 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards AI-Supported Research: a Vision of the TIB AIssistant
Dec 18, 2025

The rapid advancements in Generative AI and Large Language Models promise to transform the way research is conducted, potentially offering unprecedented opportunities to augment scholarly workflows. However, effectively integrating AI into research remains a challenge due to varying domain requirements, limited AI literacy, the complexity of coordinating tools and agents, and the unclear accuracy of Generative AI in research. We present the vision of the TIB AIssistant, a domain-agnostic human-machine collaborative platform designed to support researchers across disciplines in scientific discovery, with AI assistants supporting tasks across the research life cycle. The platform offers modular components - including prompt and tool libraries, a shared data store, and a flexible orchestration framework - that collectively facilitate ideation, literature analysis, methodology development, data analysis, and scholarly writing. We describe the conceptual framework, system architecture, and implementation of an early prototype that demonstrates the feasibility and potential impact of our approach.
Introducing ORKG ASK: an AI-driven Scholarly Literature Search and Exploration System Taking a Neuro-Symbolic Approach
Dec 18, 2025As the volume of published scholarly literature continues to grow, finding relevant literature becomes increasingly difficult. With the rise of generative Artificial Intelligence (AI), and particularly Large Language Models (LLMs), new possibilities emerge to find and explore literature. We introduce ASK (Assistant for Scientific Knowledge), an AI-driven scholarly literature search and exploration system that follows a neuro-symbolic approach. ASK aims to provide active support to researchers in finding relevant scholarly literature by leveraging vector search, LLMs, and knowledge graphs. The system allows users to input research questions in natural language and retrieve relevant articles. ASK automatically extracts key information and generates answers to research questions using a Retrieval-Augmented Generation (RAG) approach. We present an evaluation of ASK, assessing the system's usability and usefulness. Findings indicate that the system is user-friendly and users are generally satisfied while using the system.
MORTY: Structured Summarization for Targeted Information Extraction from Scholarly Articles
Dec 11, 2022Information extraction from scholarly articles is a challenging task due to the sizable document length and implicit information hidden in text, figures, and citations. Scholarly information extraction has various applications in exploration, archival, and curation services for digital libraries and knowledge management systems. We present MORTY, an information extraction technique that creates structured summaries of text from scholarly articles. Our approach condenses the article's full-text to property-value pairs as a segmented text snippet called structured summary. We also present a sizable scholarly dataset combining structured summaries retrieved from a scholarly knowledge graph and corresponding publicly available scientific articles, which we openly publish as a resource for the research community. Our results show that structured summarization is a suitable approach for targeted information extraction that complements other commonly used methods such as question answering and named entity recognition.
