 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Prompt Switch: Efficient CLIP Adaptation for Text-Video Retrieval
Aug 15, 2023
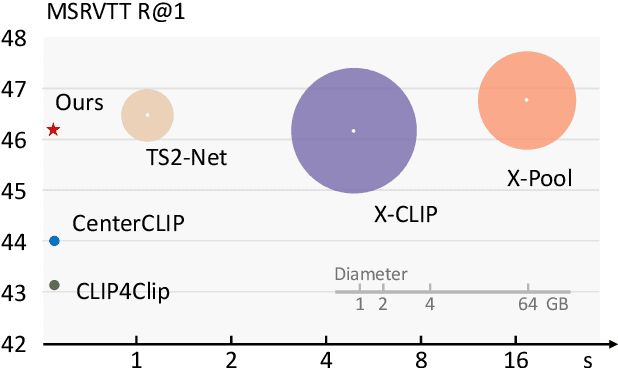
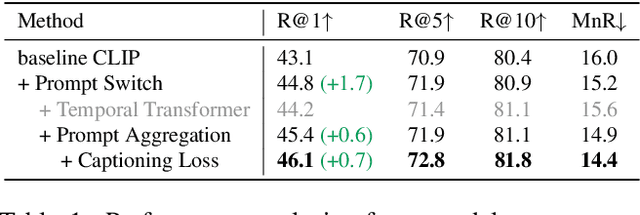
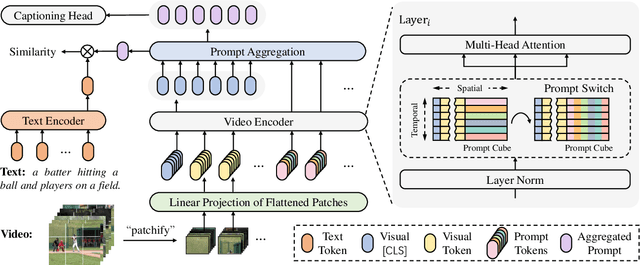
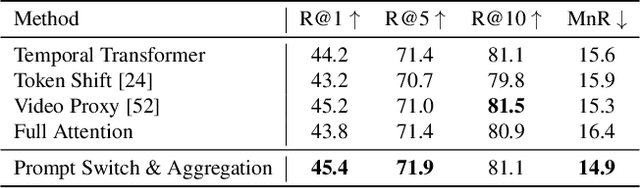
In text-video retrieval, recent works have benefited from the powerful learning capabilities of pre-trained text-image foundation models (e.g., CLIP) by adapting them to the video domain. A critical problem for them is how to effectively capture the rich semantics inside the video using the image encoder of CLIP. To tackle this, state-of-the-art methods adopt complex cross-modal modeling techniques to fuse the text information into video frame representations, which, however, incurs severe efficiency issues in large-scale retrieval systems as the video representations must be recomputed online for every text query. In this paper, we discard this problematic cross-modal fusion process and aim to learn semantically-enhanced representations purely from the video, so that the video representations can be computed offline and reused for different texts. Concretely, we first introduce a spatial-temporal "Prompt Cube" into the CLIP image encoder and iteratively switch it within the encoder layers to efficiently incorporate the global video semantics into frame representations. We then propose to apply an auxiliary video captioning objective to train the frame representations, which facilitates the learning of detailed video semantics by providing fine-grained guidance in the semantic space. With a naive temporal fusion strategy (i.e., mean-pooling) on the enhanced frame representations, we obtain state-of-the-art performances on three benchmark datasets, i.e., MSR-VTT, MSVD, and LSMDC.
