 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information Extraction": models, code, and papers
Deep-learning-based decomposition of overlapping-sparse images: application at the vertex of neutrino interactions
Nov 06, 2023
Image decomposition plays a crucial role in various computer vision tasks, enabling the analysis and manipulation of visual content at a fundamental level. Overlapping images, which occur when multiple objects or scenes partially occlude each other, pose unique challenges for decomposition algorithms. The task intensifies when working with sparse images, where the scarcity of meaningful information complicates the precise extraction of components. This paper presents a solution that leverages the power of deep learning to accurately extract individual objects within multi-dimensional overlapping-sparse images, with a direct application in high-energy physics with decomposition of overlaid elementary particles obtained from imaging detectors. In particular, the proposed approach tackles a highly complex yet unsolved problem: identifying and measuring independent particles at the vertex of neutrino interactions, where one expects to observe detector images with multiple indiscernible overlapping charged particles. By decomposing the image of the detector activity at the vertex through deep learning, it is possible to infer the kinematic parameters of the identified low-momentum particles - which otherwise would remain neglected - and enhance the reconstructed energy resolution of the neutrino event. We also present an additional step - that can be tuned directly on detector data - combining the above method with a fully-differentiable generative model to improve the image decomposition further and, consequently, the resolution of the measured parameters, achieving unprecedented results. This improvement is crucial for precisely measuring the parameters that govern neutrino flavour oscillations and searching for asymmetries between matter and antimatter.
Into the Single Cell Multiverse: an End-to-End Dataset for Procedural Knowledge Extraction in Biomedical Texts
Sep 04, 2023
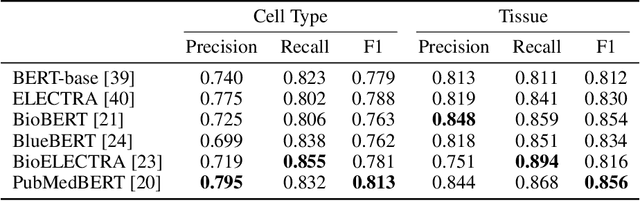

Many of the most commonly explored natural language processing (NLP) information extraction tasks can be thought of as evaluations of declarative knowledge, or fact-based information extraction. Procedural knowledge extraction, i.e., breaking down a described process into a series of steps, has received much less attention, perhaps in part due to the lack of structured datasets that capture the knowledge extraction process from end-to-end. To address this unmet need, we present FlaMB\'e (Flow annotations for Multiverse Biological entities), a collection of expert-curated datasets across a series of complementary tasks that capture procedural knowledge in biomedical texts. This dataset is inspired by the observation that one ubiquitous source of procedural knowledge that is described as unstructured text is within academic papers describing their methodology. The workflows annotated in FlaMB\'e are from texts in the burgeoning field of single cell research, a research area that has become notorious for the number of software tools and complexity of workflows used. Additionally, FlaMB\'e provides, to our knowledge, the largest manually curated named entity recognition (NER) and disambiguation (NED) datasets for tissue/cell type, a fundamental biological entity that is critical for knowledge extraction in the biomedical research domain. Beyond providing a valuable dataset to enable further development of NLP models for procedural knowledge extraction, automating the process of workflow mining also has important implications for advancing reproducibility in biomedical research.
