 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
SpikeCodec: An End-to-end Learned Compression Framework for Spiking Camera
Jun 25, 2023


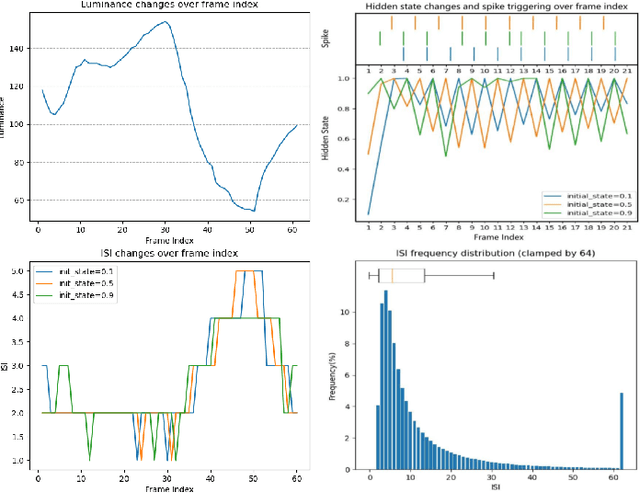

Recently, the bio-inspired spike camera with continuous motion recording capability has attracted tremendous attention due to its ultra high temporal resolution imaging characteristic. Such imaging feature results in huge data storage and transmission burden compared to that of traditional camera, raising severe challenge and imminent necessity in compression for spike camera captured content. Existing lossy data compression methods could not be applied for compressing spike streams efficiently due to integrate-and-fire characteristic and binarized data structure. Considering the imaging principle and information fidelity of spike cameras, we introduce an effective and robust representation of spike streams. Based on this representation, we propose a novel learned spike compression framework using scene recovery, variational auto-encoder plus spike simulator. To our knowledge, it is the first data-trained model for efficient and robust spike stream compression. Extensive experimental results show that our method outperforms the conventional and learning-based codecs, contributing a strong baseline for learned spike data compression.
RecBaselines2023: a new dataset for choosing baselines for recommender models
Jun 25, 2023
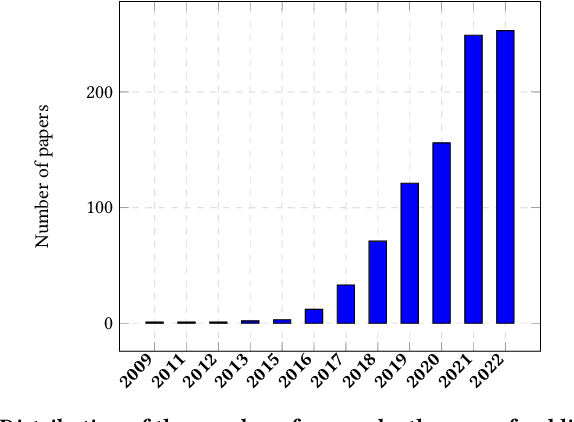
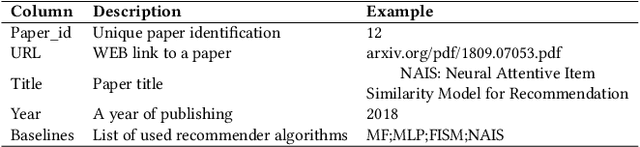
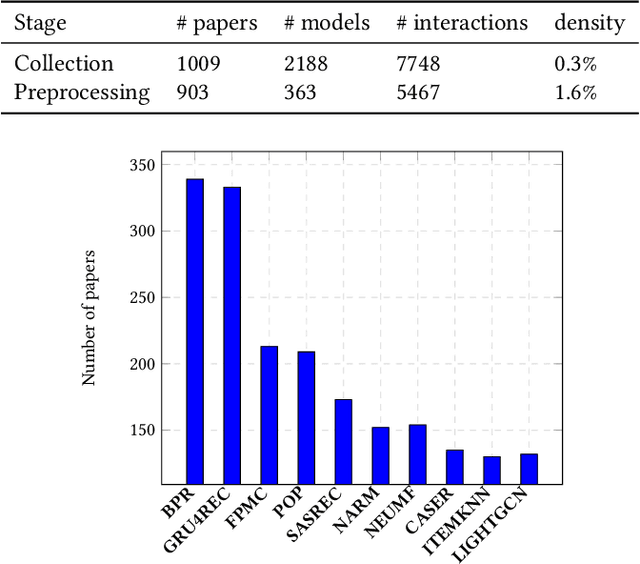
The number of proposed recommender algorithms continues to grow. The authors propose new approaches and compare them with existing models, called baselines. Due to the large number of recommender models, it is difficult to estimate which algorithms to choose in the article. To solve this problem, we have collected and published a dataset containing information about the recommender models used in 903 papers, both as baselines and as proposed approaches. This dataset can be seen as a typical dataset with interactions between papers and previously proposed models. In addition, we provide a descriptive analysis of the dataset and highlight possible challenges to be investigated with the data. Furthermore, we have conducted extensive experiments using a well-established methodology to build a good recommender algorithm under the dataset. Our experiments show that the selection of the best baselines for proposing new recommender approaches can be considered and successfully solved by existing state-of-the-art collaborative filtering models. Finally, we discuss limitations and future work.