AttMOT: Improving Multiple-Object Tracking by Introducing Auxiliary Pedestrian Attributes
Aug 15, 2023


Multi-object tracking (MOT) is a fundamental problem in computer vision with numerous applications, such as intelligent surveillance and automated driving. Despite the significant progress made in MOT, pedestrian attributes, such as gender, hairstyle, body shape, and clothing features, which contain rich and high-level information, have been less explored. To address this gap, we propose a simple, effective, and generic method to predict pedestrian attributes to support general Re-ID embedding. We first introduce AttMOT, a large, highly enriched synthetic dataset for pedestrian tracking, containing over 80k frames and 6 million pedestrian IDs with different time, weather conditions, and scenarios. To the best of our knowledge, AttMOT is the first MOT dataset with semantic attributes. Subsequently, we explore different approaches to fuse Re-ID embedding and pedestrian attributes, including attention mechanisms, which we hope will stimulate the development of attribute-assisted MOT. The proposed method AAM demonstrates its effectiveness and generality on several representative pedestrian multi-object tracking benchmarks, including MOT17 and MOT20, through experiments on the AttMOT dataset. When applied to state-of-the-art trackers, AAM achieves consistent improvements in MOTA, HOTA, AssA, IDs, and IDF1 scores. For instance, on MOT17, the proposed method yields a +1.1 MOTA, +1.7 HOTA, and +1.8 IDF1 improvement when used with FairMOT. To encourage further research on attribute-assisted MOT, we will release the AttMOT dataset.
Multimodal Dataset Distillation for Image-Text Retrieval
Aug 15, 2023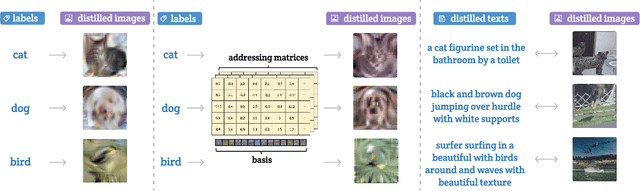
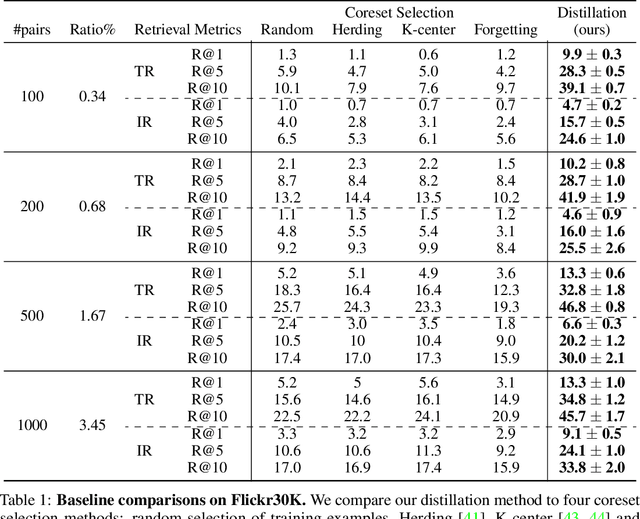
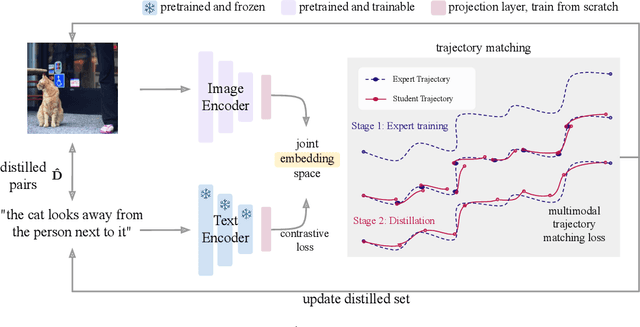
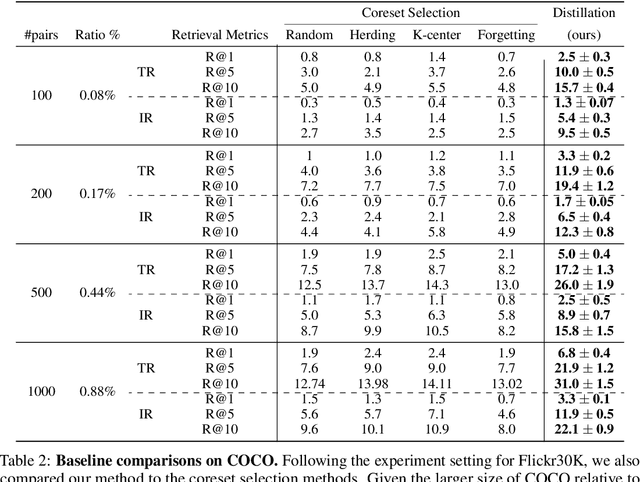
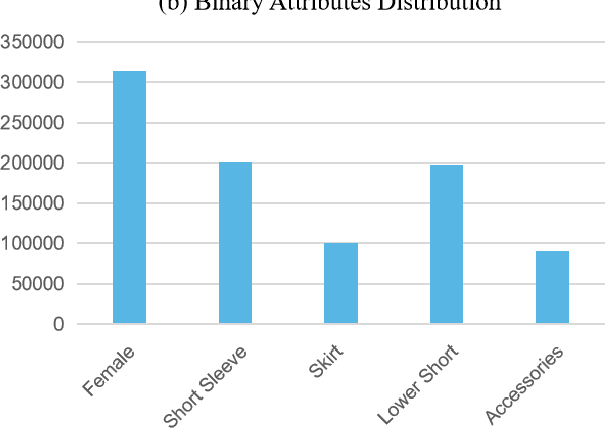