Zero-shot Bilingual App Reviews Mining with Large Language Models
Nov 06, 2023App reviews from app stores are crucial for improving software requirements. A large number of valuable reviews are continually being posted, describing software problems and expected features. Effectively utilizing user reviews necessitates the extraction of relevant information, as well as their subsequent summarization. Due to the substantial volume of user reviews, manual analysis is arduous. Various approaches based on natural language processing (NLP) have been proposed for automatic user review mining. However, the majority of them requires a manually crafted dataset to train their models, which limits their usage in real-world scenarios. In this work, we propose Mini-BAR, a tool that integrates large language models (LLMs) to perform zero-shot mining of user reviews in both English and French. Specifically, Mini-BAR is designed to (i) classify the user reviews, (ii) cluster similar reviews together, (iii) generate an abstractive summary for each cluster and (iv) rank the user review clusters. To evaluate the performance of Mini-BAR, we created a dataset containing 6,000 English and 6,000 French annotated user reviews and conducted extensive experiments. Preliminary results demonstrate the effectiveness and efficiency of Mini-BAR in requirement engineering by analyzing bilingual app reviews. (Replication package containing the code, dataset, and experiment setups on https://github.com/Jl-wei/mini-bar )
MORTY: Structured Summarization for Targeted Information Extraction from Scholarly Articles
Dec 11, 2022Information extraction from scholarly articles is a challenging task due to the sizable document length and implicit information hidden in text, figures, and citations. Scholarly information extraction has various applications in exploration, archival, and curation services for digital libraries and knowledge management systems. We present MORTY, an information extraction technique that creates structured summaries of text from scholarly articles. Our approach condenses the article's full-text to property-value pairs as a segmented text snippet called structured summary. We also present a sizable scholarly