Robust Statistical Comparison of Random Variables with Locally Varying Scale of Measurement
Jun 22, 2023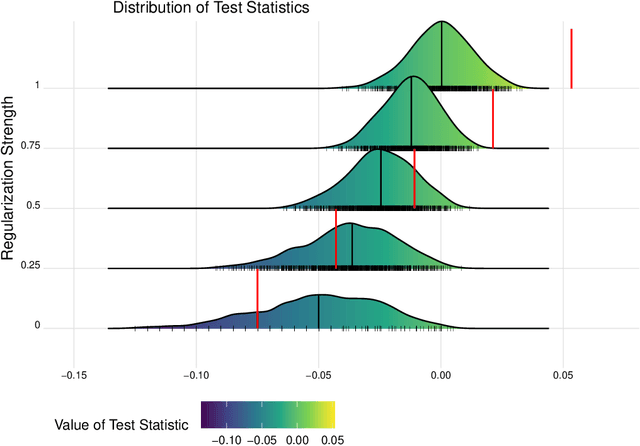
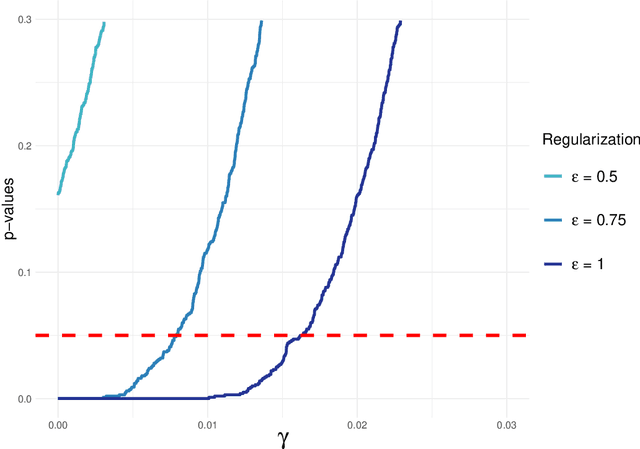
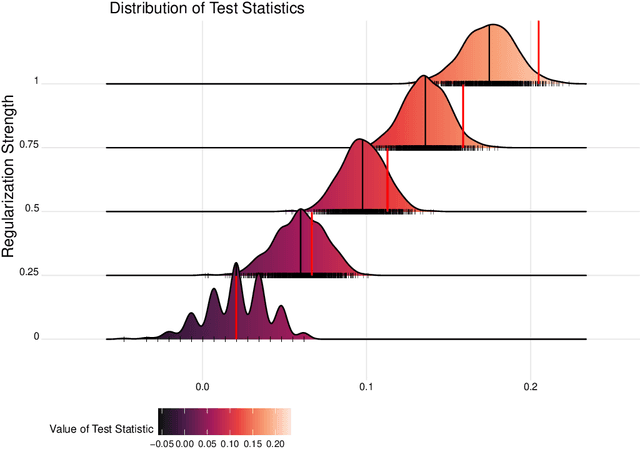
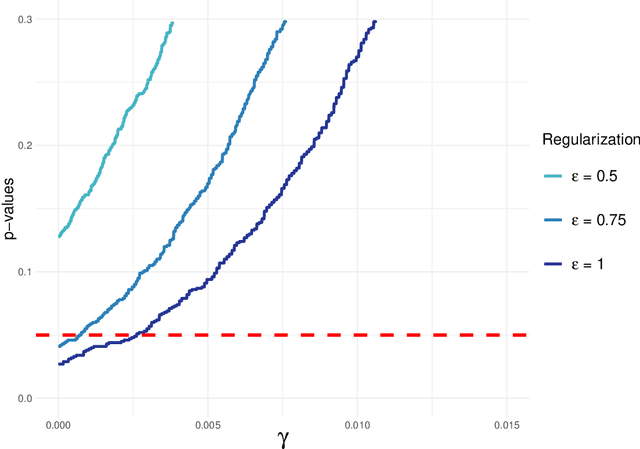
Spaces with locally varying scale of measurement, like multidimensional structures with differently scaled dimensions, are pretty common in statistics and machine learning. Nevertheless, it is still understood as an open question how to exploit the entire information encoded in them properly. We address this problem by considering an order based on (sets of) expectations of random variables mapping into such non-standard spaces. This order contains stochastic dominance and expectation order as extreme cases when no, or respectively perfect, cardinal structure is given. We derive a (regularized) statistical test for our proposed generalized stochastic dominance (GSD) order, operationalize it by linear optimization, and robustify it by imprecise probability models. Our findings are illustrated with data from multidimensional poverty measurement, finance, and medicine.
Identifying and Disentangling Spurious Features in Pretrained Image Representations
Jun 22, 2023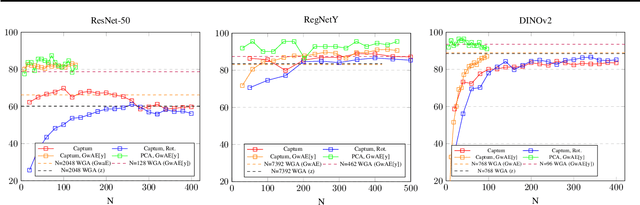
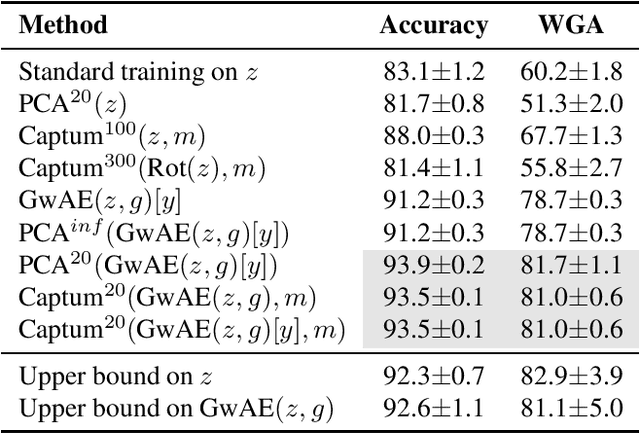
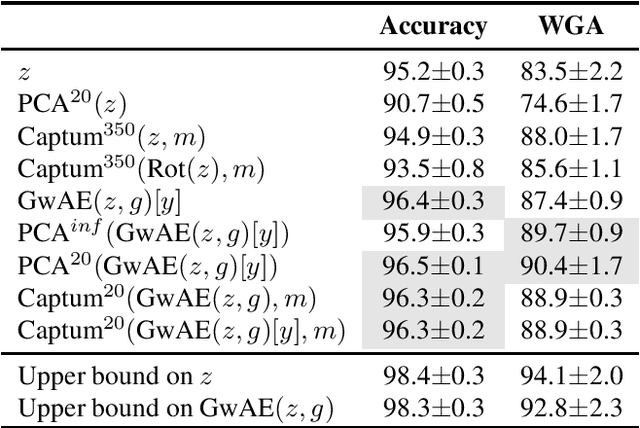
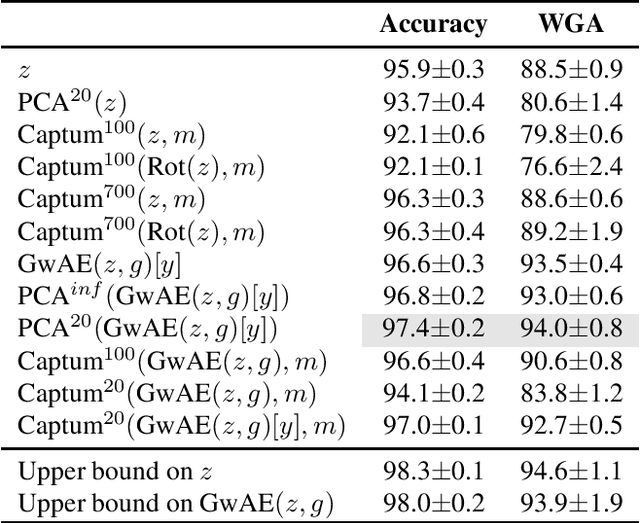
