 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
AGFSync: Leveraging AI-Generated Feedback for Preference Optimization in Text-to-Image Generation
Mar 24, 2024

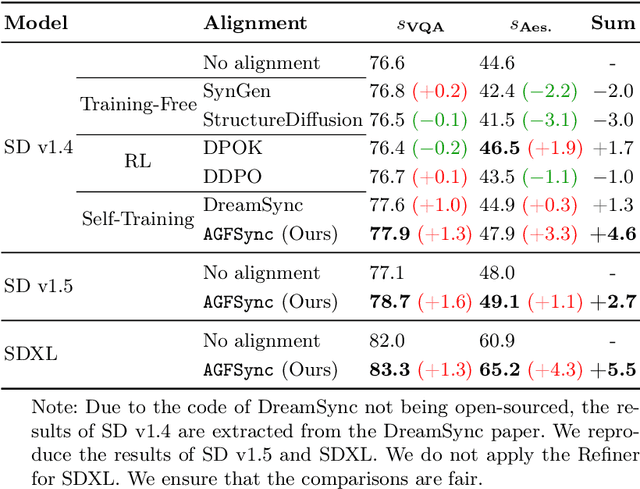
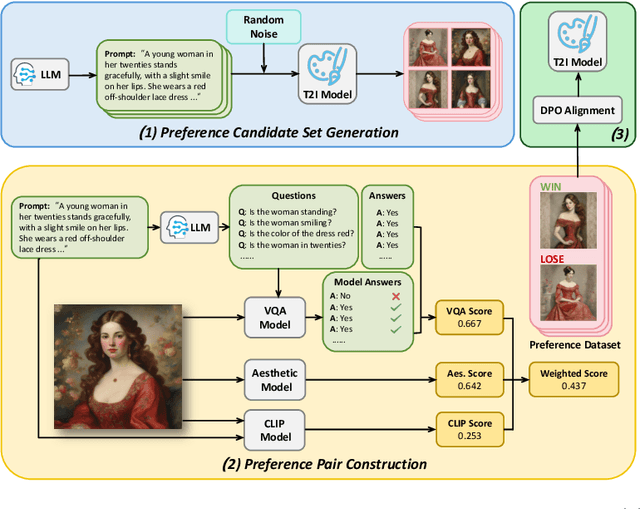
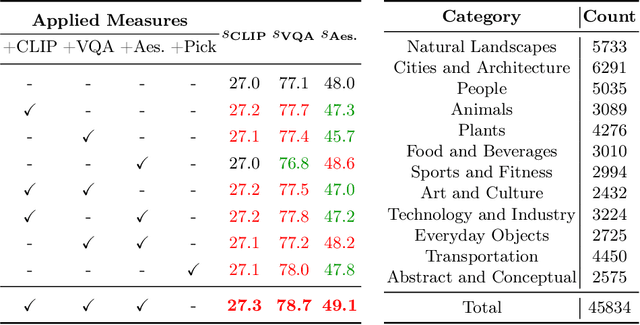
Text-to-Image (T2I) diffusion models have achieved remarkable success in image generation. Despite their progress, challenges remain in both prompt-following ability, image quality and lack of high-quality datasets, which are essential for refining these models. As acquiring labeled data is costly, we introduce AGFSync, a framework that enhances T2I diffusion models through Direct Preference Optimization (DPO) in a fully AI-driven approach. AGFSync utilizes Vision-Language Models (VLM) to assess image quality across style, coherence, and aesthetics, generating feedback data within an AI-driven loop. By applying AGFSync to leading T2I models such as SD v1.4, v1.5, and SDXL, our extensive experiments on the TIFA dataset demonstrate notable improvements in VQA scores, aesthetic evaluations, and performance on the HPSv2 benchmark, consistently outperforming the base models. AGFSync's method of refining T2I diffusion models paves the way for scalable alignment techniques.
OpenNeRF: Open Set 3D Neural Scene Segmentation with Pixel-Wise Features and Rendered Novel Views
Apr 04, 2024Large visual-language models (VLMs), like CLIP, enable open-set image segmentation to segment arbitrary concepts from an image in a zero-shot manner. This goes beyond the traditional closed-set assumption, i.e., where models can only segment classes from a pre-defined training set. More recently, first works on open-set segmentation in 3D scenes have appeared in the literature. These methods are heavily influenced by closed-set 3D convolutional approaches that process point clouds or polygon meshes. However, these 3D scene representations do not align well with the image-based nature of the visual-language models. Indeed, point cloud and 3D meshes typically have a lower resolution than images and the reconstructed 3D scene geometry might not project well to the underlying 2D image sequences used to compute pixel-aligned CLIP features. To address these challenges, we propose OpenNeRF which naturally operates on posed images and directly encodes the VLM features within the NeRF. This is similar in spirit to LERF, however our work shows that using pixel-wise VLM features (instead of global CLIP features) results in an overall less complex architecture without the need for additional DINO regularization. Our OpenNeRF further leverages NeRF's ability to render novel views and extract open-set VLM features from areas that are not well observed in the initial posed images. For 3D point cloud segmentation on the Replica dataset, OpenNeRF outperforms recent open-vocabulary methods such as LERF and OpenScene by at least +4.9 mIoU.
