 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
BanglaAbuseMeme: A Dataset for Bengali Abusive Meme Classification
Oct 18, 2023

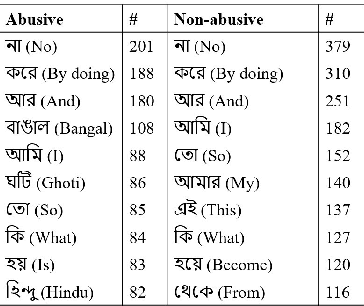
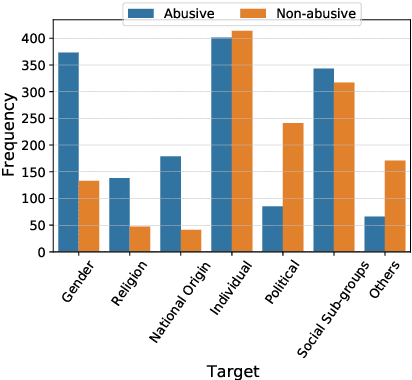
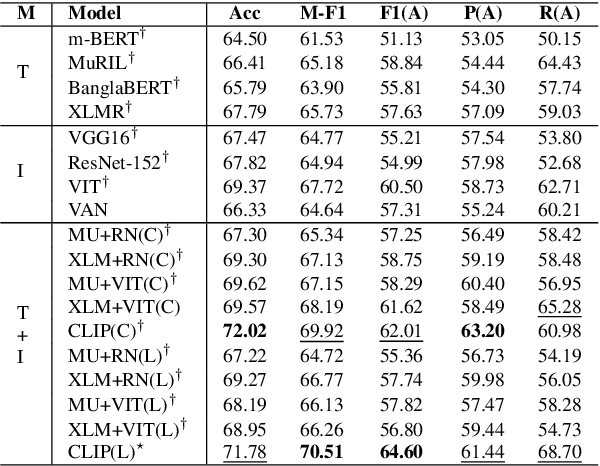
The dramatic increase in the use of social media platforms for information sharing has also fueled a steep growth in online abuse. A simple yet effective way of abusing individuals or communities is by creating memes, which often integrate an image with a short piece of text layered on top of it. Such harmful elements are in rampant use and are a threat to online safety. Hence it is necessary to develop efficient models to detect and flag abusive memes. The problem becomes more challenging in a low-resource setting (e.g., Bengali memes, i.e., images with Bengali text embedded on it) because of the absence of benchmark datasets on which AI models could be trained. In this paper we bridge this gap by building a Bengali meme dataset. To setup an effective benchmark we implement several baseline models for classifying abusive memes using this dataset. We observe that multimodal models that use both textual and visual information outperform unimodal models. Our best-performing model achieves a macro F1 score of 70.51. Finally, we perform a qualitative error analysis of the misclassified memes of the best-performing text-based, image-based and multimodal models.
MCUFormer: Deploying Vision Tranformers on Microcontrollers with Limited Memory
Oct 27, 2023Due to the high price and heavy energy consumption of GPUs, deploying deep models on IoT devices such as microcontrollers makes significant contributions for ecological AI. Conventional methods successfully enable convolutional neural network inference of high resolution images on microcontrollers, while the framework for vision transformers that achieve the state-of-the-art performance in many vision applications still remains unexplored. In this paper, we propose a hardware-algorithm co-optimizations method called MCUFormer to deploy vision transformers on microcontrollers with extremely limited memory, where we jointly design transformer architecture and construct the inference operator library to fit the memory resource constraint. More specifically, we generalize the one-shot network architecture search (NAS) to discover the optimal architecture with highest task performance given the memory budget from the microcontrollers, where we enlarge the existing search space of vision transformers by considering the low-rank decomposition dimensions and patch resolution for memory reduction. For the construction of the inference operator library of vision transformers, we schedule the memory buffer during inference through operator integration, patch embedding decomposition, and token overwriting, allowing the memory buffer to be fully utilized to adapt to the forward pass of the vision transformer. Experimental results demonstrate that our MCUFormer achieves 73.62\% top-1 accuracy on ImageNet for image classification with 320KB memory on STM32F746 microcontroller. Code is available at https://github.com/liangyn22/MCUFormer.