dataset combining structured summaries retrieved from a scholarly knowledge graph and corresponding publicly available scientific articles, which we openly publish as a resource for the research community. Our results show that structured summarization is a suitable approach for targeted information extraction that complements other commonly used methods such as question answering and named entity recognition.
SE Territory: Monaural Speech Enhancement Meets the Fixed Virtual Perceptual Space Mapping
Nov 03, 2023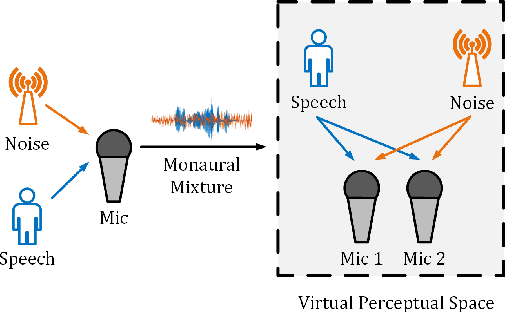
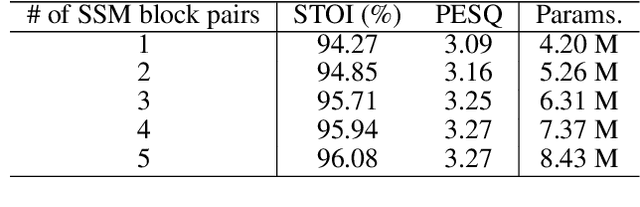
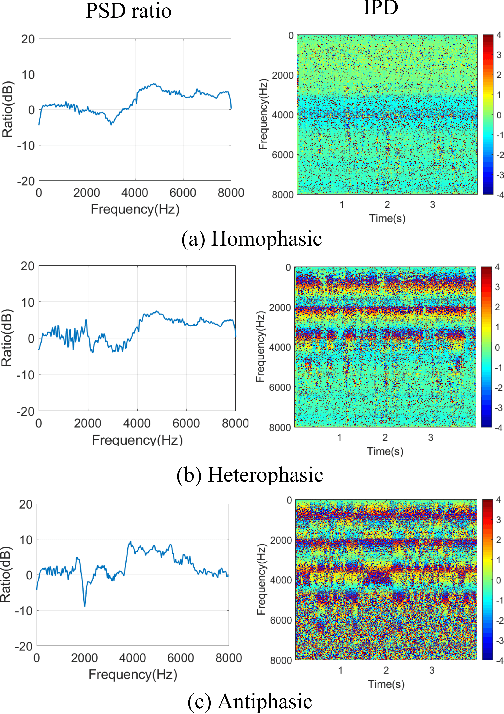

Monaural speech enhancement has achieved remarkable progress recently. However, its performance has been constrained by the limited spatial cues available at a single microphone. To overcome this limitation, we introduce a strategy to map monaural speech into a fixed simulation space for better differentiation between target speech and noise. Concretely, we propose SE-TerrNet, a novel monaural speech enhancement model featuring a virtual binaural speech mapping network via a two-stage multi-task learning framework. In the first stage, monaural noisy input is projected into a virtual space using supervised speech mapping blocks, creating binaural representations. These blocks synthesize binaural noisy speech from monaural input via an ideal binaural room impulse response. The synthesized output assigns speech and noise sources to fixed directions within the perceptual space. In the second stage, the obtained binaural features from the first stage are aggregated. This aggregation aims to decrease pattern discrepancies between the mapped binaural and original monaural features, achieved by implementing an intermediate fusion module. Furthermore, this stage incorporates the utilization of cross-attention to capture the injected virtual spatial information to improve the extraction of the target speech. Empirical studies highlight the effectiveness of virtual spatial cues in enhancing monaural speech enhancement. As a result, the proposed SE-TerrNet significantly surpasses the recent monaural speech enhancement methods in terms of both speech quality and intelligibility.