Dataset distillation methods offer the promise of reducing a large-scale dataset down to a significantly smaller set of (potentially synthetic) training examples, which preserve sufficient information for training a new model from scratch. So far dataset distillation methods have been developed for image classification. However, with the rise in capabilities of vision-language models, and especially given the scale of datasets necessary to train these models, the time is ripe to expand dataset distillation methods beyond image classification. In this work, we take the first steps towards this goal by expanding on the idea of trajectory matching to create a distillation method for vision-language datasets. The key challenge is that vision-language datasets do not have a set of discrete classes. To overcome this, our proposed multimodal dataset distillation method jointly distill the images and their corresponding language descriptions in a contrastive formulation. Since there are no existing baselines, we compare our approach to three coreset selection methods (strategic subsampling of the training dataset), which we adapt to the vision-language setting. We demonstrate significant improvements on the challenging Flickr30K and COCO retrieval benchmark: the best coreset selection method which selects 1000 image-text pairs for training is able to achieve only 5.6% image-to-text retrieval accuracy (recall@1); in contrast, our dataset distillation approach almost doubles that with just 100 (an order of magnitude fewer) training pairs.
Frugal random exploration strategy for shape recognition using statistical geometry
Aug 09, 2023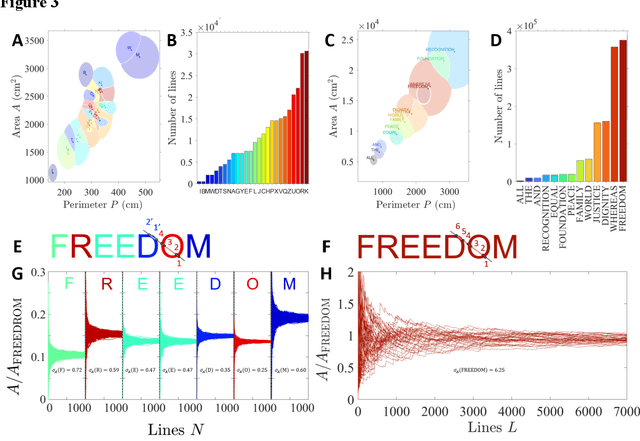
Very distinct strategies can be deployed to recognize and characterize an unknown environment or a shape. A recent and promising approach, especially in robotics, is to reduce the complexity of the exploratory units to a minimum. Here, we show that this frugal strategy can be taken to the extreme by exploiting the power of statistical geometry and introducing new invariant features. We show that an elementary robot devoid of any orientation or observation system, exploring randomly, can access global information about an environment such as the values of the explored area and perimeter. The explored shapes are of arbitrary geometry and may even non-connected. From a dictionary, this most simple robot can thus identify various shapes such as famous monuments and even read a text.