Plumber: A Modular Framework to Create Information Extraction Pipelines
Jun 03, 2022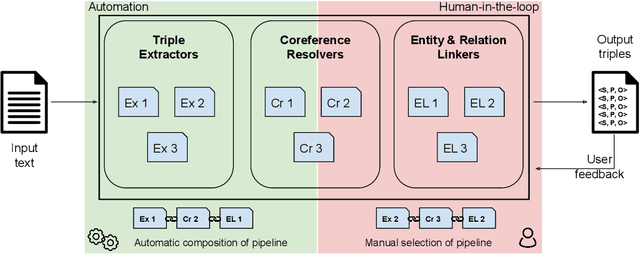
Information Extraction (IE) tasks are commonly studied topics in various domains of research. Hence, the community continuously produces multiple techniques, solutions, and tools to perform such tasks. However, running those tools and integrating them within existing infrastructure requires time, expertise, and resources. One pertinent task here is triples extraction and linking, where structured triples are extracted from a text and aligned to an existing Knowledge Graph (KG). In this paper, we present PLUMBER, the first framework that allows users to manually and automatically create suitable IE pipelines from a community-created pool of tools to perform triple extraction and alignment on unstructured text. Our approach provides an interactive medium to alter the pipelines and perform IE tasks. A short video to show the working of the framework for different use-cases is available online under: https://www.youtube.com/watch?v=XC9rJNIUv8g
Triple Classification for Scholarly Knowledge Graph Completion
Nov 23, 2021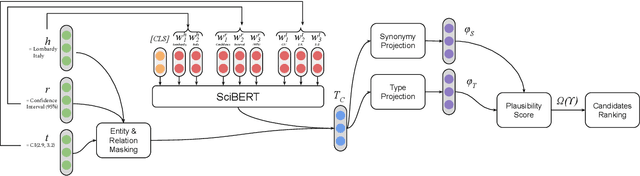

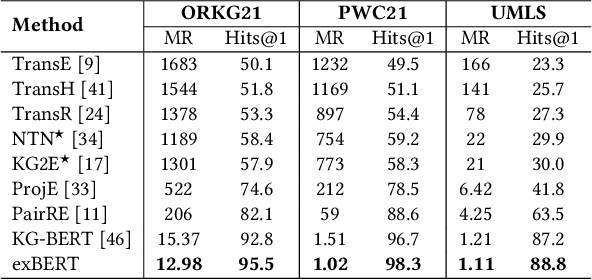
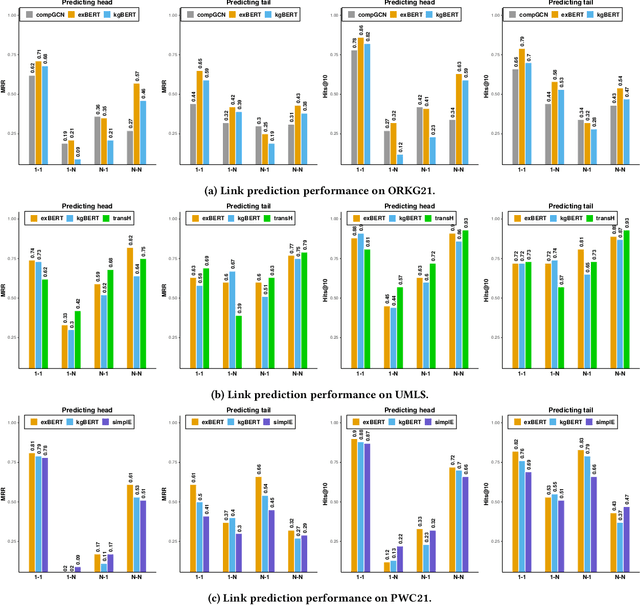
Scholarly Knowledge Graphs (KGs) provide a rich source of structured information representing knowledge encoded in scientific publications. With the sheer volume of published scientific literature comprising a plethora of inhomogeneous entities and relations to describe scientific concepts, these KGs are inherently incomplete. We present exBERT, a method for leveraging pre-trained transformer language models to perform scholarly knowledge graph completion. We model triples of a knowledge graph as text and perform triple classification (i.e., belongs to KG or not). The evaluation shows that exBERT outperforms other baselines on three scholarly KG completion datasets in the tasks of triple classification, link prediction, and relation prediction. Furthermore, we present two scholarly datasets as resources for the research community, collected from public KGs and online resources.
Better Call the Plumber: Orchestrating Dynamic Information Extraction Pipelines
Feb 22, 2021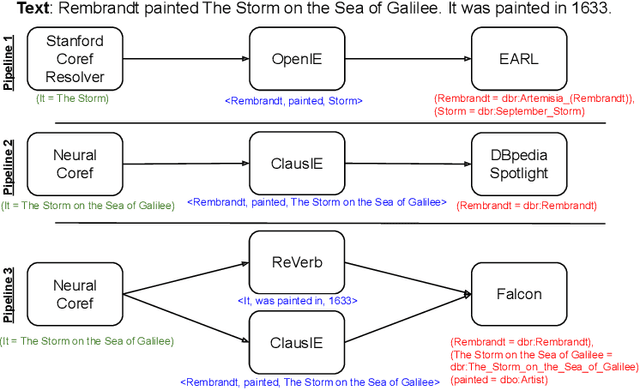
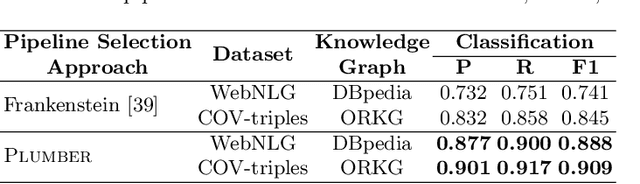
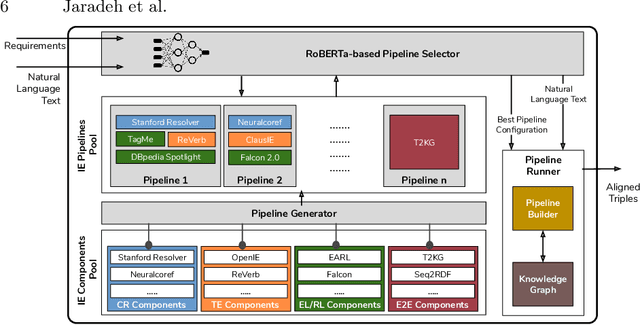
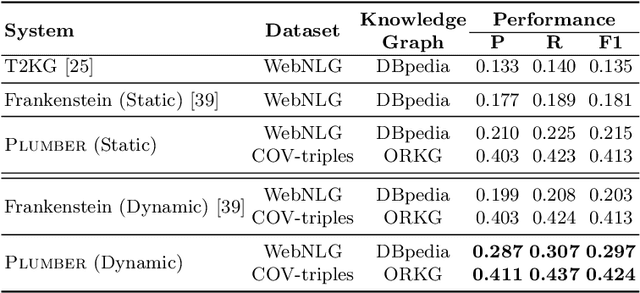
