 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompact Task-Aligned Imitation Learning for Laboratory Automation
Mar 01, 2026Robotic laboratory automation has traditionally relied on carefully engineered motion pipelines and task-specific hardware interfaces, resulting in high design cost and limited flexibility. While recent imitation learning techniques can generate general robot behaviors, their large model sizes often require high-performance computational resources, limiting applicability in practical laboratory environments. In this study, we propose a compact imitation learning framework for laboratory automation using small foundation models. The proposed method, TVF-DiT, aligns a self-supervised vision foundation model with a vision-language model through a compact adapter, and integrates them with a Diffusion Transformer-based action expert. The entire model consists of fewer than 500M parameters, enabling inference on low-VRAM GPUs. Experiments on three real-world laboratory tasks - test tube cleaning, test tube arrangement, and powder transfer - demonstrate an average success rate of 86.6%, significantly outperforming alternative lightweight baselines. Furthermore, detailed task prompts improve vision-language alignment and task performance. These results indicate that small foundation models, when properly aligned and integrated with diffusion-based policy learning, can effectively support practical laboratory automation with limited computational resources.
From Dialogue to Execution: Mixture-of-Agents Assisted Interactive Planning for Behavior Tree-Based Long-Horizon Robot Execution
Mar 01, 2026Interactive task planning with large language models (LLMs) enables robots to generate high-level action plans from natural language instructions. However, in long-horizon tasks, such approaches often require many questions, increasing user burden. Moreover, flat plan representations become difficult to manage as task complexity grows. We propose a framework that integrates Mixture-of-Agents (MoA)-based proxy answering into interactive planning and generates Behavior Trees (BTs) for structured long-term execution. The MoA consists of multiple LLM-based expert agents that answer general or domain-specific questions when possible, reducing unnecessary human intervention. The resulting BT hierarchically represents task logic and enables retry mechanisms and dynamic switching among multiple robot policies. Experiments on cocktail-making tasks show that the proposed method reduces human response requirements by approximately 27% while maintaining structural and semantic similarity to fully human-answered BTs. Real-robot experiments on a smoothie-making task further demonstrate successful long-horizon execution with adaptive policy switching and recovery from action failures. These results indicate that MoA-assisted interactive planning improves dialogue efficiency while preserving execution quality in real-world robotic tasks.
Proprioception Enhances Vision Language Model in Generating Captions and Subtask Segmentations for Robot Task
Dec 24, 2025From the perspective of future developments in robotics, it is crucial to verify whether foundation models trained exclusively on offline data, such as images and language, can understand the robot motion. In particular, since Vision Language Models (VLMs) do not include low-level motion information from robots in their training datasets, video understanding including trajectory information remains a significant challenge. In this study, we assess two capabilities of VLMs through a video captioning task with low-level robot motion information: (1) automatic captioning of robot tasks and (2) segmentation of a series of tasks. Both capabilities are expected to enhance the efficiency of robot imitation learning by linking language and motion and serve as a measure of the foundation model's performance. The proposed method generates multiple "scene" captions using image captions and trajectory data from robot tasks. The full task caption is then generated by summarizing these individual captions. Additionally, the method performs subtask segmentation by comparing the similarity between text embeddings of image captions. In both captioning tasks, the proposed method aims to improve performance by providing the robot's motion data - joint and end-effector states - as input to the VLM. Simulator experiments were conducted to validate the effectiveness of the proposed method.
Sensorimotor Attention and Language-based Regressions in Shared Latent Variables for Integrating Robot Motion Learning and LLM
Jul 12, 2024



In recent years, studies have been actively conducted on combining large language models (LLM) and robotics; however, most have not considered end-to-end feedback in the robot-motion generation phase. The prediction of deep neural networks must contain errors, it is required to update the trained model to correspond to the real environment to generate robot motion adaptively. This study proposes an integration method that connects the robot-motion learning model and LLM using shared latent variables. When generating robot motion, the proposed method updates shared parameters based on prediction errors from both sensorimotor attention points and task language instructions given to the robot. This allows the model to search for latent parameters appropriate for the robot task efficiently. Through simulator experiments on multiple robot tasks, we demonstrated the effectiveness of our proposed method from two perspectives: position generalization and language instruction generalization abilities.
Realtime Motion Generation with Active Perception Using Attention Mechanism for Cooking Robot
Sep 26, 2023