Information Fusion via Symbolic Regression: A Tutorial in the Context of Human Health
May 31, 2023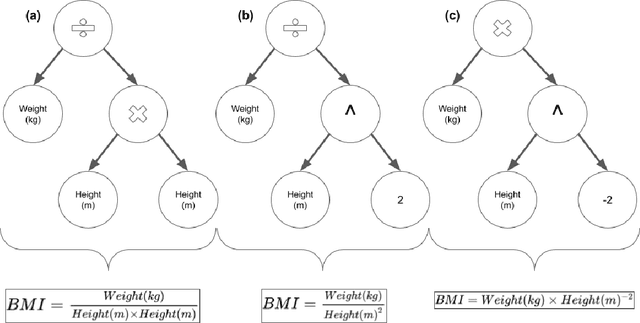
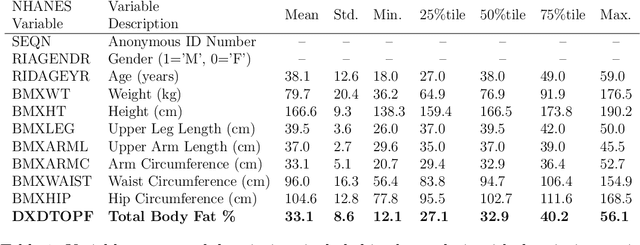
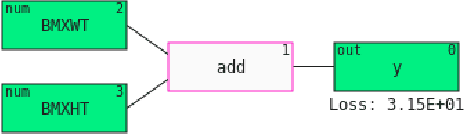
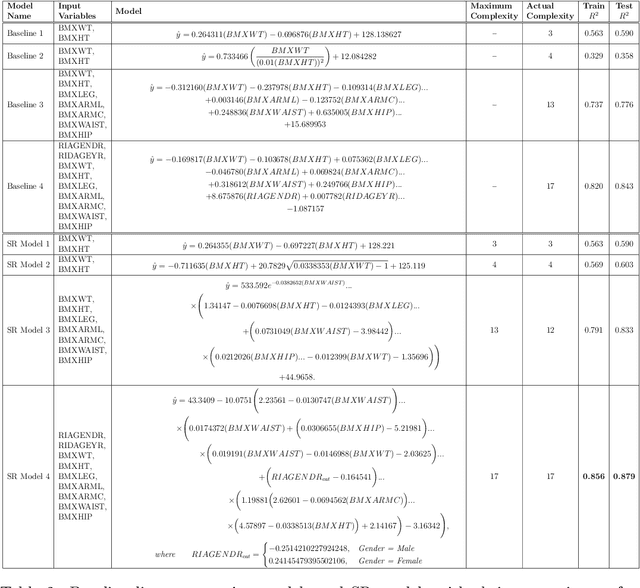
This tutorial paper provides a general overview of symbolic regression (SR) with specific focus on standards of interpretability. We posit that interpretable modeling, although its definition is still disputed in the literature, is a practical way to support the evaluation of successful information fusion. In order to convey the benefits of SR as a modeling technique, we demonstrate an application within the field of health and nutrition using publicly available National Health and Nutrition Examination Survey (NHANES) data from the Centers for Disease Control and Prevention (CDC), fusing together anthropometric markers into a simple mathematical expression to estimate body fat percentage. We discuss the advantages and challenges associated with SR modeling and provide qualitative and quantitative analyses of the learned models.