Addressing GAN Training Instabilities via Tunable Classification Losses
Oct 27, 2023Generative adversarial networks (GANs), modeled as a zero-sum game between a generator (G) and a discriminator (D), allow generating synthetic data with formal guarantees. Noting that D is a classifier, we begin by reformulating the GAN value function using class probability estimation (CPE) losses. We prove a two-way correspondence between CPE loss GANs and $f$-GANs which minimize $f$-divergences. We also show that all symmetric $f$-divergences are equivalent in convergence. In the finite sample and model capacity setting, we define and obtain bounds on estimation and generalization errors. We specialize these results to $\alpha$-GANs, defined using $\alpha$-loss, a tunable CPE loss family parametrized by $\alpha\in(0,\infty]$. We next introduce a class of dual-objective GANs to address training instabilities of GANs by modeling each player's objective using $\alpha$-loss to obtain $(\alpha_D,\alpha_G)$-GANs. We show that the resulting non-zero sum game simplifies to minimizing an $f$-divergence under appropriate conditions on $(\alpha_D,\alpha_G)$. Generalizing this dual-objective formulation using CPE losses, we define and obtain upper bounds on an appropriately defined estimation error. Finally, we highlight the value of tuning $(\alpha_D,\alpha_G)$ in alleviating training instabilities for the synthetic 2D Gaussian mixture ring as well as the large publicly available Celeb-A and LSUN Classroom image datasets.
DocStormer: Revitalizing Multi-Degraded Colored Document Images to Pristine PDF
Oct 27, 2023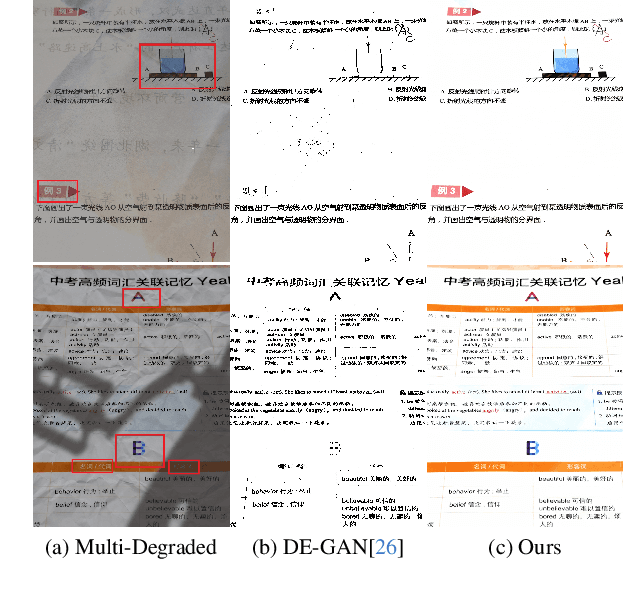

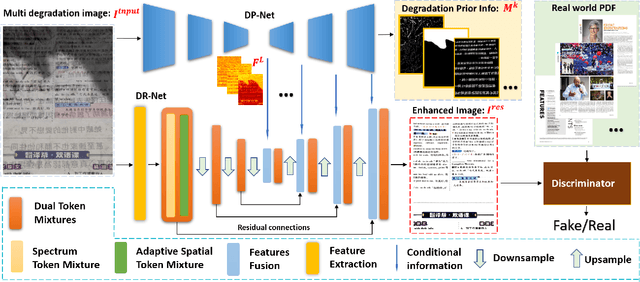
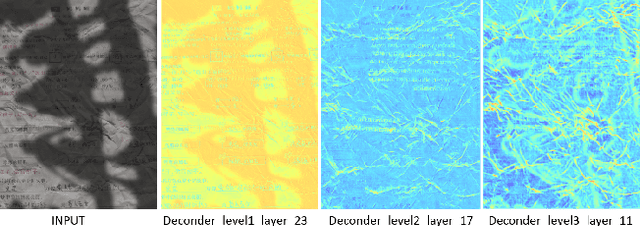
For capturing colored document images, e.g. posters and magazines, it is common that multiple degradations such as shadows, wrinkles, etc., are simultaneously introduced due to external factors. Restoring multi-degraded colored document images is a great challenge, yet overlooked, as most existing algorithms focus on enhancing color-ignored document images via binarization. Thus, we propose DocStormer, a novel algorithm designed to restore multi-degraded colored documents to their potential pristine PDF. The contributions are: firstly, we propose a "Perceive-then-Restore" paradigm with a reinforced transformer block, which more effectively encodes and utilizes the distribution of degradations. Secondly, we are the first to utilize GAN and pristine PDF