In the last decade, a large number of Knowledge Graph (KG) information extraction approaches were proposed. Albeit effective, these efforts are disjoint, and their collective strengths and weaknesses in effective KG information extraction (IE) have not been studied in the literature. We propose Plumber, the first framework that brings together the research community's disjoint IE efforts. The Plumber architecture comprises 33 reusable components for various KG information extraction subtasks, such as coreference resolution, entity linking, and relation extraction. Using these components,Plumber dynamically generates suitable information extraction pipelines and offers overall 264 distinct pipelines.We study the optimization problem of choosing suitable pipelines based on input sentences. To do so, we train a transformer-based classification model that extracts contextual embeddings from the input and finds an appropriate pipeline. We study the efficacy of Plumber for extracting the KG triples using standard datasets over two KGs: DBpedia, and Open Research Knowledge Graph (ORKG). Our results demonstrate the effectiveness of Plumber in dynamically generating KG information extraction pipelines,outperforming all baselines agnostics of the underlying KG. Furthermore,we provide an analysis of collective failure cases, study the similarities and synergies among integrated components, and discuss their limitations.
Knowledge Graphs Evolution and Preservation -- A Technical Report from ISWS 2019
Dec 22, 2020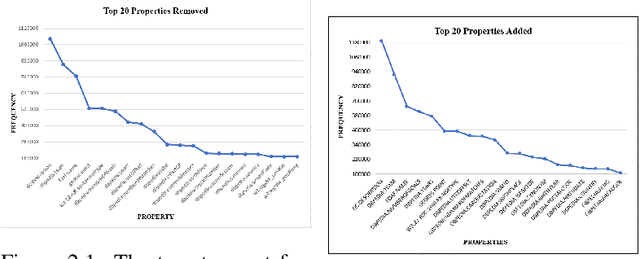
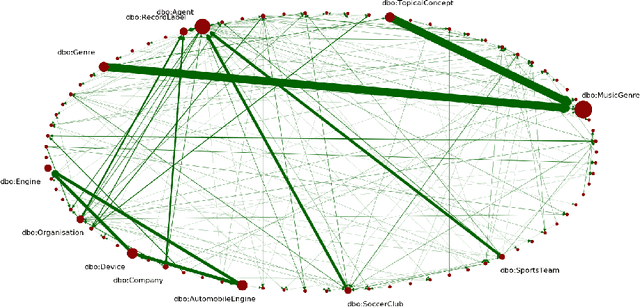

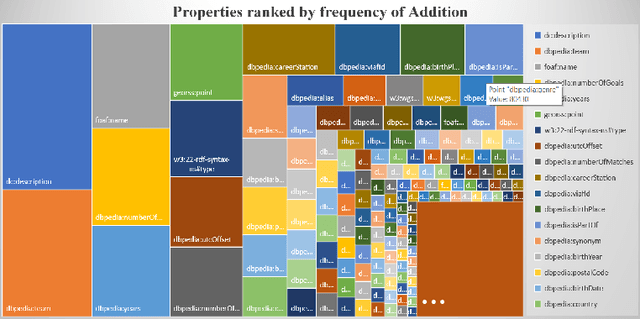
One of the grand challenges discussed during the Dagstuhl Seminar "Knowledge Graphs: New Directions for Knowledge Representation on the Semantic Web" and described in its report is that of a: "Public FAIR Knowledge Graph of Everything: We increasingly see the creation of knowledge graphs that capture information about the entirety of a class of entities. [...] This grand challenge extends this further by asking if we can create a knowledge graph of "everything" ranging from common sense concepts to location based entities. This knowledge graph should be "open to the public" in a FAIR manner democratizing this mass amount of knowledge." Although linked open data (LOD) is one knowledge graph, it is the closest realisation (and probably the only one) to a public FAIR Knowledge Graph (KG) of everything. Surely, LOD provides a unique testbed for experimenting and evaluating research hypotheses on open and FAIR KG. One of the most neglected FAIR issues about KGs is their ongoing evolution and long term preservation. We want to investigate this problem, that is to understand what preserving and supporting the evolution of KGs means and how these problems can be addressed. Clearly, the problem can be approached from different perspectives and may require the development of different approaches, including new theories, ontologies, metrics, strategies, procedures, etc. This document reports a collaborative effort performed by 9 teams of students, each guided by a senior researcher as their mentor, attending the International Semantic Web Research School (ISWS 2019). Each team provides a different perspective to the problem of knowledge graph evolution substantiated by a set of research questions as the main subject of their investigation. In addition, they provide their working definition for KG preservation and evolution.