DeepGATGO: A Hierarchical Pretraining-Based Graph-Attention Model for Automatic Protein Function Prediction
Jul 24, 2023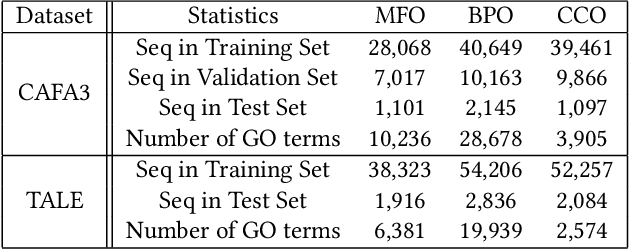
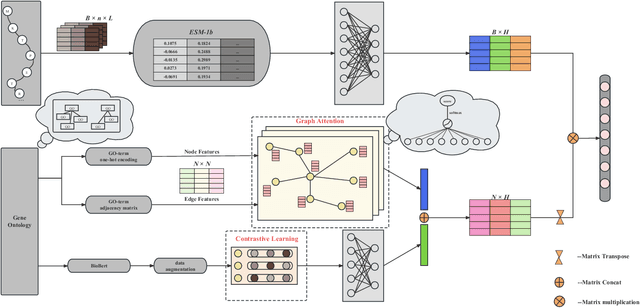
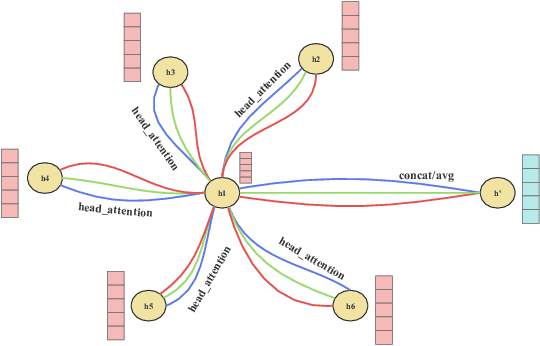
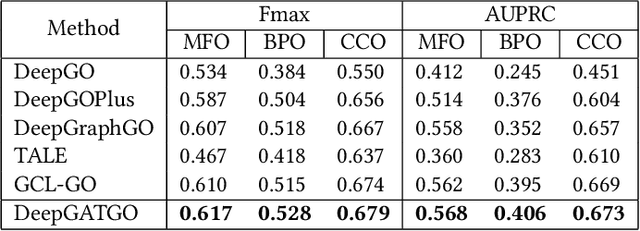
Automatic protein function prediction (AFP) is classified as a large-scale multi-label classification problem aimed at automating protein enrichment analysis to eliminate the current reliance on labor-intensive wet-lab methods. Currently, popular methods primarily combine protein-related information and Gene Ontology (GO) terms to generate final functional predictions. For example, protein sequences, structural information, and protein-protein interaction networks are integrated as prior knowledge to fuse with GO term embeddings and generate the ultimate prediction results. However, these methods are limited by the difficulty in obtaining structural information or network topology information, as well as the accuracy of such data. Therefore, more and more methods that only use protein sequences for protein function prediction have been proposed, which is a more reliable and computationally cheaper approach. However, the existing methods fail to fully extract feature information from protein sequences or label data because they do not adequately consider the intrinsic characteristics of the data itself. Therefore, we propose a sequence-based hierarchical prediction method, DeepGATGO, which processes protein sequences and GO term labels hierarchically, and utilizes graph attention networks (GATs) and contrastive learning for protein function prediction. Specifically, we compute embeddings of the sequence and label data using pre-trained models to reduce computational costs and improve the embedding accuracy. Then, we use GATs to dynamically extract the structural information of non-Euclidean data, and learn general features of the label dataset with contrastive learning by constructing positive and negative example samples. Experimental results demonstrate that our proposed model exhibits better scalability in GO term enrichment analysis on large-scale datasets.
Complete and separate: Conditional separation with missing target source attribute completion
Jul 27, 2023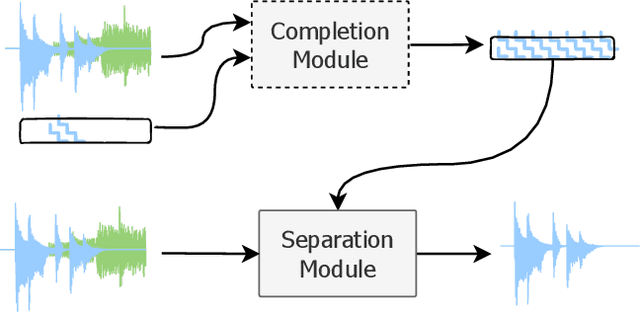
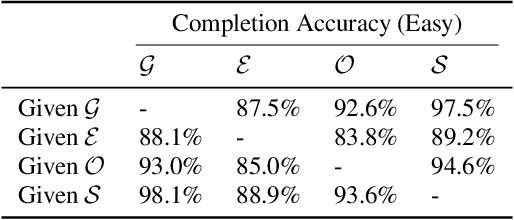
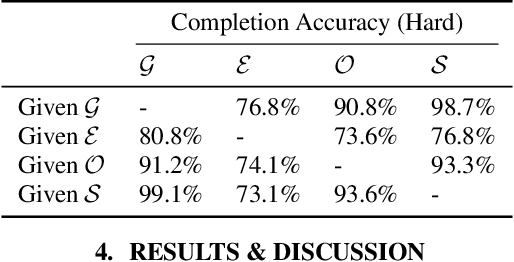
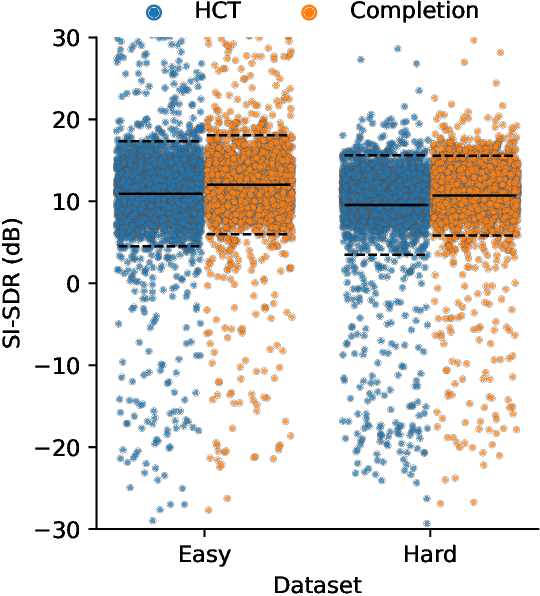