magazine images to narrow the distribution gap between the enhanced results and PDF images, in pursuit of less degradation and better visual quality. Thirdly, we propose a non-parametric strategy, PFILI, which enables a smaller training scale and larger testing resolutions with acceptable detail trade-off, while saving memory and inference time. Fourthly, we are the first to propose a novel Multi-Degraded Colored Document image Enhancing dataset, named MD-CDE, for both training and evaluation. Experimental results show that the DocStormer exhibits superior performance, capable of revitalizing multi-degraded colored documents into their potential pristine digital versions, which fills the current academic gap from the perspective of method, data, and task.
Hyper-Skin: A Hyperspectral Dataset for Reconstructing Facial Skin-Spectra from RGB Images
Oct 27, 2023We introduce Hyper-Skin, a hyperspectral dataset covering wide range of wavelengths from visible (VIS) spectrum (400nm - 700nm) to near-infrared (NIR) spectrum (700nm - 1000nm), uniquely designed to facilitate research on facial skin-spectra reconstruction. By reconstructing skin spectra from RGB images, our dataset enables the study of hyperspectral skin analysis, such as melanin and hemoglobin concentrations, directly on the consumer device. Overcoming limitations of existing datasets, Hyper-Skin consists of diverse facial skin data collected with a pushbroom hyperspectral camera. With 330 hyperspectral cubes from 51 subjects, the dataset covers the facial skin from different angles and facial poses. Each hyperspectral cube has dimensions of 1024$\times$1024$\times$448, resulting in millions of spectra vectors per image. The dataset, carefully curated in adherence to ethical guidelines, includes paired hyperspectral images and synthetic RGB images generated using real camera responses. We demonstrate the efficacy of our dataset by showcasing skin spectra reconstruction using state-of-the-art models on 31 bands of hyperspectral data resampled in the VIS and NIR spectrum. This Hyper-Skin dataset would be a valuable resource to NeurIPS community, encouraging the development of novel algorithms for skin spectral reconstruction while fostering interdisciplinary collaboration in hyperspectral skin analysis related to cosmetology and skin's well-being. Instructions to request the data and the related benchmarking codes are publicly available at: \url{https://github.com/hyperspectral-skin/Hyper-Skin-2023}.
