 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Removing confounding information from fetal ultrasound images
Mar 24, 2023
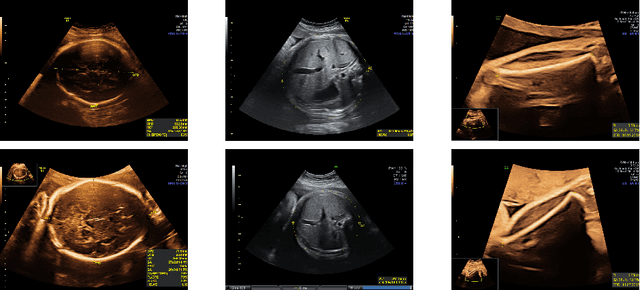
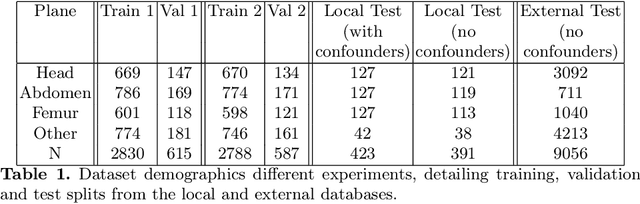

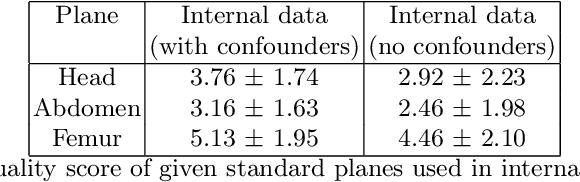
Confounding information in the form of text or markings embedded in medical images can severely affect the training of diagnostic deep learning algorithms. However, data collected for clinical purposes often have such markings embedded in them. In dermatology, known examples include drawings or rulers that are overrepresented in images of malignant lesions. In this paper, we encounter text and calipers placed on the images found in national databases containing fetal screening ultrasound scans, which correlate with standard planes to be predicted. In order to utilize the vast amounts of data available in these databases, we develop and validate a series of methods for minimizing the confounding effects of embedded text and calipers on deep learning algorithms designed for ultrasound, using standard plane classification as a test case.
Super-Resolution Information Enhancement For Crowd Counting
Mar 13, 2023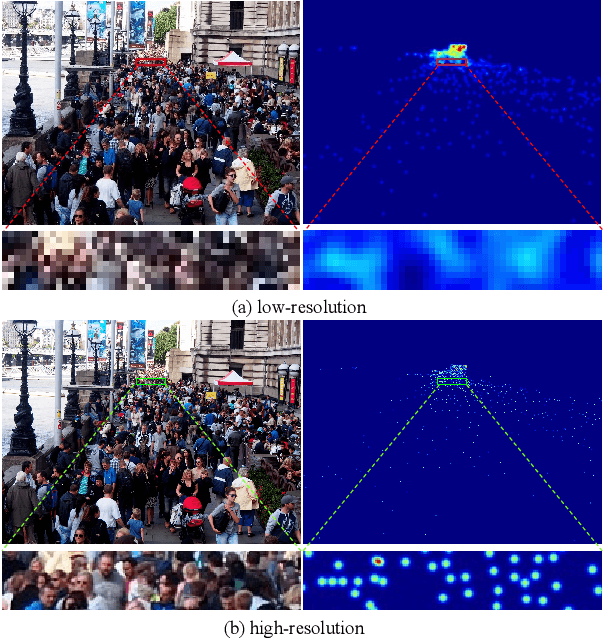
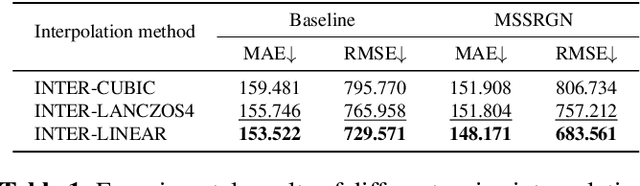
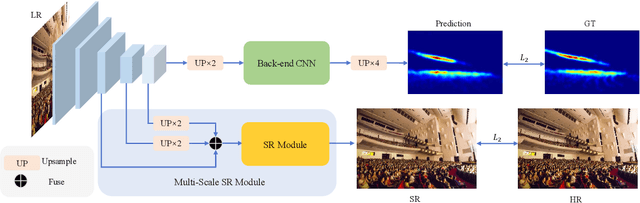
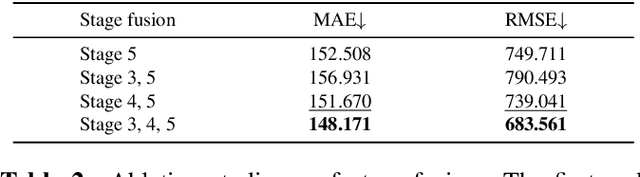
Crowd counting is a challenging task due to the heavy occlusions, scales, and density variations. Existing methods handle these challenges effectively while ignoring low-resolution (LR) circumstances. The LR circumstances weaken the counting performance deeply for two crucial reasons: 1) limited detail information; 2) overlapping head regions accumulate in density maps and result in extreme ground-truth values. An intuitive solution is to employ super-resolution (SR) pre-processes for the input LR images. However, it complicates the inference