 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Visual In-Context Prompting
Nov 22, 2023
In-context prompting in large language models (LLMs) has become a prevalent approach to improve zero-shot capabilities, but this idea is less explored in the vision domain. Existing visual prompting methods focus on referring segmentation to segment the most relevant object, falling short of addressing many generic vision tasks like open-set segmentation and detection. In this paper, we introduce a universal visual in-context prompting framework for both tasks. In particular, we build on top of an encoder-decoder architecture, and develop a versatile prompt encoder to support a variety of prompts like strokes, boxes, and points. We further enhance it to take an arbitrary number of reference image segments as the context. Our extensive explorations show that the proposed visual in-context prompting elicits extraordinary referring and generic segmentation capabilities to refer and detect, yielding competitive performance to close-set in-domain datasets and showing promising results on many open-set segmentation datasets. By joint training on COCO and SA-1B, our model achieves $57.7$ PQ on COCO and $23.2$ PQ on ADE20K. Code will be available at https://github.com/UX-Decoder/DINOv.
ViStruct: Visual Structural Knowledge Extraction via Curriculum Guided Code-Vision Representation
Nov 22, 2023
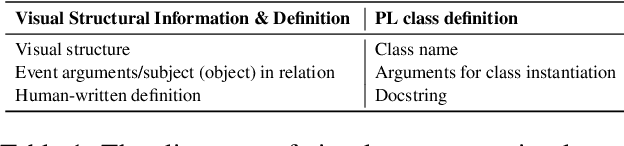


State-of-the-art vision-language models (VLMs) still have limited performance in structural knowledge extraction, such as relations between objects. In this work, we present ViStruct, a training framework to learn VLMs for effective visual structural knowledge extraction. Two novel designs are incorporated. First, we propose to leverage the inherent structure of programming language to depict visual structural information. This approach enables explicit and consistent representation of visual structural information of multiple granularities, such as concepts, relations, and events, in a well-organized structured format. Second, we introduce curriculum-based learning for VLMs to progressively comprehend visual structures, from fundamental visual concepts to intricate event structures. Our intuition is that lower-level knowledge may contribute to complex visual structure understanding. Furthermore, we compile and release a collection of datasets tailored for visual structural knowledge extraction. We adopt a weakly-supervised approach to directly generate visual event structures from captions for ViStruct training, capitalizing on abundant image-caption pairs from the web. In experiments, we evaluate ViStruct on visual structure prediction tasks, demonstrating its effectiveness in improving the understanding of visual structures. The code is public at \url{https://github.com/Yangyi-Chen/vi-struct}.
Volumetric Reconstruction Resolves Off-Resonance Artifacts in Static and Dynamic PROPELLER MRI
Nov 22, 2023Off-resonance artifacts in magnetic resonance imaging (MRI) are visual distortions that occur when the actual resonant frequencies of spins within the imaging volume differ from the expected frequencies used to encode spatial information. These discrepancies can be caused by a variety of factors, including magnetic field inhomogeneities, chemical shifts, or susceptibility differences within the tissues. Such artifacts can manifest as blurring, ghosting, or misregistration of the reconstructed image, and they often compromise its diagnostic quality. We propose to resolve these artifacts by lifting the 2D MRI reconstruction problem to 3D, introducing an additional "spectral" dimension to model this off-resonance. Our approach is inspired by recent progress in modeling radiance fields, and is capable of reconstructing both static and dynamic MR images as well as separating fat and water, which is of independent clinical interest. We demonstrate our approach in the context of PROPELLER (Periodically Rotated Overlapping ParallEL Lines with Enhanced Reconstruction) MRI acquisitions, which are popular for their robustness to motion artifacts. Our method operates in a few minutes on a single GPU, and to our knowledge is the first to correct for chemical shift in gradient echo PROPELLER MRI reconstruction without additional measurements or pretraining data.
Investigating Weight-Perturbed Deep Neural Networks With Application in Iris Presentation Attack Detection
Nov 22, 2023Deep neural networks (DNNs) exhibit superior performance in various machine learning tasks, e.g., image classification, speech recognition, biometric recognition, object detection, etc. However, it is essential to analyze their sensitivity to parameter perturbations before deploying them in real-world applications. In this work, we assess the sensitivity of DNNs against perturbations to their weight and bias parameters. The sensitivity analysis involves three DNN architectures (VGG, ResNet, and DenseNet), three types of parameter perturbations (Gaussian noise, weight zeroing, and weight scaling), and two settings (entire network and layer-wise). We perform experiments in the context of iris presentation attack detection and evaluate on two publicly available datasets: LivDet-Iris-2017 and LivDet-Iris-2020. Based on the sensitivity analysis, we propose improved models simply by perturbing parameters of the network without undergoing training. We further combine these perturbed models at the score-level and at the parameter-level to improve the performance over the original model. The ensemble at the parameter-level shows an average improvement of 43.58% on the LivDet-Iris-2017 dataset and 9.25% on the LivDet-Iris-2020 dataset. The source code is available at https://github.com/redwankarimsony/WeightPerturbation-MSU.
