 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Graph Bayesian Optimization for Multiplex Influence Maximization
Mar 25, 2024
Influence maximization (IM) is the problem of identifying a limited number of initial influential users within a social network to maximize the number of influenced users. However, previous research has mostly focused on individual information propagation, neglecting the simultaneous and interactive dissemination of multiple information items. In reality, when users encounter a piece of information, such as a smartphone product, they often associate it with related products in their minds, such as earphones or computers from the same brand. Additionally, information platforms frequently recommend related content to users, amplifying this cascading effect and leading to multiplex influence diffusion. This paper first formulates the Multiplex Influence Maximization (Multi-IM) problem using multiplex diffusion models with an information association mechanism. In this problem, the seed set is a combination of influential users and information. To effectively manage the combinatorial complexity, we propose Graph Bayesian Optimization for Multi-IM (GBIM). The multiplex diffusion process is thoroughly investigated using a highly effective global kernelized attention message-passing module. This module, in conjunction with Bayesian linear regression (BLR), produces a scalable surrogate model. A data acquisition module incorporating the exploration-exploitation trade-off is developed to optimize the seed set further. Extensive experiments on synthetic and real-world datasets have proven our proposed framework effective. The code is available at https://github.com/zirui-yuan/GBIM.
Towards a RAG-based Summarization Agent for the Electron-Ion Collider
Mar 26, 2024The complexity and sheer volume of information encompassing documents, papers, data, and other resources from large-scale experiments demand significant time and effort to navigate, making the task of accessing and utilizing these varied forms of information daunting, particularly for new collaborators and early-career scientists. To tackle this issue, a Retrieval Augmented Generation (RAG)--based Summarization AI for EIC (RAGS4EIC) is under development. This AI-Agent not only condenses information but also effectively references relevant responses, offering substantial advantages for collaborators. Our project involves a two-step approach: first, querying a comprehensive vector database containing all pertinent experiment information; second, utilizing a Large Language Model (LLM) to generate concise summaries enriched with citations based on user queries and retrieved data. We describe the evaluation methods that use RAG assessments (RAGAs) scoring mechanisms to assess the effectiveness of responses. Furthermore, we describe the concept of prompt template-based instruction-tuning which provides flexibility and accuracy in summarization. Importantly, the implementation relies on LangChain, which serves as the foundation of our entire workflow. This integration ensures efficiency and scalability, facilitating smooth deployment and accessibility for various user groups within the Electron Ion Collider (EIC) community. This innovative AI-driven framework not only simplifies the understanding of vast datasets but also encourages collaborative participation, thereby empowering researchers. As a demonstration, a web application has been developed to explain each stage of the RAG Agent development in detail.
Extracting Social Support and Social Isolation Information from Clinical Psychiatry Notes: Comparing a Rule-based NLP System and a Large Language Model
Mar 25, 2024Background: Social support (SS) and social isolation (SI) are social determinants of health (SDOH) associated with psychiatric outcomes. In electronic health records (EHRs), individual-level SS/SI is typically documented as narrative clinical notes rather than structured coded data. Natural language processing (NLP) algorithms can automate the otherwise labor-intensive process of data extraction. Data and Methods: Psychiatric encounter notes from Mount Sinai Health System (MSHS, n=300) and Weill Cornell Medicine (WCM, n=225) were annotated and established a gold standard corpus. A rule-based system (RBS) involving lexicons and a large language model (LLM) using FLAN-T5-XL were developed to identify mentions of SS and SI and their subcategories (e.g., social network, instrumental support, and loneliness). Results: For extracting SS/SI, the RBS obtained higher macro-averaged f-scores than the LLM at both MSHS (0.89 vs. 0.65) and WCM (0.85 vs. 0.82). For extracting subcategories, the RBS also outperformed the LLM at both MSHS (0.90 vs. 0.62) and WCM (0.82 vs. 0.81). Discussion and Conclusion: Unexpectedly, the RBS outperformed the LLMs across all metrics. Intensive review demonstrates that this finding is due to the divergent approach taken by the RBS and LLM. The RBS were designed and refined to follow the same specific rules as the gold standard annotations. Conversely, the LLM were more inclusive with categorization and conformed to common English-language understanding. Both approaches offer advantages and are made available open-source for future testing.