steps and thus limits application potentials when requiring real-time. We propose a more elegant method termed Multi-Scale Super-Resolution Module (MSSRM). It guides the network to estimate the lost de tails and enhances the detailed information in the feature space. Noteworthy that the MSSRM is plug-in plug-out and deals with the LR problems with no inference cost. As the proposed method requires SR labels, we further propose a Super-Resolution Crowd Counting dataset (SR-Crowd). Extensive experiments on three datasets demonstrate the superiority of our method. The code will be available at https://github.com/PRIS-CV/MSSRM.git.
A Hierarchical Transformer Encoder to Improve Entire Neoplasm Segmentation on Whole Slide Image of Hepatocellular Carcinoma
Jul 11, 2023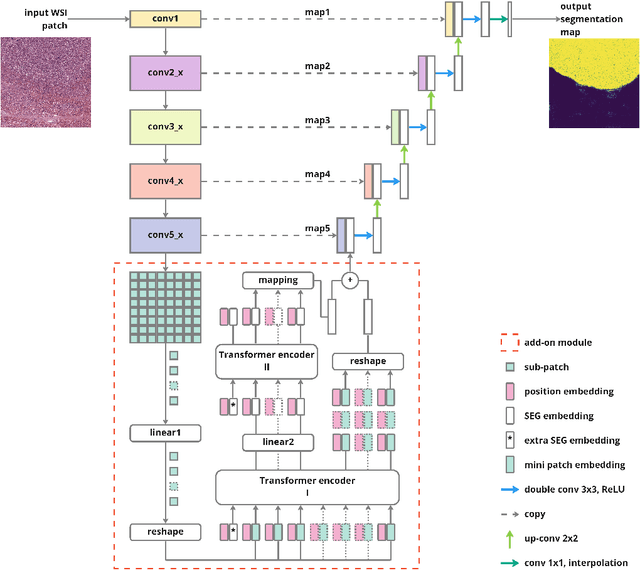
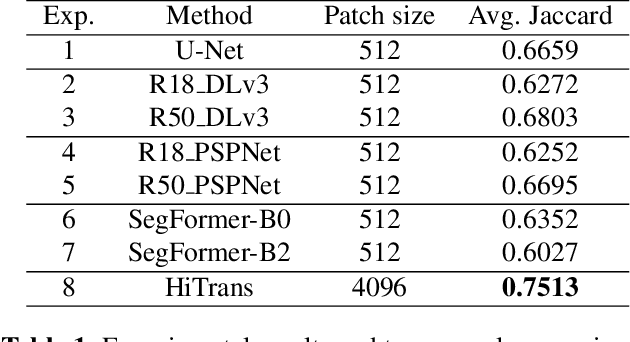
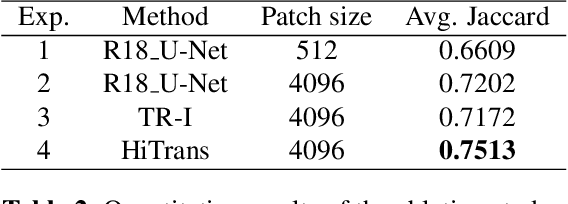

In digital histopathology, entire neoplasm segmentation on Whole Slide Image (WSI) of Hepatocellular Carcinoma (HCC) plays an important role, especially as a preprocessing filter to automatically exclude healthy tissue, in histological molecular correlations mining and other downstream histopathological tasks. The segmentation task remains challenging due to HCC's inherent high-heterogeneity and the lack of dependency learning in large field of view. In this article, we propose a novel deep learning architecture with a hierarchical Transformer encoder, HiTrans, to learn the global dependencies within expanded 4096$\times$4096 WSI patches. HiTrans is designed to encode and decode the patches with larger reception fields and the learned global dependencies, compared to the state-of-the-art Fully Convolutional Neural networks (FCNN). Empirical evaluations verified that HiTrans leads to better segmentation performance by taking into account regional and global dependency information.