DOMINO: A Dual-System for Multi-step Visual Language Reasoning
Oct 04, 2023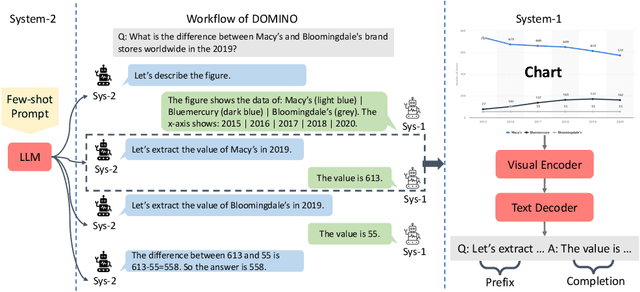
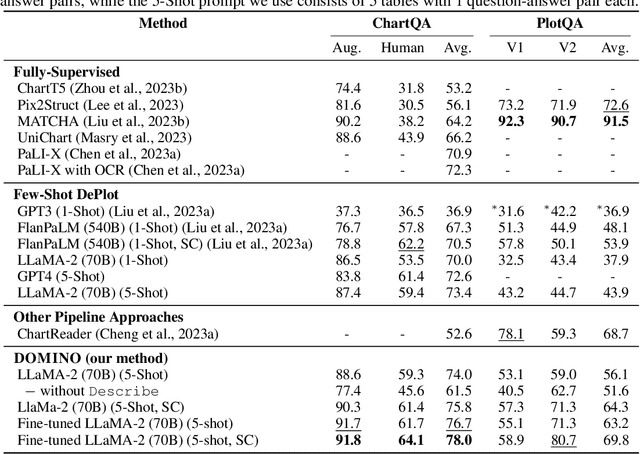
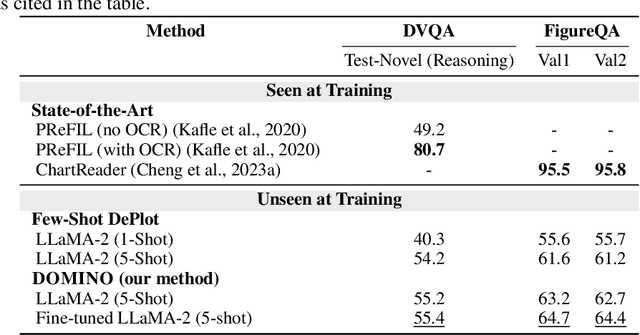
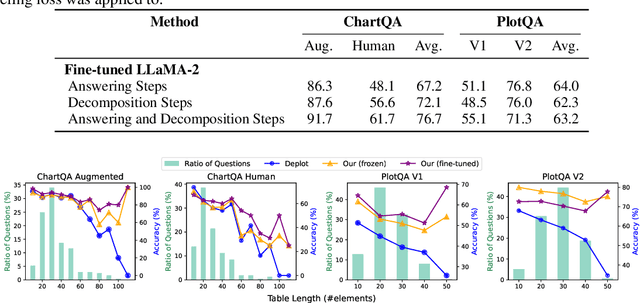
Visual language reasoning requires a system to extract text or numbers from information-dense images like charts or plots and perform logical or arithmetic reasoning to arrive at an answer. To tackle this task, existing work relies on either (1) an end-to-end vision-language model trained on a large amount of data, or (2) a two-stage pipeline where a captioning model converts the image into text that is further read by another large language model to deduce the answer. However, the former approach forces the model to answer a complex question with one single step, and the latter approach is prone to inaccurate or distracting information in the converted text that can confuse the language model. In this work, we propose a dual-system for multi-step multimodal reasoning, which consists of a "System-1" step for visual information extraction and a "System-2" step for deliberate reasoning. Given an input, System-2 breaks down the question into atomic sub-steps, each guiding System-1 to extract the information required for reasoning from the image. Experiments on chart and plot datasets show that our method with a pre-trained System-2 module performs competitively compared to prior work on in- and out-of-distribution data. By fine-tuning the System-2 module (LLaMA-2 70B) on only a small amount of data on multi-step reasoning, the accuracy of our method is further improved and surpasses the best fully-supervised end-to-end approach by 5.7% and a pipeline approach with FlanPaLM (540B) by 7.5% on a challenging dataset with human-authored questions.
A Unique Training Strategy to Enhance Language Models Capabilities for Health Mention Detection from Social Media Content
Oct 29, 2023An ever-increasing amount of social media content requires advanced AI-based computer programs capable of extracting useful information. Specifically, the extraction of health-related content from social media is useful for the development of diverse types of applications including disease spread, mortality rate prediction, and finding the impact of diverse types of drugs on diverse types of diseases. Language models are competent in extracting the syntactic and semantics of text. However, they face a hard time extracting similar patterns from social media texts. The primary reason for this shortfall lies in the non-standardized writing style commonly employed by social media users. Following the need for an optimal language model competent in extracting useful patterns from social media text, the key goal of this paper is to train language models in such a way that they learn to derive generalized patterns. The key goal is achieved through the incorporation of random weighted perturbation and contrastive learning strategies. On top of a unique training strategy, a meta predictor is proposed that reaps the benefits of 5 different language models for discriminating posts of social media text into non-health and health-related classes. Comprehensive experimentation across 3 public benchmark datasets reveals that the proposed training strategy improves the performance of the language models up to 3.87%, in terms of F1-score, as compared to their performance with traditional training. Furthermore, the proposed meta predictor outperforms existing health mention classification predictors across all 3 benchmark datasets.