Recent approaches in source separation leverage semantic information about their input mixtures and constituent sources that when used in conditional separation models can achieve impressive performance. Most approaches along these lines have focused on simple descriptions, which are not always useful for varying types of input mixtures. In this work, we present an approach in which a model, given an input mixture and partial semantic information about a target source, is trained to extract additional semantic data. We then leverage this pre-trained model to improve the separation performance of an uncoupled multi-conditional separation network. Our experiments demonstrate that the separation performance of this multi-conditional model is significantly improved, approaching the performance of an oracle model with complete semantic information. Furthermore, our approach achieves performance levels that are comparable to those of the best performing specialized single conditional models, thus providing an easier to use alternative.
Developmental Bootstrapping of AIs
Aug 17, 2023

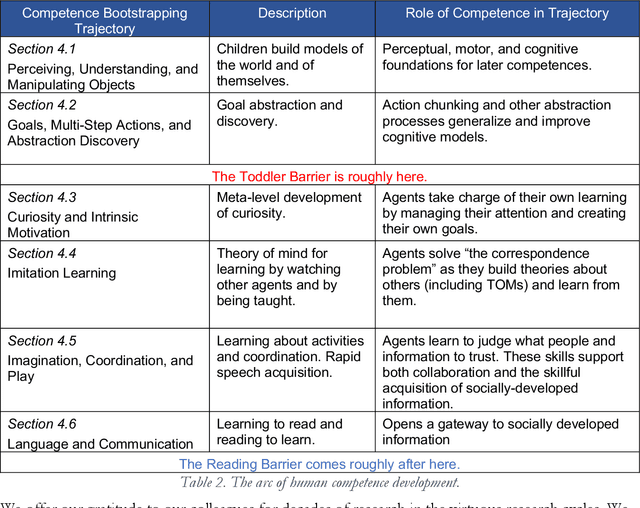
Although some current AIs surpass human abilities in closed artificial worlds such as board games, their abilities in the real world are limited. They make strange mistakes and do not notice them. They cannot be instructed easily, fail to use common sense, and lack curiosity. They do not make good collaborators. Mainstream approaches for creating AIs are the traditional manually-constructed symbolic AI approach and generative and deep learning AI approaches including large language models (LLMs). These systems are not well suited for creating robust and trustworthy AIs. Although it is outside of the mainstream, the developmental bootstrapping approach has more potential. In developmental bootstrapping, AIs develop competences like human children do. They start with innate competences. They interact with the environment and learn from their interactions. They incrementally extend their innate competences with self-developed competences. They interact and learn from people and establish perceptual, cognitive, and common grounding. They acquire the competences they need through bootstrapping. However, developmental robotics has not yet produced AIs with robust adult-level competences. Projects have typically stopped at the Toddler Barrier corresponding to human infant development at about two years of age, before their speech is fluent. They also do not bridge the Reading Barrier, to skillfully and skeptically draw on the socially developed information resources that power current LLMs. The next competences in human cognitive development involve intrinsic motivation, imitation learning, imagination, coordination, and communication. This position paper lays out the logic, prospects, gaps, and challenges for extending the practice of developmental bootstrapping to acquire further competences and create robust, resilient, and human-compatible AIs.