Situation Awareness for Driver-Centric Driving Style Adaptation
Mar 28, 2024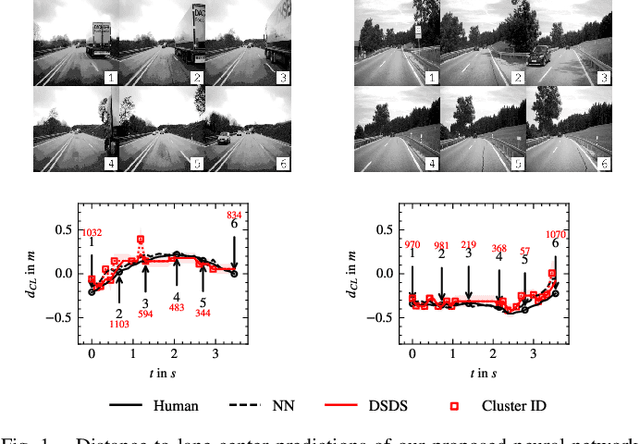
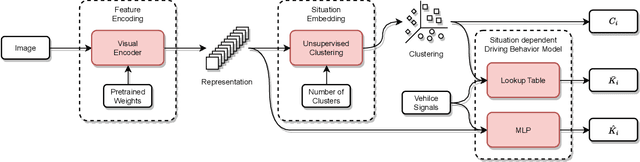
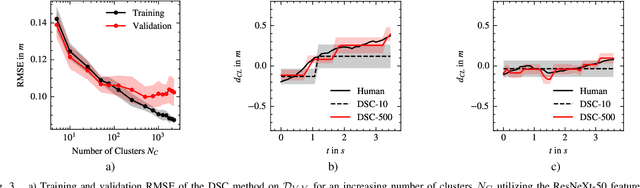

There is evidence that the driving style of an autonomous vehicle is important to increase the acceptance and trust of the passengers. The driving situation has been found to have a significant influence on human driving behavior. However, current driving style models only partially incorporate driving environment information, limiting the alignment between an agent and the given situation. Therefore, we propose a situation-aware driving style model based on different visual feature encoders pretrained on fleet data, as well as driving behavior predictors, which are adapted to the driving style of a specific driver. Our experiments show that the proposed method outperforms static driving styles significantly and forms plausible situation clusters. Furthermore, we found that feature encoders pretrained on our dataset lead to more precise driving behavior modeling. In contrast, feature encoders pretrained supervised and unsupervised on different data sources lead to more specific situation clusters, which can be utilized to constrain and control the driving style adaptation for specific situations. Moreover, in a real-world setting, where driving style adaptation is happening iteratively, we found the MLP-based behavior predictors achieve good performance initially but suffer from catastrophic forgetting. In contrast, behavior predictors based on situationdependent statistics can learn iteratively from continuous data streams by design. Overall, our experiments show that important information for driving behavior prediction is contained within the visual feature encoder. The dataset is publicly available at huggingface.co/datasets/jHaselberger/SADC-Situation-Awareness-for-Driver-Centric-Driving-Style-Adaptation.