Data-Centric Long-Tailed Image Recognition
Nov 03, 2023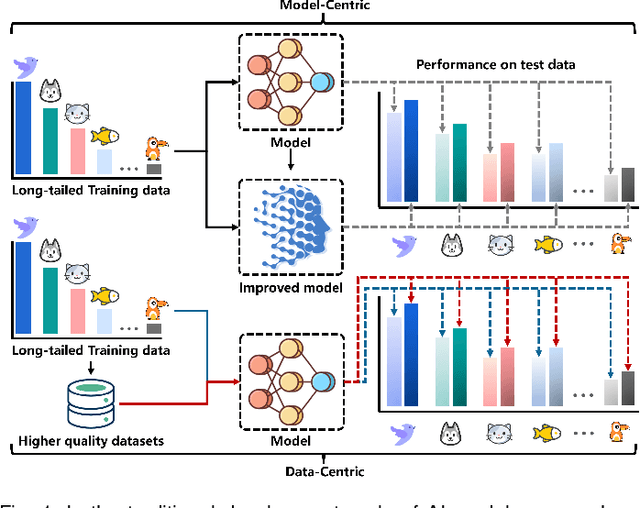
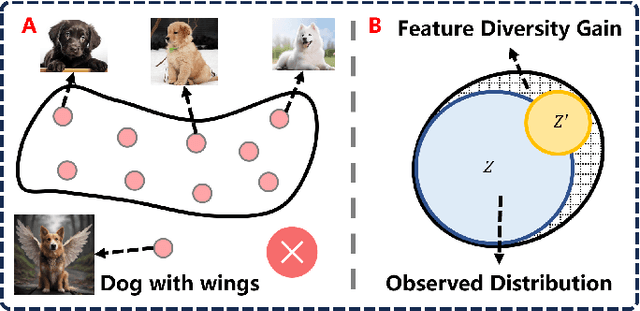
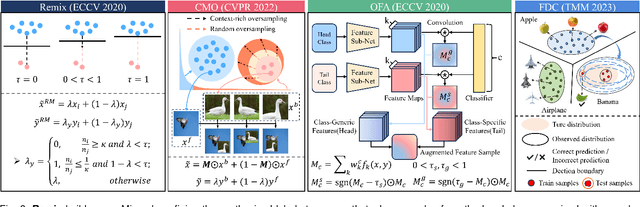
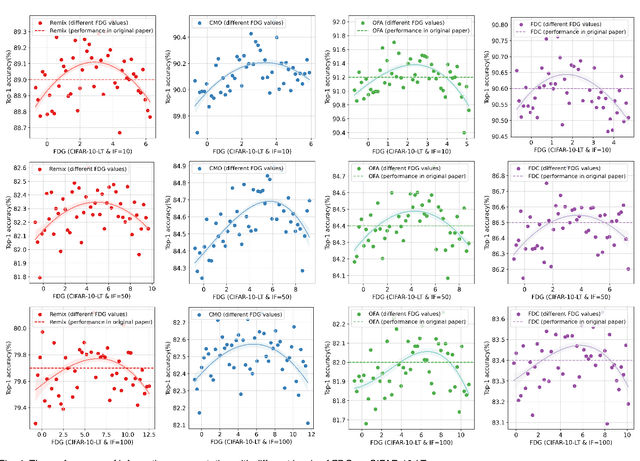
In the context of the long-tail scenario, models exhibit a strong demand for high-quality data. Data-centric approaches aim to enhance both the quantity and quality of data to improve model performance. Among these approaches, information augmentation has been progressively introduced as a crucial category. It achieves a balance in model performance by augmenting the richness and quantity of samples in the tail classes. However, there is currently a lack of research into the underlying mechanisms explaining the effectiveness of information augmentation methods. Consequently, the utilization of information augmentation in long-tail recognition tasks relies heavily on empirical and intricate fine-tuning. This work makes two primary contributions. Firstly, we approach the problem from the perspectives of feature diversity and distribution shift, introducing the concept of Feature Diversity Gain (FDG) to elucidate why information augmentation is effective. We find that the performance of information augmentation can be explained by FDG, and its performance peaks when FDG achieves an appropriate balance. Experimental results demonstrate that by using FDG to select augmented data, we can further enhance model performance without the need for any modifications to the model's architecture. Thus, data-centric approaches hold significant potential in the field of long-tail recognition, beyond the development of new model structures. Furthermore, we systematically introduce the core components and fundamental tasks of a data-centric long-tail learning framework for the first time. These core components guide the implementation and deployment of the system, while the corresponding fundamental tasks refine and expand the research area.