* ICLR 2024, Project page: https://opennerf.github.io
A Study in Dataset Pruning for Image Super-Resolution
Mar 25, 2024In image Super-Resolution (SR), relying on large datasets for training is a double-edged sword. While offering rich training material, they also demand substantial computational and storage resources. In this work, we analyze dataset pruning as a solution to these challenges. We introduce a novel approach that reduces a dataset to a core-set of training samples, selected based on their loss values as determined by a simple pre-trained SR model. By focusing the training on just 50% of the original dataset, specifically on the samples characterized by the highest loss values, we achieve results comparable to or even surpassing those obtained from training on the entire dataset. Interestingly, our analysis reveals that the top 5% of samples with the highest loss values negatively affect the training process. Excluding these samples and adjusting the selection to favor easier samples further enhances training outcomes. Our work opens new perspectives to the untapped potential of dataset pruning in image SR. It suggests that careful selection of training data based on loss-value metrics can lead to better SR models, challenging the conventional wisdom that more data inevitably leads to better performance.
Learning Topology Uniformed Face Mesh by Volume Rendering for Multi-view Reconstruction
Apr 08, 2024Face meshes in consistent topology serve as the foundation for many face-related applications, such as 3DMM constrained face reconstruction and expression retargeting. Traditional methods commonly acquire topology uniformed face meshes by two separate steps: multi-view stereo (MVS) to reconstruct shapes followed by non-rigid registration to align topology, but struggles with handling noise and non-lambertian surfaces. Recently neural volume rendering techniques have been rapidly evolved and shown great advantages in 3D reconstruction or novel view synthesis. Our goal is to leverage the superiority of neural volume rendering into multi-view reconstruction of face mesh with consistent topology. We propose a mesh volume rendering method that enables directly optimizing mesh geometry while preserving topology, and learning implicit features to model complex facial appearance from multi-view images. The key innovation lies in spreading sparse mesh features into the surrounding space to simulate radiance field required for volume rendering, which facilitates backpropagation of gradients from images to mesh geometry and implicit appearance features. Our proposed feature spreading module exhibits deformation invariance, enabling photorealistic rendering seamlessly after mesh editing. We conduct experiments on multi-view face image dataset to evaluate the reconstruction and implement an application for photorealistic rendering of animated face mesh.
Certified PEFTSmoothing: Parameter-Efficient Fine-Tuning with Randomized Smoothing
Apr 08, 2024Randomized smoothing is the primary certified robustness method for accessing the robustness of deep learning models to adversarial perturbations in the l2-norm, by adding isotropic Gaussian noise to the input image and returning the majority votes over the base classifier. Theoretically, it provides a certified norm bound, ensuring predictions of adversarial examples are stable within this bound. A notable constraint limiting widespread adoption is the necessity to retrain base models entirely from scratch to attain a robust version. This is because the base model fails to learn the noise-augmented data distribution to give an accurate vote. One intuitive way to overcome this challenge is to involve a custom-trained denoiser to eliminate the noise. However, this approach is inefficient and sub-optimal. Inspired by recent large model training procedures, we explore an alternative way named PEFTSmoothing to adapt the base model to learn the Gaussian noise-augmented data with Parameter-Efficient Fine-Tuning (PEFT) methods in both white-box and black-box settings. Extensive results demonstrate the effectiveness and efficiency of PEFTSmoothing, which allow us to certify over 98% accuracy for ViT on CIFAR-10, 20% higher than SoTA denoised smoothing, and over 61% accuracy on ImageNet which is 30% higher than CNN-based denoiser and comparable to the Diffusion-based denoiser.
Towards More General Video-based Deepfake Detection through Facial Feature Guided Adaptation for Foundation Model
Apr 08, 2024With the rise of deep learning, generative models have enabled the creation of highly realistic synthetic images, presenting challenges due to their potential misuse. While research in Deepfake detection has grown rapidly in response, many detection methods struggle with unseen Deepfakes generated by new synthesis techniques. To address this generalisation challenge, we propose a novel Deepfake detection approach by adapting rich information encoded inside the Foundation Models with rich information encoded inside, specifically using the image encoder from CLIP which has demonstrated strong zero-shot capability for downstream tasks. Inspired by the recent advances of parameter efficient fine-tuning, we propose a novel side-network-based decoder to extract spatial and temporal cues from the given video clip, with the promotion of the Facial Component Guidance (FCG) to guidencourage the spatial feature to include features of key facial parts for more robust and general Deepfake detection. Through extensive cross-dataset evaluations, our approach exhibits superior effectiveness in identifying unseen Deepfake samples, achieving notable performance improvementsuccess even with limited training samples and manipulation types. Our model secures an average performance enhancement of 0.9% AUROC in cross-dataset assessments comparing with state-of-the-art methods, especiallytablishing a significant lead of achieving 4.4% improvement on the challenging DFDC dataset.