Exploiting Asymmetry in Logic Puzzles: Using ZDDs for Symbolic Model Checking Dynamic Epistemic Logic
Jul 11, 2023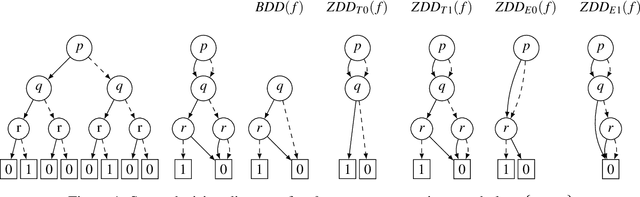
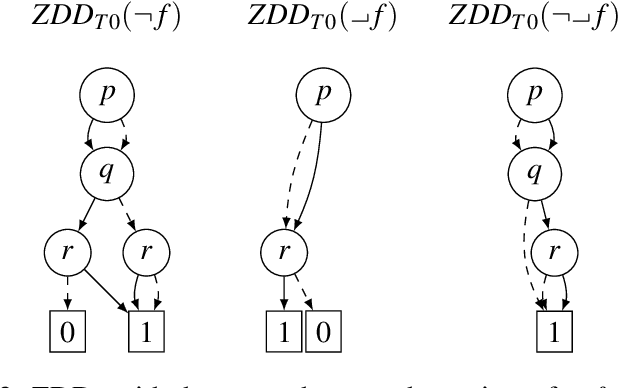
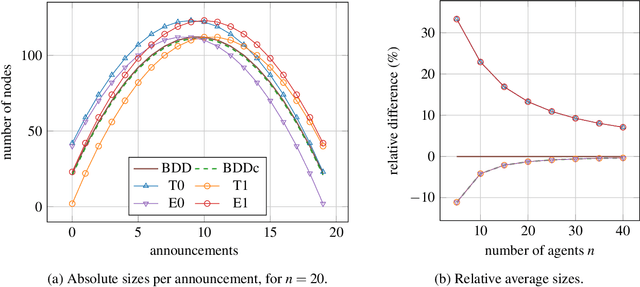
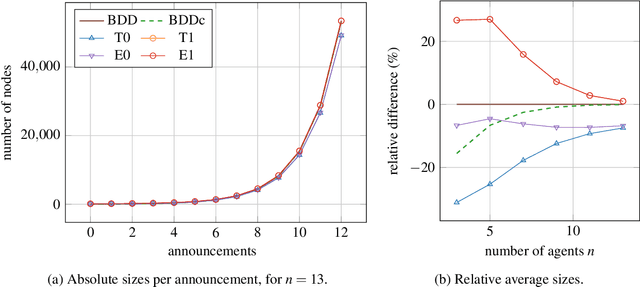
Binary decision diagrams (BDDs) are widely used to mitigate the state-explosion problem in model checking. A variation of BDDs are Zero-suppressed Decision Diagrams (ZDDs) which omit variables that must be false, instead of omitting variables that do not matter. We use ZDDs to symbolically encode Kripke models used in Dynamic Epistemic Logic, a framework to reason about knowledge and information dynamics in multi-agent systems. We compare the memory usage of different ZDD variants for three well-known examples from the literature: the Muddy Children, the Sum and Product puzzle and the Dining Cryptographers. Our implementation is based on the existing model checker SMCDEL and the CUDD library. Our results show that replacing BDDs with the right variant of ZDDs can significantly reduce memory usage. This suggests that ZDDs are a useful tool for model checking multi-agent systems.