Neural networks employ spurious correlations in their predictions, resulting in decreased performance when these correlations do not hold. Recent works suggest fixing pretrained representations and training a classification head that does not use spurious features. We investigate how spurious features are represented in pretrained representations and explore strategies for removing information about spurious features. Considering the Waterbirds dataset and a few pretrained representations, we find that even with full knowledge of spurious features, their removal is not straightforward due to entangled representation. To address this, we propose a linear autoencoder training method to separate the representation into core, spurious, and other features. We propose two effective spurious feature removal approaches that are applied to the encoding and significantly improve classification performance measured by worst group accuracy.
Information-Theoretic Regret Bounds for Bandits with Fixed Expert Advice
Mar 15, 2023We investigate the problem of bandits with expert advice when the experts are fixed and known distributions over the actions. Improving on previous analyses, we show that the regret in this setting is controlled by information-theoretic quantities that measure the similarity between experts. In some natural special cases, this allows us to obtain the first regret bound for EXP4 that can get arbitrarily close to zero if the experts are similar enough. While for a different algorithm, we provide another bound that describes the similarity between the experts in terms of the KL-divergence, and we show that this bound can be smaller than the one of EXP4 in some cases. Additionally, we provide lower bounds for certain classes of experts showing that the algorithms we analyzed are nearly optimal in some cases.