CycleGANAS: Differentiable Neural Architecture Search for CycleGAN
Nov 13, 2023We develop a Neural Architecture Search (NAS) framework for CycleGAN that carries out unpaired image-to-image translation task. Extending previous NAS techniques for Generative Adversarial Networks (GANs) to CycleGAN is not straightforward due to the task difference and greater search space. We design architectures that consist of a stack of simple ResNet-based cells and develop a search method that effectively explore the large search space. We show that our framework, called CycleGANAS, not only effectively discovers high-performance architectures that either match or surpass the performance of the original CycleGAN, but also successfully address the data imbalance by individual architecture search for each translation direction. To our best knowledge, it is the first NAS result for CycleGAN and shed light on NAS for more complex structures.
Intelligent Cervical Spine Fracture Detection Using Deep Learning Methods
Nov 09, 2023Cervical spine fractures constitute a critical medical emergency, with the potential for lifelong paralysis or even fatality if left untreated or undetected. Over time, these fractures can deteriorate without intervention. To address the lack of research on the practical application of deep learning techniques for the detection of spine fractures, this study leverages a dataset containing both cervical spine fractures and non-fractured computed tomography images. This paper introduces a two-stage pipeline designed to identify the presence of cervical vertebrae in each image slice and pinpoint the location of fractures. In the first stage, a multi-input network, incorporating image and image metadata, is trained. This network is based on the Global Context Vision Transformer, and its performance is benchmarked against popular deep learning image classification model. In the second stage, a YOLOv8 model is trained to detect fractures within the images, and its effectiveness is compared to YOLOv5. The obtained results indicate that the proposed algorithm significantly reduces the workload of radiologists and enhances the accuracy of fracture detection.
RealFill: Reference-Driven Generation for Authentic Image Completion
Sep 28, 2023
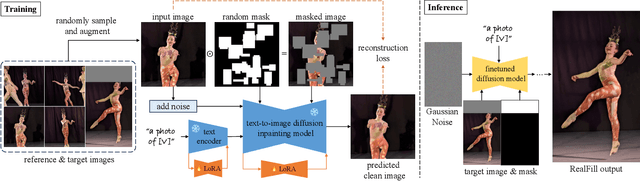
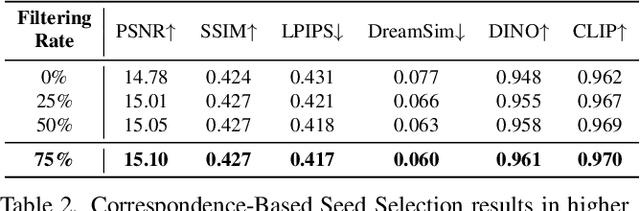

Recent advances in generative imagery have brought forth outpainting and inpainting models that can produce high-quality, plausible image content in unknown regions, but the content these models hallucinate is necessarily inauthentic, since the models lack sufficient context about the true scene. In this work, we propose RealFill, a novel generative approach for image completion that fills in missing regions of an image with the content that should have been there. RealFill is a generative inpainting model that is personalized using only a few reference images of a scene. These reference images do not have to be aligned with the target image, and can be taken with drastically varying viewpoints, lighting conditions, camera apertures, or image styles. Once personalized, RealFill is able to complete a target image with visually compelling contents that are faithful to the original scene. We evaluate RealFill on a new image completion benchmark that covers a set of diverse and challenging scenarios, and find that it outperforms existing approaches by a large margin. See more results on our project page: https://realfill.github.io
Teaching Text-to-Image Models to Communicate
Sep 27, 2023Various works have been extensively studied in the research of text-to-image generation. Although existing models perform well in text-to-image generation, there are significant challenges when directly employing them to generate images in dialogs. In this paper, we first highlight a new problem: dialog-to-image generation, that is, given the dialog context, the model should generate a realistic image which is consistent with the specified conversation as response. To tackle the problem, we propose an efficient approach for dialog-to-image generation without any intermediate translation, which maximizes the extraction of the semantic information contained in the dialog. Considering the characteristics of dialog structure, we put segment token before each sentence in a turn of a dialog to differentiate different speakers. Then, we fine-tune pre-trained text-to-image models to enable them to generate images conditioning on processed dialog context. After fine-tuning, our approach can consistently improve the performance of various models across multiple metrics. Experimental results on public benchmark demonstrate the effectiveness and practicability of our method.
On The Relationship Between Universal Adversarial Attacks And Sparse Representations
Nov 14, 2023The prominent success of neural networks, mainly in computer vision tasks, is increasingly shadowed by their sensitivity to small, barely perceivable adversarial perturbations in image input. In this work, we aim at explaining this vulnerability through the framework of sparsity. We show the connection between adversarial attacks and sparse representations, with a focus on explaining the universality and transferability of adversarial examples in neural networks. To this end, we show that sparse coding algorithms, and the neural network-based learned iterative shrinkage thresholding algorithm (LISTA) among them, suffer from this sensitivity, and that common attacks on neural networks can be expressed as attacks on the sparse representation of the input image. The phenomenon that we observe holds true also when the network is agnostic to the sparse representation and dictionary, and thus can provide a possible explanation for the universality and transferability of adversarial attacks. The code is available at https://github.com/danawr/adversarial_attacks_and_sparse_representations.