 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGOT-JEPA: Generic Object Tracking with Model Adaptation and Occlusion Handling using Joint-Embedding Predictive Architecture
Feb 16, 2026The human visual system tracks objects by integrating current observations with previously observed information, adapting to target and scene changes, and reasoning about occlusion at fine granularity. In contrast, recent generic object trackers are often optimized for training targets, which limits robustness and generalization in unseen scenarios, and their occlusion reasoning remains coarse, lacking detailed modeling of occlusion patterns. To address these limitations in generalization and occlusion perception, we propose GOT-JEPA, a model-predictive pretraining framework that extends JEPA from predicting image features to predicting tracking models. Given identical historical information, a teacher predictor generates pseudo-tracking models from a clean current frame, and a student predictor learns to predict the same pseudo-tracking models from a corrupted version of the current frame. This design provides stable pseudo supervision and explicitly trains the predictor to produce reliable tracking models under occlusions, distractors, and other adverse observations, improving generalization to dynamic environments. Building on GOT-JEPA, we further propose OccuSolver to enhance occlusion perception for object tracking. OccuSolver adapts a point-centric point tracker for object-aware visibility estimation and detailed occlusion-pattern capture. Conditioned on object priors iteratively generated by the tracker, OccuSolver incrementally refines visibility states, strengthens occlusion handling, and produces higher-quality reference labels that progressively improve subsequent model predictions. Extensive evaluations on seven benchmarks show that our method effectively enhances tracker generalization and robustness.
GOT-Edit: Geometry-Aware Generic Object Tracking via Online Model Editing
Feb 09, 2026Human perception for effective object tracking in a 2D video stream arises from the implicit use of prior 3D knowledge combined with semantic reasoning. In contrast, most generic object tracking (GOT) methods primarily rely on 2D features of the target and its surroundings while neglecting 3D geometric cues, which makes them susceptible to partial occlusion, distractors, and variations in geometry and appearance. To address this limitation, we introduce GOT-Edit, an online cross-modality model editing approach that integrates geometry-aware cues into a generic object tracker from a 2D video stream. Our approach leverages features from a pre-trained Visual Geometry Grounded Transformer to enable geometric cue inference from only a few 2D images. To tackle the challenge of seamlessly combining geometry and semantics, GOT-Edit performs online model editing with null-space constrained updates that incorporate geometric information while preserving semantic discrimination, yielding consistently better performance across diverse scenarios. Extensive experiments on multiple GOT benchmarks demonstrate that GOT-Edit achieves superior robustness and accuracy, particularly under occlusion and clutter, establishing a new paradigm for combining 2D semantics with 3D geometric reasoning for generic object tracking.
M-ErasureBench: A Comprehensive Multimodal Evaluation Benchmark for Concept Erasure in Diffusion Models
Dec 28, 2025Text-to-image diffusion models may generate harmful or copyrighted content, motivating research on concept erasure. However, existing approaches primarily focus on erasing concepts from text prompts, overlooking other input modalities that are increasingly critical in real-world applications such as image editing and personalized generation. These modalities can become attack surfaces, where erased concepts re-emerge despite defenses. To bridge this gap, we introduce M-ErasureBench, a novel multimodal evaluation framework that systematically benchmarks concept erasure methods across three input modalities: text prompts, learned embeddings, and inverted latents. For the latter two, we evaluate both white-box and black-box access, yielding five evaluation scenarios. Our analysis shows that existing methods achieve strong erasure performance against text prompts but largely fail under learned embeddings and inverted latents, with Concept Reproduction Rate (CRR) exceeding 90% in the white-box setting. To address these vulnerabilities, we propose IRECE (Inference-time Robustness Enhancement for Concept Erasure), a plug-and-play module that localizes target concepts via cross-attention and perturbs the associated latents during denoising. Experiments demonstrate that IRECE consistently restores robustness, reducing CRR by up to 40% under the most challenging white-box latent inversion scenario, while preserving visual quality. To the best of our knowledge, M-ErasureBench provides the first comprehensive benchmark of concept erasure beyond text prompts. Together with IRECE, our benchmark offers practical safeguards for building more reliable protective generative models.