Multi-modal Fake News Detection on Social Media via Multi-grained Information Fusion
Apr 03, 2023
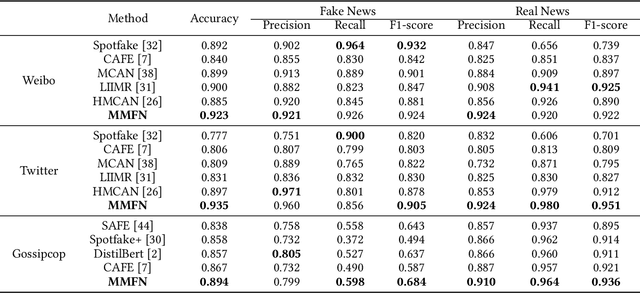
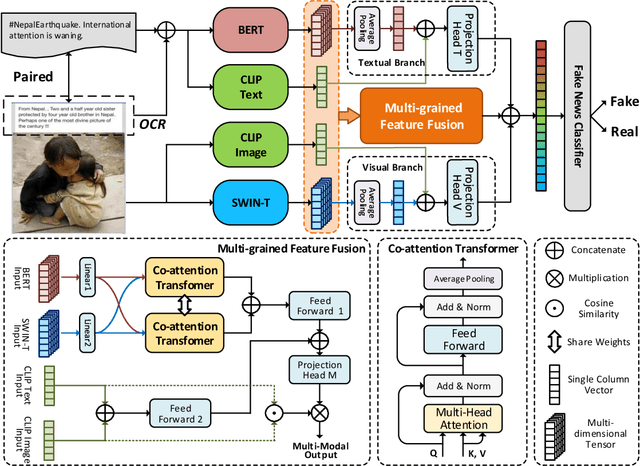
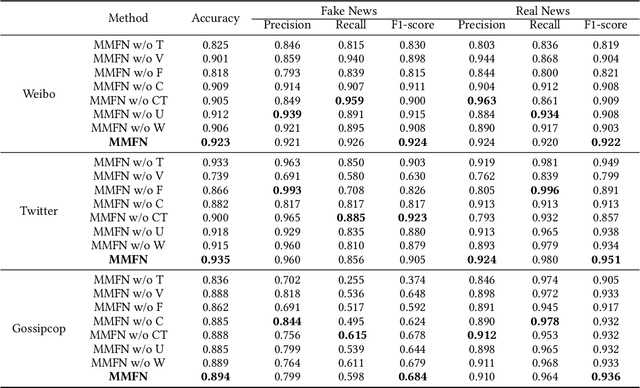
The easy sharing of multimedia content on social media has caused a rapid dissemination of fake news, which threatens society's stability and security. Therefore, fake news detection has garnered extensive research interest in the field of social forensics. Current methods primarily concentrate on the integration of textual and visual features but fail to effectively exploit multi-modal information at both fine-grained and coarse-grained levels. Furthermore, they suffer from an ambiguity problem due to a lack of correlation between modalities or a contradiction between the decisions made by each modality. To overcome these challenges, we present a Multi-grained Multi-modal Fusion Network (MMFN) for fake news detection. Inspired by the multi-grained process of human assessment of news authenticity, we respectively employ two Transformer-based pre-trained models to encode token-level features from text and images. The multi-modal module fuses fine-grained features, taking into account coarse-grained features encoded by the CLIP encoder. To address the ambiguity problem, we design uni-modal branches with similarity-based weighting to adaptively adjust the use of multi-modal features. Experimental results demonstrate that the proposed framework outperforms state-of-the-art methods on three prevalent datasets.
Detector Guidance for Multi-Object Text-to-Image Generation
Jun 04, 2023
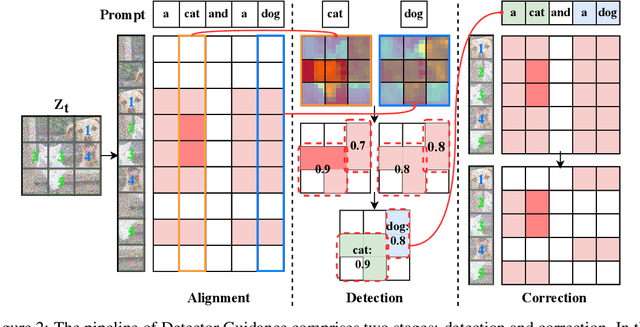

Diffusion models have demonstrated impressive performance in text-to-image generation. They utilize a text encoder and cross-attention blocks to infuse textual information into images at a pixel level. However, their capability to generate images with text containing multiple objects is still restricted. Previous works identify the problem of information mixing in the CLIP text encoder and introduce the T5 text encoder or incorporate strong prior knowledge to assist with the alignment. We find that mixing problems also occur on the image side and in the cross-attention blocks. The noisy images can cause different objects to appear similar, and the cross-attention blocks inject information at a pixel level, leading to leakage of global object understanding and resulting in object mixing. In this paper, we introduce Detector Guidance (DG), which integrates a latent object detection model to separate different objects during the generation process. DG first performs latent object detection on cross-attention maps (CAMs) to obtain object information. Based on this information, DG then masks conflicting prompts and enhances related prompts by manipulating the following CAMs. We evaluate the effectiveness of DG using Stable Diffusion on COCO, CC, and a novel multi-related object benchmark, MRO. Human evaluations demonstrate that DG provides an 8-22\% advantage in preventing the amalgamation of conflicting concepts and ensuring that each object possesses its unique region without any human involvement and additional iterations. Our implementation is available at \url{https://github.com/luping-liu/Detector-Guidance}.