* In Proceedings TARK 2023, arXiv:2307.04005
Self-Supervised Learning with Lie Symmetries for Partial Differential Equations
Jul 11, 2023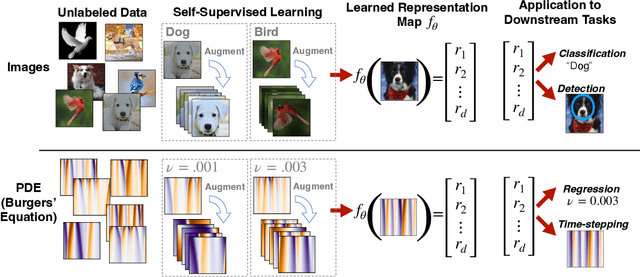
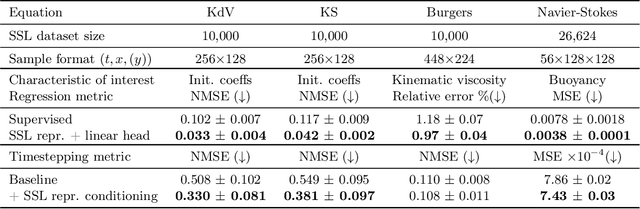
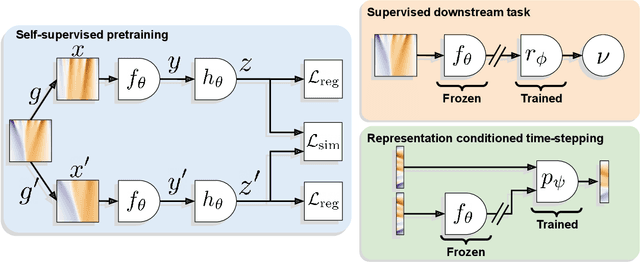

Machine learning for differential equations paves the way for computationally efficient alternatives to numerical solvers, with potentially broad impacts in science and engineering. Though current algorithms typically require simulated training data tailored to a given setting, one may instead wish to learn useful information from heterogeneous sources, or from real dynamical systems observations that are messy or incomplete. In this work, we learn general-purpose representations of PDEs from heterogeneous data by implementing joint embedding methods for self-supervised learning (SSL), a framework for unsupervised representation learning that has had notable success in computer vision. Our representation outperforms baseline approaches to invariant tasks, such as regressing the coefficients of a PDE, while also improving the time-stepping performance of neural solvers. We hope that our proposed methodology will prove useful in the eventual development of general-purpose foundation models for PDEs.
Mao-Zedong At SemEval-2023 Task 4: Label Represention Multi-Head Attention Model With Contrastive Learning-Enhanced Nearest Neighbor Mechanism For Multi-Label Text Classification
Jul 11, 2023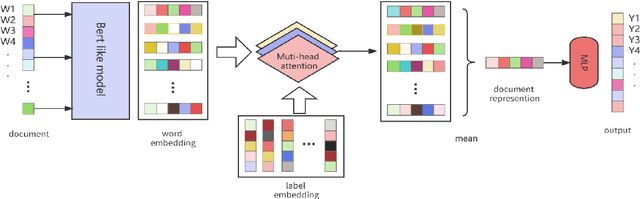
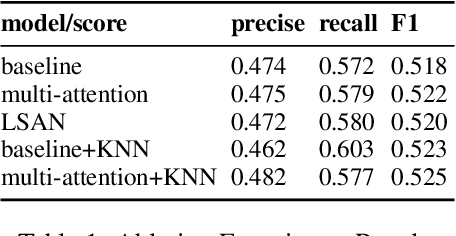
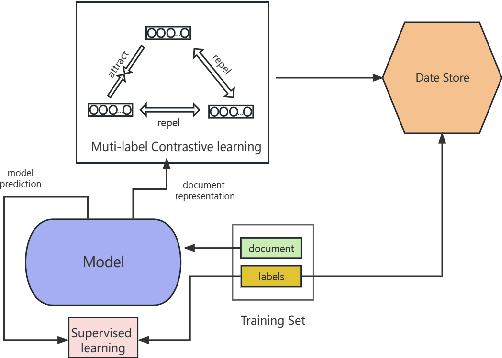
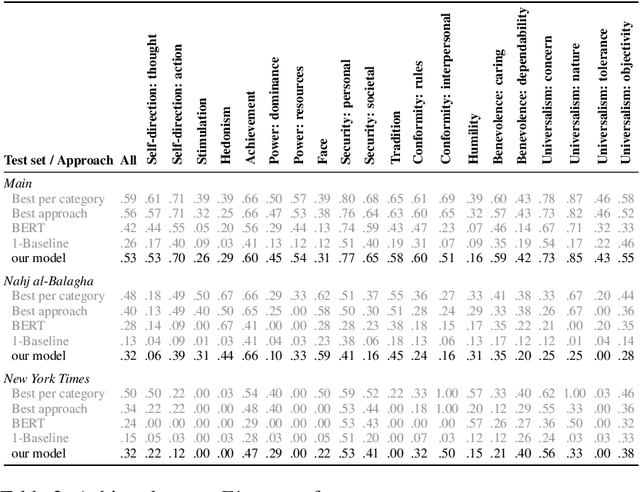