Invisible Backdoor Triggers in Image Editing Model via Deep Watermarking
Jun 05, 2025



Diffusion models have achieved remarkable progress in both image generation and editing. However, recent studies have revealed their vulnerability to backdoor attacks, in which specific patterns embedded in the input can manipulate the model's behavior. Most existing research in this area has proposed attack frameworks focused on the image generation pipeline, leaving backdoor attacks in image editing relatively unexplored. Among the few studies targeting image editing, most utilize visible triggers, which are impractical because they introduce noticeable alterations to the input image before editing. In this paper, we propose a novel attack framework that embeds invisible triggers into the image editing process via poisoned training data. We leverage off-the-shelf deep watermarking models to encode imperceptible watermarks as backdoor triggers. Our goal is to make the model produce the predefined backdoor target when it receives watermarked inputs, while editing clean images normally according to the given prompt. With extensive experiments across different watermarking models, the proposed method achieves promising attack success rates. In addition, the analysis results of the watermark characteristics in term of backdoor attack further support the effectiveness of our approach. The code is available at:https://github.com/aiiu-lab/BackdoorImageEditing
Gen-n-Val: Agentic Image Data Generation and Validation
Jun 05, 2025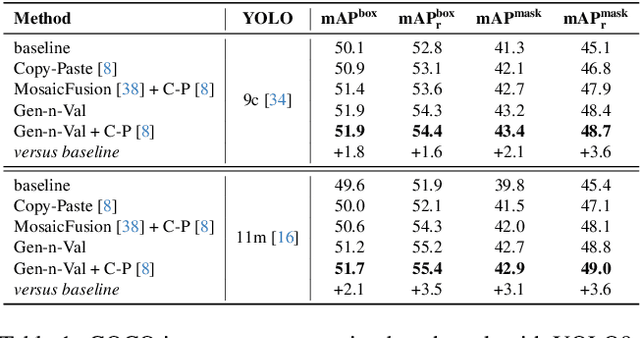



Recently, Large Language Models (LLMs) and Vision Large Language Models (VLLMs) have demonstrated impressive performance as agents across various tasks while data scarcity and label noise remain significant challenges in computer vision tasks, such as object detection and instance segmentation. A common solution for resolving these issues is to generate synthetic data. However, current synthetic data generation methods struggle with issues, such as multiple objects per mask, inaccurate segmentation, and incorrect category labels, limiting their effectiveness. To address these issues, we introduce Gen-n-Val, a novel agentic data generation framework that leverages Layer Diffusion (LD), LLMs, and VLLMs to produce high-quality, single-object masks and diverse backgrounds. Gen-n-Val consists of two agents: (1) The LD prompt agent, an LLM, optimizes prompts for LD to generate high-quality foreground instance images and segmentation masks. These optimized prompts ensure the generation of single-object synthetic data with precise instance masks and clean backgrounds. (2) The data validation agent, a VLLM, which filters out low-quality synthetic instance images. The system prompts for both agents are refined through TextGrad. Additionally, we use image harmonization to combine multiple instances within scenes. Compared to state-of-the-art synthetic data approaches like MosaicFusion, our approach reduces invalid synthetic data from 50% to 7% and improves performance by 1% mAP on rare classes in COCO instance segmentation with YOLOv9c and YOLO11m. Furthermore, Gen-n-Val shows significant improvements (7. 1% mAP) over YOLO-Worldv2-M in open-vocabulary object detection benchmarks with YOLO11m. Moreover, Gen-n-Val improves the performance of YOLOv9 and YOLO11 families in instance segmentation and object detection.
CameraBench: Benchmarking Visual Reasoning in MLLMs via Photography
Apr 14, 2025Large language models (LLMs) and multimodal large language models (MLLMs) have significantly advanced artificial intelligence. However, visual reasoning, reasoning involving both visual and textual inputs, remains underexplored. Recent advancements, including the reasoning models like OpenAI o1 and Gemini 2.0 Flash Thinking, which incorporate image inputs, have opened this capability. In this ongoing work, we focus specifically on photography-related tasks because a photo is a visual snapshot of the physical world where the underlying physics (i.e., illumination, blur extent, etc.) interplay with the camera parameters. Successfully reasoning from the visual information of a photo to identify these numerical camera settings requires the MLLMs to have a deeper understanding of the underlying physics for precise visual comprehension, representing a challenging and intelligent capability essential for practical applications like photography assistant agents. We aim to evaluate MLLMs on their ability to distinguish visual differences related to numerical camera settings, extending a methodology previously proposed for vision-language models (VLMs). Our preliminary results demonstrate the importance of visual reasoning in photography-related tasks. Moreover, these results show that no single MLLM consistently dominates across all evaluation tasks, demonstrating ongoing challenges and opportunities in developing MLLMs with better visual reasoning.