Visual Information Extraction in the Wild: Practical Dataset and End-to-end Solution
May 12, 2023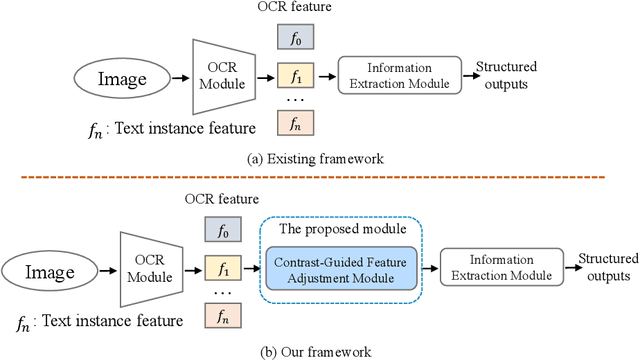

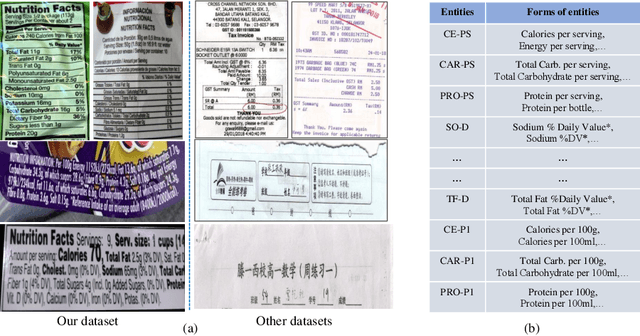
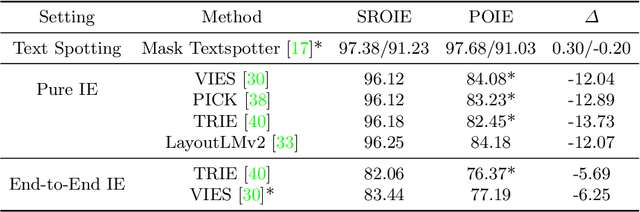
Visual information extraction (VIE), which aims to simultaneously perform OCR and information extraction in a unified framework, has drawn increasing attention due to its essential role in various applications like understanding receipts, goods, and traffic signs. However, as existing benchmark datasets for VIE mainly consist of document images without the adequate diversity of layout structures, background disturbs, and entity categories, they cannot fully reveal the challenges of real-world applications. In this paper, we propose a large-scale dataset consisting of camera images for VIE, which contains not only the larger variance of layout, backgrounds, and fonts but also much more types of entities. Besides, we propose a novel framework for end-to-end VIE that combines the stages of OCR and information extraction in an end-to-end learning fashion. Different from the previous end-to-end approaches that directly adopt OCR features as the input of an information extraction module, we propose to use contrastive learning to narrow the semantic gap caused by the difference between the tasks of OCR and information extraction. We evaluate the existing end-to-end methods for VIE on the proposed dataset and observe that the performance of these methods has a distinguishable drop from SROIE (a widely used English dataset) to our proposed dataset due to the larger variance of layout and entities. These results demonstrate our dataset is more practical for promoting advanced VIE algorithms. In addition, experiments demonstrate that the proposed VIE method consistently achieves the obvious performance gains on the proposed and SROIE datasets.