RexUIE: A Recursive Method with Explicit Schema Instructor for Universal Information Extraction
Apr 28, 2023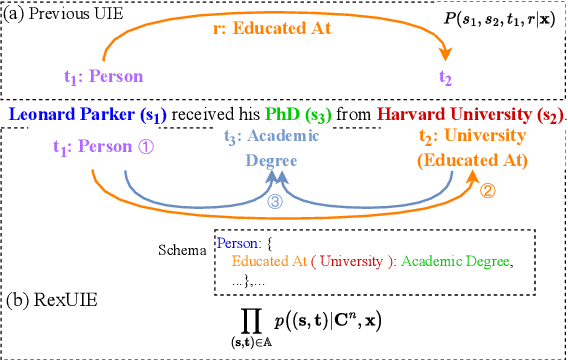
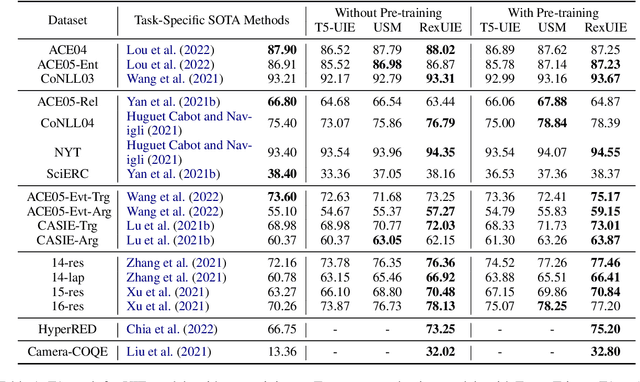
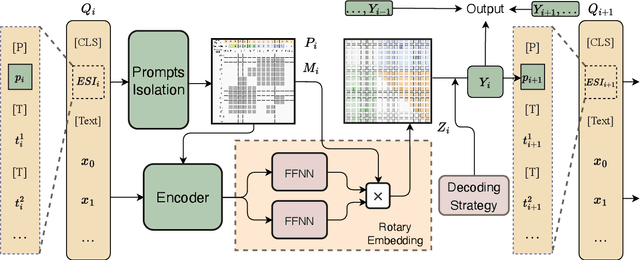
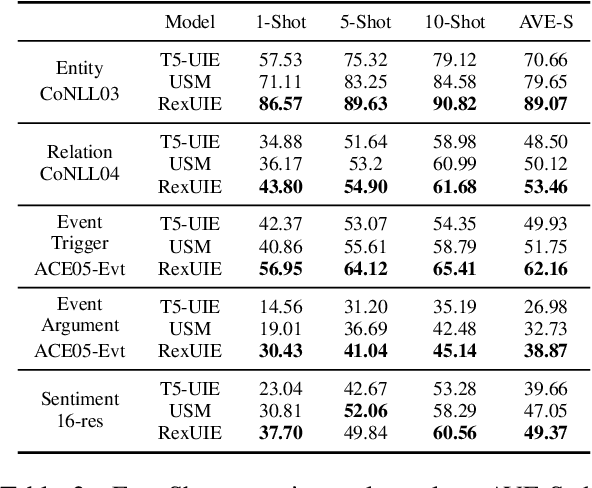
Universal Information Extraction (UIE) is an area of interest due to the challenges posed by varying targets, heterogeneous structures, and demand-specific schemas. However, previous works have only achieved limited success by unifying a few tasks, such as Named Entity Recognition (NER) and Relation Extraction (RE), which fall short of being authentic UIE models particularly when extracting other general schemas such as quadruples and quintuples. Additionally, these models used an implicit structural schema instructor, which could lead to incorrect links between types, hindering the model's generalization and performance in low-resource scenarios. In this paper, we redefine the authentic UIE with a formal formulation that encompasses almost all extraction schemas. To the best of our knowledge, we are the first to introduce UIE for any kind of schemas. In addition, we propose RexUIE, which is a Recursive Method with Explicit Schema Instructor for UIE. To avoid interference between different types, we reset the position ids and attention mask matrices. RexUIE shows strong performance under both full-shot and few-shot settings and achieves State-of-the-Art results on the tasks of extracting complex schemas.