To support humans in their daily lives, robots are required to autonomously learn, adapt to objects and environments, and perform the appropriate actions. We tackled on the task of cooking scrambled eggs using real ingredients, in which the robot needs to perceive the states of the egg and adjust stirring movement in real time, while the egg is heated and the state changes continuously. In previous works, handling changing objects was found to be challenging because sensory information includes dynamical, both important or noisy information, and the modality which should be focused on changes every time, making it difficult to realize both perception and motion generation in real time. We propose a predictive recurrent neural network with an attention mechanism that can weigh the sensor input, distinguishing how important and reliable each modality is, that realize quick and efficient perception and motion generation. The model is trained with learning from the demonstration, and allows the robot to acquire human-like skills. We validated the proposed technique using the robot, Dry-AIREC, and with our learning model, it could perform cooking eggs with unknown ingredients. The robot could change the method of stirring and direction depending on the status of the egg, as in the beginning it stirs in the whole pot, then subsequently, after the egg started being heated, it starts flipping and splitting motion targeting specific areas, although we did not explicitly indicate them.
Interactively Robot Action Planning with Uncertainty Analysis and Active Questioning by Large Language Model
Aug 30, 2023The application of the Large Language Model (LLM) to robot action planning has been actively studied. The instructions given to the LLM by natural language may include ambiguity and lack of information depending on the task context. It is possible to adjust the output of LLM by making the instruction input more detailed; however, the design cost is high. In this paper, we propose the interactive robot action planning method that allows the LLM to analyze and gather missing information by asking questions to humans. The method can minimize the design cost of generating precise robot instructions. We demonstrated the effectiveness of our method through concrete examples in cooking tasks. However, our experiments also revealed challenges in robot action planning with LLM, such as asking unimportant questions and assuming crucial information without asking. Shedding light on these issues provides valuable insights for future research on utilizing LLM for robotics.
Deep Predictive Learning : Motion Learning Concept inspired by Cognitive Robotics
Jun 26, 2023



A deep learning-based approach can generalize model performance while reducing feature design costs by learning end-to-end environment recognition and motion generation. However, the process incurs huge training data collection costs and time and human resources for trial-and-error when involving physical contact with robots. Therefore, we propose ``deep predictive learning,'' a motion learning concept that assumes imperfections in the predictive model and minimizes the prediction error with the real-world situation. Deep predictive learning is inspired by the ``free energy principle and predictive coding theory,'' which explains how living organisms behave to minimize the prediction error between the real world and the brain. Robots predict near-future situations based on sensorimotor information and generate motions that minimize the gap with reality. The robot can flexibly perform tasks in unlearned situations by adjusting its motion in real-time while considering the gap between learning and reality. This paper describes the concept of deep predictive learning, its implementation, and examples of its application to real robots. The code and document are available at https: //ogata-lab.github.io/eipl-docs
Learning Bidirectional Translation between Descriptions and Actions with Small Paired Data
Mar 08, 2022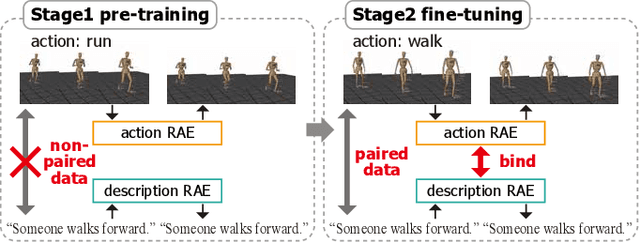
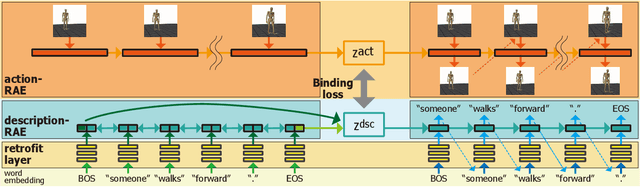

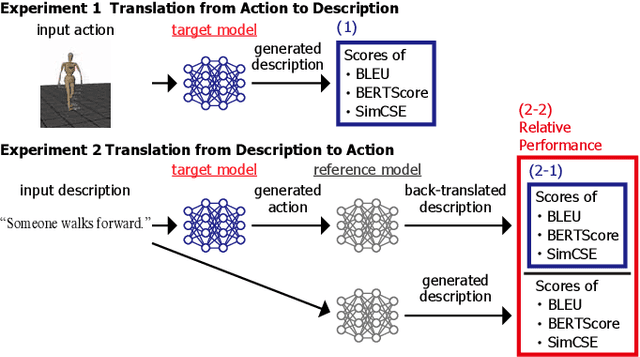
This study achieved bidirectional translation between descriptions and actions using small paired data. The ability to mutually generate descriptions and actions is essential for robots to collaborate with humans in their daily lives. The robot is required to associate real-world objects with linguistic expressions, and large-scale paired data are required for machine learning approaches. However, a paired dataset is expensive to construct and difficult to collect. This study proposes a two-stage training method for bidirectional translation. In the proposed method, we train recurrent autoencoders (RAEs) for descriptions and actions with a large amount of non-paired data. Then, we fine-tune the entire model to bind their intermediate representations using small paired data. Because the data used for pre-training do not require pairing, behavior-only data or a large language corpus can be used. We experimentally evaluated our method using a paired dataset consisting of motion-captured actions and descriptions. The results showed that our method performed well, even when the amount of paired data to train was small. The visualization of the intermediate representations of each RAE showed that similar actions were encoded in a clustered position and the corresponding feature vectors well aligned.
Three approaches to facilitate DNN generalization to objects in out-of-distribution orientations and illuminations: late-stopping, tuning batch normalization and invariance loss
Oct 30, 2021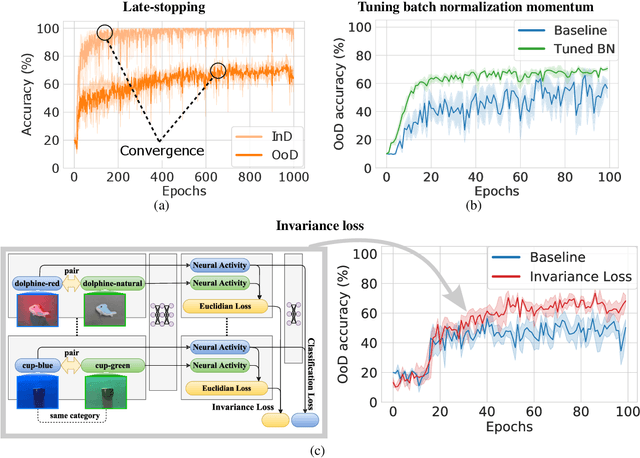