IP-Adapter: Text Compatible Image Prompt Adapter for Text-to-Image Diffusion Models
Aug 13, 2023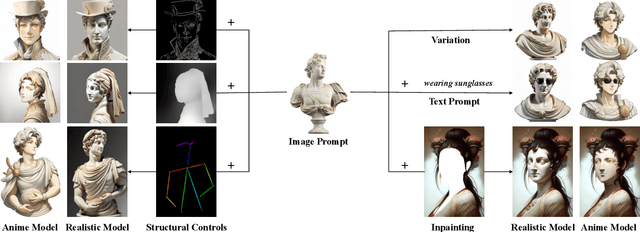
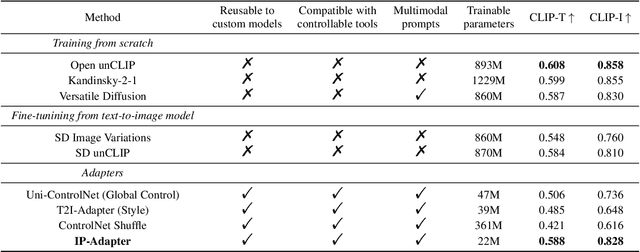
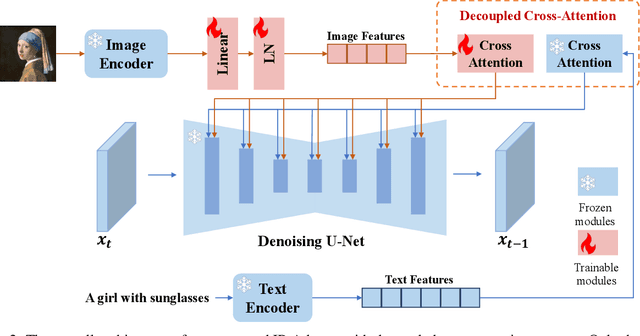

Recent years have witnessed the strong power of large text-to-image diffusion models for the impressive generative capability to create high-fidelity images. However, it is very tricky to generate desired images using only text prompt as it often involves complex prompt engineering. An alternative to text prompt is image prompt, as the saying goes: "an image is worth a thousand words". Although existing methods of direct fine-tuning from pretrained models are effective, they require large computing resources and are not compatible with other base models, text prompt, and structural controls. In this paper, we present IP-Adapter, an effective and lightweight adapter to achieve image prompt capability for the pretrained text-to-image diffusion models. The key design of our IP-Adapter is decoupled cross-attention mechanism that separates cross-attention layers for text features and image features. Despite the simplicity of our method, an IP-Adapter with only 22M parameters can achieve comparable or even better performance to a fully fine-tuned image prompt model. As we freeze the pretrained diffusion model, the proposed IP-Adapter can be generalized not only to other custom models fine-tuned from the same base model, but also to controllable generation using existing controllable tools. With the benefit of the decoupled cross-attention strategy, the image prompt can also work well with the text prompt to achieve multimodal image generation. The project page is available at \url{https://ip-adapter.github.io}.
DeFormer: Integrating Transformers with Deformable Models for 3D Shape Abstraction from a Single Image
Sep 22, 2023
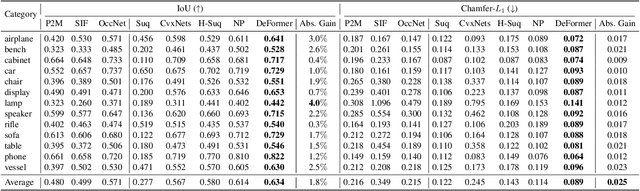
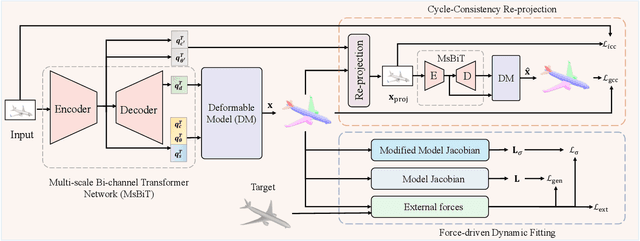
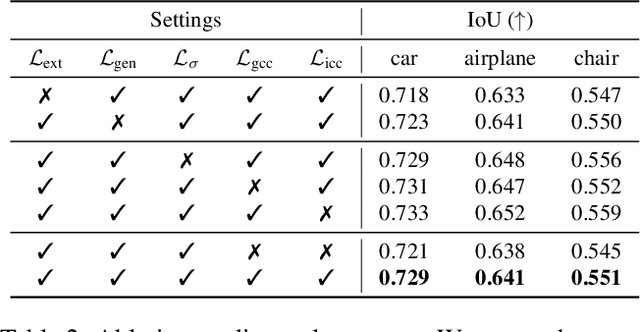
Accurate 3D shape abstraction from a single 2D image is a long-standing problem in computer vision and graphics. By leveraging a set of primitives to represent the target shape, recent methods have achieved promising results. However, these methods either use a relatively large number of primitives or lack geometric flexibility due to the limited expressibility of the primitives. In this paper, we propose a novel bi-channel Transformer architecture, integrated with parameterized deformable models, termed DeFormer, to simultaneously estimate the global and local deformations of primitives. In this way, DeFormer can abstract complex object shapes while using a small number of primitives which offer a broader geometry coverage and finer details. Then, we introduce a force-driven dynamic fitting and a cycle-consistent re-projection loss to optimize the primitive parameters. Extensive experiments on ShapeNet across various settings show that DeFormer achieves better reconstruction accuracy over the state-of-the-art, and visualizes with consistent semantic correspondences for improved interpretability.