The study of human values is essential in both practical and theoretical domains. With the development of computational linguistics, the creation of large-scale datasets has made it possible to automatically recognize human values accurately. SemEval 2023 Task 4\cite{kiesel:2023} provides a set of arguments and 20 types of human values that are implicitly expressed in each argument. In this paper, we present our team's solution. We use the Roberta\cite{liu_roberta_2019} model to obtain the word vector encoding of the document and propose a multi-head attention mechanism to establish connections between specific labels and semantic components. Furthermore, we use a contrastive learning-enhanced K-nearest neighbor mechanism\cite{su_contrastive_2022} to leverage existing instance information for prediction. Our approach achieved an F1 score of 0.533 on the test set and ranked fourth on the leaderboard.
On the Limits of Single Anchor Localization: Near-Field vs Far-Field
Jun 30, 2023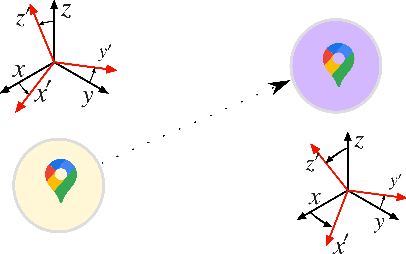
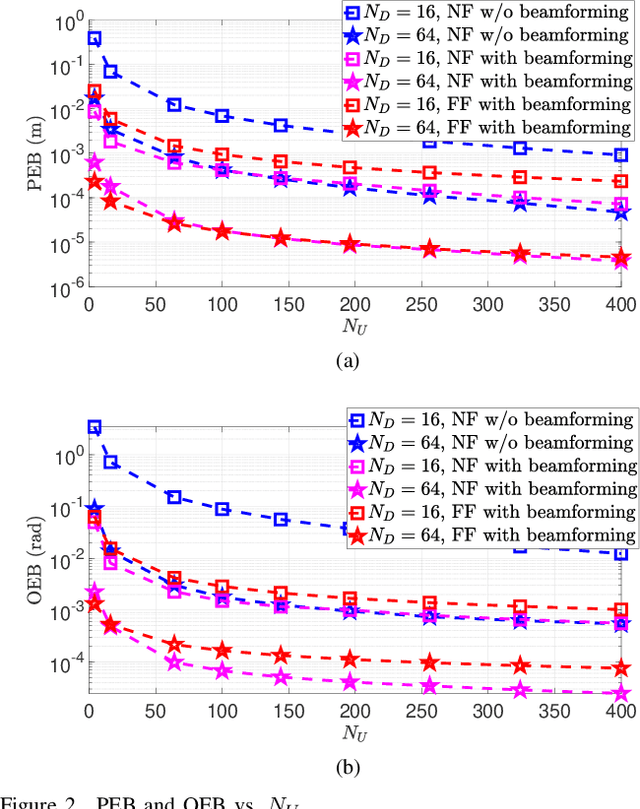
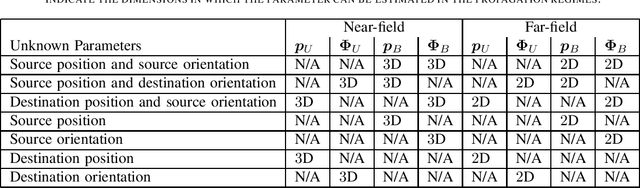
It is well known that a single anchor can be used to determine the position and orientation of an agent communicating with it. However, it is not clear what information about the anchor or the agent is necessary to perform this localization, especially when the agent is in the near-field of the anchor. Hence, in this paper, to investigate the limits of localizing an agent with some uncertainty in the anchor location, we consider a wireless link consisting of source and destination nodes. More specifically, we present a Fisher information theoretical investigation