Challenges of Linking Organizational Information in Open Government Data to Knowledge Graphs
Aug 14, 2020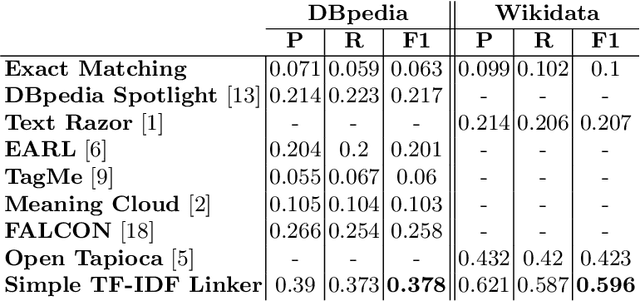
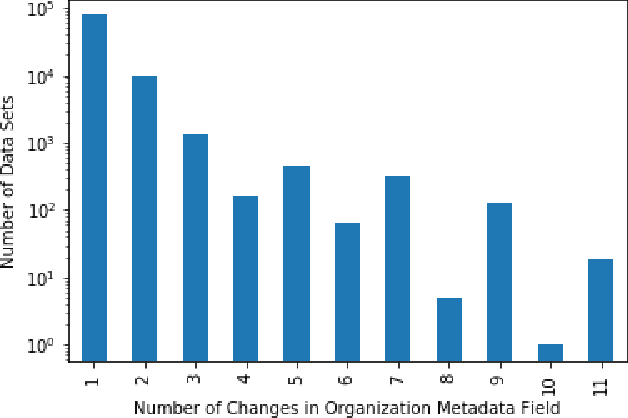
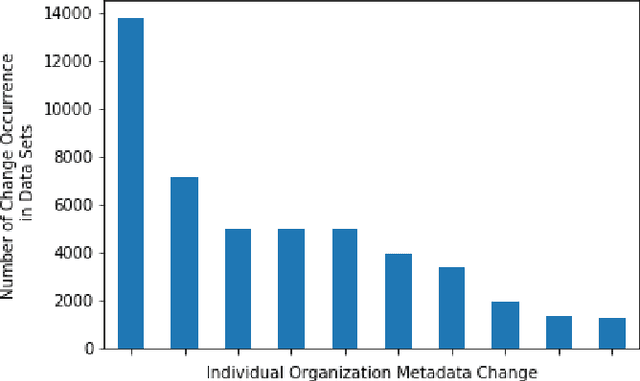
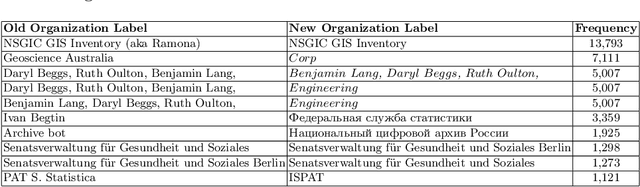
Open Government Data (OGD) is being published by various public administration organizations around the globe. Within the metadata of OGD data catalogs, the publishing organizations (1) are not uniquely and unambiguously identifiable and, even worse, (2) change over time, by public administration units being merged or restructured. In order to enable fine-grained analyses or searches on Open Government Data on the level of publishing organizations, linking those from OGD portals to publicly available knowledge graphs (KGs) such as Wikidata and DBpedia seems like an obvious solution. Still, as we show in this position paper, organization linking faces significant challenges, both in terms of available (portal) metadata and KGs in terms of data quality and completeness. We herein specifically highlight five main challenges, namely regarding (1) temporal changes in organizations and in the portal metadata, (2) lack of a base ontology for describing organizational structures and changes in public knowledge graphs, (3) metadata and KG data quality, (4) multilinguality, and (5) disambiguating public sector organizations. Based on available OGD portal metadata from the Open Data Portal Watch, we provide an in-depth analysis of these issues, make suggestions for concrete starting points on how to tackle them along with a call to the community to jointly work on these open challenges.