UPL-SFDA: Uncertainty-aware Pseudo Label Guided Source-Free Domain Adaptation for Medical Image Segmentation
Sep 19, 2023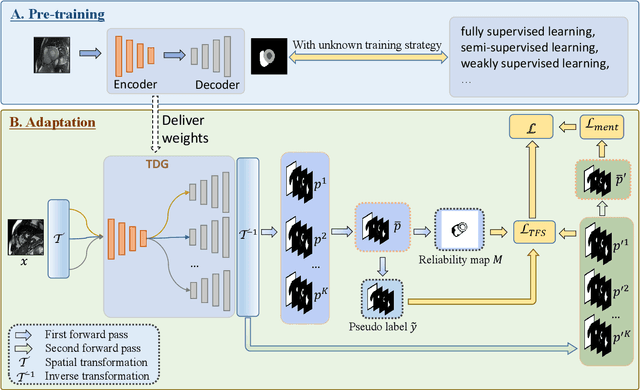
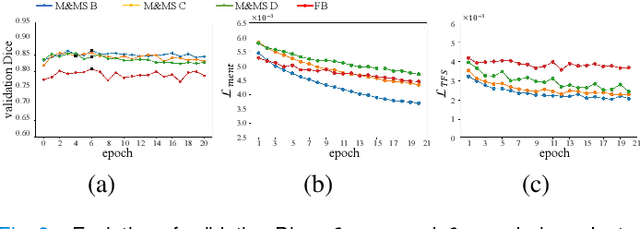
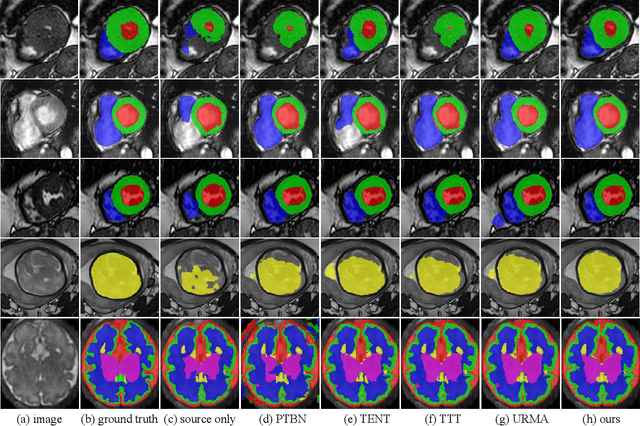

Domain Adaptation (DA) is important for deep learning-based medical image segmentation models to deal with testing images from a new target domain. As the source-domain data are usually unavailable when a trained model is deployed at a new center, Source-Free Domain Adaptation (SFDA) is appealing for data and annotation-efficient adaptation to the target domain. However, existing SFDA methods have a limited performance due to lack of sufficient supervision with source-domain images unavailable and target-domain images unlabeled. We propose a novel Uncertainty-aware Pseudo Label guided (UPL) SFDA method for medical image segmentation. Specifically, we propose Target Domain Growing (TDG) to enhance the diversity of predictions in the target domain by duplicating the pre-trained model's prediction head multiple times with perturbations. The different predictions in these duplicated heads are used to obtain pseudo labels for unlabeled target-domain images and their uncertainty to identify reliable pseudo labels. We also propose a Twice Forward pass Supervision (TFS) strategy that uses reliable pseudo labels obtained in one forward pass to supervise predictions in the next forward pass. The adaptation is further regularized by a mean prediction-based entropy minimization term that encourages confident and consistent results in different prediction heads. UPL-SFDA was validated with a multi-site heart MRI segmentation dataset, a cross-modality fetal brain segmentation dataset, and a 3D fetal tissue segmentation dataset. It improved the average Dice by 5.54, 5.01 and 6.89 percentage points for the three tasks compared with the baseline, respectively, and outperformed several state-of-the-art SFDA methods.
