 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGradient-Variation Regret Bounds for Unconstrained Online Learning
Apr 13, 2026We develop parameter-free algorithms for unconstrained online learning with regret guarantees that scale with the gradient variation $V_T(u) = \sum_{t=2}^T \|\nabla f_t(u)-\nabla f_{t-1}(u)\|^2$. For $L$-smooth convex loss, we provide fully-adaptive algorithms achieving regret of order $\widetilde{O}(\|u\|\sqrt{V_T(u)} + L\|u\|^2+G^4)$ without requiring prior knowledge of comparator norm $\|u\|$, Lipschitz constant $G$, or smoothness $L$. The update in each round can be computed efficiently via a closed-form expression. Our results extend to dynamic regret and find immediate implications to the stochastically-extended adversarial (SEA) model, which significantly improves upon the previous best-known result [Wang et al., 2025].
A Perturbation Approach to Unconstrained Linear Bandits
Mar 30, 2026We revisit the standard perturbation-based approach of Abernethy et al. (2008) in the context of unconstrained Bandit Linear Optimization (uBLO). We show the surprising result that in the unconstrained setting, this approach effectively reduces Bandit Linear Optimization (BLO) to a standard Online Linear Optimization (OLO) problem. Our framework improves on prior work in several ways. First, we derive expected-regret guarantees when our perturbation scheme is combined with comparator-adaptive OLO algorithms, leading to new insights about the impact of different adversarial models on the resulting comparator-adaptive rates. We also extend our analysis to dynamic regret, obtaining the optimal $\sqrt{P_T}$ path-length dependencies without prior knowledge of $P_T$. We then develop the first high-probability guarantees for both static and dynamic regret in uBLO. Finally, we discuss lower bounds on the static regret, and prove the folklore $Ω(\sqrt{dT})$ rate for adversarial linear bandits on the unit Euclidean ball, which is of independent interest.
Parameter-Free Dynamic Regret for Unconstrained Linear Bandits
Mar 26, 2026We study dynamic regret minimization in unconstrained adversarial linear bandit problems. In this setting, a learner must minimize the cumulative loss relative to an arbitrary sequence of comparators $\boldsymbol{u}_1,\ldots,\boldsymbol{u}_T$ in $\mathbb{R}^d$, but receives only point-evaluation feedback on each round. We provide a simple approach to combining the guarantees of several bandit algorithms, allowing us to optimally adapt to the number of switches $S_T = \sum_t\mathbb{I}\{\boldsymbol{u}_t \neq \boldsymbol{u}_{t-1}\}$ of an arbitrary comparator sequence. In particular, we provide the first algorithm for linear bandits achieving the optimal regret guarantee of order $\mathcal{O}\big(\sqrt{d(1+S_T) T}\big)$ up to poly-logarithmic terms without prior knowledge of $S_T$, thus resolving a long-standing open problem.
Lookahead identification in adversarial bandits: accuracy and memory bounds
Feb 28, 2026We study an identification problem in multi-armed bandits. In each round a learner selects one of $K$ arms and observes its reward, with the goal of eventually identifying an arm that will perform best at a {\it future} time. In adversarial environments, however, past performance may offer little information about the future, raising the question of whether meaningful identification is possible at all. In this work, we introduce \emph{lookahead identification}, a task in which the goal of the learner is to select a future prediction window and commit in advance to an arm whose average reward over that window is within $\varepsilon$ of optimal. Our analysis characterizes both the achievable accuracy of lookahead identification and the memory resources required to obtain it. From an accuracy standpoint, for any horizon $T$ we give an algorithm achieving $\varepsilon = O\bigl(1/\sqrt{\log T}\bigr)$ over $Ω(\sqrt{T})$ prediction windows. This demonstrates that, perhaps surprisingly, identification is possible in adversarial settings, despite significant lack of information. We also prove a near-matching lower bound showing that $\varepsilon = Ω\bigl(1/\log T\bigr)$ is unavoidable. We then turn to investigate the role of memory in our problem, first proving that any algorithm achieving nontrivial accuracy requires $Ω(K)$ bits of memory. Under a natural \emph{local sparsity} condition, we show that the same accuracy guarantees can be achieved using only poly-logarithmic memory.