Question Answering on Scholarly Knowledge Graphs
Jun 02, 2020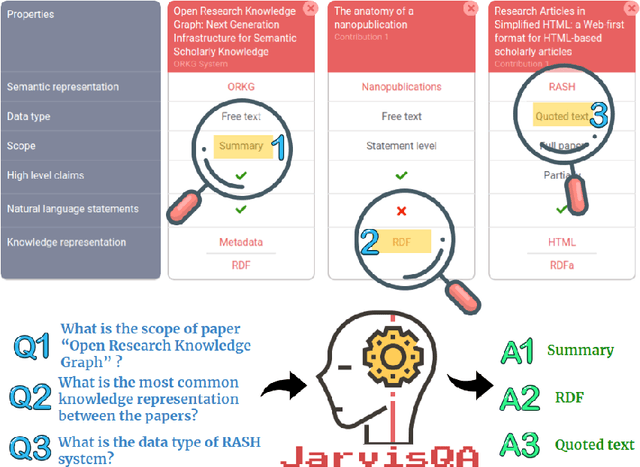
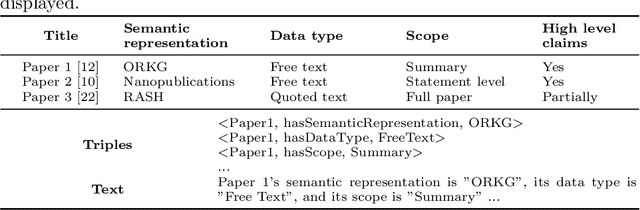
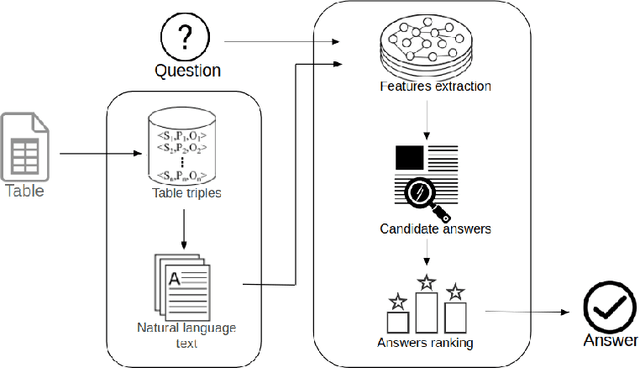

Answering questions on scholarly knowledge comprising text and other artifacts is a vital part of any research life cycle. Querying scholarly knowledge and retrieving suitable answers is currently hardly possible due to the following primary reason: machine inactionable, ambiguous and unstructured content in publications. We present JarvisQA, a BERT based system to answer questions on tabular views of scholarly knowledge graphs. Such tables can be found in a variety of shapes in the scholarly literature (e.g., surveys, comparisons or results). Our system can retrieve direct answers to a variety of different questions asked on tabular data in articles. Furthermore, we present a preliminary dataset of related tables and a corresponding set of natural language questions. This dataset is used as a benchmark for our system and can be reused by others. Additionally, JarvisQA is evaluated on two datasets against other baselines and shows an improvement of two to three folds in performance compared to related methods.
The STEM-ECR Dataset: Grounding Scientific Entity References in STEM Scholarly Content to Authoritative Encyclopedic and Lexicographic Sources
Mar 06, 2020



We introduce the STEM (Science, Technology, Engineering, and Medicine) Dataset for Scientific Entity Extraction, Classification, and Resolution, version 1.0 (STEM-ECR v1.0). The STEM-ECR v1.0 dataset has been developed to provide a benchmark for the evaluation of scientific entity extraction, classification, and resolution tasks in a domain-independent fashion. It comprises abstracts in 10 STEM disciplines that were found to be the most prolific ones on a major publishing platform. We describe the creation of such a multidisciplinary corpus and highlight the obtained findings in terms of the following features: 1) a generic conceptual formalism for scientific entities in a multidisciplinary scientific context; 2) the feasibility of the domain-independent human annotation of scientific entities under such a generic formalism; 3) a performance benchmark obtainable for automatic extraction of multidisciplinary scientific entities using BERT-based neural models; 4) a delineated 3-step entity resolution procedure for human annotation of the scientific entities via encyclopedic entity linking and lexicographic word sense disambiguation; and 5) human evaluations of Babelfy returned encyclopedic links and lexicographic senses for our entities. Our findings cumulatively indicate that human annotation and automatic learning of multidisciplinary scientific concepts as well as their semantic disambiguation in a wide-ranging setting as STEM is reasonable.