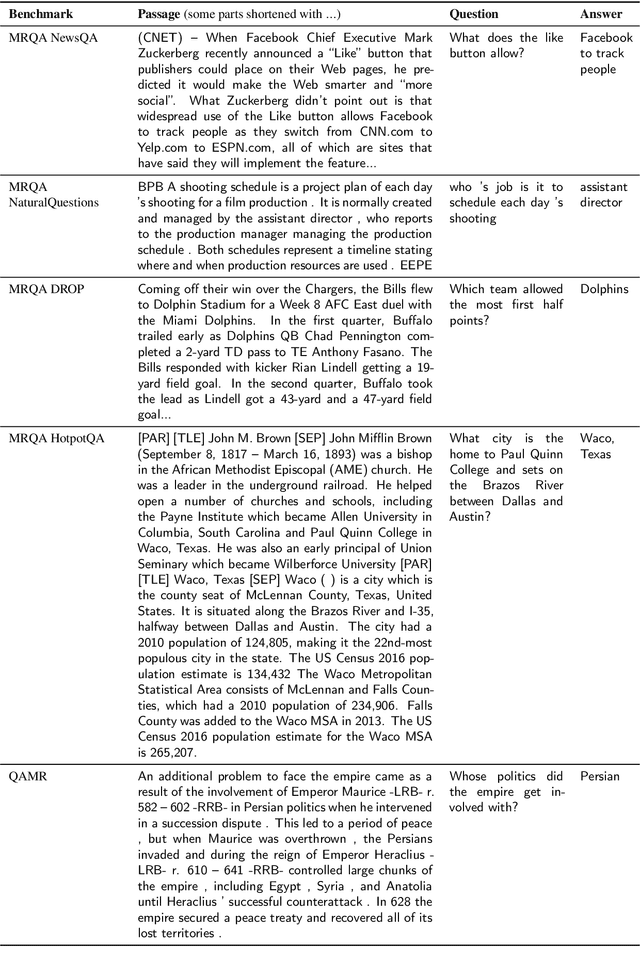
Datasets are not only resources for training accurate, deployable systems, but are also benchmarks for developing new modeling approaches. While large, natural datasets are necessary for training accurate systems, are they necessary for driving modeling innovation? For example, while the popular SQuAD question answering benchmark has driven the development of new modeling approaches, could synthetic or smaller benchmarks have led to similar innovations? This counterfactual question is impossible to answer, but we can study a necessary condition: the ability for a benchmark to recapitulate findings made on SQuAD. We conduct a retrospective study of 20 SQuAD modeling approaches, investigating how well 32 existing and synthesized benchmarks concur with SQuAD -- i.e., do they rank the approaches similarly? We carefully construct small, targeted synthetic benchmarks that do not resemble natural language, yet have high concurrence with SQuAD, demonstrating that naturalness and size are not necessary for reflecting historical modeling improvements on SQuAD. Our results raise the intriguing possibility that small and carefully designed synthetic benchmarks may be useful for driving the development of new modeling approaches.