StructChart: Perception, Structuring, Reasoning for Visual Chart Understanding
Sep 25, 2023
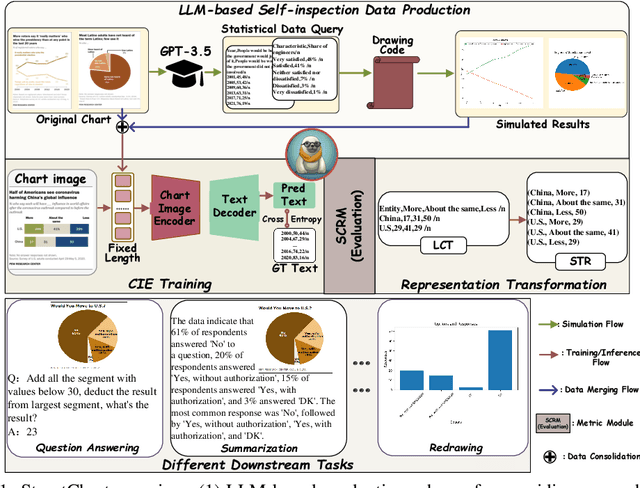
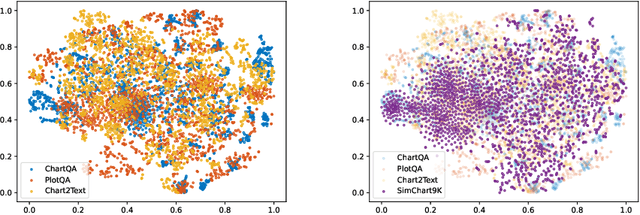
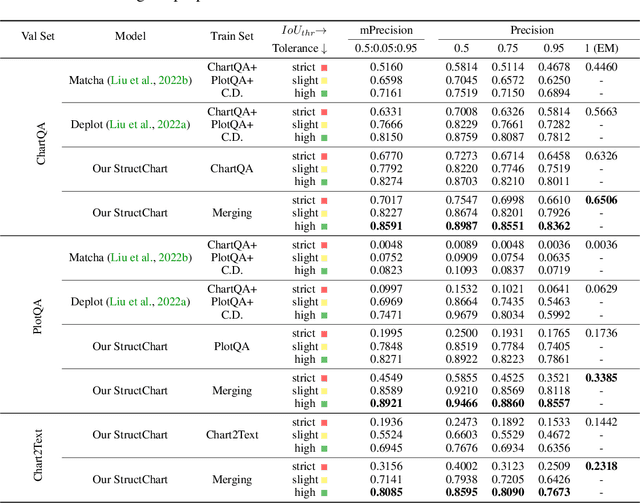
Charts are common in literature across different scientific fields, conveying rich information easily accessible to readers. Current chart-related tasks focus on either chart perception which refers to extracting information from the visual charts, or performing reasoning given the extracted data, e.g. in a tabular form. In this paper, we aim to establish a unified and label-efficient learning paradigm for joint perception and reasoning tasks, which can be generally applicable to different downstream tasks, beyond the question-answering task as specifically studied in peer works. Specifically, StructChart first reformulates the chart information from the popular tubular form (specifically linearized CSV) to the proposed Structured Triplet Representations (STR), which is more friendly for reducing the task gap between chart perception and reasoning due to the employed structured information extraction for charts. We then propose a Structuring Chart-oriented Representation Metric (SCRM) to quantitatively evaluate the performance for the chart perception task. To enrich the dataset for training, we further explore the possibility of leveraging the Large Language Model (LLM), enhancing the chart diversity in terms of both chart visual style and its statistical information. Extensive experiments are conducted on various chart-related tasks, demonstrating the effectiveness and promising potential for a unified chart perception-reasoning paradigm to push the frontier of chart understanding.