Deep Predictive Learning : Motion Learning Concept inspired by Cognitive Robotics
Jun 26, 2023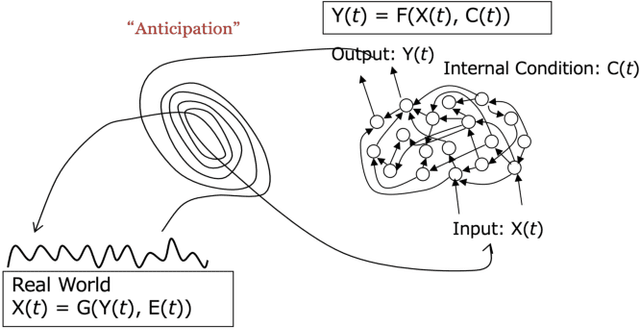
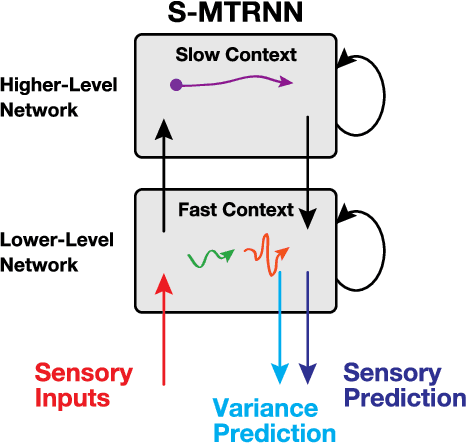

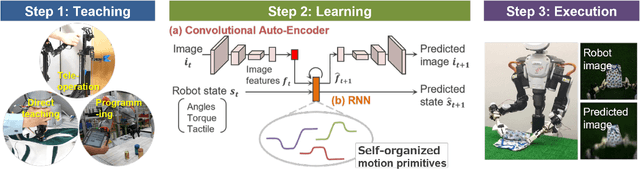
A deep learning-based approach can generalize model performance while reducing feature design costs by learning end-to-end environment recognition and motion generation. However, the process incurs huge training data collection costs and time and human resources for trial-and-error when involving physical contact with robots. Therefore, we propose ``deep predictive learning,'' a motion learning concept that assumes imperfections in the predictive model and minimizes the prediction error with the real-world situation. Deep predictive learning is inspired by the ``free energy principle and predictive coding theory,'' which explains how living organisms behave to minimize the prediction error between the real world and the brain. Robots predict near-future situations based on sensorimotor information and generate motions that minimize the gap with reality. The robot can flexibly perform tasks in unlearned situations by adjusting its motion in real-time while considering the gap between learning and reality. This paper describes the concept of deep predictive learning, its implementation, and examples of its application to real robots. The code and document are available at https: //ogata-lab.github.io/eipl-docs
RVT: Robotic View Transformer for 3D Object Manipulation
Jun 26, 2023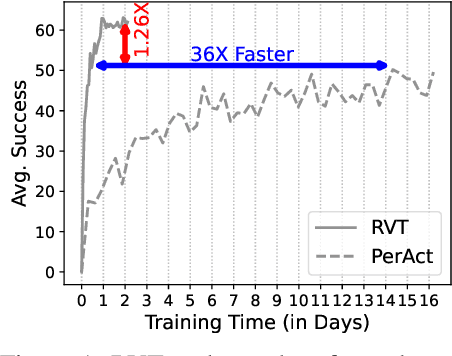
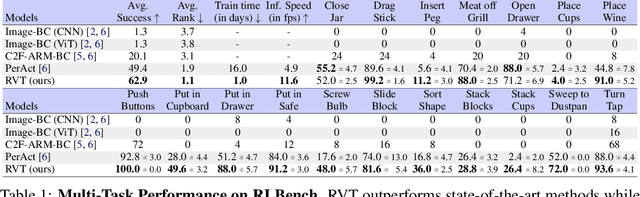
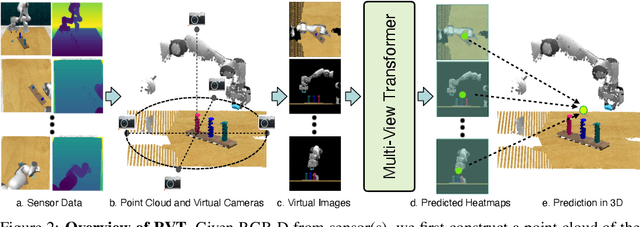
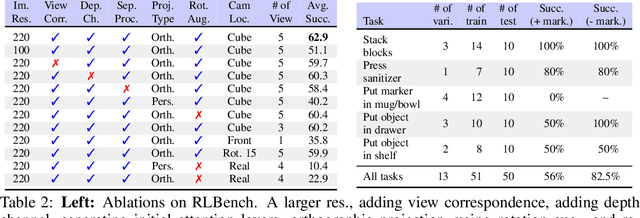
For 3D object manipulation, methods that build an explicit 3D representation perform better than those relying only on camera images. But using explicit 3D representations like voxels comes at large computing cost, adversely affecting scalability. In this work, we propose RVT, a multi-view transformer for 3D manipulation that is both scalable and accurate. Some key features of RVT are