Near-Optimal Regret for Distributed Adversarial Bandits: A Black-Box Approach
Feb 06, 2026We study distributed adversarial bandits, where $N$ agents cooperate to minimize the global average loss while observing only their own local losses. We show that the minimax regret for this problem is $\tildeΘ(\sqrt{(ρ^{-1/2}+K/N)T})$, where $T$ is the horizon, $K$ is the number of actions, and $ρ$ is the spectral gap of the communication matrix. Our algorithm, based on a novel black-box reduction to bandits with delayed feedback, requires agents to communicate only through gossip. It achieves an upper bound that significantly improves over the previous best bound $\tilde{O}(ρ^{-1/3}(KT)^{2/3})$ of Yi and Vojnovic (2023). We complement this result with a matching lower bound, showing that the problem's difficulty decomposes into a communication cost $ρ^{-1/4}\sqrt{T}$ and a bandit cost $\sqrt{KT/N}$. We further demonstrate the versatility of our approach by deriving first-order and best-of-both-worlds bounds in the distributed adversarial setting. Finally, we extend our framework to distributed linear bandits in $R^d$, obtaining a regret bound of $\tilde{O}(\sqrt{(ρ^{-1/2}+1/N)dT})$, achieved with only $O(d)$ communication cost per agent and per round via a volumetric spanner.
Online Linear Regression with Paid Stochastic Features
Nov 11, 2025We study an online linear regression setting in which the observed feature vectors are corrupted by noise and the learner can pay to reduce the noise level. In practice, this may happen for several reasons: for example, because features can be measured more accurately using more expensive equipment, or because data providers can be incentivized to release less private features. Assuming feature vectors are drawn i.i.d. from a fixed but unknown distribution, we measure the learner's regret against the linear predictor minimizing a notion of loss that combines the prediction error and payment. When the mapping between payments and noise covariance is known, we prove that the rate $\sqrt{T}$ is optimal for regret if logarithmic factors are ignored. When the noise covariance is unknown, we show that the optimal regret rate becomes of order $T^{2/3}$ (ignoring log factors). Our analysis leverages matrix martingale concentration, showing that the empirical loss uniformly converges to the expected one for all payments and linear predictors.
Instance-Dependent Regret Bounds for Nonstochastic Linear Partial Monitoring
Oct 22, 2025In contrast to the classic formulation of partial monitoring, linear partial monitoring can model infinite outcome spaces, while imposing a linear structure on both the losses and the observations. This setting can be viewed as a generalization of linear bandits where loss and feedback are decoupled in a flexible manner. In this work, we address a nonstochastic (adversarial), finite-actions version of the problem through a simple instance of the exploration-by-optimization method that is amenable to efficient implementation. We derive regret bounds that depend on the game structure in a more transparent manner than previous theoretical guarantees for this paradigm. Our bounds feature instance-specific quantities that reflect the degree of alignment between observations and losses, and resemble known guarantees in the stochastic setting. Notably, they achieve the standard $\sqrt{T}$ rate in easy (locally observable) games and $T^{2/3}$ in hard (globally observable) games, where $T$ is the time horizon. We instantiate these bounds in a selection of old and new partial information settings subsumed by this model, and illustrate that the achieved dependence on the game structure can be tight in interesting cases.
Of Dice and Games: A Theory of Generalized Boosting
Dec 11, 2024Cost-sensitive loss functions are crucial in many real-world prediction problems, where different types of errors are penalized differently; for example, in medical diagnosis, a false negative prediction can lead to worse consequences than a false positive prediction. However, traditional PAC learning theory has mostly focused on the symmetric 0-1 loss, leaving cost-sensitive losses largely unaddressed. In this work, we extend the celebrated theory of boosting to incorporate both cost-sensitive and multi-objective losses. Cost-sensitive losses assign costs to the entries of a confusion matrix, and are used to control the sum of prediction errors accounting for the cost of each error type. Multi-objective losses, on the other hand, simultaneously track multiple cost-sensitive losses, and are useful when the goal is to satisfy several criteria at once (e.g., minimizing false positives while keeping false negatives below a critical threshold). We develop a comprehensive theory of cost-sensitive and multi-objective boosting, providing a taxonomy of weak learning guarantees that distinguishes which guarantees are trivial (i.e., can always be achieved), which ones are boostable (i.e., imply strong learning), and which ones are intermediate, implying non-trivial yet not arbitrarily accurate learning. For binary classification, we establish a dichotomy: a weak learning guarantee is either trivial or boostable. In the multiclass setting, we describe a more intricate landscape of intermediate weak learning guarantees. Our characterization relies on a geometric interpretation of boosting, revealing a surprising equivalence between cost-sensitive and multi-objective losses.