DreamWalk: Style Space Exploration using Diffusion Guidance
Apr 04, 2024Text-conditioned diffusion models can generate impressive images, but fall short when it comes to fine-grained control. Unlike direct-editing tools like Photoshop, text conditioned models require the artist to perform "prompt engineering," constructing special text sentences to control the style or amount of a particular subject present in the output image. Our goal is to provide fine-grained control over the style and substance specified by the prompt, for example to adjust the intensity of styles in different regions of the image (Figure 1). Our approach is to decompose the text prompt into conceptual elements, and apply a separate guidance term for each element in a single diffusion process. We introduce guidance scale functions to control when in the diffusion process and \emph{where} in the image to intervene. Since the method is based solely on adjusting diffusion guidance, it does not require fine-tuning or manipulating the internal layers of the diffusion model's neural network, and can be used in conjunction with LoRA- or DreamBooth-trained models (Figure2). Project page: https://mshu1.github.io/dreamwalk.github.io/
Guarantees of confidentiality via Hammersley-Chapman-Robbins bounds
Apr 06, 2024Protecting privacy during inference with deep neural networks is possible by adding noise to the activations in the last layers prior to the final classifiers or other task-specific layers. The activations in such layers are known as "features" (or, less commonly, as "embeddings" or "feature embeddings"). The added noise helps prevent reconstruction of the inputs from the noisy features. Lower bounding the variance of every possible unbiased estimator of the inputs quantifies the confidentiality arising from such added noise. Convenient, computationally tractable bounds are available from classic inequalities of Hammersley and of Chapman and Robbins -- the HCR bounds. Numerical experiments indicate that the HCR bounds are on the precipice of being effectual for small neural nets with the data sets, "MNIST" and "CIFAR-10," which contain 10 classes each for image classification. The HCR bounds appear to be insufficient on their own to guarantee confidentiality of the inputs to inference with standard deep neural nets, "ResNet-18" and "Swin-T," pre-trained on the data set, "ImageNet-1000," which contains 1000 classes. Supplementing the addition of noise to features with other methods for providing confidentiality may be warranted in the case of ImageNet. In all cases, the results reported here limit consideration to amounts of added noise that incur little degradation in the accuracy of classification from the noisy features. Thus, the added noise enhances confidentiality without much reduction in the accuracy on the task of image classification.
Homogeneous Tokenizer Matters: Homogeneous Visual Tokenizer for Remote Sensing Image Understanding
Mar 27, 2024The tokenizer, as one of the fundamental components of large models, has long been overlooked or even misunderstood in visual tasks. One key factor of the great comprehension power of the large language model is that natural language tokenizers utilize meaningful words or subwords as the basic elements of language. In contrast, mainstream visual tokenizers, represented by patch-based methods such as Patch Embed, rely on meaningless rectangular patches as basic elements of vision, which cannot serve as effectively as words or subwords in language. Starting from the essence of the tokenizer, we defined semantically independent regions (SIRs) for vision. We designed a simple HOmogeneous visual tOKenizer: HOOK. HOOK mainly consists of two modules: the Object Perception Module (OPM) and the Object Vectorization Module (OVM). To achieve homogeneity, the OPM splits the image into 4*4 pixel seeds and then utilizes the attention mechanism to perceive SIRs. The OVM employs cross-attention to merge seeds within the same SIR. To achieve adaptability, the OVM defines a variable number of learnable vectors as cross-attention queries, allowing for the adjustment of token quantity. We conducted experiments on the NWPU-RESISC45, WHU-RS19 classification dataset, and GID5 segmentation dataset for sparse and dense tasks. The results demonstrate that the visual tokens obtained by HOOK correspond to individual objects, which demonstrates homogeneity. HOOK outperformed Patch Embed by 6\% and 10\% in the two tasks and achieved state-of-the-art performance compared to the baselines used for comparison. Compared to Patch Embed, which requires more than one hundred tokens for one image, HOOK requires only 6 and 8 tokens for sparse and dense tasks, respectively, resulting in efficiency improvements of 1.5 to 2.8 times. The code is available at https://github.com/GeoX-Lab/Hook.
FACTUAL: A Novel Framework for Contrastive Learning Based Robust SAR Image Classification
Apr 04, 2024Deep Learning (DL) Models for Synthetic Aperture Radar (SAR) Automatic Target Recognition (ATR), while delivering improved performance, have been shown to be quite vulnerable to adversarial attacks. Existing works improve robustness by training models on adversarial samples. However, by focusing mostly on attacks that manipulate images randomly, they neglect the real-world feasibility of such attacks. In this paper, we propose FACTUAL, a novel Contrastive Learning framework for Adversarial Training and robust SAR classification. FACTUAL consists of two components: (1) Differing from existing works, a novel perturbation scheme that incorporates realistic physical adversarial attacks (such as OTSA) to build a supervised adversarial pre-training network. This network utilizes class labels for clustering clean and perturbed images together into a more informative feature space. (2) A linear classifier cascaded after the encoder to use the computed representations to predict the target labels. By pre-training and fine-tuning our model on both clean and adversarial samples, we show that our model achieves high prediction accuracy on both cases. Our model achieves 99.7% accuracy on clean samples, and 89.6% on perturbed samples, both outperforming previous state-of-the-art methods.