an attention mechanism to aggregate information across views and re-rendering of the camera input from virtual views around the robot workspace. In simulations, we find that a single RVT model works well across 18 RLBench tasks with 249 task variations, achieving 26% higher relative success than the existing state-of-the-art method (PerAct). It also trains 36X faster than PerAct for achieving the same performance and achieves 2.3X the inference speed of PerAct. Further, RVT can perform a variety of manipulation tasks in the real world with just a few ($\sim$10) demonstrations per task. Visual results, code, and trained model are provided at https://robotic-view-transformer.github.io/.
Multi-View Attention Learning for Residual Disease Prediction of Ovarian Cancer
Jun 26, 2023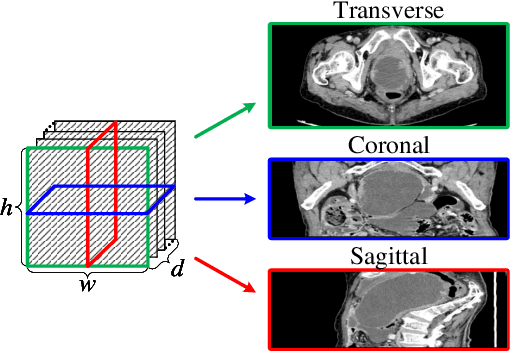
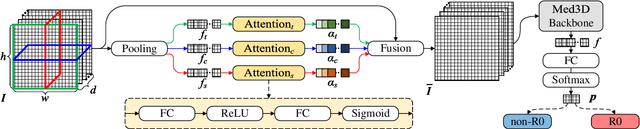
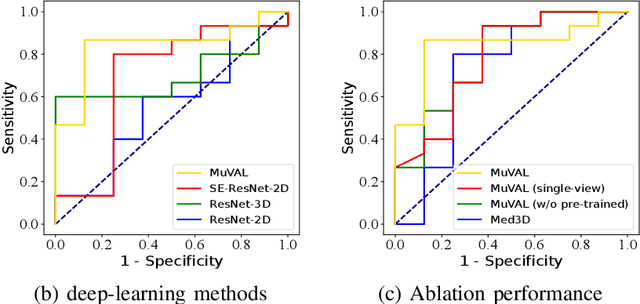

In the treatment of ovarian cancer, precise residual disease prediction is significant for clinical and surgical decision-making. However, traditional methods are either invasive (e.g., laparoscopy) or time-consuming (e.g., manual analysis). Recently, deep learning methods make many efforts in automatic analysis of medical images. Despite the remarkable progress, most of them underestimated the importance of 3D image information of disease, which might brings a limited performance for residual disease prediction, especially in small-scale datasets. To this end, in this paper, we propose a novel Multi-View Attention Learning (MuVAL) method for residual disease prediction, which focuses on the comprehensive learning of 3D Computed Tomography (CT) images in a multi-view manner. Specifically, we first obtain multi-view of 3D CT images from transverse, coronal and sagittal views. To better represent the image features in a multi-view manner, we further leverage attention mechanism to help find the more relevant slices in each view. Extensive experiments on a dataset of 111 patients show that our method outperforms existing deep-learning methods.