A Simple and Effective Point-based Network for Event Camera 6-DOFs Pose Relocalization
Mar 28, 2024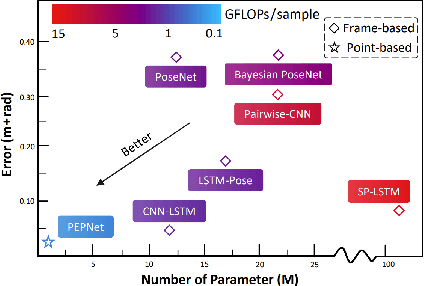
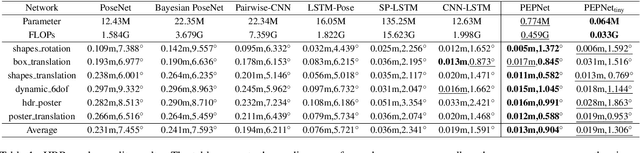
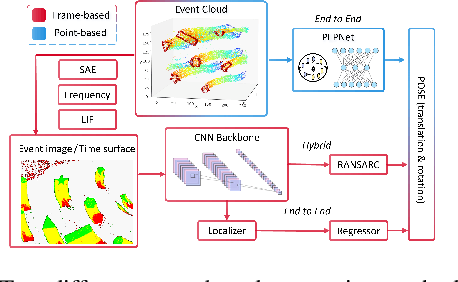

Event cameras exhibit remarkable attributes such as high dynamic range, asynchronicity, and low latency, making them highly suitable for vision tasks that involve high-speed motion in challenging lighting conditions. These cameras implicitly capture movement and depth information in events, making them appealing sensors for Camera Pose Relocalization (CPR) tasks. Nevertheless, existing CPR networks based on events neglect the pivotal fine-grained temporal information in events, resulting in unsatisfactory performance. Moreover, the energy-efficient features are further compromised by the use of excessively complex models, hindering efficient deployment on edge devices. In this paper, we introduce PEPNet, a simple and effective point-based network designed to regress six degrees of freedom (6-DOFs) event camera poses. We rethink the relationship between the event camera and CPR tasks, leveraging the raw Point Cloud directly as network input to harness the high-temporal resolution and inherent sparsity of events. PEPNet is adept at abstracting the spatial and implicit temporal features through hierarchical structure and explicit temporal features by Attentive Bi-directional Long Short-Term Memory (A-Bi-LSTM). By employing a carefully crafted lightweight design, PEPNet delivers state-of-the-art (SOTA) performance on both indoor and outdoor datasets with meager computational resources. Specifically, PEPNet attains a significant 38% and 33% performance improvement on the random split IJRR and M3ED datasets, respectively. Moreover, the lightweight design version PEPNet$_{tiny}$ accomplishes results comparable to the SOTA while employing a mere 0.5% of the parameters.
An Empirical Study of Training ID-Agnostic Multi-modal Sequential Recommenders
Mar 30, 2024Sequential Recommendation (SR) aims to predict future user-item interactions based on historical interactions. While many SR approaches concentrate on user IDs and item IDs, the human perception of the world through multi-modal signals, like text and images, has inspired researchers to delve into constructing SR from multi-modal information without using IDs. However, the complexity of multi-modal learning manifests in diverse feature extractors, fusion methods, and pre-trained models. Consequently, designing a simple and universal \textbf{M}ulti-\textbf{M}odal \textbf{S}equential \textbf{R}ecommendation (\textbf{MMSR}) framework remains a formidable challenge. We systematically summarize the existing multi-modal related SR methods and distill the essence into four core components: visual encoder, text encoder, multimodal fusion module, and sequential architecture. Along these dimensions, we dissect the model designs, and answer the following sub-questions: First, we explore how to construct MMSR from scratch, ensuring its performance either on par with or exceeds existing SR methods without complex techniques. Second, we examine if MMSR can benefit from existing multi-modal pre-training paradigms. Third, we assess MMSR's capability in tackling common challenges like cold start and domain transferring. Our experiment results across four real-world recommendation scenarios demonstrate the great potential ID-agnostic multi-modal sequential recommendation. Our framework can be found at: https://github.com/MMSR23/MMSR.
Look-Around Before You Leap: High-Frequency Injected Transformer for Image Restoration
Mar 30, 2024Transformer-based approaches have achieved superior performance in image restoration, since they can model long-term dependencies well. However, the limitation in capturing local information restricts their capacity to remove degradations. While existing approaches attempt to mitigate this issue by incorporating convolutional operations, the core component in Transformer, i.e., self-attention, which serves as a low-pass filter, could unintentionally dilute or even eliminate the acquired local patterns. In this paper, we propose HIT, a simple yet effective High-frequency Injected Transformer for image restoration. Specifically, we design a window-wise injection module (WIM), which incorporates abundant high-frequency details into the feature map, to provide reliable references for restoring high-quality images. We also develop a bidirectional interaction module (BIM) to aggregate features at different scales using a mutually reinforced paradigm, resulting in spatially and contextually improved representations. In addition, we introduce a spatial enhancement unit (SEU) to preserve essential spatial relationships that may be lost due to the computations carried out across channel dimensions in the BIM. Extensive experiments on 9 tasks (real noise, real rain streak, raindrop, motion blur, moir\'e, shadow, snow, haze, and low-light condition) demonstrate that HIT with linear computational complexity performs favorably against the state-of-the-art methods. The source code and pre-trained models will be available at https://github.com/joshyZhou/HIT.