of the possibility of estimating different combinations of the source and destination's position and orientation from the signal received at the destination. To present a comprehensive study, we perform this Fisher information theoretic investigation under both the near and far field propagation models. One of the key insights is that while the source or destination's $3$D orientation can be jointly estimated with the source or destination's $3$D position in the near-field propagation regime, only the source or destination's $2$D orientation can be jointly estimated with the source or destination's $2$D position in the far-field propagation regime. Also, a simulation of the FIM indicates that in the near-field, we can estimate the source's $3$D orientation angles with no beamforming, but in the far-field, we can not estimate the source's $2$D orientation angles when no beamforming is employed.
Toward Intelligent and Efficient 6G Networks: JCSC Enabled On-Purpose Machine Communications
Jun 30, 2023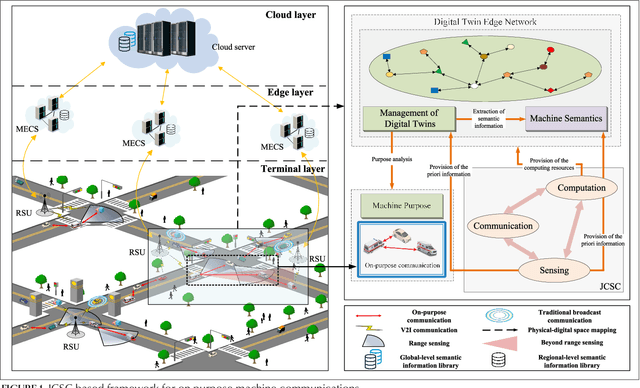
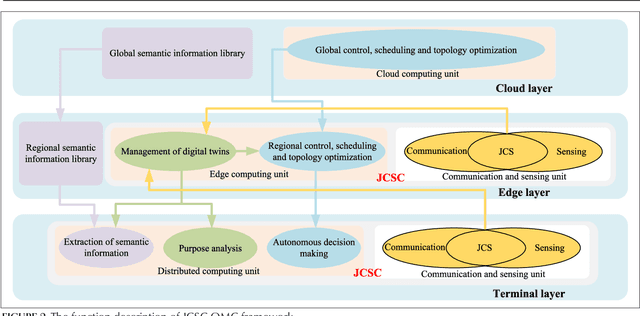
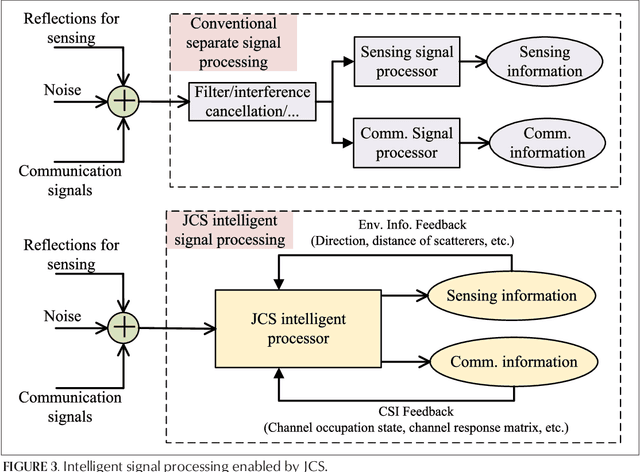
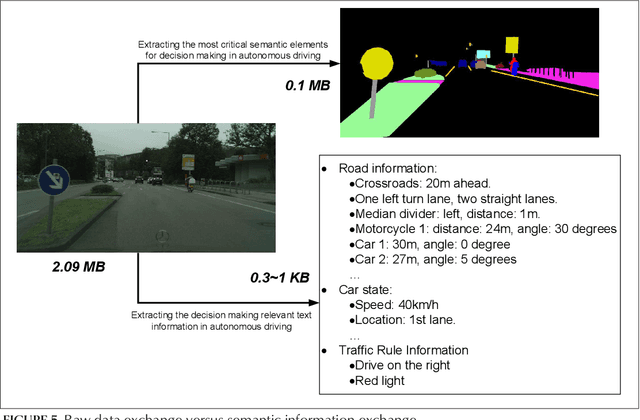
Driven by the vision of "intelligent connection of everything" toward 6G, the collective intelligence of networked machines can be fully exploited to improve system efficiency by shifting the paradigm of wireless communication design from naive maximalist approaches to intelligent value-based approaches. In this article, we propose an on-purpose machine communication framework enabled by joint communication, sensing, and computation (JCSC) technology, which employs