SS-MAE: Spatial-Spectral Masked Auto-Encoder for Multi-Source Remote Sensing Image Classification
Nov 08, 2023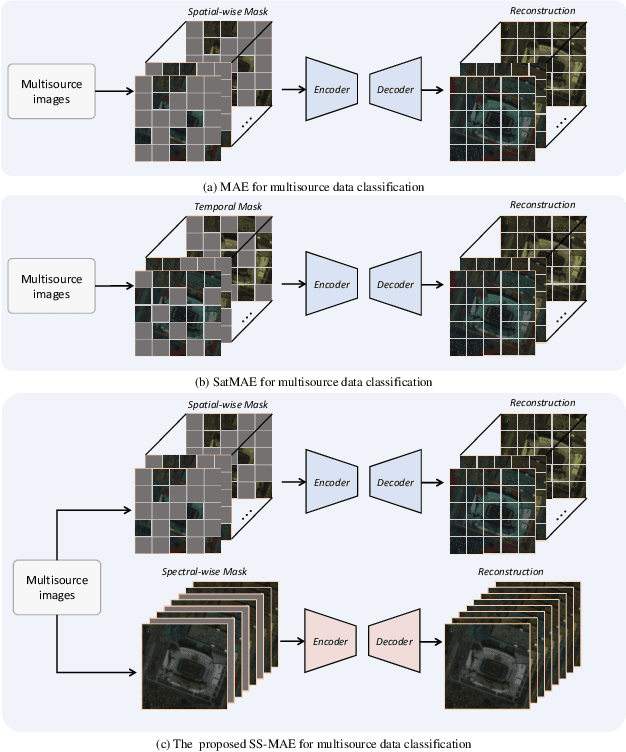

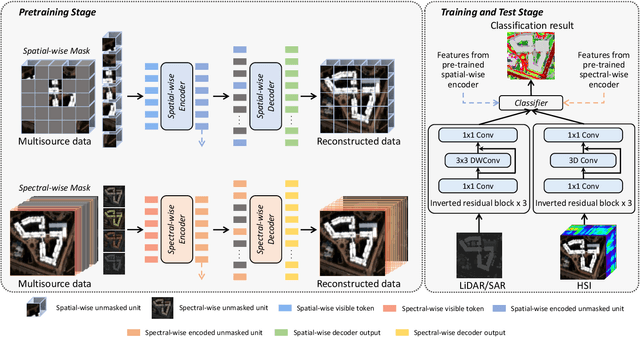
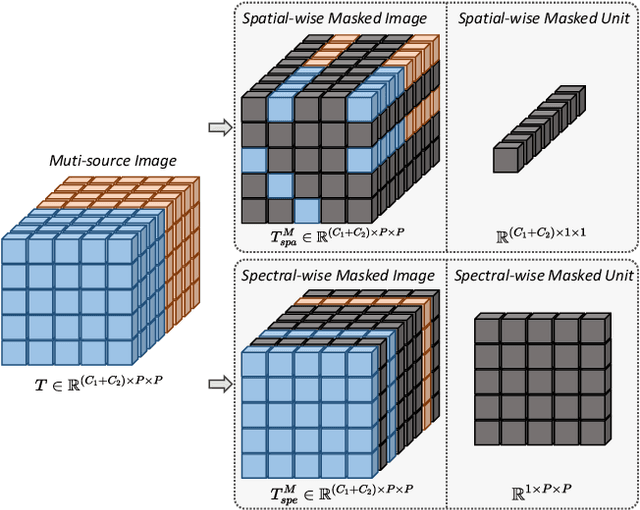
Masked image modeling (MIM) is a highly popular and effective self-supervised learning method for image understanding. Existing MIM-based methods mostly focus on spatial feature modeling, neglecting spectral feature modeling. Meanwhile, existing MIM-based methods use Transformer for feature extraction, some local or high-frequency information may get lost. To this end, we propose a spatial-spectral masked auto-encoder (SS-MAE) for HSI and LiDAR/SAR data joint classification. Specifically, SS-MAE consists of a spatial-wise branch and a spectral-wise branch. The spatial-wise branch masks random patches and reconstructs missing pixels, while the spectral-wise branch masks random spectral channels and reconstructs missing channels. Our SS-MAE fully exploits the spatial and spectral representations of the input data. Furthermore, to complement local features in the training stage, we add two lightweight CNNs for feature extraction. Both global and local features are taken into account for feature modeling. To demonstrate the effectiveness of the proposed SS-MAE, we conduct extensive experiments on three publicly available datasets. Extensive experiments on three multi-source datasets verify the superiority of our SS-MAE compared with several state-of-the-art baselines. The source codes are available at \url{https://github.com/summitgao/SS-MAE}.