Seeing the Unseen: A Frequency Prompt Guided Transformer for Image Restoration
Mar 30, 2024How to explore useful features from images as prompts to guide the deep image restoration models is an effective way to solve image restoration. In contrast to mining spatial relations within images as prompt, which leads to characteristics of different frequencies being neglected and further remaining subtle or undetectable artifacts in the restored image, we develop a Frequency Prompting image restoration method, dubbed FPro, which can effectively provide prompt components from a frequency perspective to guild the restoration model address these differences. Specifically, we first decompose input features into separate frequency parts via dynamically learned filters, where we introduce a gating mechanism for suppressing the less informative elements within the kernels. To propagate useful frequency information as prompt, we then propose a dual prompt block, consisting of a low-frequency prompt modulator (LPM) and a high-frequency prompt modulator (HPM), to handle signals from different bands respectively. Each modulator contains a generation process to incorporate prompting components into the extracted frequency maps, and a modulation part that modifies the prompt feature with the guidance of the decoder features. Experimental results on commonly used benchmarks have demonstrated the favorable performance of our pipeline against SOTA methods on 5 image restoration tasks, including deraining, deraindrop, demoir\'eing, deblurring, and dehazing. The source code and pre-trained models will be available at https://github.com/joshyZhou/FPro.
HSIMamba: Hyperpsectral Imaging Efficient Feature Learning with Bidirectional State Space for Classification
Mar 30, 2024Classifying hyperspectral images is a difficult task in remote sensing, due to their complex high-dimensional data. To address this challenge, we propose HSIMamba, a novel framework that uses bidirectional reversed convolutional neural network pathways to extract spectral features more efficiently. Additionally, it incorporates a specialized block for spatial analysis. Our approach combines the operational efficiency of CNNs with the dynamic feature extraction capability of attention mechanisms found in Transformers. However, it avoids the associated high computational demands. HSIMamba is designed to process data bidirectionally, significantly enhancing the extraction of spectral features and integrating them with spatial information for comprehensive analysis. This approach improves classification accuracy beyond current benchmarks and addresses computational inefficiencies encountered with advanced models like Transformers. HSIMamba were tested against three widely recognized datasets Houston 2013, Indian Pines, and Pavia University and demonstrated exceptional performance, surpassing existing state-of-the-art models in HSI classification. This method highlights the methodological innovation of HSIMamba and its practical implications, which are particularly valuable in contexts where computational resources are limited. HSIMamba redefines the standards of efficiency and accuracy in HSI classification, thereby enhancing the capabilities of remote sensing applications. Hyperspectral imaging has become a crucial tool for environmental surveillance, agriculture, and other critical areas that require detailed analysis of the Earth surface. Please see our code in HSIMamba for more details.
DVLO: Deep Visual-LiDAR Odometry with Local-to-Global Feature Fusion and Bi-Directional Structure Alignment
Mar 27, 2024Information inside visual and LiDAR data is well complementary derived from the fine-grained texture of images and massive geometric information in point clouds. However, it remains challenging to explore effective visual-LiDAR fusion, mainly due to the intrinsic data structure inconsistency between two modalities: Images are regular and dense, but LiDAR points are unordered and sparse. To address the problem, we propose a local-to-global fusion network with bi-directional structure alignment. To obtain locally fused features, we project points onto image plane as cluster centers and cluster image pixels around each center. Image pixels are pre-organized as pseudo points for image-to-point structure alignment. Then, we convert points to pseudo images by cylindrical projection (point-to-image structure alignment) and perform adaptive global feature fusion between point features with local fused features. Our method achieves state-of-the-art performance on KITTI odometry and FlyingThings3D scene flow datasets compared to both single-modal and multi-modal methods. Codes will be released later.