Harnessing Large Language and Vision-Language Models for Robust Out-of-Distribution Detection
Jan 09, 2025Out-of-distribution (OOD) detection has seen significant advancements with zero-shot approaches by leveraging the powerful Vision-Language Models (VLMs) such as CLIP. However, prior research works have predominantly focused on enhancing Far-OOD performance, while potentially compromising Near-OOD efficacy, as observed from our pilot study. To address this issue, we propose a novel strategy to enhance zero-shot OOD detection performances for both Far-OOD and Near-OOD scenarios by innovatively harnessing Large Language Models (LLMs) and VLMs. Our approach first exploit an LLM to generate superclasses of the ID labels and their corresponding background descriptions followed by feature extraction using CLIP. We then isolate the core semantic features for ID data by subtracting background features from the superclass features. The refined representation facilitates the selection of more appropriate negative labels for OOD data from a comprehensive candidate label set of WordNet, thereby enhancing the performance of zero-shot OOD detection in both scenarios. Furthermore, we introduce novel few-shot prompt tuning and visual prompt tuning to adapt the proposed framework to better align with the target distribution. Experimental results demonstrate that the proposed approach consistently outperforms current state-of-the-art methods across multiple benchmarks, with an improvement of up to 2.9% in AUROC and a reduction of up to 12.6% in FPR95. Additionally, our method exhibits superior robustness against covariate shift across different domains, further highlighting its effectiveness in real-world scenarios.
StyleDiT: A Unified Framework for Diverse Child and Partner Faces Synthesis with Style Latent Diffusion Transformer
Dec 14, 2024Kinship face synthesis is a challenging problem due to the scarcity and low quality of the available kinship data. Existing methods often struggle to generate descendants with both high diversity and fidelity while precisely controlling facial attributes such as age and gender. To address these issues, we propose the Style Latent Diffusion Transformer (StyleDiT), a novel framework that integrates the strengths of StyleGAN with the diffusion model to generate high-quality and diverse kinship faces. In this framework, the rich facial priors of StyleGAN enable fine-grained attribute control, while our conditional diffusion model is used to sample a StyleGAN latent aligned with the kinship relationship of conditioning images by utilizing the advantage of modeling complex kinship relationship distribution. StyleGAN then handles latent decoding for final face generation. Additionally, we introduce the Relational Trait Guidance (RTG) mechanism, enabling independent control of influencing conditions, such as each parent's facial image. RTG also enables a fine-grained adjustment between the diversity and fidelity in synthesized faces. Furthermore, we extend the application to an unexplored domain: predicting a partner's facial images using a child's image and one parent's image within the same framework. Extensive experiments demonstrate that our StyleDiT outperforms existing methods by striking an excellent balance between generating diverse and high-fidelity kinship faces.
FIPER: Generalizable Factorized Fields for Joint Image Compression and Super-Resolution
Oct 23, 2024In this work, we propose a unified representation for Super-Resolution (SR) and Image Compression, termed **Factorized Fields**, motivated by the shared principles between these two tasks. Both SISR and Image Compression require recovering and preserving fine image details--whether by enhancing resolution or reconstructing compressed data. Unlike previous methods that mainly focus on network architecture, our proposed approach utilizes a basis-coefficient decomposition to explicitly capture multi-scale visual features and structural components in images, addressing the core challenges of both tasks. We first derive our SR model, which includes a Coefficient Backbone and Basis Swin Transformer for generalizable Factorized Fields. Then, to further unify these two tasks, we leverage the strong information-recovery capabilities of the trained SR modules as priors in the compression pipeline, improving both compression efficiency and detail reconstruction. Additionally, we introduce a merged-basis compression branch that consolidates shared structures, further optimizing the compression process. Extensive experiments show that our unified representation delivers state-of-the-art performance, achieving an average relative improvement of 204.4% in PSNR over the baseline in Super-Resolution (SR) and 9.35% BD-rate reduction in Image Compression compared to the previous SOTA.
ACCEPT: Adaptive Codebook for Composite and Efficient Prompt Tuning
Oct 10, 2024



Prompt Tuning has been a popular Parameter-Efficient Fine-Tuning method attributed to its remarkable performance with few updated parameters on various large-scale pretrained Language Models (PLMs). Traditionally, each prompt has been considered indivisible and updated independently, leading the parameters increase proportionally as prompt length grows. To address this issue, we propose Adaptive Codebook for Composite and Efficient Prompt Tuning (ACCEPT). In our method, we refer to the concept of product quantization (PQ), allowing all soft prompts to share a set of learnable codebook vectors in each subspace, with each prompt differentiated by a set of adaptive weights. We achieve the superior performance on 17 diverse natural language tasks including natural language understanding (NLU) and question answering (QA) tasks by tuning only 0.3% of parameters of the PLMs. Our approach also excels in few-shot and large model settings, highlighting its significant potential.