Prompt-based All-in-One Image Restoration using CNNs and Transformer
Sep 06, 2023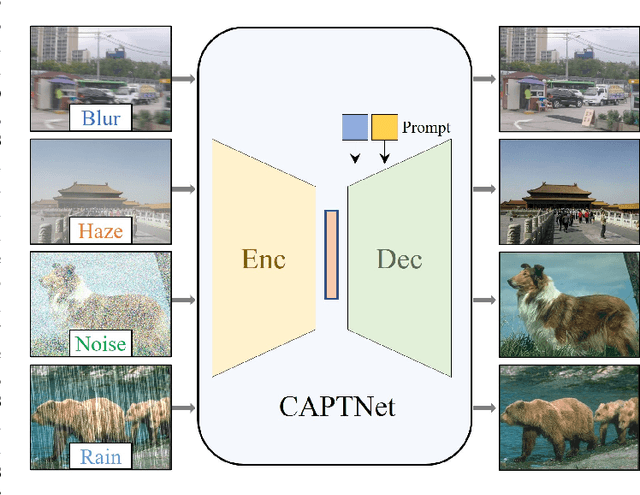



Image restoration aims to recover the high-quality images from their degraded observations. Since most existing methods have been dedicated into single degradation removal, they may not yield optimal results on other types of degradations, which do not satisfy the applications in real world scenarios. In this paper, we propose a novel data ingredient-oriented approach that leverages prompt-based learning to enable a single model to efficiently tackle multiple image degradation tasks. Specifically, we utilize a encoder to capture features and introduce prompts with degradation-specific information to guide the decoder in adaptively recovering images affected by various degradations. In order to model the local invariant properties and non-local information for high-quality image restoration, we combined CNNs operations and Transformers. Simultaneously, we made several key designs in the Transformer blocks (multi-head rearranged attention with prompts and simple-gate feed-forward network) to reduce computational requirements and selectively determines what information should be persevered to facilitate efficient recovery of potentially sharp images. Furthermore, we incorporate a feature fusion mechanism further explores the multi-scale information to improve the aggregated features. The resulting tightly interlinked hierarchy architecture, named as CAPTNet, despite being designed to handle different types of degradations, extensive experiments demonstrate that our method performs competitively to the task-specific algorithms.
Pre-trained Speech Processing Models Contain Human-Like Biases that Propagate to Speech Emotion Recognition
Oct 29, 2023Previous work has established that a person's demographics and speech style affect how well speech processing models perform for them. But where does this bias come from? In this work, we present the Speech Embedding Association Test (SpEAT), a method for detecting bias in one type of model used for many speech tasks: pre-trained models. The SpEAT is inspired by word embedding association tests in natural language processing, which quantify intrinsic bias in a model's representations of different concepts, such as race or valence (something's pleasantness or unpleasantness) and capture the extent to which a model trained on large-scale socio-cultural data has learned human-like biases. Using the SpEAT, we test for six types of bias in 16 English speech models (including 4 models also trained on multilingual data), which come from the wav2vec 2.0, HuBERT, WavLM, and Whisper model families. We find that 14 or more models reveal positive valence (pleasantness) associations with abled people over disabled people, with European-Americans over African-Americans, with females over males, with U.S. accented speakers over non-U.S. accented speakers, and with younger people over older people. Beyond establishing that pre-trained speech models contain these biases, we also show that they can have real world effects. We compare biases found in pre-trained models to biases in downstream models adapted to the task of Speech Emotion Recognition (SER) and find that in 66 of the 96 tests performed (69%), the group that is more associated with positive valence as indicated by the SpEAT also tends to be predicted as speaking with higher valence by the downstream model. Our work provides evidence that, like text and image-based models, pre-trained speech based-models frequently learn human-like biases. Our work also shows that bias found in pre-trained models can propagate to the downstream task of SER.