Market Making without Regret
Nov 21, 2024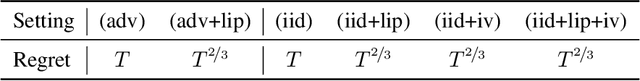
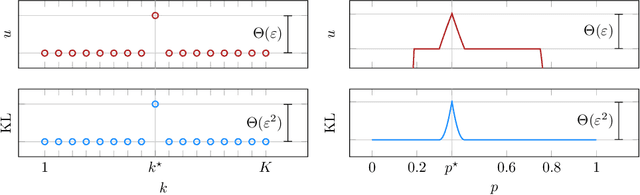
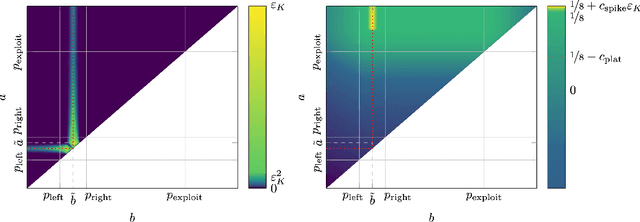
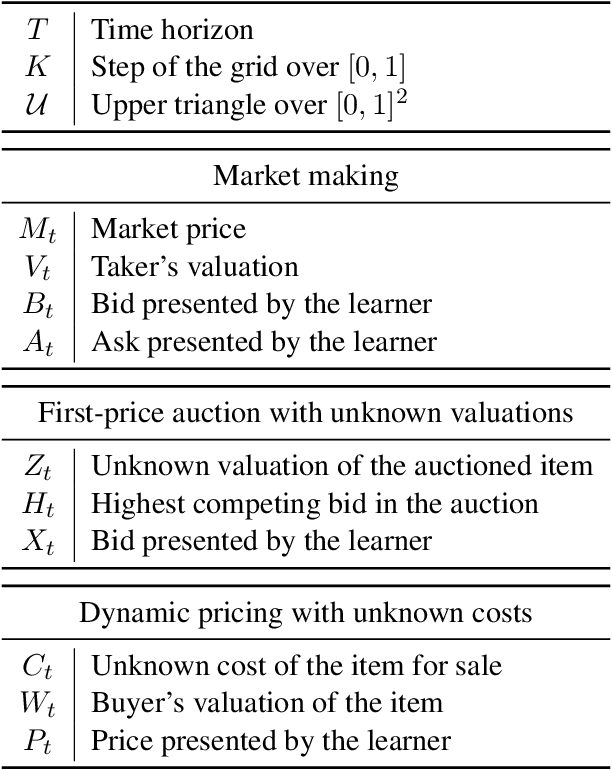
We consider a sequential decision-making setting where, at every round $t$, a market maker posts a bid price $B_t$ and an ask price $A_t$ to an incoming trader (the taker) with a private valuation for one unit of some asset. If the trader's valuation is lower than the bid price, or higher than the ask price, then a trade (sell or buy) occurs. If a trade happens at round $t$, then letting $M_t$ be the market price (observed only at the end of round $t$), the maker's utility is $M_t - B_t$ if the maker bought the asset, and $A_t - M_t$ if they sold it. We characterize the maker's regret with respect to the best fixed choice of bid and ask pairs under a variety of assumptions (adversarial, i.i.d., and their variants) on the sequence of market prices and valuations. Our upper bound analysis unveils an intriguing connection relating market making to first-price auctions and dynamic pricing. Our main technical contribution is a lower bound for the i.i.d. case with Lipschitz distributions and independence between prices and valuations. The difficulty in the analysis stems from the unique structure of the reward and feedback functions, allowing an algorithm to acquire information by graduating the "cost of exploration" in an arbitrary way.
Improved Regret Bounds for Bandits with Expert Advice
Jun 24, 2024In this research note, we revisit the bandits with expert advice problem. Under a restricted feedback model, we prove a lower bound of order $\sqrt{K T \ln(N/K)}$ for the worst-case regret, where $K$ is the number of actions, $N>K$ the number of experts, and $T$ the time horizon. This matches a previously known upper bound of the same order and improves upon the best available lower bound of $\sqrt{K T (\ln N) / (\ln K)}$. For the standard feedback model, we prove a new instance-based upper bound that depends on the agreement between the experts and provides a logarithmic improvement compared to prior results.