machine semantics as the interactive information flow. Naturally, there are potential technical barriers to be solved before the widespread adoption of on-purpose communications, including the conception of machine purpose, fast and concise networking strategy, and semantics-aware information exchange mechanism during the process of task-oriented cooperation. Hence, we discuss enabling technologies complemented by a range of open challenges. The simulation result shows that the proposed framework can significantly reduce networking overhead and improve communication efficiency.
* 8 pages, 6 figures
A New Task and Dataset on Detecting Attacks on Human Rights Defenders
Jun 30, 2023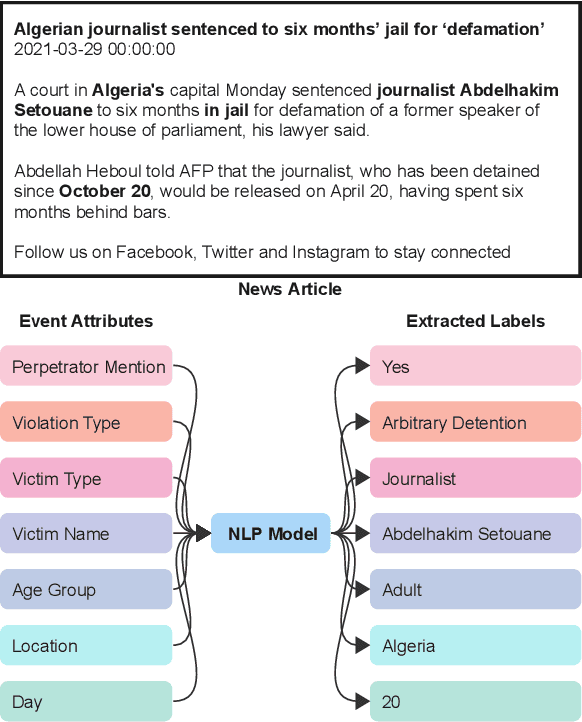



The ability to conduct retrospective analyses of attacks on human rights defenders over time and by location is important for humanitarian organizations to better understand historical or ongoing human rights violations and thus better manage the global impact of such events. We hypothesize that NLP can support such efforts by quickly processing large collections of news articles to detect and summarize the characteristics of attacks on human rights defenders. To that end, we propose a new dataset for detecting Attacks on Human Rights Defenders (HRDsAttack) consisting of crowdsourced annotations on 500 online news articles. The annotations include fine-grained information about the type and location of the attacks, as well as information about the victim(s). We demonstrate the usefulness of the dataset by using it to train and evaluate baseline models on several sub-tasks to predict the annotated characteristics.