DS-Depth: Dynamic and Static Depth Estimation via a Fusion Cost Volume
Aug 14, 2023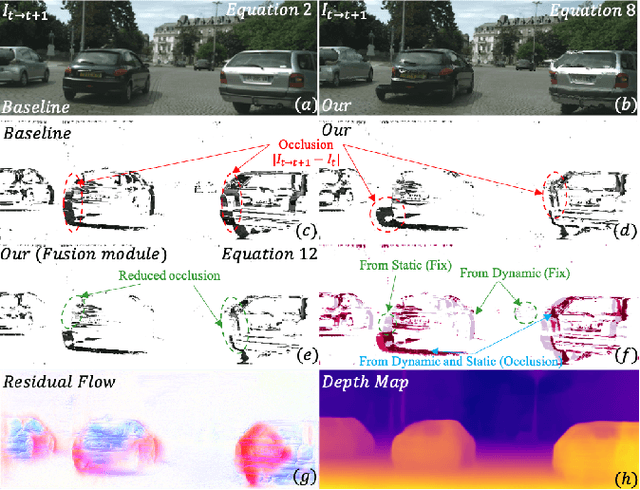
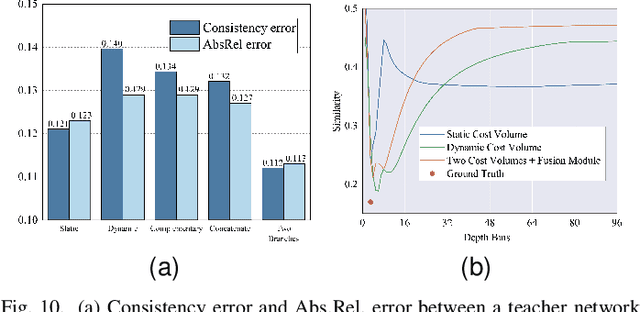
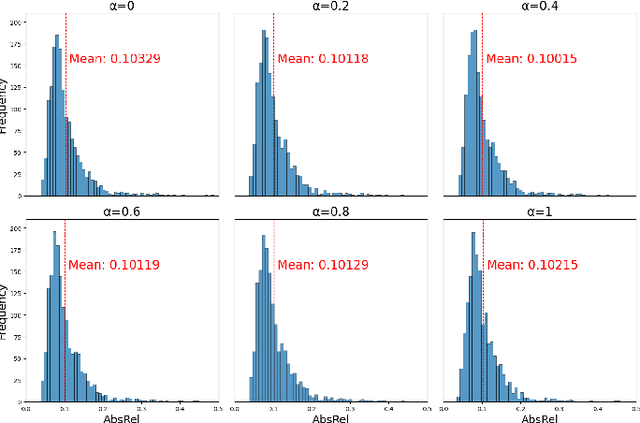
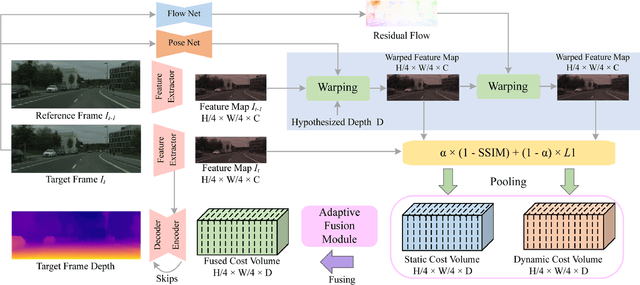
Self-supervised monocular depth estimation methods typically rely on the reprojection error to capture geometric relationships between successive frames in static environments. However, this assumption does not hold in dynamic objects in scenarios, leading to errors during the view synthesis stage, such as feature mismatch and occlusion, which can significantly reduce the accuracy of the generated depth maps. To address this problem, we propose a novel dynamic cost volume that exploits residual optical flow to describe moving objects, improving incorrectly occluded regions in static cost volumes used in previous work. Nevertheless, the dynamic cost volume inevitably generates extra occlusions and noise, thus we alleviate this by designing a fusion module that makes static and dynamic cost volumes compensate for each other. In other words, occlusion from the static volume is refined by the dynamic volume, and incorrect information from the dynamic volume is eliminated by the static volume. Furthermore, we propose a pyramid distillation loss to reduce photometric error inaccuracy at low resolutions and an adaptive photometric error loss to alleviate the flow direction of the large gradient in the occlusion regions. We conducted extensive experiments on the KITTI and Cityscapes datasets, and the results demonstrate that our model outperforms previously published baselines for self-supervised monocular depth estimation.