The training data distribution is often biased towards objects in certain orientations and illumination conditions. While humans have a remarkable capability of recognizing objects in out-of-distribution (OoD) orientations and illuminations, Deep Neural Networks (DNNs) severely suffer in this case, even when large amounts of training examples are available. In this paper, we investigate three different approaches to improve DNNs in recognizing objects in OoD orientations and illuminations. Namely, these are (i) training much longer after convergence of the in-distribution (InD) validation accuracy, i.e., late-stopping, (ii) tuning the momentum parameter of the batch normalization layers, and (iii) enforcing invariance of the neural activity in an intermediate layer to orientation and illumination conditions. Each of these approaches substantially improves the DNN's OoD accuracy (more than 20% in some cases). We report results in four datasets: two datasets are modified from the MNIST and iLab datasets, and the other two are novel (one of 3D rendered cars and another of objects taken from various controlled orientations and illumination conditions). These datasets allow to study the effects of different amounts of bias and are challenging as DNNs perform poorly in OoD conditions. Finally, we demonstrate that even though the three approaches focus on different aspects of DNNs, they all tend to lead to the same underlying neural mechanism to enable OoD accuracy gains -- individual neurons in the intermediate layers become more selective to a category and also invariant to OoD orientations and illuminations.
Annotation Cost Reduction of Stream-based Active Learning by Automated Weak Labeling using a Robot Arm
Oct 03, 2021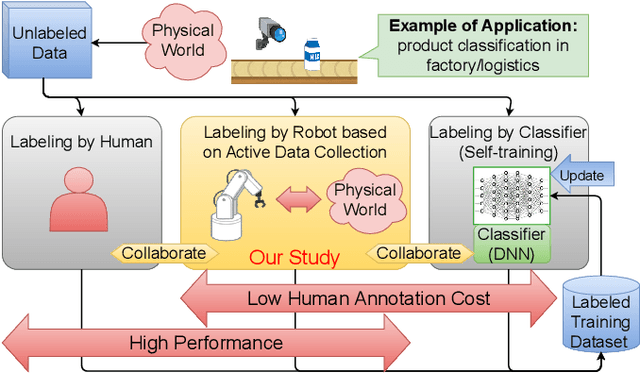
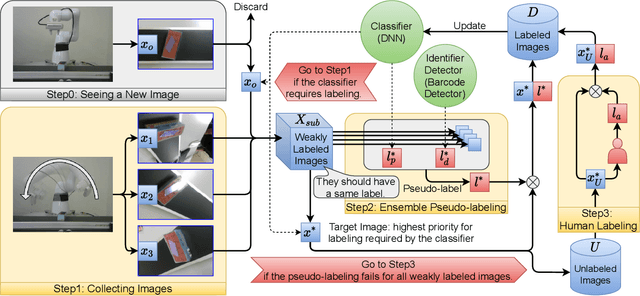


Stream-based active learning (AL) is an efficient training data collection method, and it is used to reduce human annotation cost required in machine learning. However, it is difficult to say that the human cost is low enough because most previous studies have assumed that an oracle is a human with domain knowledge. In this study, we propose a method to replace a part of the oracle's work in stream-based AL by self-training with weak labeling using a robot arm. A camera attached to a robot arm takes a series of image data related to a streamed object, which should have the same label. We use this information as a weak label to connect a pseudo-label (estimated class label) and a target instance. Our method selects two data from a series of image data; high confidence data for correcting pseudo-labels and low confidence data for improving the performance of the classifier. We paired a pseudo-label provided to high confidence data with a target instance (low confidence data). By using this technique, we mitigate the inefficiency in self-training, that is, difficulty in creating pseudo-labeled training data with a high impact on the target classifier. In the experiments, we employed the proposed method in the classification task of objects on a belt conveyor. We evaluated the performance against human cost on multiple scenarios considering the temporal variation of data. The proposed method achieves the same or better performance as the conventional methods while reducing human cost.