3D-SeqMOS: A Novel Sequential 3D Moving Object Segmentation in Autonomous Driving
Jul 18, 2023

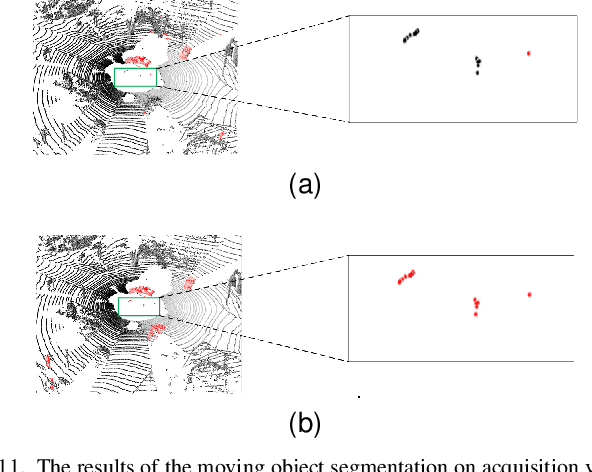
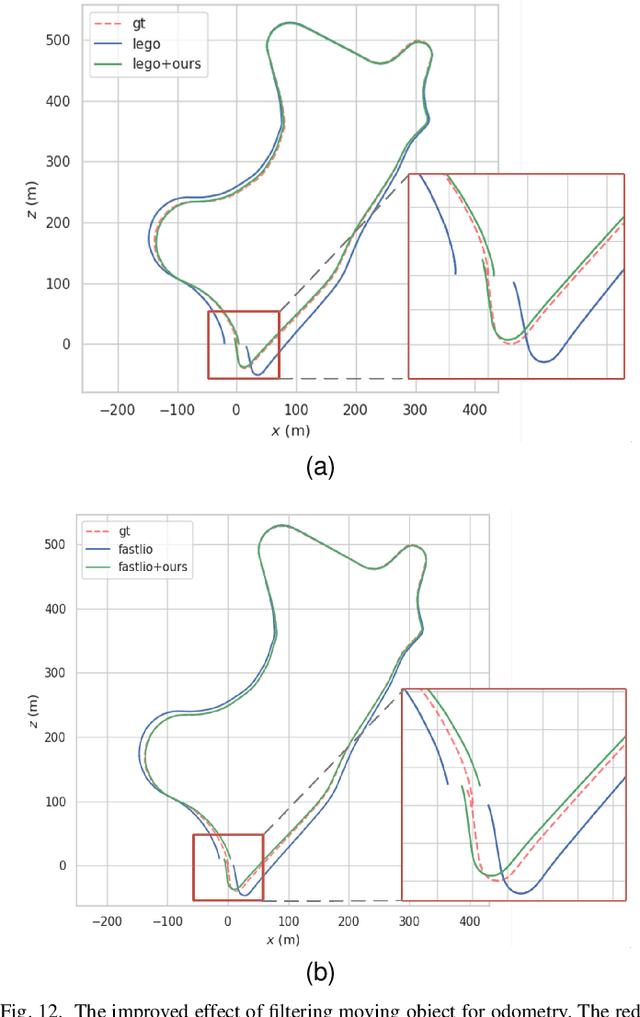
For the SLAM system in robotics and autonomous driving, the accuracy of front-end odometry and back-end loop-closure detection determine the whole intelligent system performance. But the LiDAR-SLAM could be disturbed by current scene moving objects, resulting in drift errors and even loop-closure failure. Thus, the ability to detect and segment moving objects is essential for high-precision positioning and building a consistent map. In this paper, we address the problem of moving object segmentation from 3D LiDAR scans to improve the odometry and loop-closure accuracy of SLAM. We propose a novel 3D Sequential Moving-Object-Segmentation (3D-SeqMOS) method that can accurately segment the scene into moving and static objects, such as moving and static cars. Different from the existing projected-image method, we process the raw 3D point cloud and build a 3D convolution neural network for MOS task. In addition, to make full use of the spatio-temporal information of point cloud, we propose a point cloud residual mechanism using the spatial features of current scan and the temporal features of previous residual scans. Besides, we build a complete SLAM framework to verify the effectiveness and accuracy of 3D-SeqMOS. Experiments on SemanticKITTI dataset show that our proposed 3D-SeqMOS method can effectively detect moving objects and improve the accuracy of LiDAR odometry and loop-closure detection. The test results show our 3D-SeqMOS outperforms the state-of-the-art method by 12.4%. We extend the proposed method to the SemanticKITTI: Moving Object Segmentation competition and achieve the 2nd in the leaderboard, showing its effectiveness.